 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Modeling with Phase Stochastic Bridges
Oct 13, 2023
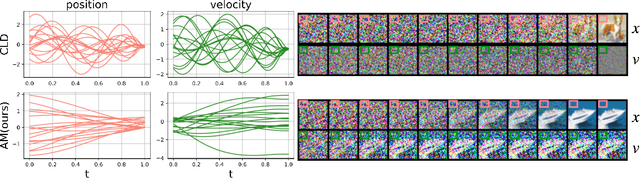

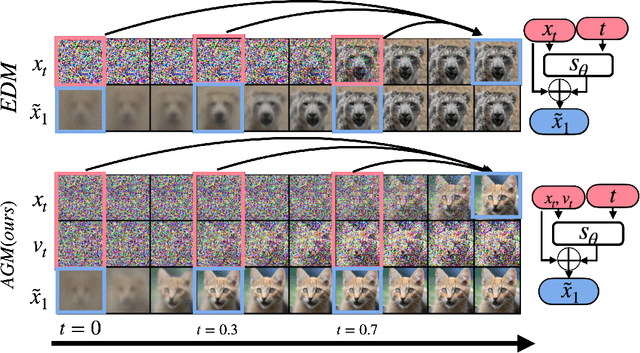

Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space), and using a neural network to reverse it. In this work, we introduce a novel generative modeling framework grounded in \textbf{phase space dynamics}, where a phase space is defined as {an augmented space encompassing both position and velocity.} Leveraging insights from Stochastic Optimal Control, we construct a path measure in the phase space that enables efficient sampling. {In contrast to DMs, our framework demonstrates the capability to generate realistic data points at an early stage of dynamics propagation.} This early prediction sets the stage for efficient data generation by leveraging additional velocity information along the trajectory. On standard image generation benchmarks, our model yields favorable performance over baselines in the regime of small Number of Function Evaluations (NFEs). Furthermore, our approach rivals the performance of diffusion models equipped with efficient sampling techniques, underscoring its potential as a new tool generative modeling.
GrowCLIP: Data-aware Automatic Model Growing for Large-scale Contrastive Language-Image Pre-training
Aug 22, 2023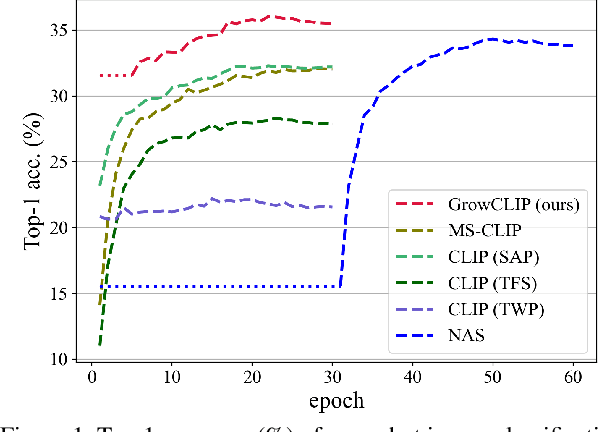

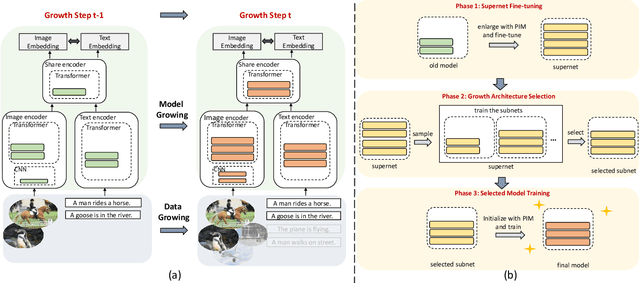

Cross-modal pre-training has shown impressive performance on a wide range of downstream tasks, benefiting from massive image-text pairs collected from the Internet. In practice, online data are growing constantly, highlighting the importance of the ability of pre-trained model to learn from data that is continuously growing. Existing works on cross-modal pre-training mainly focus on training a network with fixed architecture. However, it is impractical to limit the model capacity when considering the continuously growing nature of pre-training data in real-world applications. On the other hand, it is important to utilize the knowledge in the current model to obtain efficient training and better performance. To address the above issues, in this paper, we propose GrowCLIP, a data-driven automatic model growing algorithm for contrastive language-image pre-training with continuous image-text pairs as input. Specially, we adopt a dynamic growth space and seek out the optimal architecture at each growth step to adapt to online learning scenarios. And the shared encoder is proposed in our growth space to enhance the degree of cross-modal fusion. Besides, we explore the effect of growth in different dimensions, which could provide future references for the design of cross-modal model architecture. Finally, we employ parameter inheriting with momentum (PIM) to maintain the previous knowledge and address the issue of the local minimum dilemma. Compared with the existing methods, GrowCLIP improves 2.3% average top-1 accuracy on zero-shot image classification of 9 downstream tasks. As for zero-shot image retrieval, GrowCLIP can improve 1.2% for top-1 image-to-text recall on Flickr30K dataset.
Learning Interactive Real-World Simulators
Oct 09, 2023

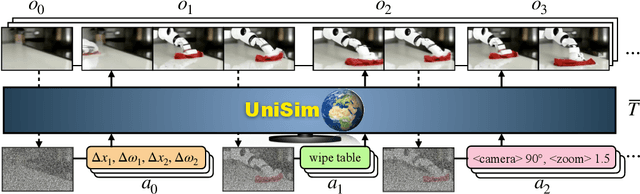

Generative models trained on internet data have revolutionized how text, image, and video content can be created. Perhaps the next milestone for generative models is to simulate realistic experience in response to actions taken by humans, robots, and other interactive agents. Applications of a real-world simulator range from controllable content creation in games and movies, to training embodied agents purely in simulation that can be directly deployed in the real world. We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling. We first make the important observation that natural datasets available for learning a real-world simulator are often rich along different axes (e.g., abundant objects in image data, densely sampled actions in robotics data, and diverse movements in navigation data). With careful orchestration of diverse datasets, each providing a different aspect of the overall experience, UniSim can emulate how humans and agents interact with the world by simulating the visual outcome of both high-level instructions such as "open the drawer" and low-level controls such as "move by x, y" from otherwise static scenes and objects. There are numerous use cases for such a real-world simulator. As an example, we use UniSim to train both high-level vision-language planners and low-level reinforcement learning policies, each of which exhibit zero-shot real-world transfer after training purely in a learned real-world simulator. We also show that other types of intelligence such as video captioning models can benefit from training with simulated experience in UniSim, opening up even wider applications. Video demos can be found at https://universal-simulator.github.io.
Improved YOLOv8 Detection Algorithm in Security Inspection Image
Aug 22, 2023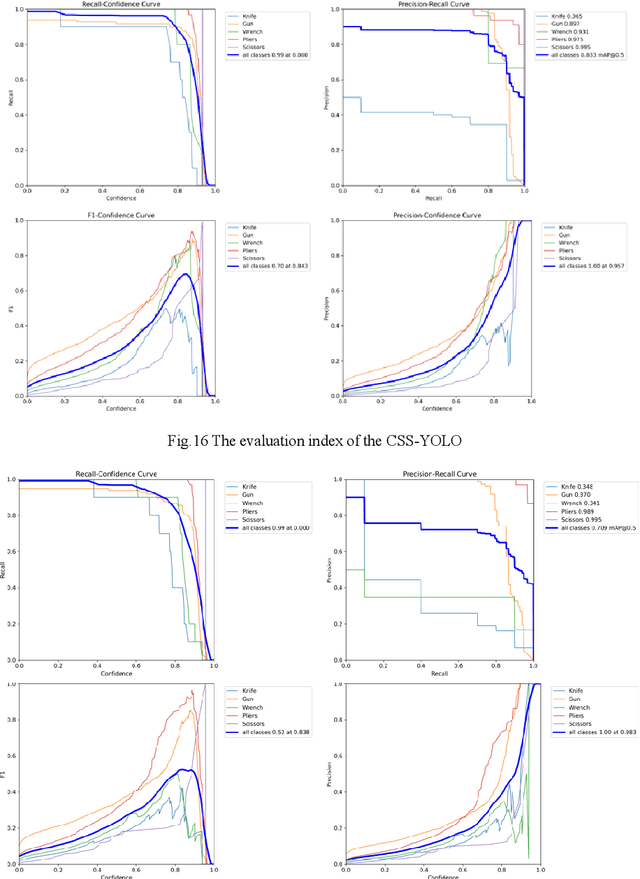


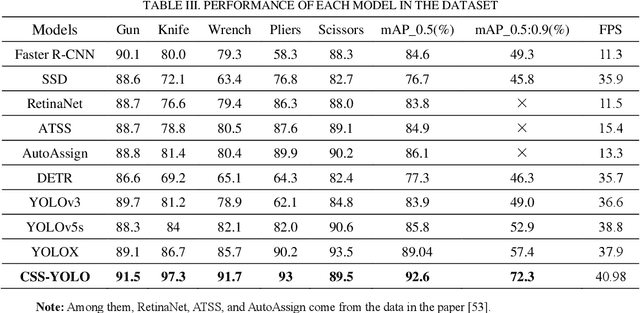
Security inspection is the first line of defense to ensure the safety of people's lives and property, and intelligent security inspection is an inevitable trend in the future development of the security inspection industry. Aiming at the problems of overlapping detection objects, false detection of contraband, and missed detection in the process of X-ray image detection, an improved X-ray contraband detection algorithm CSS-YOLO based on YOLOv8s is proposed.
StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data
Aug 20, 2023
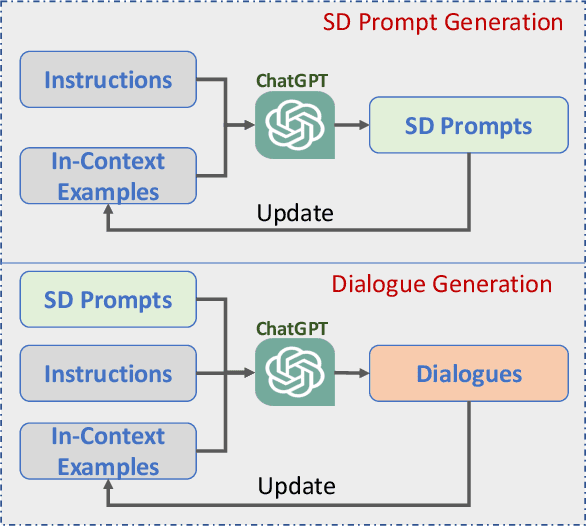
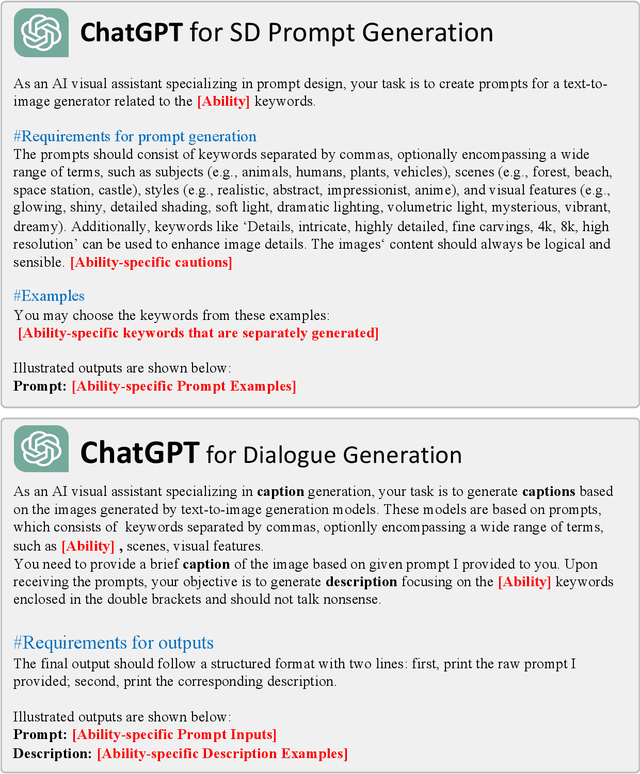

The remarkable multimodal capabilities demonstrated by OpenAI's GPT-4 have sparked significant interest in the development of multimodal Large Language Models (LLMs). A primary research objective of such models is to align visual and textual modalities effectively while comprehending human instructions. Current methodologies often rely on annotations derived from benchmark datasets to construct image-dialogue datasets for training purposes, akin to instruction tuning in LLMs. However, these datasets often exhibit domain bias, potentially constraining the generative capabilities of the models. In an effort to mitigate these limitations, we propose a novel data collection methodology that synchronously synthesizes images and dialogues for visual instruction tuning. This approach harnesses the power of generative models, marrying the abilities of ChatGPT and text-to-image generative models to yield a diverse and controllable dataset with varied image content. This not only provides greater flexibility compared to existing methodologies but also significantly enhances several model capabilities. Our research includes comprehensive experiments conducted on various datasets using the open-source LLAVA model as a testbed for our proposed pipeline. Our results underscore marked enhancements across more than ten commonly assessed capabilities,
Denoising Diffusion Bridge Models
Sep 29, 2023


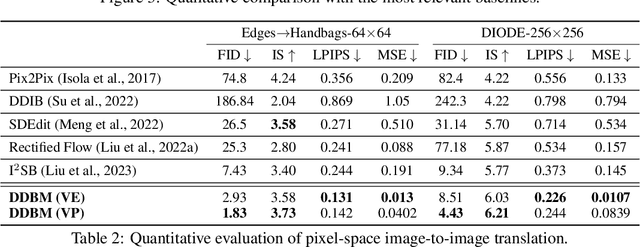
Diffusion models are powerful generative models that map noise to data using stochastic processes. However, for many applications such as image editing, the model input comes from a distribution that is not random noise. As such, diffusion models must rely on cumbersome methods like guidance or projected sampling to incorporate this information in the generative process. In our work, we propose Denoising Diffusion Bridge Models (DDBMs), a natural alternative to this paradigm based on diffusion bridges, a family of processes that interpolate between two paired distributions given as endpoints. Our method learns the score of the diffusion bridge from data and maps from one endpoint distribution to the other by solving a (stochastic) differential equation based on the learned score. Our method naturally unifies several classes of generative models, such as score-based diffusion models and OT-Flow-Matching, allowing us to adapt existing design and architectural choices to our more general problem. Empirically, we apply DDBMs to challenging image datasets in both pixel and latent space. On standard image translation problems, DDBMs achieve significant improvement over baseline methods, and, when we reduce the problem to image generation by setting the source distribution to random noise, DDBMs achieve comparable FID scores to state-of-the-art methods despite being built for a more general task.
Fine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering
Sep 29, 2023Knowledge-based Visual Question Answering (KB-VQA) requires VQA systems to utilize knowledge from existing knowledge bases to answer visually-grounded questions. Retrieval-Augmented Visual Question Answering (RA-VQA), a strong framework to tackle KB-VQA, first retrieves related documents with Dense Passage Retrieval (DPR) and then uses them to answer questions. This paper proposes Fine-grained Late-interaction Multi-modal Retrieval (FLMR) which significantly improves knowledge retrieval in RA-VQA. FLMR addresses two major limitations in RA-VQA's retriever: (1) the image representations obtained via image-to-text transforms can be incomplete and inaccurate and (2) relevance scores between queries and documents are computed with one-dimensional embeddings, which can be insensitive to finer-grained relevance. FLMR overcomes these limitations by obtaining image representations that complement those from the image-to-text transforms using a vision model aligned with an existing text-based retriever through a simple alignment network. FLMR also encodes images and questions using multi-dimensional embeddings to capture finer-grained relevance between queries and documents. FLMR significantly improves the original RA-VQA retriever's PRRecall@5 by approximately 8\%. Finally, we equipped RA-VQA with two state-of-the-art large multi-modal/language models to achieve $\sim61\%$ VQA score in the OK-VQA dataset.
Condition numbers in multiview geometry, instability in relative pose estimation, and RANSAC
Oct 04, 2023In this paper we introduce a general framework for analyzing the numerical conditioning of minimal problems in multiple view geometry, using tools from computational algebra and Riemannian geometry. Special motivation comes from the fact that relative pose estimation, based on standard 5-point or 7-point Random Sample Consensus (RANSAC) algorithms, can fail even when no outliers are present and there is enough data to support a hypothesis. We argue that these cases arise due to the intrinsic instability of the 5- and 7-point minimal problems. We apply our framework to characterize the instabilities, both in terms of the world scenes that lead to infinite condition number, and directly in terms of ill-conditioned image data. The approach produces computational tests for assessing the condition number before solving the minimal problem. Lastly synthetic and real data experiments suggest that RANSAC serves not only to remove outliers, but also to select for well-conditioned image data, as predicted by our theory.
Application of Quantum Pre-Processing Filter for Binary Image Classification with Small Samples
Aug 28, 2023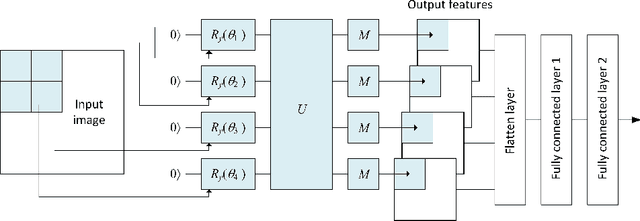
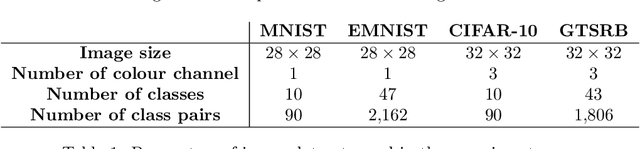
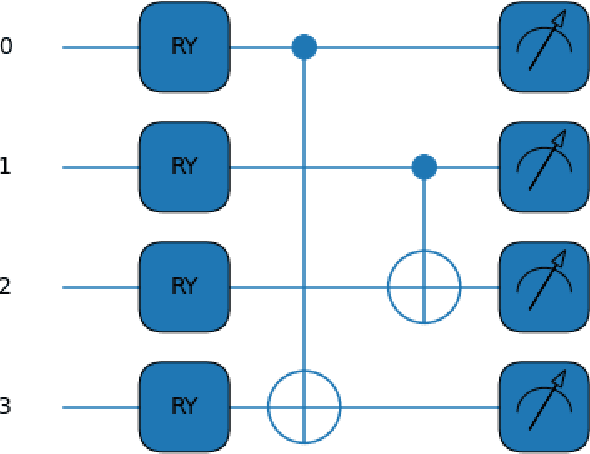
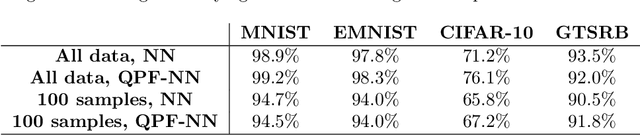
Over the past few years, there has been significant interest in Quantum Machine Learning (QML) among researchers, as it has the potential to transform the field of machine learning. Several models that exploit the properties of quantum mechanics have been developed for practical applications. In this study, we investigated the application of our previously proposed quantum pre-processing filter (QPF) to binary image classification. We evaluated the QPF on four datasets: MNIST (handwritten digits), EMNIST (handwritten digits and alphabets), CIFAR-10 (photographic images) and GTSRB (real-life traffic sign images). Similar to our previous multi-class classification results, the application of QPF improved the binary image classification accuracy using neural network against MNIST, EMNIST, and CIFAR-10 from 98.9% to 99.2%, 97.8% to 98.3%, and 71.2% to 76.1%, respectively, but degraded it against GTSRB from 93.5% to 92.0%. We then applied QPF in cases using a smaller number of training and testing samples, i.e. 80 and 20 samples per class, respectively. In order to derive statistically stable results, we conducted the experiment with 100 trials choosing randomly different training and testing samples and averaging the results. The result showed that the application of QPF did not improve the image classification accuracy against MNIST and EMNIST but improved it against CIFAR-10 and GTSRB from 65.8% to 67.2% and 90.5% to 91.8%, respectively. Further research will be conducted as part of future work to investigate the potential of QPF to assess the scalability of the proposed approach to larger and complex datasets.
Self-Sampling Meta SAM: Enhancing Few-shot Medical Image Segmentation with Meta-Learning
Sep 01, 2023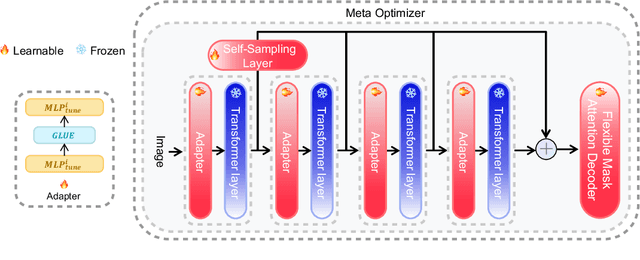
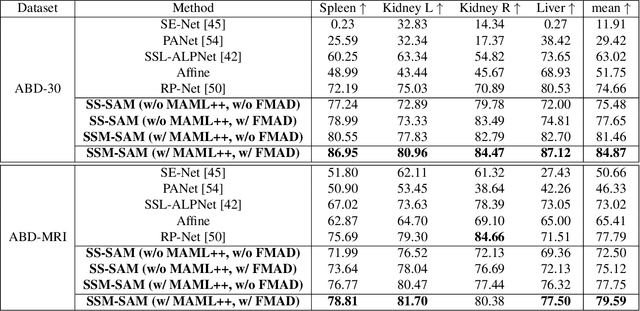
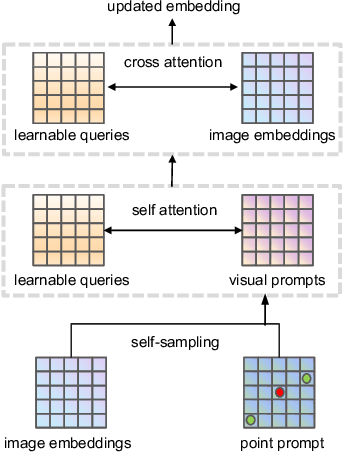
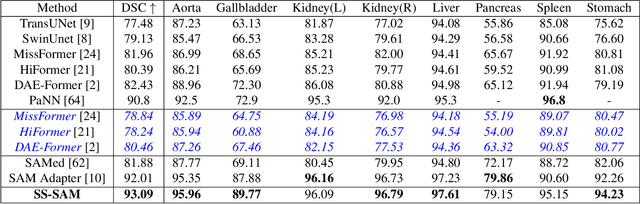
While the Segment Anything Model (SAM) excels in semantic segmentation for general-purpose images, its performance significantly deteriorates when applied to medical images, primarily attributable to insufficient representation of medical images in its training dataset. Nonetheless, gathering comprehensive datasets and training models that are universally applicable is particularly challenging due to the long-tail problem common in medical images. To address this gap, here we present a Self-Sampling Meta SAM (SSM-SAM) framework for few-shot medical image segmentation. Our innovation lies in the design of three key modules: 1) An online fast gradient descent optimizer, further optimized by a meta-learner, which ensures swift and robust adaptation to new tasks. 2) A Self-Sampling module designed to provide well-aligned visual prompts for improved attention allocation; and 3) A robust attention-based decoder specifically designed for medical few-shot learning to capture relationship between different slices. Extensive experiments on a popular abdominal CT dataset and an MRI dataset demonstrate that the proposed method achieves significant improvements over state-of-the-art methods in few-shot segmentation, with an average improvements of 10.21% and 1.80% in terms of DSC, respectively. In conclusion, we present a novel approach for rapid online adaptation in interactive image segmentation, adapting to a new organ in just 0.83 minutes. Code is publicly available on GitHub upon acceptance.