 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WeedCLR: Weed Contrastive Learning through Visual Representations with Class-Optimized Loss in Long-Tailed Datasets
Oct 19, 2023
Image classification is a crucial task in modern weed management and crop intervention technologies. However, the limited size, diversity, and balance of existing weed datasets hinder the development of deep learning models for generalizable weed identification. In addition, the expensive labelling requirements of mainstream fully-supervised weed classifiers make them cost- and time-prohibitive to deploy widely, for new weed species, and in site-specific weed management. This paper proposes a novel method for Weed Contrastive Learning through visual Representations (WeedCLR), that uses class-optimized loss with Von Neumann Entropy of deep representation for weed classification in long-tailed datasets. WeedCLR leverages self-supervised learning to learn rich and robust visual features without any labels and applies a class-optimized loss function to address the class imbalance problem in long-tailed datasets. WeedCLR is evaluated on two public weed datasets: CottonWeedID15, containing 15 weed species, and DeepWeeds, containing 8 weed species. WeedCLR achieves an average accuracy improvement of 4.3\% on CottonWeedID15 and 5.6\% on DeepWeeds over previous methods. It also demonstrates better generalization ability and robustness to different environmental conditions than existing methods without the need for expensive and time-consuming human annotations. These significant improvements make WeedCLR an effective tool for weed classification in long-tailed datasets and allows for more rapid and widespread deployment of site-specific weed management and crop intervention technologies.
Heart Disease Detection using Vision-Based Transformer Models from ECG Images
Oct 19, 2023Heart disease, also known as cardiovascular disease, is a prevalent and critical medical condition characterized by the impairment of the heart and blood vessels, leading to various complications such as coronary artery disease, heart failure, and myocardial infarction. The timely and accurate detection of heart disease is of paramount importance in clinical practice. Early identification of individuals at risk enables proactive interventions, preventive measures, and personalized treatment strategies to mitigate the progression of the disease and reduce adverse outcomes. In recent years, the field of heart disease detection has witnessed notable advancements due to the integration of sophisticated technologies and computational approaches. These include machine learning algorithms, data mining techniques, and predictive modeling frameworks that leverage vast amounts of clinical and physiological data to improve diagnostic accuracy and risk stratification. In this work, we propose to detect heart disease from ECG images using cutting-edge technologies, namely vision transformer models. These models are Google-Vit, Microsoft-Beit, and Swin-Tiny. To the best of our knowledge, this is the initial endeavor concentrating on the detection of heart diseases through image-based ECG data by employing cuttingedge technologies namely, transformer models. To demonstrate the contribution of the proposed framework, the performance of vision transformer models are compared with state-of-the-art studies. Experiment results show that the proposed framework exhibits remarkable classification results.
DT/MARS-CycleGAN: Improved Object Detection for MARS Phenotyping Robot
Oct 19, 2023Robotic crop phenotyping has emerged as a key technology to assess crops' morphological and physiological traits at scale. These phenotypical measurements are essential for developing new crop varieties with the aim of increasing productivity and dealing with environmental challenges such as climate change. However, developing and deploying crop phenotyping robots face many challenges such as complex and variable crop shapes that complicate robotic object detection, dynamic and unstructured environments that baffle robotic control, and real-time computing and managing big data that challenge robotic hardware/software. This work specifically tackles the first challenge by proposing a novel Digital-Twin(DT)MARS-CycleGAN model for image augmentation to improve our Modular Agricultural Robotic System (MARS)'s crop object detection from complex and variable backgrounds. Our core idea is that in addition to the cycle consistency losses in the CycleGAN model, we designed and enforced a new DT-MARS loss in the deep learning model to penalize the inconsistency between real crop images captured by MARS and synthesized images sensed by DT MARS. Therefore, the generated synthesized crop images closely mimic real images in terms of realism, and they are employed to fine-tune object detectors such as YOLOv8. Extensive experiments demonstrated that our new DT/MARS-CycleGAN framework significantly boosts our MARS' crop object/row detector's performance, contributing to the field of robotic crop phenotyping.
STANLEY: Stochastic Gradient Anisotropic Langevin Dynamics for Learning Energy-Based Models
Oct 19, 2023We propose in this paper, STANLEY, a STochastic gradient ANisotropic LangEvin dYnamics, for sampling high dimensional data. With the growing efficacy and potential of Energy-Based modeling, also known as non-normalized probabilistic modeling, for modeling a generative process of different natures of high dimensional data observations, we present an end-to-end learning algorithm for Energy-Based models (EBM) with the purpose of improving the quality of the resulting sampled data points. While the unknown normalizing constant of EBMs makes the training procedure intractable, resorting to Markov Chain Monte Carlo (MCMC) is in general a viable option. Realizing what MCMC entails for the EBM training, we propose in this paper, a novel high dimensional sampling method, based on an anisotropic stepsize and a gradient-informed covariance matrix, embedded into a discretized Langevin diffusion. We motivate the necessity for an anisotropic update of the negative samples in the Markov Chain by the nonlinearity of the backbone of the EBM, here a Convolutional Neural Network. Our resulting method, namely STANLEY, is an optimization algorithm for training Energy-Based models via our newly introduced MCMC method. We provide a theoretical understanding of our sampling scheme by proving that the sampler leads to a geometrically uniformly ergodic Markov Chain. Several image generation experiments are provided in our paper to show the effectiveness of our method.
FSD: Fast Self-Supervised Single RGB-D to Categorical 3D Objects
Oct 19, 2023In this work, we address the challenging task of 3D object recognition without the reliance on real-world 3D labeled data. Our goal is to predict the 3D shape, size, and 6D pose of objects within a single RGB-D image, operating at the category level and eliminating the need for CAD models during inference. While existing self-supervised methods have made strides in this field, they often suffer from inefficiencies arising from non-end-to-end processing, reliance on separate models for different object categories, and slow surface extraction during the training of implicit reconstruction models; thus hindering both the speed and real-world applicability of the 3D recognition process. Our proposed method leverages a multi-stage training pipeline, designed to efficiently transfer synthetic performance to the real-world domain. This approach is achieved through a combination of 2D and 3D supervised losses during the synthetic domain training, followed by the incorporation of 2D supervised and 3D self-supervised losses on real-world data in two additional learning stages. By adopting this comprehensive strategy, our method successfully overcomes the aforementioned limitations and outperforms existing self-supervised 6D pose and size estimation baselines on the NOCS test-set with a 16.4% absolute improvement in mAP for 6D pose estimation while running in near real-time at 5 Hz.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
Oct 11, 2023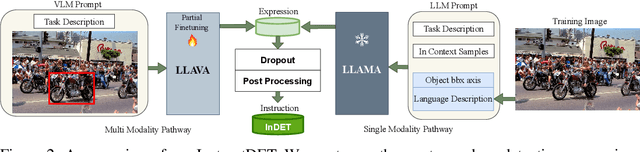

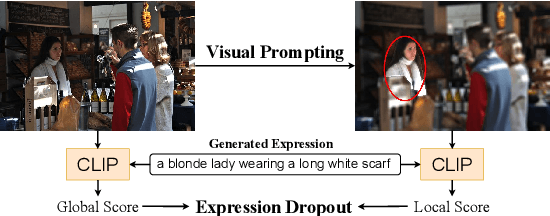
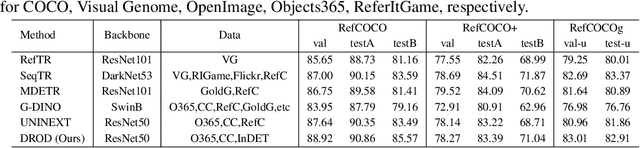
We propose InstructDET, a data-centric method for referring object detection (ROD) that localizes target objects based on user instructions. While deriving from referring expressions (REC), the instructions we leverage are greatly diversified to encompass common user intentions related to object detection. For one image, we produce tremendous instructions that refer to every single object and different combinations of multiple objects. Each instruction and its corresponding object bounding boxes (bbxs) constitute one training data pair. In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e.g., describing object property, category, and relationship). We name our constructed dataset as InDET. It contains images, bbxs and generalized instructions that are from foundation models. Our InDET is developed from existing REC datasets and object detection datasets, with the expanding potential that any image with object bbxs can be incorporated through using our InstructDET method. By using our InDET dataset, we show that a conventional ROD model surpasses existing methods on standard REC datasets and our InDET test set. Our data-centric method InstructDET, with automatic data expansion by leveraging foundation models, directs a promising field that ROD can be greatly diversified to execute common object detection instructions.
SRMAE: Masked Image Modeling for Scale-Invariant Deep Representations
Aug 17, 2023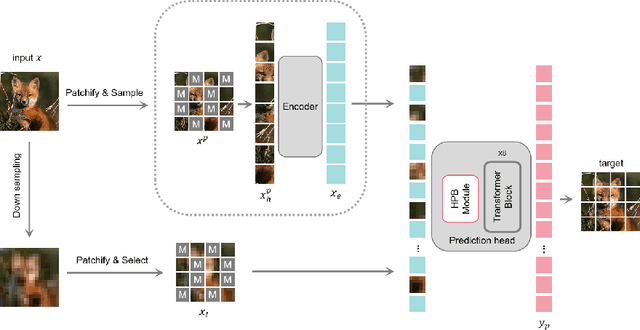


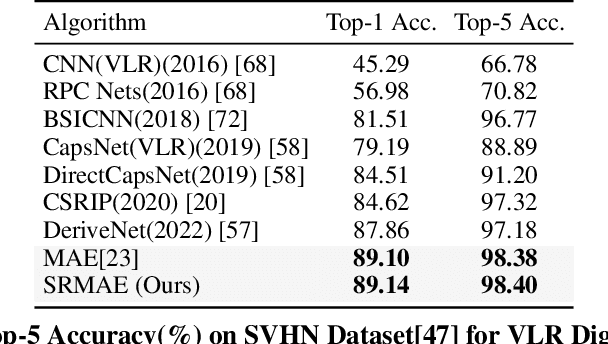
Due to the prevalence of scale variance in nature images, we propose to use image scale as a self-supervised signal for Masked Image Modeling (MIM). Our method involves selecting random patches from the input image and downsampling them to a low-resolution format. Our framework utilizes the latest advances in super-resolution (SR) to design the prediction head, which reconstructs the input from low-resolution clues and other patches. After 400 epochs of pre-training, our Super Resolution Masked Autoencoders (SRMAE) get an accuracy of 82.1% on the ImageNet-1K task. Image scale signal also allows our SRMAE to capture scale invariance representation. For the very low resolution (VLR) recognition task, our model achieves the best performance, surpassing DeriveNet by 1.3%. Our method also achieves an accuracy of 74.84% on the task of recognizing low-resolution facial expressions, surpassing the current state-of-the-art FMD by 9.48%.
Fully Sparse Long Range 3D Object Detection Using Range Experts and Multimodal Virtual Points
Oct 07, 20233D object detection at long-range is crucial for ensuring the safety and efficiency of self-driving cars, allowing them to accurately perceive and react to objects, obstacles, and potential hazards from a distance. But most current state-of-the-art LiDAR based methods are limited by the sparsity of range sensors, which generates a form of domain gap between points closer to and farther away from the ego vehicle. Another related problem is the label imbalance for faraway objects, which inhibits the performance of Deep Neural Networks at long-range. Although image features could be beneficial for long-range detections, and some recently proposed multimodal methods incorporate image features, they do not scale well computationally at long ranges or are limited by depth estimation accuracy. To address the above limitations, we propose to combine two LiDAR based 3D detection networks, one specializing at near to mid-range objects, and one at long-range 3D detection. To train a detector at long range under a scarce label regime, we further propose to weigh the loss according to the labelled objects' distance from ego vehicle. To mitigate the LiDAR sparsity issue, we leverage Multimodal Virtual Points (MVP), an image based depth completion algorithm, to enrich our data with virtual points. Our method, combining two range experts trained with MVP, which we refer to as RangeFSD, achieves state-of-the-art performance on the Argoverse2 (AV2) dataset, with improvements at long range. The code will be released soon.
Pixel Adapter: A Graph-Based Post-Processing Approach for Scene Text Image Super-Resolution
Sep 16, 2023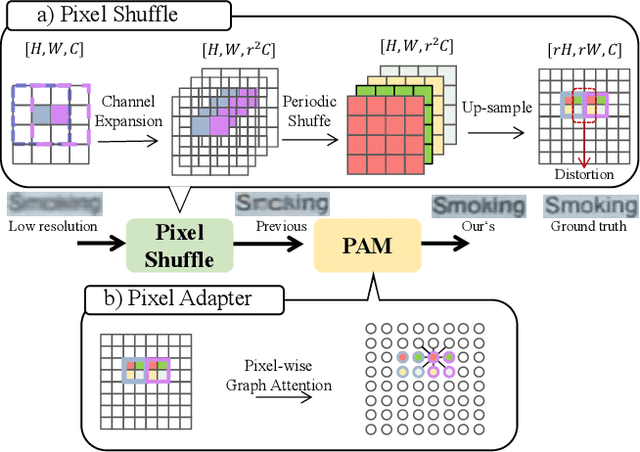
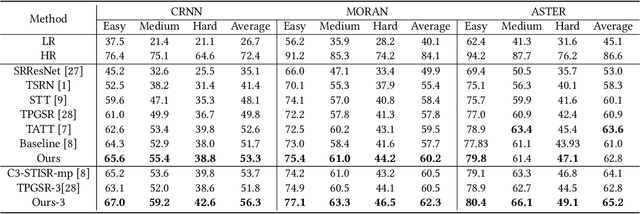
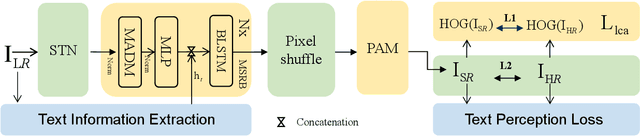
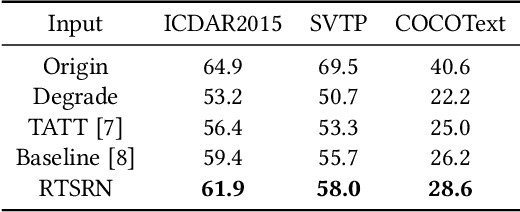
Current Scene text image super-resolution approaches primarily focus on extracting robust features, acquiring text information, and complex training strategies to generate super-resolution images. However, the upsampling module, which is crucial in the process of converting low-resolution images to high-resolution ones, has received little attention in existing works. To address this issue, we propose the Pixel Adapter Module (PAM) based on graph attention to address pixel distortion caused by upsampling. The PAM effectively captures local structural information by allowing each pixel to interact with its neighbors and update features. Unlike previous graph attention mechanisms, our approach achieves 2-3 orders of magnitude improvement in efficiency and memory utilization by eliminating the dependency on sparse adjacency matrices and introducing a sliding window approach for efficient parallel computation. Additionally, we introduce the MLP-based Sequential Residual Block (MSRB) for robust feature extraction from text images, and a Local Contour Awareness loss ($\mathcal{L}_{lca}$) to enhance the model's perception of details. Comprehensive experiments on TextZoom demonstrate that our proposed method generates high-quality super-resolution images, surpassing existing methods in recognition accuracy. For single-stage and multi-stage strategies, we achieved improvements of 0.7\% and 2.6\%, respectively, increasing the performance from 52.6\% and 53.7\% to 53.3\% and 56.3\%. The code is available at https://github.com/wenyu1009/RTSRN.
Visual Grounding Helps Learn Word Meanings in Low-Data Regimes
Oct 20, 2023Modern neural language models (LMs) are powerful tools for modeling human sentence production and comprehension, and their internal representations are remarkably well-aligned with representations of language in the human brain. But to achieve these results, LMs must be trained in distinctly un-human-like ways -- requiring orders of magnitude more language data than children receive during development, and without any of the accompanying grounding in perception, action, or social behavior. Do models trained more naturalistically -- with grounded supervision -- exhibit more human-like language learning? We investigate this question in the context of word learning, a key sub-task in language acquisition. We train a diverse set of LM architectures, with and without auxiliary supervision from image captioning tasks, on datasets of varying scales. We then evaluate these models on a broad set of benchmarks characterizing models' learning of syntactic categories, lexical relations, semantic features, semantic similarity, and alignment with human neural representations. We find that visual supervision can indeed improve the efficiency of word learning. However, these improvements are limited: they are present almost exclusively in the low-data regime, and sometimes canceled out by the inclusion of rich distributional signals from text. The information conveyed by text and images is not redundant -- we find that models mainly driven by visual information yield qualitatively different from those mainly driven by word co-occurrences. However, our results suggest that current multi-modal modeling approaches fail to effectively leverage visual information to build more human-like word representations from human-sized datasets.