 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Feature Mining and External Knowledge-Assisted Text-Pedestrian Image Retrieval
Aug 23, 2023
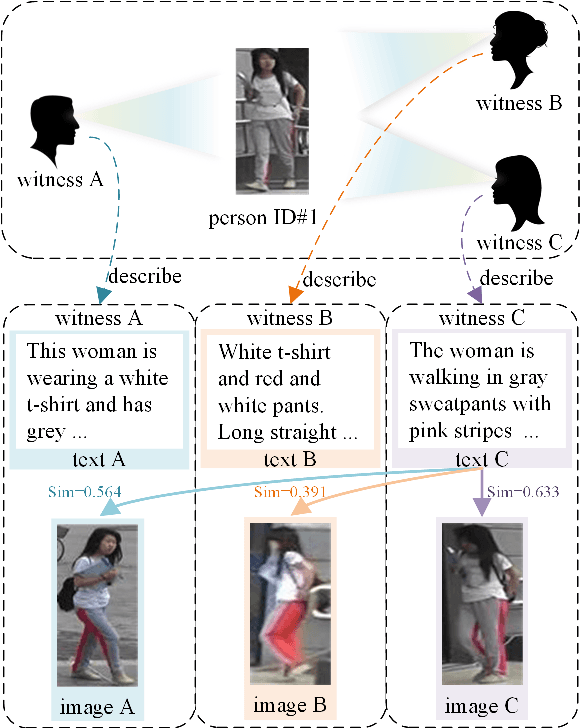

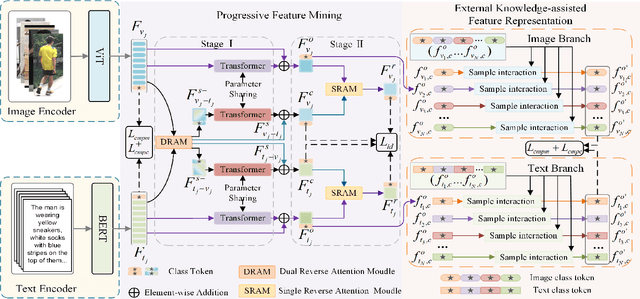
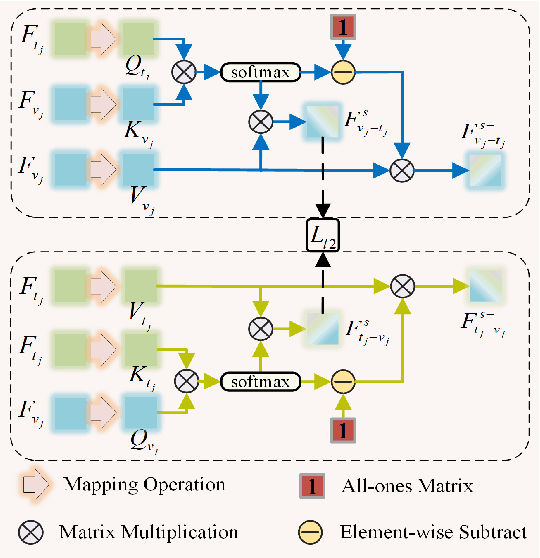
Text-Pedestrian Image Retrieval aims to use the text describing pedestrian appearance to retrieve the corresponding pedestrian image. This task involves not only modality discrepancy, but also the challenge of the textual diversity of pedestrians with the same identity. At present, although existing research progress has been made in text-pedestrian image retrieval, these methods do not comprehensively consider the above-mentioned problems. Considering these, this paper proposes a progressive feature mining and external knowledge-assisted feature purification method. Specifically, we use a progressive mining mode to enable the model to mine discriminative features from neglected information, thereby avoiding the loss of discriminative information and improving the expression ability of features. In addition, to further reduce the negative impact of modal discrepancy and text diversity on cross-modal matching, we propose to use other sample knowledge of the same modality, i.e., external knowledge to enhance identity-consistent features and weaken identity-inconsistent features. This process purifies features and alleviates the interference caused by textual diversity and negative sample correlation features of the same modal. Extensive experiments on three challenging datasets demonstrate the effectiveness and superiority of the proposed method, and the retrieval performance even surpasses that of the large-scale model-based method on large-scale datasets.
Enhancing Medical Image Segmentation: Optimizing Cross-Entropy Weights and Post-Processing with Autoencoders
Aug 21, 2023
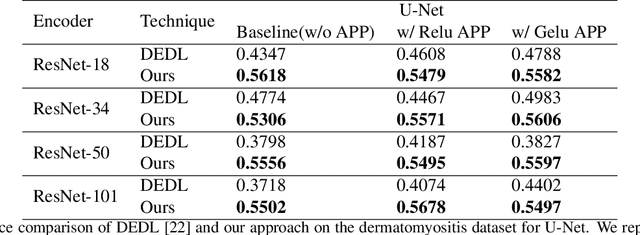
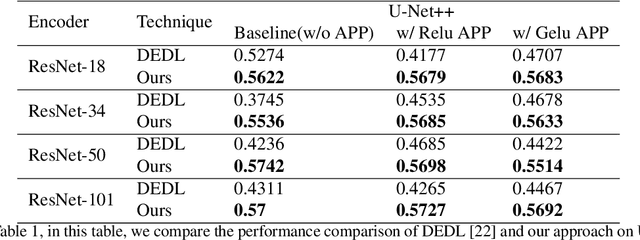
The task of medical image segmentation presents unique challenges, necessitating both localized and holistic semantic understanding to accurately delineate areas of interest, such as critical tissues or aberrant features. This complexity is heightened in medical image segmentation due to the high degree of inter-class similarities, intra-class variations, and possible image obfuscation. The segmentation task further diversifies when considering the study of histopathology slides for autoimmune diseases like dermatomyositis. The analysis of cell inflammation and interaction in these cases has been less studied due to constraints in data acquisition pipelines. Despite the progressive strides in medical science, we lack a comprehensive collection of autoimmune diseases. As autoimmune diseases globally escalate in prevalence and exhibit associations with COVID-19, their study becomes increasingly essential. While there is existing research that integrates artificial intelligence in the analysis of various autoimmune diseases, the exploration of dermatomyositis remains relatively underrepresented. In this paper, we present a deep-learning approach tailored for Medical image segmentation. Our proposed method outperforms the current state-of-the-art techniques by an average of 12.26% for U-Net and 12.04% for U-Net++ across the ResNet family of encoders on the dermatomyositis dataset. Furthermore, we probe the importance of optimizing loss function weights and benchmark our methodology on three challenging medical image segmentation tasks
Argumentative Stance Prediction: An Exploratory Study on Multimodality and Few-Shot Learning
Oct 11, 2023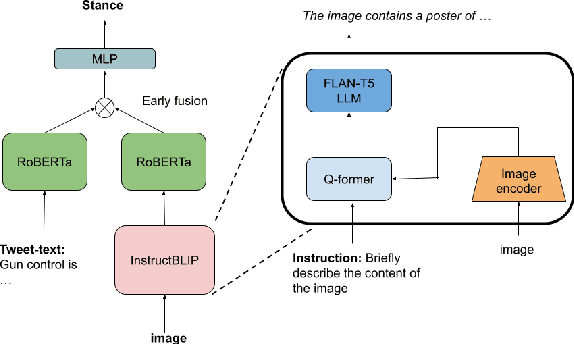
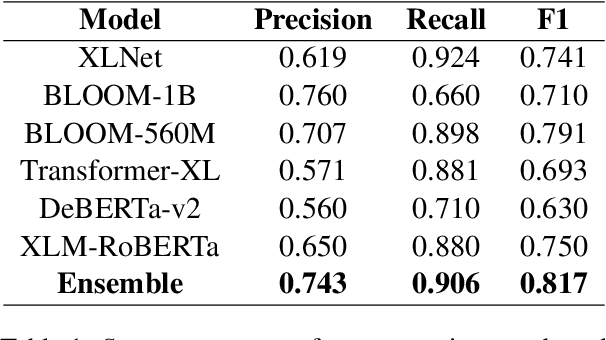
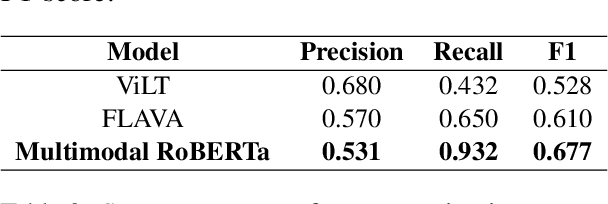

To advance argumentative stance prediction as a multimodal problem, the First Shared Task in Multimodal Argument Mining hosted stance prediction in crucial social topics of gun control and abortion. Our exploratory study attempts to evaluate the necessity of images for stance prediction in tweets and compare out-of-the-box text-based large-language models (LLM) in few-shot settings against fine-tuned unimodal and multimodal models. Our work suggests an ensemble of fine-tuned text-based language models (0.817 F1-score) outperforms both the multimodal (0.677 F1-score) and text-based few-shot prediction using a recent state-of-the-art LLM (0.550 F1-score). In addition to the differences in performance, our findings suggest that the multimodal models tend to perform better when image content is summarized as natural language over their native pixel structure and, using in-context examples improves few-shot performance of LLMs.
Relational Prior Knowledge Graphs for Detection and Instance Segmentation
Oct 11, 2023
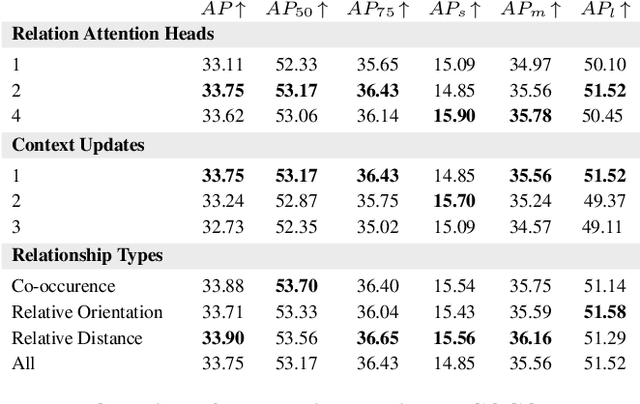
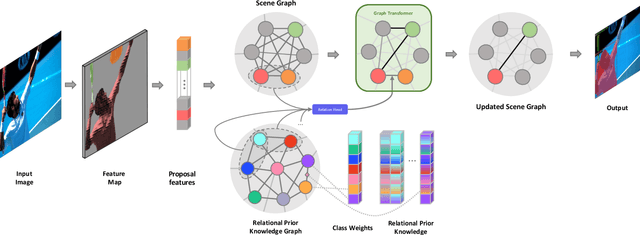
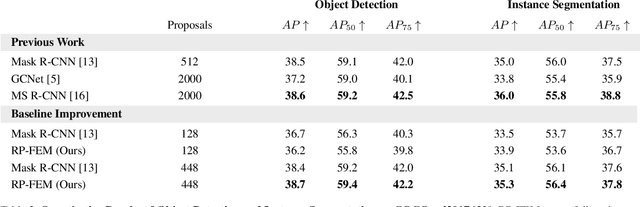
Humans have a remarkable ability to perceive and reason about the world around them by understanding the relationships between objects. In this paper, we investigate the effectiveness of using such relationships for object detection and instance segmentation. To this end, we propose a Relational Prior-based Feature Enhancement Model (RP-FEM), a graph transformer that enhances object proposal features using relational priors. The proposed architecture operates on top of scene graphs obtained from initial proposals and aims to concurrently learn relational context modeling for object detection and instance segmentation. Experimental evaluations on COCO show that the utilization of scene graphs, augmented with relational priors, offer benefits for object detection and instance segmentation. RP-FEM demonstrates its capacity to suppress improbable class predictions within the image while also preventing the model from generating duplicate predictions, leading to improvements over the baseline model on which it is built.
AdLER: Adversarial Training with Label Error Rectification for One-Shot Medical Image Segmentation
Sep 02, 2023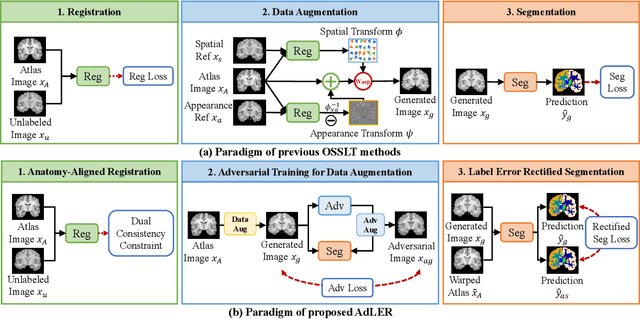
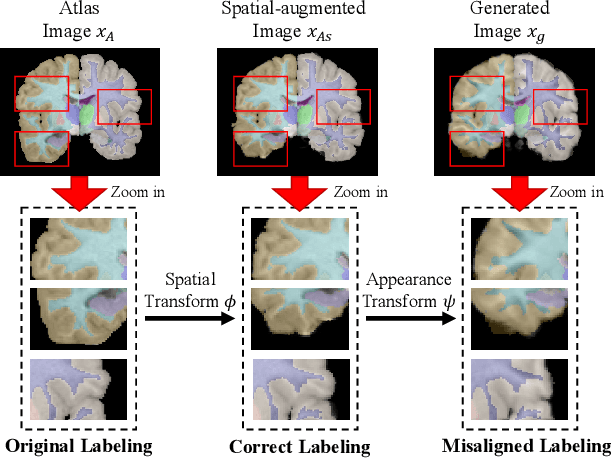
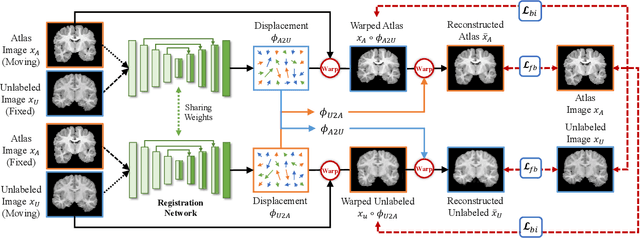
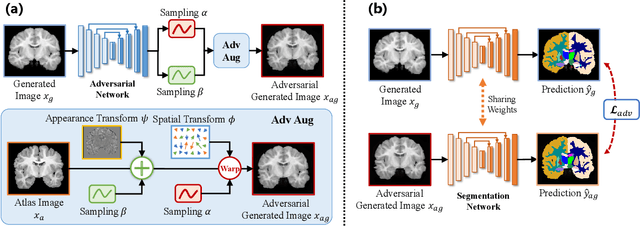
Accurate automatic segmentation of medical images typically requires large datasets with high-quality annotations, making it less applicable in clinical settings due to limited training data. One-shot segmentation based on learned transformations (OSSLT) has shown promise when labeled data is extremely limited, typically including unsupervised deformable registration, data augmentation with learned registration, and segmentation learned from augmented data. However, current one-shot segmentation methods are challenged by limited data diversity during augmentation, and potential label errors caused by imperfect registration. To address these issues, we propose a novel one-shot medical image segmentation method with adversarial training and label error rectification (AdLER), with the aim of improving the diversity of generated data and correcting label errors to enhance segmentation performance. Specifically, we implement a novel dual consistency constraint to ensure anatomy-aligned registration that lessens registration errors. Furthermore, we develop an adversarial training strategy to augment the atlas image, which ensures both generation diversity and segmentation robustness. We also propose to rectify potential label errors in the augmented atlas images by estimating segmentation uncertainty, which can compensate for the imperfect nature of deformable registration and improve segmentation authenticity. Experiments on the CANDI and ABIDE datasets demonstrate that the proposed AdLER outperforms previous state-of-the-art methods by 0.7% (CANDI), 3.6% (ABIDE "seen"), and 4.9% (ABIDE "unseen") in segmentation based on Dice scores, respectively. The source code will be available at https://github.com/hsiangyuzhao/AdLER.
Augmenting Vision-Based Human Pose Estimation with Rotation Matrix
Oct 09, 2023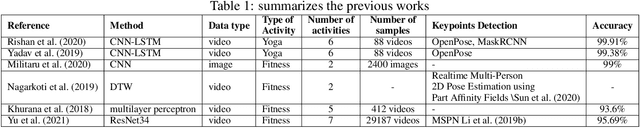
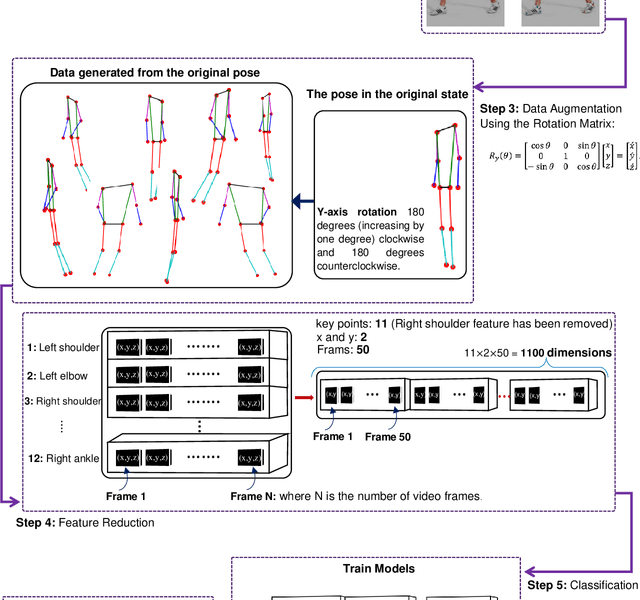

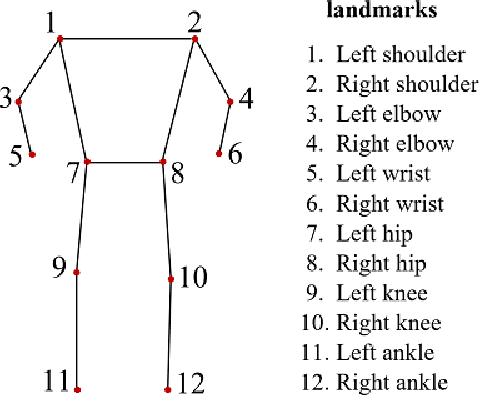
Fitness applications are commonly used to monitor activities within the gym, but they often fail to automatically track indoor activities inside the gym. This study proposes a model that utilizes pose estimation combined with a novel data augmentation method, i.e., rotation matrix. We aim to enhance the classification accuracy of activity recognition based on pose estimation data. Through our experiments, we experiment with different classification algorithms along with image augmentation approaches. Our findings demonstrate that the SVM with SGD optimization, using data augmentation with the Rotation Matrix, yields the most accurate results, achieving a 96% accuracy rate in classifying five physical activities. Conversely, without implementing the data augmentation techniques, the baseline accuracy remains at a modest 64%.
Frugal Satellite Image Change Detection with Deep-Net Inversion
Sep 26, 2023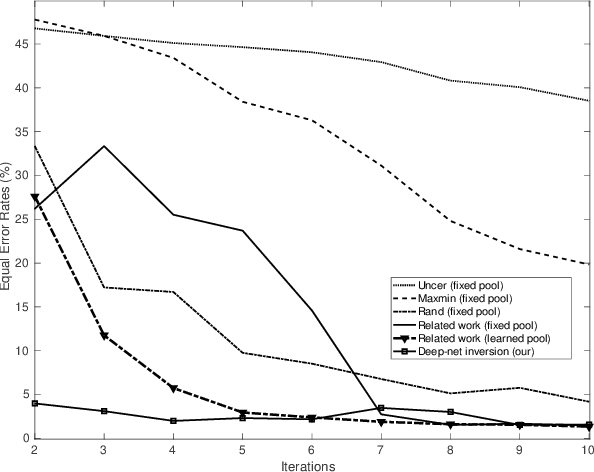
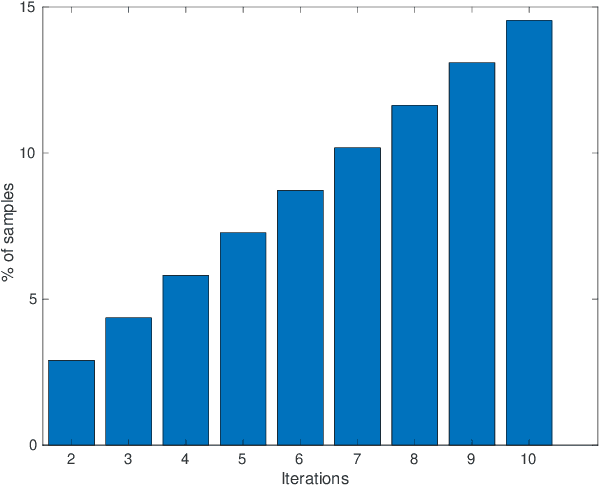
Change detection in satellite imagery seeks to find occurrences of targeted changes in a given scene taken at different instants. This task has several applications ranging from land-cover mapping, to anthropogenic activity monitory as well as climate change and natural hazard damage assessment. However, change detection is highly challenging due to the acquisition conditions and also to the subjectivity of changes. In this paper, we devise a novel algorithm for change detection based on active learning. The proposed method is based on a question and answer model that probes an oracle (user) about the relevance of changes only on a small set of critical images (referred to as virtual exemplars), and according to oracle's responses updates deep neural network (DNN) classifiers. The main contribution resides in a novel adversarial model that allows learning the most representative, diverse and uncertain virtual exemplars (as inverted preimages of the trained DNNs) that challenge (the most) the trained DNNs, and this leads to a better re-estimate of these networks in the subsequent iterations of active learning. Experiments show the out-performance of our proposed deep-net inversion against the related work.
SLIQ: Quantum Image Similarity Networks on Noisy Quantum Computers
Sep 26, 2023Exploration into quantum machine learning has grown tremendously in recent years due to the ability of quantum computers to speed up classical programs. However, these efforts have yet to solve unsupervised similarity detection tasks due to the challenge of porting them to run on quantum computers. To overcome this challenge, we propose SLIQ, the first open-sourced work for resource-efficient quantum similarity detection networks, built with practical and effective quantum learning and variance-reducing algorithms.
Semantic Scene Difference Detection in Daily Life Patroling by Mobile Robots using Pre-Trained Large-Scale Vision-Language Model
Sep 28, 2023It is important for daily life support robots to detect changes in their environment and perform tasks. In the field of anomaly detection in computer vision, probabilistic and deep learning methods have been used to calculate the image distance. These methods calculate distances by focusing on image pixels. In contrast, this study aims to detect semantic changes in the daily life environment using the current development of large-scale vision-language models. Using its Visual Question Answering (VQA) model, we propose a method to detect semantic changes by applying multiple questions to a reference image and a current image and obtaining answers in the form of sentences. Unlike deep learning-based methods in anomaly detection, this method does not require any training or fine-tuning, is not affected by noise, and is sensitive to semantic state changes in the real world. In our experiments, we demonstrated the effectiveness of this method by applying it to a patrol task in a real-life environment using a mobile robot, Fetch Mobile Manipulator. In the future, it may be possible to add explanatory power to changes in the daily life environment through spoken language.
Demystifying CLIP Data
Oct 02, 2023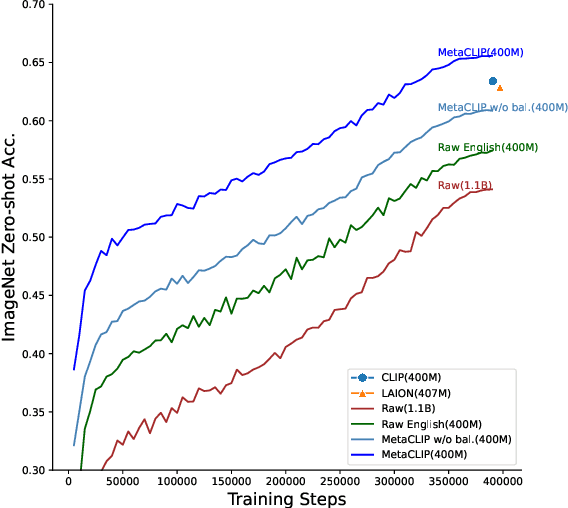

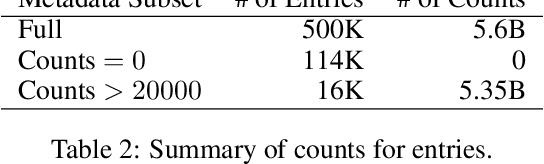
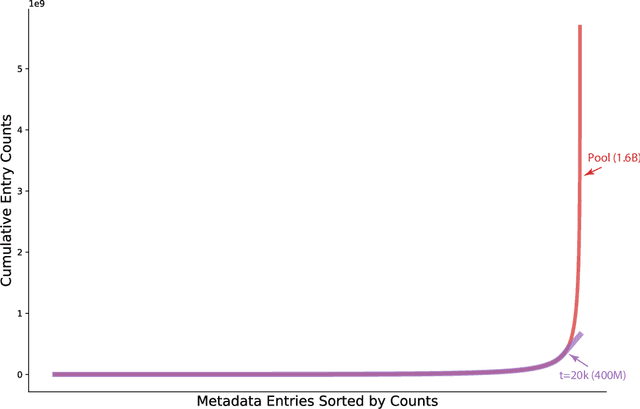
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.