 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning based Image Watermarking: A Brief Survey
Aug 08, 2023
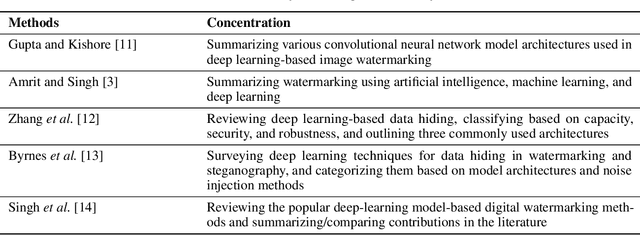
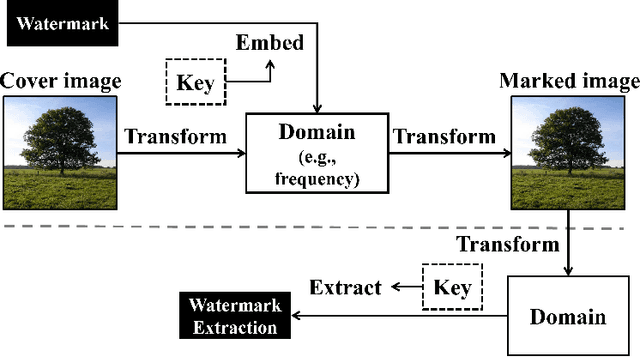
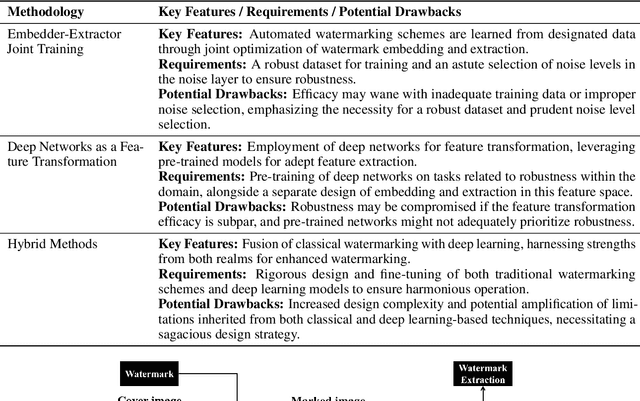
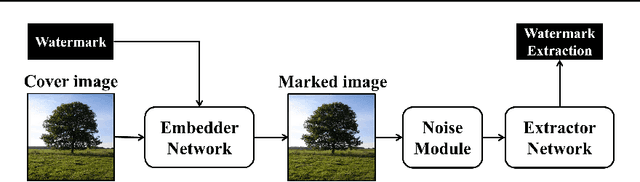
The act of secretly embedding and extracting a watermark on a cover image to protect it is known as image watermarking. In recent years, deep learning-based image watermarking techniques have been emerging one after another. To study the state-of-the-art, this survey categorizes cutting-edge deep learning-based image watermarking techniques into Embedder-Extractor Joint Training, Deep Networks as a Feature Transformation, and Hybrid schemes. Research directions in each category are also analyzed and summarized. Additionally, potential future research directions are discussed to envision future studies.
Towards Open-World Co-Salient Object Detection with Generative Uncertainty-aware Group Selective Exchange-Masking
Oct 16, 2023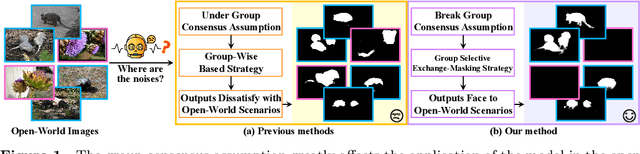
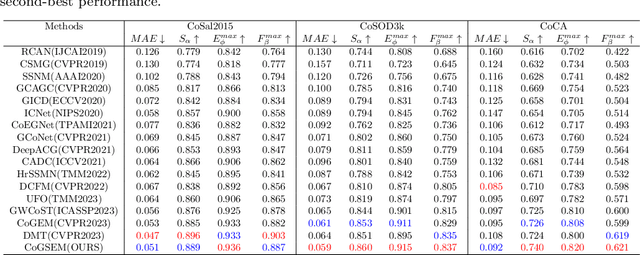
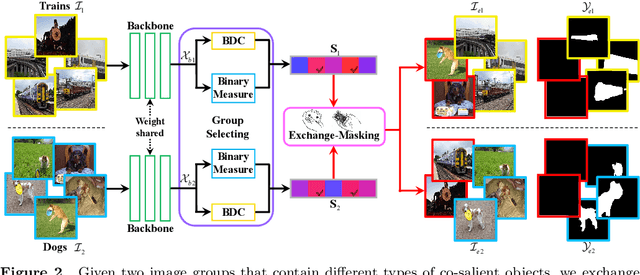
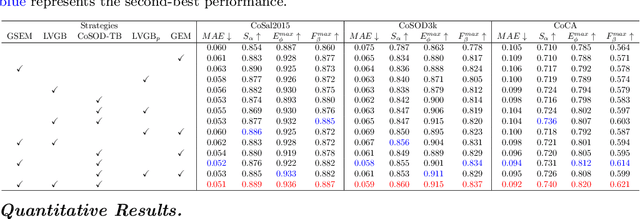
The traditional definition of co-salient object detection (CoSOD) task is to segment the common salient objects in a group of relevant images. This definition is based on an assumption of group consensus consistency that is not always reasonable in the open-world setting, which results in robustness issue in the model when dealing with irrelevant images in the inputting image group under the open-word scenarios. To tackle this problem, we introduce a group selective exchange-masking (GSEM) approach for enhancing the robustness of the CoSOD model. GSEM takes two groups of images as input, each containing different types of salient objects. Based on the mixed metric we designed, GSEM selects a subset of images from each group using a novel learning-based strategy, then the selected images are exchanged. To simultaneously consider the uncertainty introduced by irrelevant images and the consensus features of the remaining relevant images in the group, we designed a latent variable generator branch and CoSOD transformer branch. The former is composed of a vector quantised-variational autoencoder to generate stochastic global variables that model uncertainty. The latter is designed to capture correlation-based local features that include group consensus. Finally, the outputs of the two branches are merged and passed to a transformer-based decoder to generate robust predictions. Taking into account that there are currently no benchmark datasets specifically designed for open-world scenarios, we constructed three open-world benchmark datasets, namely OWCoSal, OWCoSOD, and OWCoCA, based on existing datasets. By breaking the group-consistency assumption, these datasets provide effective simulations of real-world scenarios and can better evaluate the robustness and practicality of models.
Enhancing Medical Image Segmentation: Optimizing Cross-Entropy Weights and Post-Processing with Autoencoders
Aug 21, 2023
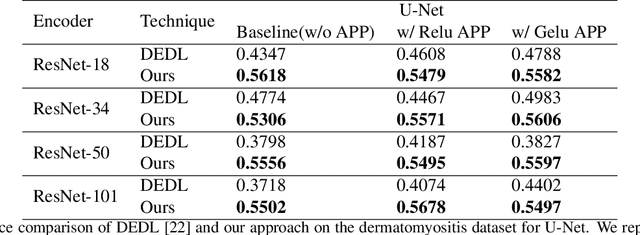
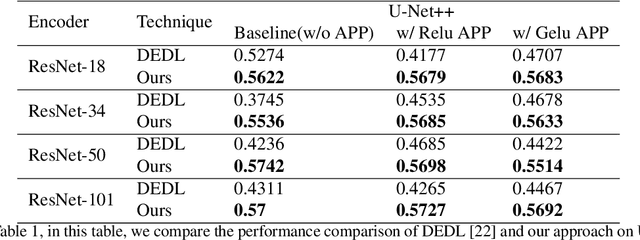
The task of medical image segmentation presents unique challenges, necessitating both localized and holistic semantic understanding to accurately delineate areas of interest, such as critical tissues or aberrant features. This complexity is heightened in medical image segmentation due to the high degree of inter-class similarities, intra-class variations, and possible image obfuscation. The segmentation task further diversifies when considering the study of histopathology slides for autoimmune diseases like dermatomyositis. The analysis of cell inflammation and interaction in these cases has been less studied due to constraints in data acquisition pipelines. Despite the progressive strides in medical science, we lack a comprehensive collection of autoimmune diseases. As autoimmune diseases globally escalate in prevalence and exhibit associations with COVID-19, their study becomes increasingly essential. While there is existing research that integrates artificial intelligence in the analysis of various autoimmune diseases, the exploration of dermatomyositis remains relatively underrepresented. In this paper, we present a deep-learning approach tailored for Medical image segmentation. Our proposed method outperforms the current state-of-the-art techniques by an average of 12.26% for U-Net and 12.04% for U-Net++ across the ResNet family of encoders on the dermatomyositis dataset. Furthermore, we probe the importance of optimizing loss function weights and benchmark our methodology on three challenging medical image segmentation tasks
MVC: A Multi-Task Vision Transformer Network for COVID-19 Diagnosis from Chest X-ray Images
Sep 30, 2023Medical image analysis using computer-based algorithms has attracted considerable attention from the research community and achieved tremendous progress in the last decade. With recent advances in computing resources and availability of large-scale medical image datasets, many deep learning models have been developed for disease diagnosis from medical images. However, existing techniques focus on sub-tasks, e.g., disease classification and identification, individually, while there is a lack of a unified framework enabling multi-task diagnosis. Inspired by the capability of Vision Transformers in both local and global representation learning, we propose in this paper a new method, namely Multi-task Vision Transformer (MVC) for simultaneously classifying chest X-ray images and identifying affected regions from the input data. Our method is built upon the Vision Transformer but extends its learning capability in a multi-task setting. We evaluated our proposed method and compared it with existing baselines on a benchmark dataset of COVID-19 chest X-ray images. Experimental results verified the superiority of the proposed method over the baselines on both the image classification and affected region identification tasks.
Generating Image-Specific Text Improves Fine-grained Image Classification
Jul 21, 2023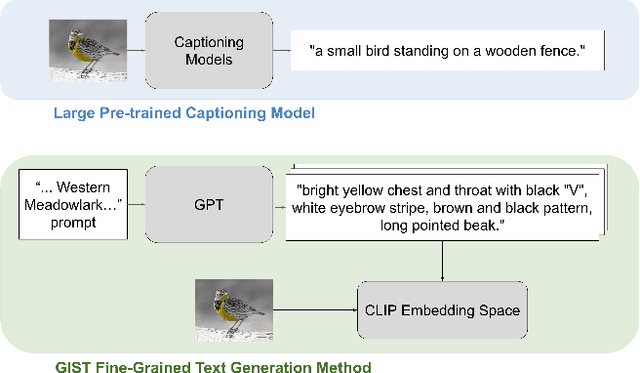
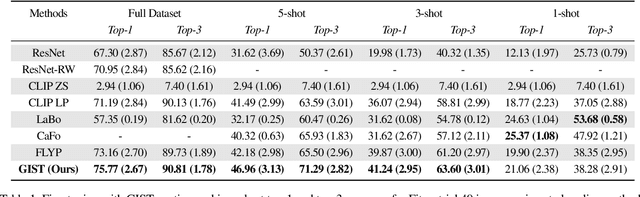
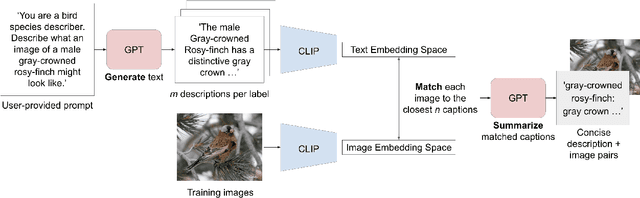
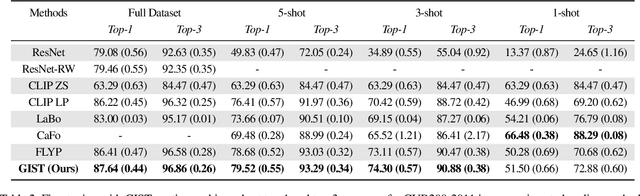
Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.
Noisy-Correspondence Learning for Text-to-Image Person Re-identification
Aug 19, 2023
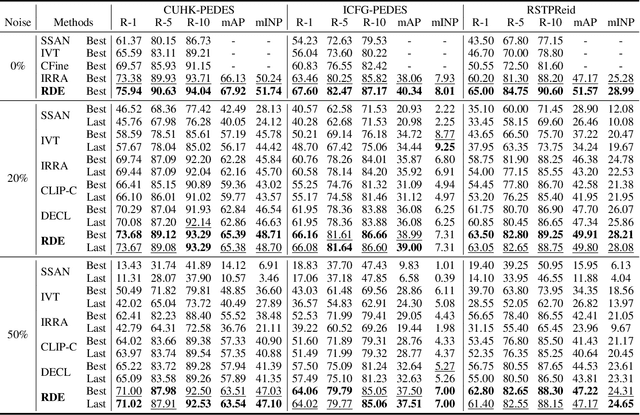
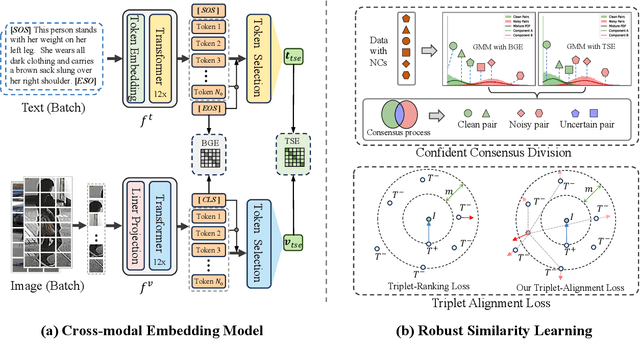
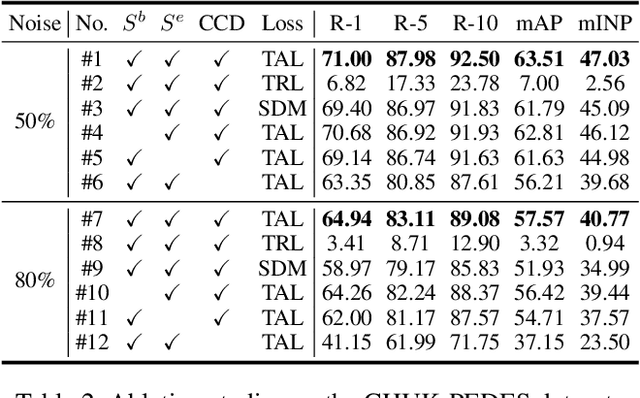
Text-to-image person re-identification (TIReID) is a compelling topic in the cross-modal community, which aims to retrieve the target person based on a textual query. Although numerous TIReID methods have been proposed and achieved promising performance, they implicitly assume the training image-text pairs are correctly aligned, which is not always the case in real-world scenarios. In practice, the image-text pairs inevitably exist under-correlated or even false-correlated, a.k.a noisy correspondence (NC), due to the low quality of the images and annotation errors. To address this problem, we propose a novel Robust Dual Embedding method (RDE) that can learn robust visual-semantic associations even with NC. Specifically, RDE consists of two main components: 1) A Confident Consensus Division (CCD) module that leverages the dual-grained decisions of dual embedding modules to obtain a consensus set of clean training data, which enables the model to learn correct and reliable visual-semantic associations. 2) A Triplet-Alignment Loss (TAL) relaxes the conventional triplet-ranking loss with hardest negatives, which tends to rapidly overfit NC, to a log-exponential upper bound over all negatives, thus preventing the model from overemphasizing false image-text pairs. We conduct extensive experiments on three public benchmarks, namely CUHK-PEDES, ICFG-PEDES, and RSTPReID, to evaluate the performance and robustness of our RDE. Our method achieves state-of-the-art results both with and without synthetic noisy correspondences on all three datasets.
Self-Sampling Meta SAM: Enhancing Few-shot Medical Image Segmentation with Meta-Learning
Sep 01, 2023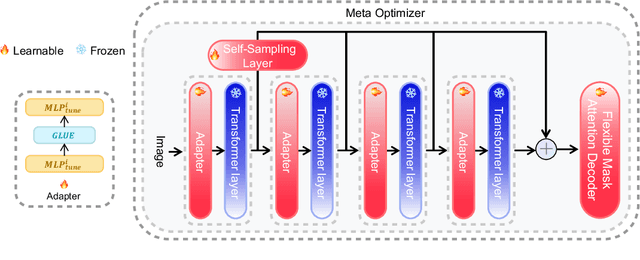
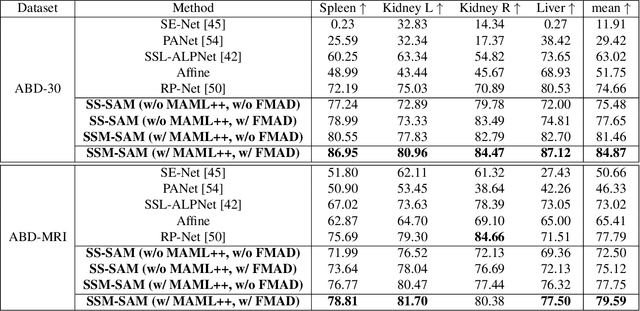
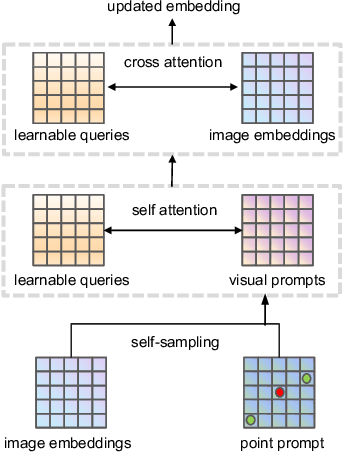
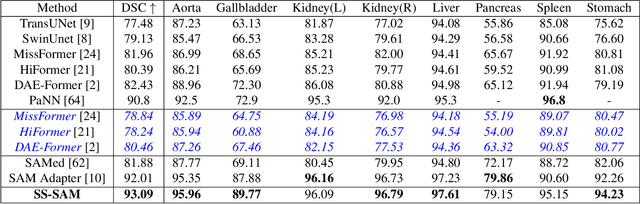
While the Segment Anything Model (SAM) excels in semantic segmentation for general-purpose images, its performance significantly deteriorates when applied to medical images, primarily attributable to insufficient representation of medical images in its training dataset. Nonetheless, gathering comprehensive datasets and training models that are universally applicable is particularly challenging due to the long-tail problem common in medical images. To address this gap, here we present a Self-Sampling Meta SAM (SSM-SAM) framework for few-shot medical image segmentation. Our innovation lies in the design of three key modules: 1) An online fast gradient descent optimizer, further optimized by a meta-learner, which ensures swift and robust adaptation to new tasks. 2) A Self-Sampling module designed to provide well-aligned visual prompts for improved attention allocation; and 3) A robust attention-based decoder specifically designed for medical few-shot learning to capture relationship between different slices. Extensive experiments on a popular abdominal CT dataset and an MRI dataset demonstrate that the proposed method achieves significant improvements over state-of-the-art methods in few-shot segmentation, with an average improvements of 10.21% and 1.80% in terms of DSC, respectively. In conclusion, we present a novel approach for rapid online adaptation in interactive image segmentation, adapting to a new organ in just 0.83 minutes. Code is publicly available on GitHub upon acceptance.
Self-supervised visual learning for analyzing firearms trafficking activities on the Web
Oct 12, 2023Automated visual firearms classification from RGB images is an important real-world task with applications in public space security, intelligence gathering and law enforcement investigations. When applied to images massively crawled from the World Wide Web (including social media and dark Web sites), it can serve as an important component of systems that attempt to identify criminal firearms trafficking networks, by analyzing Big Data from open-source intelligence. Deep Neural Networks (DNN) are the state-of-the-art methodology for achieving this, with Convolutional Neural Networks (CNN) being typically employed. The common transfer learning approach consists of pretraining on a large-scale, generic annotated dataset for whole-image classification, such as ImageNet-1k, and then finetuning the DNN on a smaller, annotated, task-specific, downstream dataset for visual firearms classification. Neither Visual Transformer (ViT) neural architectures nor Self-Supervised Learning (SSL) approaches have been so far evaluated on this critical task. SSL essentially consists of replacing the traditional supervised pretraining objective with an unsupervised pretext task that does not require ground-truth labels..
Neural Diffusion Models
Oct 12, 2023



Diffusion models have shown remarkable performance on many generative tasks. Despite recent success, most diffusion models are restricted in that they only allow linear transformation of the data distribution. In contrast, broader family of transformations can potentially help train generative distributions more efficiently, simplifying the reverse process and closing the gap between the true negative log-likelihood and the variational approximation. In this paper, we present Neural Diffusion Models (NDMs), a generalization of conventional diffusion models that enables defining and learning time-dependent non-linear transformations of data. We show how to optimise NDMs using a variational bound in a simulation-free setting. Moreover, we derive a time-continuous formulation of NDMs, which allows fast and reliable inference using off-the-shelf numerical ODE and SDE solvers. Finally, we demonstrate the utility of NDMs with learnable transformations through experiments on standard image generation benchmarks, including CIFAR-10, downsampled versions of ImageNet and CelebA-HQ. NDMs outperform conventional diffusion models in terms of likelihood and produce high-quality samples.
Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP
Oct 02, 2023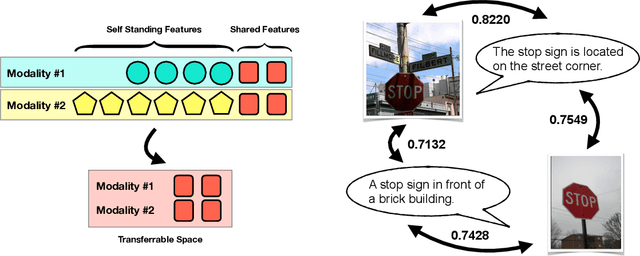

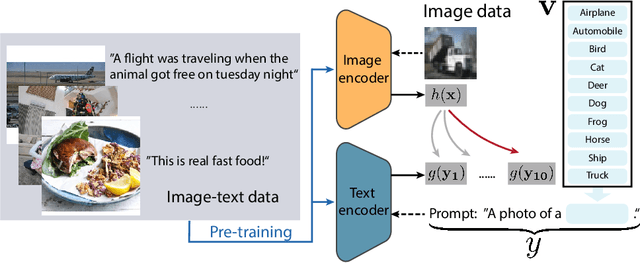

Multi-modal learning has become increasingly popular due to its ability to leverage information from different data sources (e.g., text and images) to improve the model performance. Recently, CLIP has emerged as an effective approach that employs vision-language contrastive pretraining to learn joint image and text representations and exhibits remarkable performance in zero-shot learning and text-guided natural image generation. Despite the huge practical success of CLIP, its theoretical understanding remains elusive. In this paper, we formally study transferrable representation learning underlying CLIP and demonstrate how features from different modalities get aligned. We also analyze its zero-shot transfer performance on the downstream tasks. Inspired by our analysis, we propose a new CLIP-type approach, which achieves better performance than CLIP and other state-of-the-art methods on benchmark datasets.