 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intelligent Software Tooling for Improving Software Development
Oct 17, 2023
Software has eaten the world with many of the necessities and quality of life services people use requiring software. Therefore, tools that improve the software development experience can have a significant impact on the world such as generating code and test cases, detecting bugs, question and answering, etc., The success of Deep Learning (DL) over the past decade has shown huge advancements in automation across many domains, including Software Development processes. One of the main reasons behind this success is the availability of large datasets such as open-source code available through GitHub or image datasets of mobile Graphical User Interfaces (GUIs) with RICO and ReDRAW to be trained on. Therefore, the central research question my dissertation explores is: In what ways can the software development process be improved through leveraging DL techniques on the vast amounts of unstructured software engineering artifacts?
Real-Fake: Effective Training Data Synthesis Through Distribution Matching
Oct 16, 2023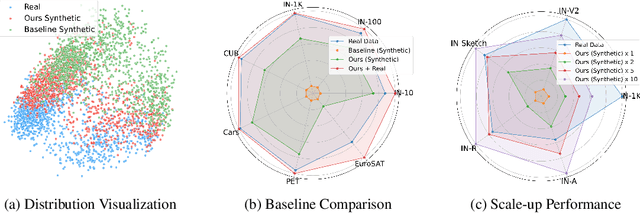
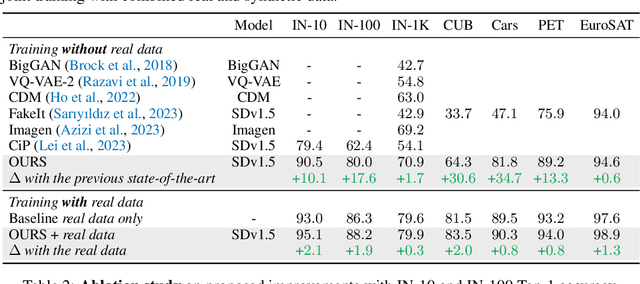
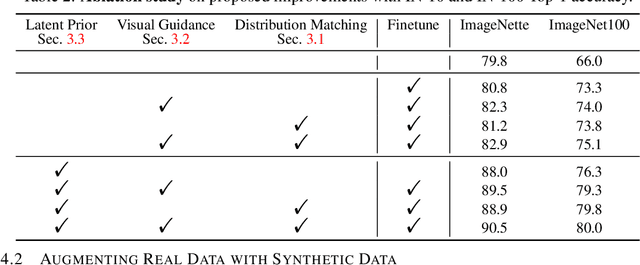
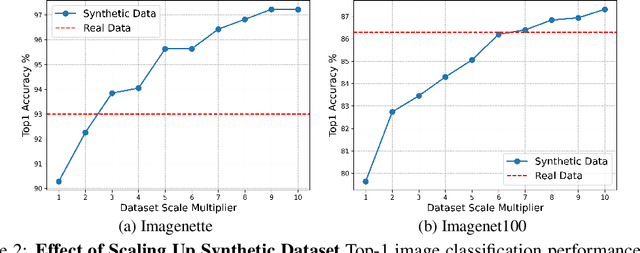
Synthetic training data has gained prominence in numerous learning tasks and scenarios, offering advantages such as dataset augmentation, generalization evaluation, and privacy preservation. Despite these benefits, the efficiency of synthetic data generated by current methodologies remains inferior when training advanced deep models exclusively, limiting its practical utility. To address this challenge, we analyze the principles underlying training data synthesis for supervised learning and elucidate a principled theoretical framework from the distribution-matching perspective that explicates the mechanisms governing synthesis efficacy. Through extensive experiments, we demonstrate the effectiveness of our synthetic data across diverse image classification tasks, both as a replacement for and augmentation to real datasets, while also benefits challenging tasks such as out-of-distribution generalization and privacy preservation.
Conditional Diffusion Distillation
Oct 02, 2023
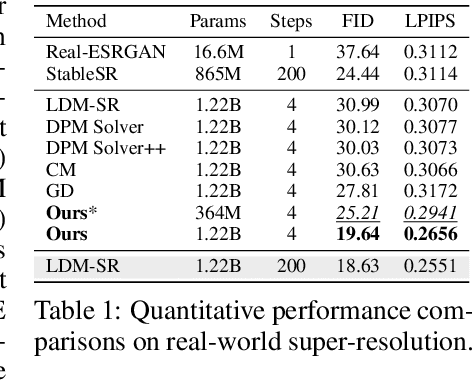
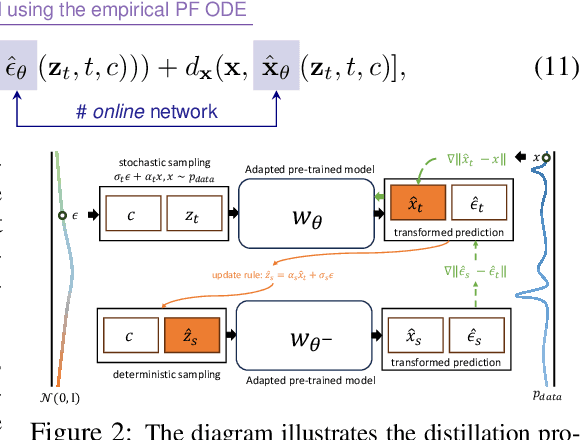

Generative diffusion models provide strong priors for text-to-image generation and thereby serve as a foundation for conditional generation tasks such as image editing, restoration, and super-resolution. However, one major limitation of diffusion models is their slow sampling time. To address this challenge, we present a novel conditional distillation method designed to supplement the diffusion priors with the help of image conditions, allowing for conditional sampling with very few steps. We directly distill the unconditional pre-training in a single stage through joint-learning, largely simplifying the previous two-stage procedures that involve both distillation and conditional finetuning separately. Furthermore, our method enables a new parameter-efficient distillation mechanism that distills each task with only a small number of additional parameters combined with the shared frozen unconditional backbone. Experiments across multiple tasks including super-resolution, image editing, and depth-to-image generation demonstrate that our method outperforms existing distillation techniques for the same sampling time. Notably, our method is the first distillation strategy that can match the performance of the much slower fine-tuned conditional diffusion models.
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 29, 2023

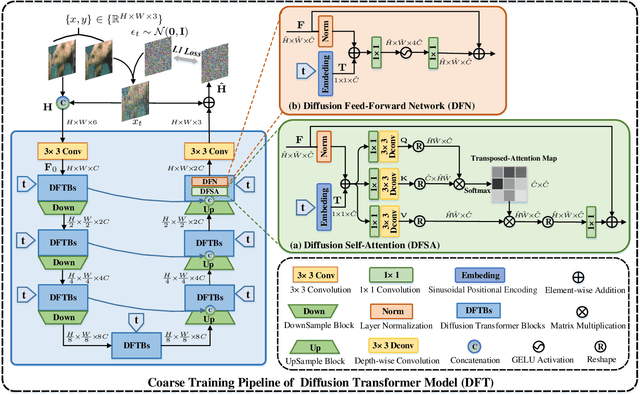
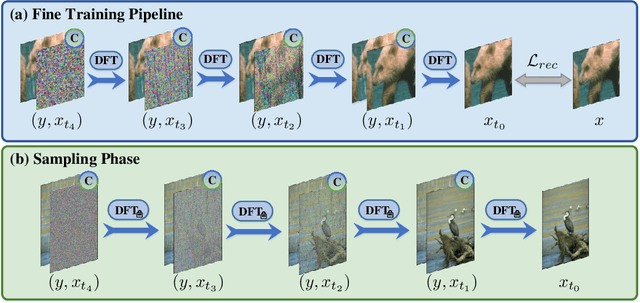
Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising. The code is available at https://github.com/wlydlut/C2F-DFT.
Fast 2D Bicephalous Convolutional Autoencoder for Compressing 3D Time Projection Chamber Data
Oct 23, 2023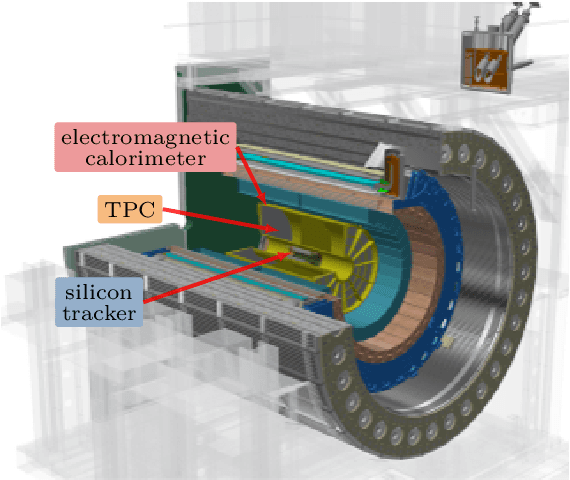
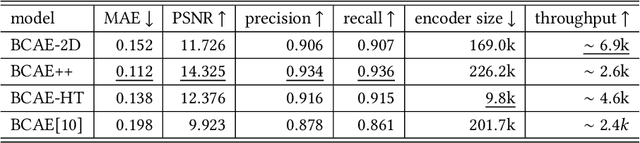
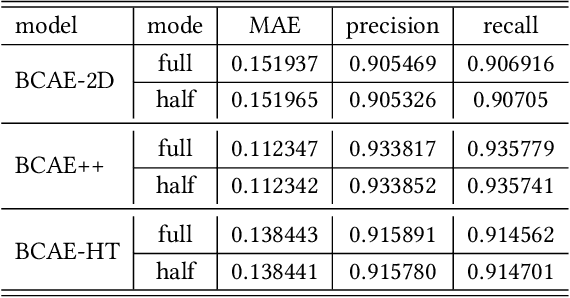
High-energy large-scale particle colliders produce data at high speed in the order of 1 terabytes per second in nuclear physics and petabytes per second in high-energy physics. Developing real-time data compression algorithms to reduce such data at high throughput to fit permanent storage has drawn increasing attention. Specifically, at the newly constructed sPHENIX experiment at the Relativistic Heavy Ion Collider (RHIC), a time projection chamber is used as the main tracking detector, which records particle trajectories in a volume of a three-dimensional (3D) cylinder. The resulting data are usually very sparse with occupancy around 10.8%. Such sparsity presents a challenge to conventional learning-free lossy compression algorithms, such as SZ, ZFP, and MGARD. The 3D convolutional neural network (CNN)-based approach, Bicephalous Convolutional Autoencoder (BCAE), outperforms traditional methods both in compression rate and reconstruction accuracy. BCAE can also utilize the computation power of graphical processing units suitable for deployment in a modern heterogeneous high-performance computing environment. This work introduces two BCAE variants: BCAE++ and BCAE-2D. BCAE++ achieves a 15% better compression ratio and a 77% better reconstruction accuracy measured in mean absolute error compared with BCAE. BCAE-2D treats the radial direction as the channel dimension of an image, resulting in a 3x speedup in compression throughput. In addition, we demonstrate an unbalanced autoencoder with a larger decoder can improve reconstruction accuracy without significantly sacrificing throughput. Lastly, we observe both the BCAE++ and BCAE-2D can benefit more from using half-precision mode in throughput (76-79% increase) without loss in reconstruction accuracy. The source code and links to data and pretrained models can be found at https://github.com/BNL-DAQ-LDRD/NeuralCompression_v2.
A flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023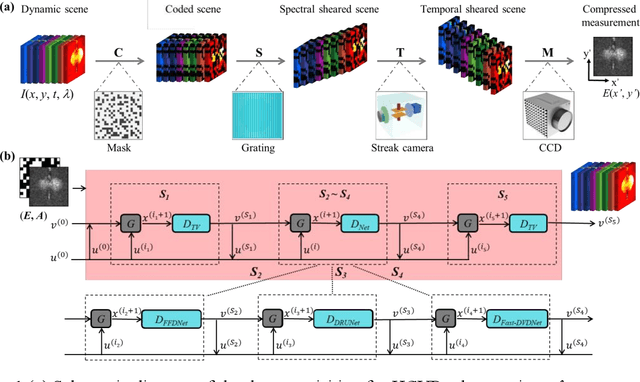
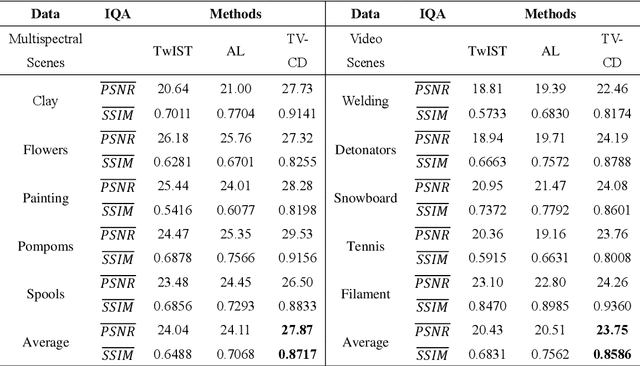
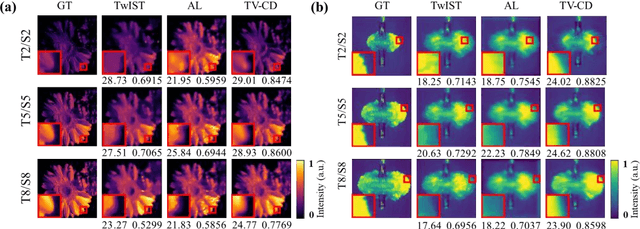
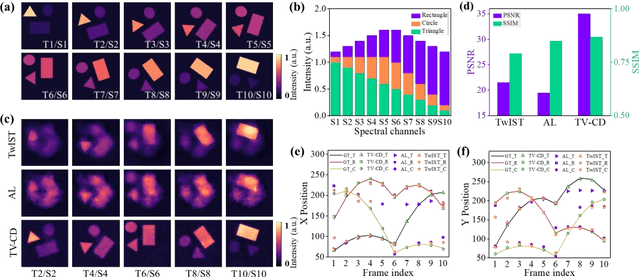
Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
Equivariant Bootstrapping for Uncertainty Quantification in Imaging Inverse Problems
Oct 20, 2023Scientific imaging problems are often severely ill-posed, and hence have significant intrinsic uncertainty. Accurately quantifying the uncertainty in the solutions to such problems is therefore critical for the rigorous interpretation of experimental results as well as for reliably using the reconstructed images as scientific evidence. Unfortunately, existing imaging methods are unable to quantify the uncertainty in the reconstructed images in a manner that is robust to experiment replications. This paper presents a new uncertainty quantification methodology based on an equivariant formulation of the parametric bootstrap algorithm that leverages symmetries and invariance properties commonly encountered in imaging problems. Additionally, the proposed methodology is general and can be easily applied with any image reconstruction technique, including unsupervised training strategies that can be trained from observed data alone, thus enabling uncertainty quantification in situations where there is no ground truth data available. We demonstrate the proposed approach with a series of numerical experiments and through comparisons with alternative uncertainty quantification strategies from the state-of-the-art, such as Bayesian strategies involving score-based diffusion models and Langevin samplers. In all our experiments, the proposed method delivers remarkably accurate high-dimensional confidence regions and outperforms the competing approaches in terms of estimation accuracy, uncertainty quantification accuracy, and computing time.
DIG-MILP: a Deep Instance Generator for Mixed-Integer Linear Programming with Feasibility Guarantee
Oct 20, 2023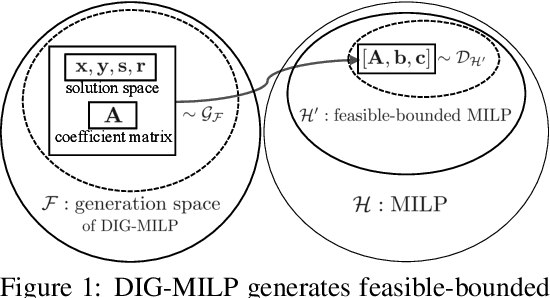

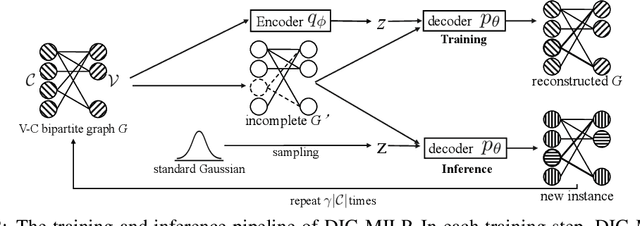

Mixed-integer linear programming (MILP) stands as a notable NP-hard problem pivotal to numerous crucial industrial applications. The development of effective algorithms, the tuning of solvers, and the training of machine learning models for MILP resolution all hinge on access to extensive, diverse, and representative data. Yet compared to the abundant naturally occurring data in image and text realms, MILP is markedly data deficient, underscoring the vital role of synthetic MILP generation. We present DIG-MILP, a deep generative framework based on variational auto-encoder (VAE), adept at extracting deep-level structural features from highly limited MILP data and producing instances that closely mirror the target data. Notably, by leveraging the MILP duality, DIG-MILP guarantees a correct and complete generation space as well as ensures the boundedness and feasibility of the generated instances. Our empirical study highlights the novelty and quality of the instances generated by DIG-MILP through two distinct downstream tasks: (S1) Data sharing, where solver solution times correlate highly positive between original and DIG-MILP-generated instances, allowing data sharing for solver tuning without publishing the original data; (S2) Data Augmentation, wherein the DIG-MILP-generated instances bolster the generalization performance of machine learning models tasked with resolving MILP problems.
S4C: Self-Supervised Semantic Scene Completion with Neural Fields
Oct 12, 2023


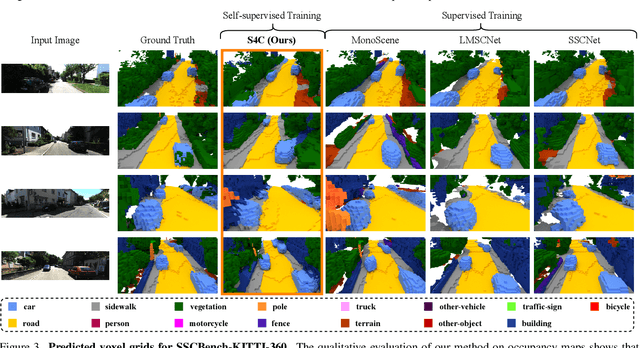
3D semantic scene understanding is a fundamental challenge in computer vision. It enables mobile agents to autonomously plan and navigate arbitrary environments. SSC formalizes this challenge as jointly estimating dense geometry and semantic information from sparse observations of a scene. Current methods for SSC are generally trained on 3D ground truth based on aggregated LiDAR scans. This process relies on special sensors and annotation by hand which are costly and do not scale well. To overcome this issue, our work presents the first self-supervised approach to SSC called S4C that does not rely on 3D ground truth data. Our proposed method can reconstruct a scene from a single image and only relies on videos and pseudo segmentation ground truth generated from off-the-shelf image segmentation network during training. Unlike existing methods, which use discrete voxel grids, we represent scenes as implicit semantic fields. This formulation allows querying any point within the camera frustum for occupancy and semantic class. Our architecture is trained through rendering-based self-supervised losses. Nonetheless, our method achieves performance close to fully supervised state-of-the-art methods. Additionally, our method demonstrates strong generalization capabilities and can synthesize accurate segmentation maps for far away viewpoints.
ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
Oct 12, 2023

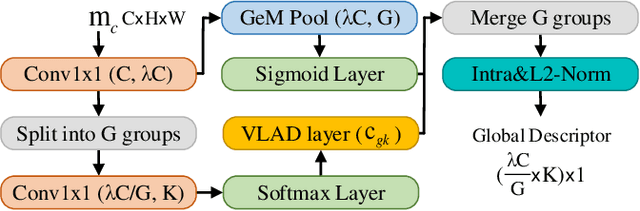
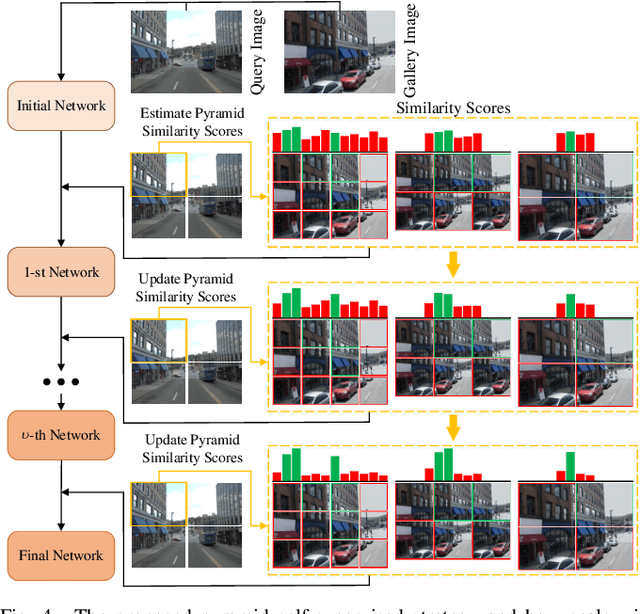
Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.