 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Improved Encoder-Decoder Framework for Food Energy Estimation
Sep 22, 2023
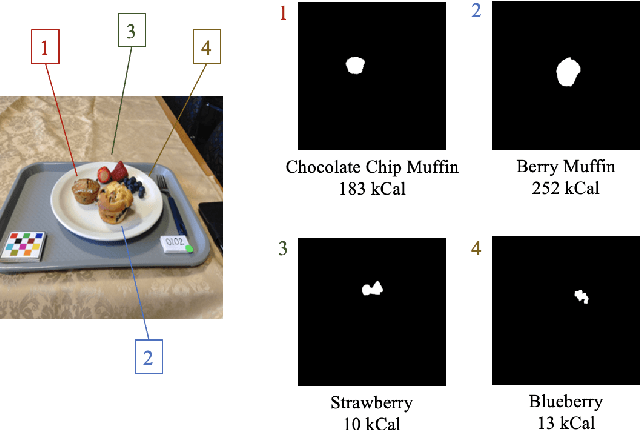

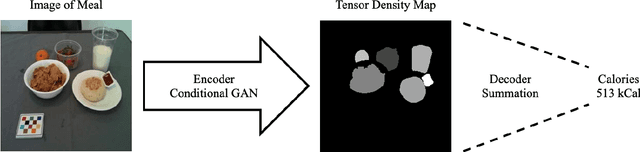

Dietary assessment is essential to maintaining a healthy lifestyle. Automatic image-based dietary assessment is a growing field of research due to the increasing prevalence of image capturing devices (e.g. mobile phones). In this work, we estimate food energy from a single monocular image, a difficult task due to the limited hard-to-extract amount of energy information present in an image. To do so, we employ an improved encoder-decoder framework for energy estimation; the encoder transforms the image into a representation embedded with food energy information in an easier-to-extract format, which the decoder then extracts the energy information from. To implement our method, we compile a high-quality food image dataset verified by registered dietitians containing eating scene images, food-item segmentation masks, and ground truth calorie values. Our method improves upon previous caloric estimation methods by over 10\% and 30 kCal in terms of MAPE and MAE respectively.
Bi-Modality Medical Image Synthesis Using Semi-Supervised Sequential Generative Adversarial Networks
Aug 29, 2023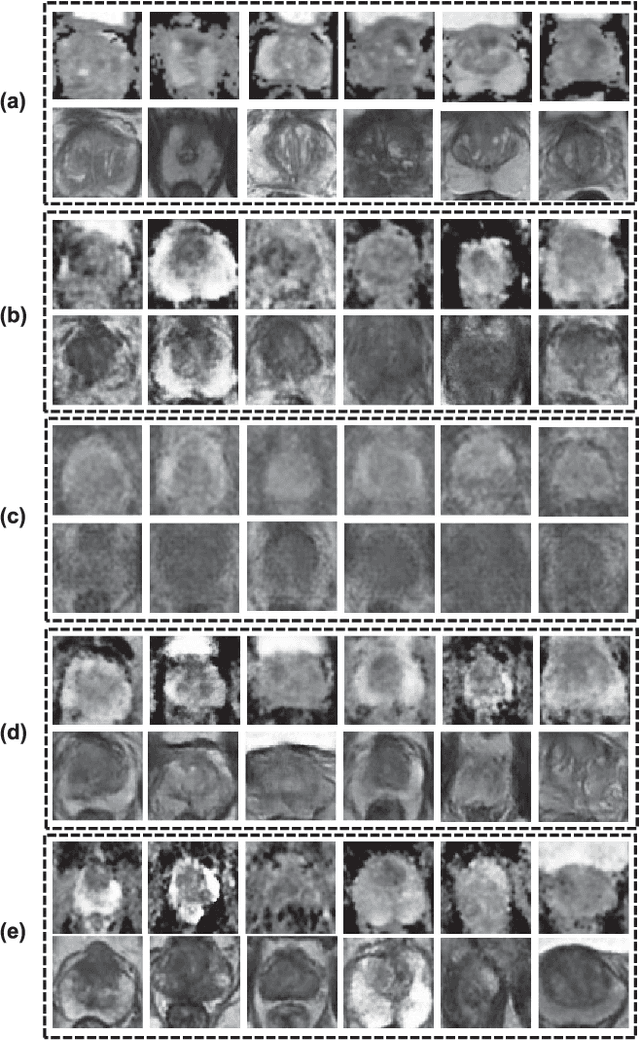
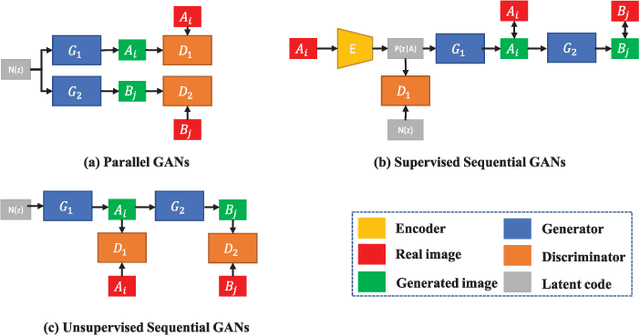
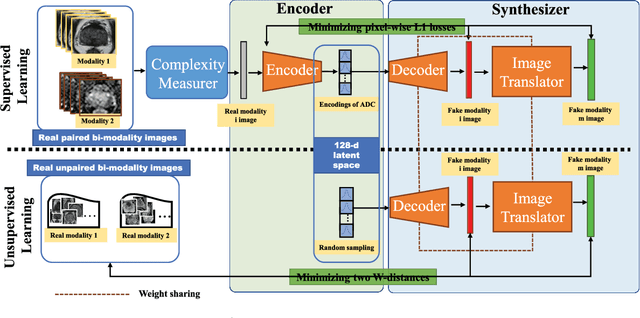
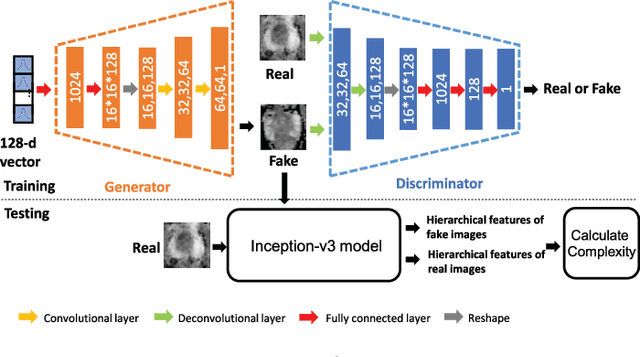
In this paper, we propose a bi-modality medical image synthesis approach based on sequential generative adversarial network (GAN) and semi-supervised learning. Our approach consists of two generative modules that synthesize images of the two modalities in a sequential order. A method for measuring the synthesis complexity is proposed to automatically determine the synthesis order in our sequential GAN. Images of the modality with a lower complexity are synthesized first, and the counterparts with a higher complexity are generated later. Our sequential GAN is trained end-to-end in a semi-supervised manner. In supervised training, the joint distribution of bi-modality images are learned from real paired images of the two modalities by explicitly minimizing the reconstruction losses between the real and synthetic images. To avoid overfitting limited training images, in unsupervised training, the marginal distribution of each modality is learned based on unpaired images by minimizing the Wasserstein distance between the distributions of real and fake images. We comprehensively evaluate the proposed model using two synthesis tasks based on three types of evaluate metrics and user studies. Visual and quantitative results demonstrate the superiority of our method to the state-of-the-art methods, and reasonable visual quality and clinical significance. Code is made publicly available at https://github.com/hustlinyi/Multimodal-Medical-Image-Synthesis.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023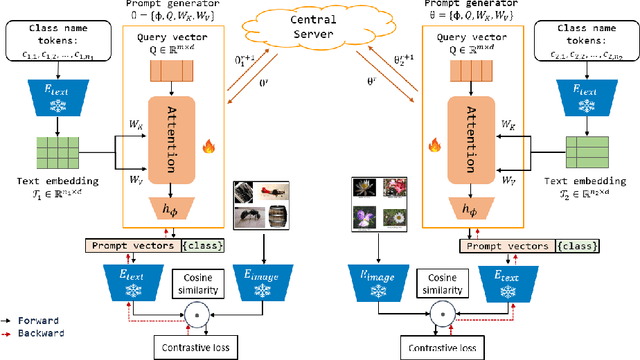
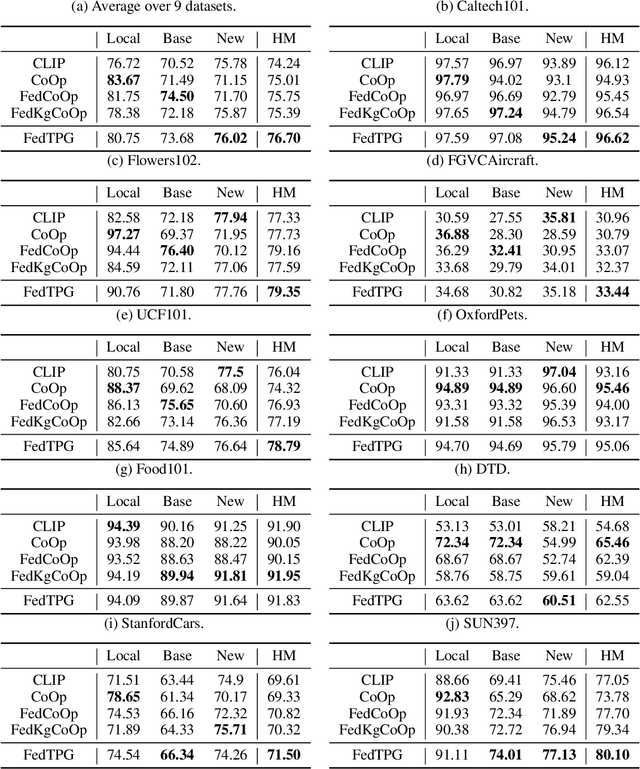
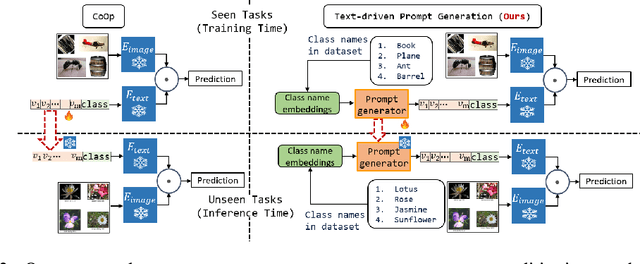
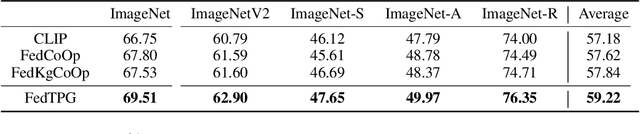
Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
Echocardiography video synthesis from end diastolic semantic map via diffusion model
Oct 11, 2023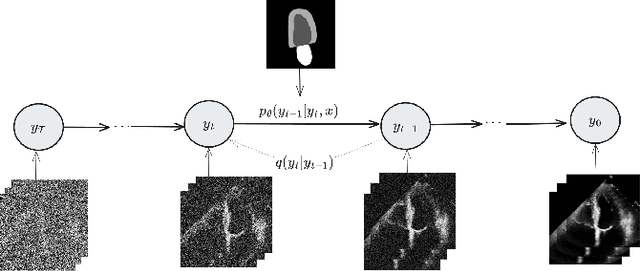
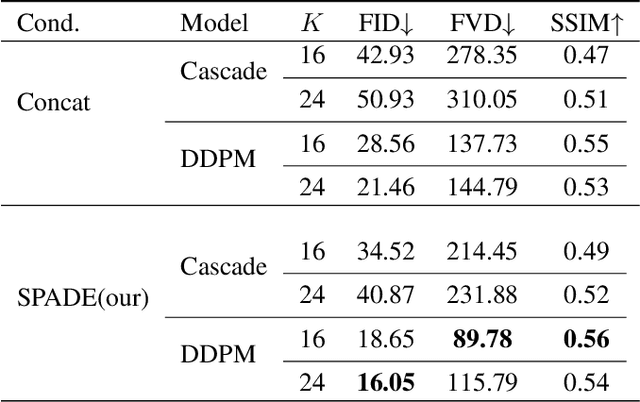
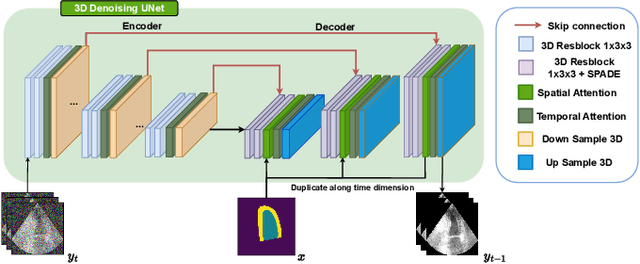
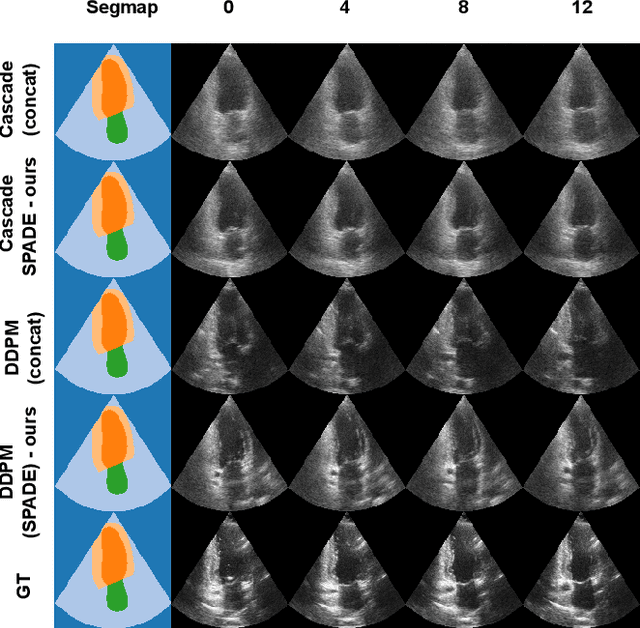
Denoising Diffusion Probabilistic Models (DDPMs) have demonstrated significant achievements in various image and video generation tasks, including the domain of medical imaging. However, generating echocardiography videos based on semantic anatomical information remains an unexplored area of research. This is mostly due to the constraints imposed by the currently available datasets, which lack sufficient scale and comprehensive frame-wise annotations for every cardiac cycle. This paper aims to tackle the aforementioned challenges by expanding upon existing video diffusion models for the purpose of cardiac video synthesis. More specifically, our focus lies in generating video using semantic maps of the initial frame during the cardiac cycle, commonly referred to as end diastole. To further improve the synthesis process, we integrate spatial adaptive normalization into multiscale feature maps. This enables the inclusion of semantic guidance during synthesis, resulting in enhanced realism and coherence of the resultant video sequences. Experiments are conducted on the CAMUS dataset, which is a highly used dataset in the field of echocardiography. Our model exhibits better performance compared to the standard diffusion technique in terms of multiple metrics, including FID, FVD, and SSMI.
Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling
Oct 11, 2023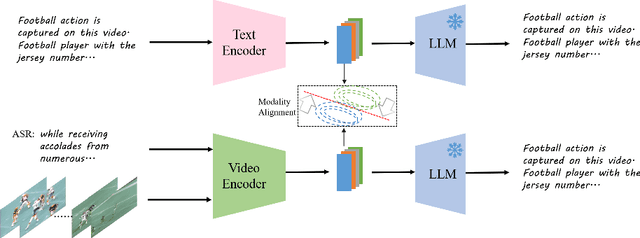
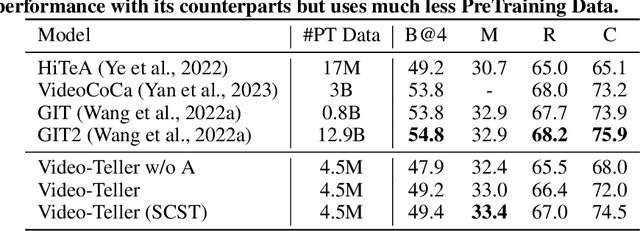
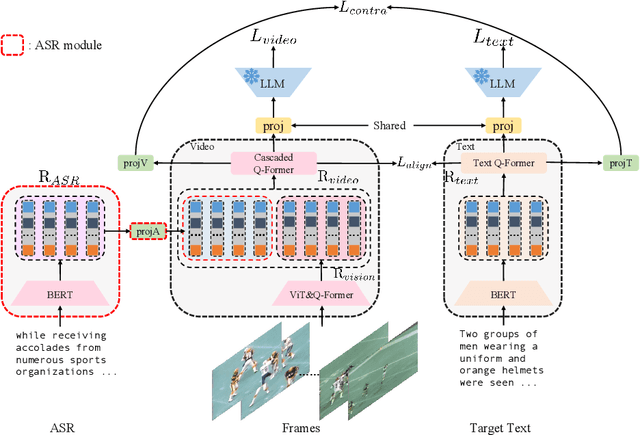

This paper proposes Video-Teller, a video-language foundation model that leverages multi-modal fusion and fine-grained modality alignment to significantly enhance the video-to-text generation task. Video-Teller boosts the training efficiency by utilizing frozen pretrained vision and language modules. It capitalizes on the robust linguistic capabilities of large language models, enabling the generation of both concise and elaborate video descriptions. To effectively integrate visual and auditory information, Video-Teller builds upon the image-based BLIP-2 model and introduces a cascaded Q-Former which fuses information across frames and ASR texts. To better guide video summarization, we introduce a fine-grained modality alignment objective, where the cascaded Q-Former's output embedding is trained to align with the caption/summary embedding created by a pretrained text auto-encoder. Experimental results demonstrate the efficacy of our proposed video-language foundation model in accurately comprehending videos and generating coherent and precise language descriptions. It is worth noting that the fine-grained alignment enhances the model's capabilities (4% improvement of CIDEr score on MSR-VTT) with only 13% extra parameters in training and zero additional cost in inference.
Microscopy Image Segmentation via Point and Shape Regularized Data Synthesis
Aug 18, 2023Current deep learning-based approaches for the segmentation of microscopy images heavily rely on large amount of training data with dense annotation, which is highly costly and laborious in practice. Compared to full annotation where the complete contour of objects is depicted, point annotations, specifically object centroids, are much easier to acquire and still provide crucial information about the objects for subsequent segmentation. In this paper, we assume access to point annotations only during training and develop a unified pipeline for microscopy image segmentation using synthetically generated training data. Our framework includes three stages: (1) it takes point annotations and samples a pseudo dense segmentation mask constrained with shape priors; (2) with an image generative model trained in an unpaired manner, it translates the mask to a realistic microscopy image regularized by object level consistency; (3) the pseudo masks along with the synthetic images then constitute a pairwise dataset for training an ad-hoc segmentation model. On the public MoNuSeg dataset, our synthesis pipeline produces more diverse and realistic images than baseline models while maintaining high coherence between input masks and generated images. When using the identical segmentation backbones, the models trained on our synthetic dataset significantly outperform those trained with pseudo-labels or baseline-generated images. Moreover, our framework achieves comparable results to models trained on authentic microscopy images with dense labels, demonstrating its potential as a reliable and highly efficient alternative to labor-intensive manual pixel-wise annotations in microscopy image segmentation. The code is available.
CMISR: Circular Medical Image Super-Resolution
Aug 15, 2023
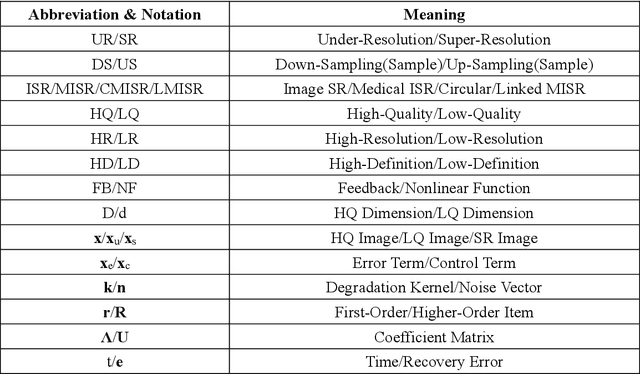
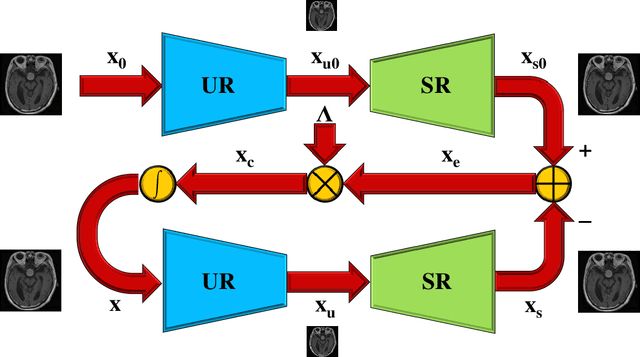
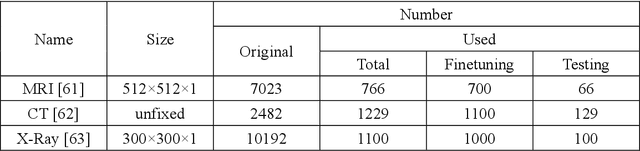
Classical methods of medical image super-resolution (MISR) utilize open-loop architecture with implicit under-resolution (UR) unit and explicit super-resolution (SR) unit. The UR unit can always be given, assumed, or estimated, while the SR unit is elaborately designed according to various SR algorithms. The closed-loop feedback mechanism is widely employed in current MISR approaches and can efficiently improve their performance. The feedback mechanism may be divided into two categories: local and global feedback. Therefore, this paper proposes a global feedback-based closed-cycle framework, circular MISR (CMISR), with unambiguous UR and SR elements. Mathematical model and closed-loop equation of CMISR are built. Mathematical proof with Taylor-series approximation indicates that CMISR has zero recovery error in steady-state. In addition, CMISR holds plug-and-play characteristic which can be established on any existing MISR algorithms. Five CMISR algorithms are respectively proposed based on the state-of-the-art open-loop MISR algorithms. Experimental results with three scale factors and on three open medical image datasets show that CMISR is superior to MISR in reconstruction performance and is particularly suited to medical images with strong edges or intense contrast.
Tackling VQA with Pretrained Foundation Models without Further Training
Sep 27, 2023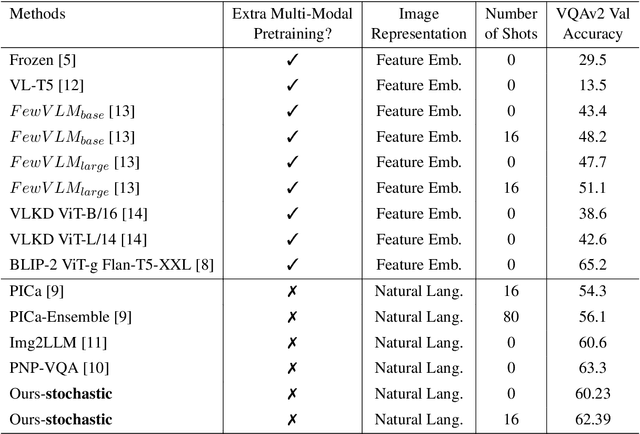
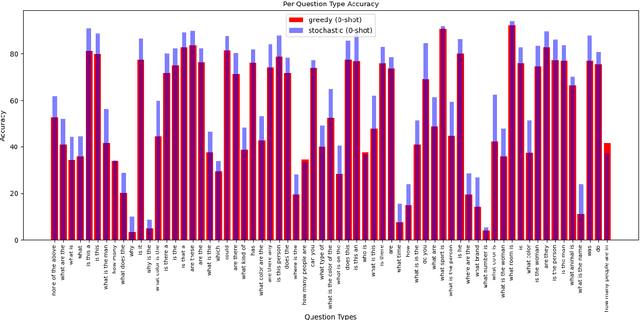
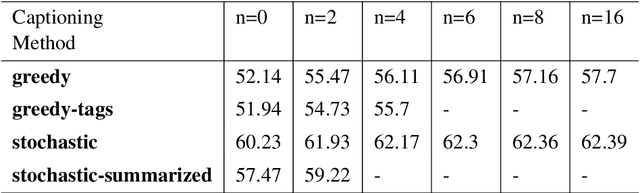
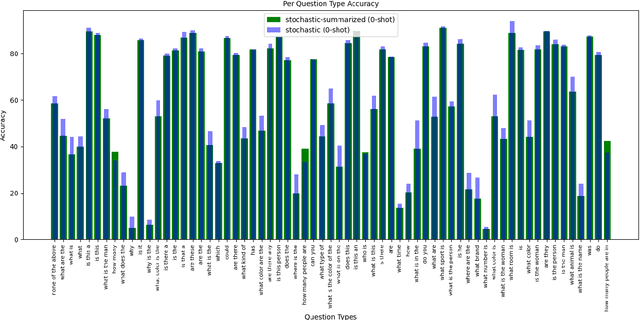
Large language models (LLMs) have achieved state-of-the-art results in many natural language processing tasks. They have also demonstrated ability to adapt well to different tasks through zero-shot or few-shot settings. With the capability of these LLMs, researchers have looked into how to adopt them for use with Visual Question Answering (VQA). Many methods require further training to align the image and text embeddings. However, these methods are computationally expensive and requires large scale image-text dataset for training. In this paper, we explore a method of combining pretrained LLMs and other foundation models without further training to solve the VQA problem. The general idea is to use natural language to represent the images such that the LLM can understand the images. We explore different decoding strategies for generating textual representation of the image and evaluate their performance on the VQAv2 dataset.
Jurassic World Remake: Bringing Ancient Fossils Back to Life via Zero-Shot Long Image-to-Image Translation
Aug 14, 2023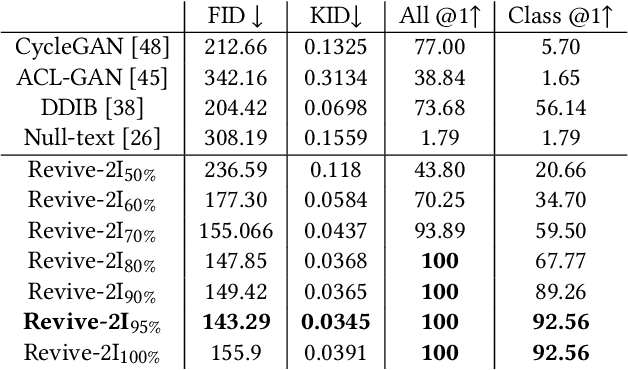
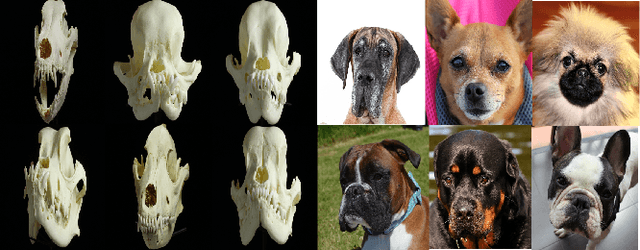
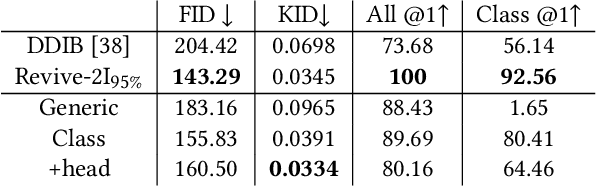
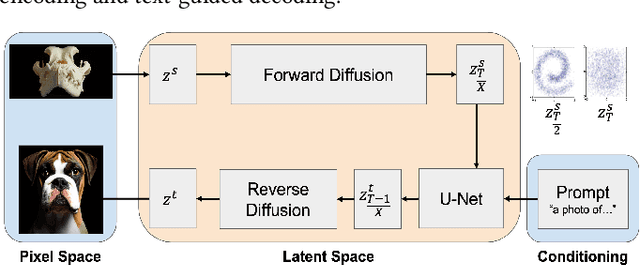
With a strong understanding of the target domain from natural language, we produce promising results in translating across large domain gaps and bringing skeletons back to life. In this work, we use text-guided latent diffusion models for zero-shot image-to-image translation (I2I) across large domain gaps (longI2I), where large amounts of new visual features and new geometry need to be generated to enter the target domain. Being able to perform translations across large domain gaps has a wide variety of real-world applications in criminology, astrology, environmental conservation, and paleontology. In this work, we introduce a new task Skull2Animal for translating between skulls and living animals. On this task, we find that unguided Generative Adversarial Networks (GANs) are not capable of translating across large domain gaps. Instead of these traditional I2I methods, we explore the use of guided diffusion and image editing models and provide a new benchmark model, Revive-2I, capable of performing zero-shot I2I via text-prompting latent diffusion models. We find that guidance is necessary for longI2I because, to bridge the large domain gap, prior knowledge about the target domain is needed. In addition, we find that prompting provides the best and most scalable information about the target domain as classifier-guided diffusion models require retraining for specific use cases and lack stronger constraints on the target domain because of the wide variety of images they are trained on.
Deshadow-Anything: When Segment Anything Model Meets Zero-shot shadow removal
Sep 21, 2023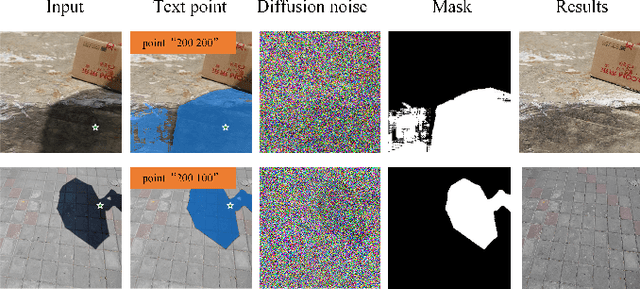
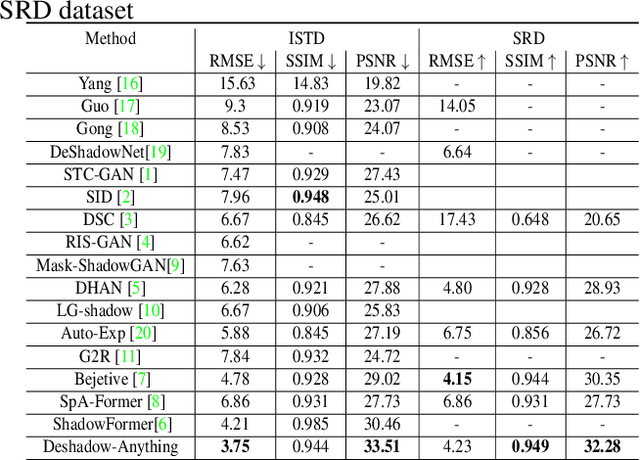
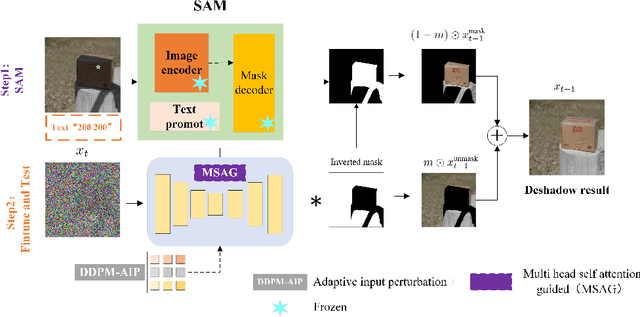

Segment Anything (SAM), an advanced universal image segmentation model trained on an expansive visual dataset, has set a new benchmark in image segmentation and computer vision. However, it faced challenges when it came to distinguishing between shadows and their backgrounds. To address this, we developed Deshadow-Anything, considering the generalization of large-scale datasets, and we performed Fine-tuning on large-scale datasets to achieve image shadow removal. The diffusion model can diffuse along the edges and textures of an image, helping to remove shadows while preserving the details of the image. Furthermore, we design Multi-Self-Attention Guidance (MSAG) and adaptive input perturbation (DDPM-AIP) to accelerate the iterative training speed of diffusion. Experiments on shadow removal tasks demonstrate that these methods can effectively improve image restoration performance.