 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Learning of Object-Centric Embeddings for Cell Instance Segmentation in Microscopy Images
Oct 12, 2023
Segmentation of objects in microscopy images is required for many biomedical applications. We introduce object-centric embeddings (OCEs), which embed image patches such that the spatial offsets between patches cropped from the same object are preserved. Those learnt embeddings can be used to delineate individual objects and thus obtain instance segmentations. Here, we show theoretically that, under assumptions commonly found in microscopy images, OCEs can be learnt through a self-supervised task that predicts the spatial offset between image patches. Together, this forms an unsupervised cell instance segmentation method which we evaluate on nine diverse large-scale microscopy datasets. Segmentations obtained with our method lead to substantially improved results, compared to state-of-the-art baselines on six out of nine datasets, and perform on par on the remaining three datasets. If ground-truth annotations are available, our method serves as an excellent starting point for supervised training, reducing the required amount of ground-truth needed by one order of magnitude, thus substantially increasing the practical applicability of our method. Source code is available at https://github.com/funkelab/cellulus.
Visual Data-Type Understanding does not emerge from Scaling Vision-Language Models
Oct 16, 2023Recent advances in the development of vision-language models (VLMs) are yielding remarkable success in recognizing visual semantic content, including impressive instances of compositional image understanding. Here, we introduce the novel task of Visual Data-Type Identification, a basic perceptual skill with implications for data curation (e.g., noisy data-removal from large datasets, domain-specific retrieval) and autonomous vision (e.g., distinguishing changing weather conditions from camera lens staining). We develop two datasets consisting of animal images altered across a diverse set of 27 visual data-types, spanning four broad categories. An extensive zero-shot evaluation of 39 VLMs, ranging from 100M to 80B parameters, shows a nuanced performance landscape. While VLMs are reasonably good at identifying certain stylistic \textit{data-types}, such as cartoons and sketches, they struggle with simpler data-types arising from basic manipulations like image rotations or additive noise. Our findings reveal that (i) model scaling alone yields marginal gains for contrastively-trained models like CLIP, and (ii) there is a pronounced drop in performance for the largest auto-regressively trained VLMs like OpenFlamingo. This finding points to a blind spot in current frontier VLMs: they excel in recognizing semantic content but fail to acquire an understanding of visual data-types through scaling. By analyzing the pre-training distributions of these models and incorporating data-type information into the captions during fine-tuning, we achieve a significant enhancement in performance. By exploring this previously uncharted task, we aim to set the stage for further advancing VLMs to equip them with visual data-type understanding. Code and datasets are released at https://github.com/bethgelab/DataTypeIdentification.
Neural Sampling in Hierarchical Exponential-family Energy-based Models
Oct 22, 2023Bayesian brain theory suggests that the brain employs generative models to understand the external world. The sampling-based perspective posits that the brain infers the posterior distribution through samples of stochastic neuronal responses. Additionally, the brain continually updates its generative model to approach the true distribution of the external world. In this study, we introduce the Hierarchical Exponential-family Energy-based (HEE) model, which captures the dynamics of inference and learning. In the HEE model, we decompose the partition function into individual layers and leverage a group of neurons with shorter time constants to sample the gradient of the decomposed normalization term. This allows our model to estimate the partition function and perform inference simultaneously, circumventing the negative phase encountered in conventional energy-based models (EBMs). As a result, the learning process is localized both in time and space, and the model is easy to converge. To match the brain's rapid computation, we demonstrate that neural adaptation can serve as a momentum term, significantly accelerating the inference process. On natural image datasets, our model exhibits representations akin to those observed in the biological visual system. Furthermore, for the machine learning community, our model can generate observations through joint or marginal generation. We show that marginal generation outperforms joint generation and achieves performance on par with other EBMs.
Hierarchical Vector Quantized Transformer for Multi-class Unsupervised Anomaly Detection
Oct 22, 2023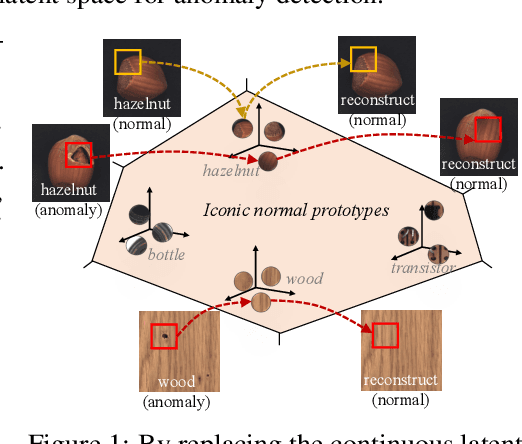
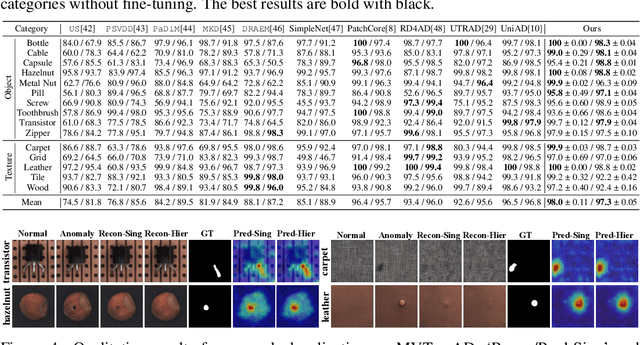
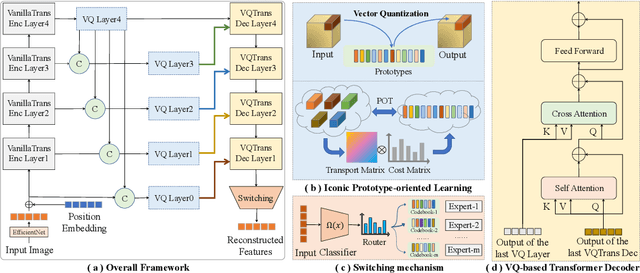
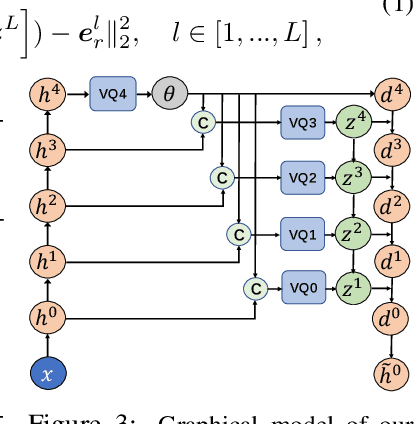
Unsupervised image Anomaly Detection (UAD) aims to learn robust and discriminative representations of normal samples. While separate solutions per class endow expensive computation and limited generalizability, this paper focuses on building a unified framework for multiple classes. Under such a challenging setting, popular reconstruction-based networks with continuous latent representation assumption always suffer from the "identical shortcut" issue, where both normal and abnormal samples can be well recovered and difficult to distinguish. To address this pivotal issue, we propose a hierarchical vector quantized prototype-oriented Transformer under a probabilistic framework. First, instead of learning the continuous representations, we preserve the typical normal patterns as discrete iconic prototypes, and confirm the importance of Vector Quantization in preventing the model from falling into the shortcut. The vector quantized iconic prototype is integrated into the Transformer for reconstruction, such that the abnormal data point is flipped to a normal data point.Second, we investigate an exquisite hierarchical framework to relieve the codebook collapse issue and replenish frail normal patterns. Third, a prototype-oriented optimal transport method is proposed to better regulate the prototypes and hierarchically evaluate the abnormal score. By evaluating on MVTec-AD and VisA datasets, our model surpasses the state-of-the-art alternatives and possesses good interpretability. The code is available at https://github.com/RuiyingLu/HVQ-Trans.
Visual-Attribute Prompt Learning for Progressive Mild Cognitive Impairment Prediction
Oct 22, 2023Deep learning (DL) has been used in the automatic diagnosis of Mild Cognitive Impairment (MCI) and Alzheimer's Disease (AD) with brain imaging data. However, previous methods have not fully exploited the relation between brain image and clinical information that is widely adopted by experts in practice. To exploit the heterogeneous features from imaging and tabular data simultaneously, we propose the Visual-Attribute Prompt Learning-based Transformer (VAP-Former), a transformer-based network that efficiently extracts and fuses the multi-modal features with prompt fine-tuning. Furthermore, we propose a Prompt fine-Tuning (PT) scheme to transfer the knowledge from AD prediction task for progressive MCI (pMCI) diagnosis. In details, we first pre-train the VAP-Former without prompts on the AD diagnosis task and then fine-tune the model on the pMCI detection task with PT, which only needs to optimize a small amount of parameters while keeping the backbone frozen. Next, we propose a novel global prompt token for the visual prompts to provide global guidance to the multi-modal representations. Extensive experiments not only show the superiority of our method compared with the state-of-the-art methods in pMCI prediction but also demonstrate that the global prompt can make the prompt learning process more effective and stable. Interestingly, the proposed prompt learning model even outperforms the fully fine-tuning baseline on transferring the knowledge from AD to pMCI.
VGDiffZero: Text-to-image Diffusion Models Can Be Zero-shot Visual Grounders
Sep 03, 2023Large-scale text-to-image diffusion models have shown impressive capabilities across various generative tasks, enabled by strong vision-language alignment obtained through pre-training. However, most vision-language discriminative tasks require extensive fine-tuning on carefully-labeled datasets to acquire such alignment, with great cost in time and computing resources. In this work, we explore directly applying a pre-trained generative diffusion model to the challenging discriminative task of visual grounding without any fine-tuning and additional training dataset. Specifically, we propose VGDiffZero, a simple yet effective zero-shot visual grounding framework based on text-to-image diffusion models. We also design a comprehensive region-scoring method considering both global and local contexts of each isolated proposal. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg show that VGDiffZero achieves strong performance on zero-shot visual grounding.
Image-Object-Specific Prompt Learning for Few-Shot Class-Incremental Learning
Sep 06, 2023While many FSCIL studies have been undertaken, achieving satisfactory performance, especially during incremental sessions, has remained challenging. One prominent challenge is that the encoder, trained with an ample base session training set, often underperforms in incremental sessions. In this study, we introduce a novel training framework for FSCIL, capitalizing on the generalizability of the Contrastive Language-Image Pre-training (CLIP) model to unseen classes. We achieve this by formulating image-object-specific (IOS) classifiers for the input images. Here, an IOS classifier refers to one that targets specific attributes (like wings or wheels) of class objects rather than the image's background. To create these IOS classifiers, we encode a bias prompt into the classifiers using our specially designed module, which harnesses key-prompt pairs to pinpoint the IOS features of classes in each session. From an FSCIL standpoint, our framework is structured to retain previous knowledge and swiftly adapt to new sessions without forgetting or overfitting. This considers the updatability of modules in each session and some tricks empirically found for fast convergence. Our approach consistently demonstrates superior performance compared to state-of-the-art methods across the miniImageNet, CIFAR100, and CUB200 datasets. Further, we provide additional experiments to validate our learned model's ability to achieve IOS classifiers. We also conduct ablation studies to analyze the impact of each module within the architecture.
PAC Prediction Sets Under Label Shift
Oct 19, 2023Prediction sets capture uncertainty by predicting sets of labels rather than individual labels, enabling downstream decisions to conservatively account for all plausible outcomes. Conformal inference algorithms construct prediction sets guaranteed to contain the true label with high probability. These guarantees fail to hold in the face of distribution shift, which is precisely when reliable uncertainty quantification can be most useful. We propose a novel algorithm for constructing prediction sets with PAC guarantees in the label shift setting. This method estimates the predicted probabilities of the classes in a target domain, as well as the confusion matrix, then propagates uncertainty in these estimates through a Gaussian elimination algorithm to compute confidence intervals for importance weights. Finally, it uses these intervals to construct prediction sets. We evaluate our approach on five datasets: the CIFAR-10, ChestX-Ray and Entity-13 image datasets, the tabular CDC Heart dataset, and the AGNews text dataset. Our algorithm satisfies the PAC guarantee while producing smaller, more informative, prediction sets compared to several baselines.
Ablation Study to Clarify the Mechanism of Object Segmentation in Multi-Object Representation Learning
Oct 05, 2023Multi-object representation learning aims to represent complex real-world visual input using the composition of multiple objects. Representation learning methods have often used unsupervised learning to segment an input image into individual objects and encode these objects into each latent vector. However, it is not clear how previous methods have achieved the appropriate segmentation of individual objects. Additionally, most of the previous methods regularize the latent vectors using a Variational Autoencoder (VAE). Therefore, it is not clear whether VAE regularization contributes to appropriate object segmentation. To elucidate the mechanism of object segmentation in multi-object representation learning, we conducted an ablation study on MONet, which is a typical method. MONet represents multiple objects using pairs that consist of an attention mask and the latent vector corresponding to the attention mask. Each latent vector is encoded from the input image and attention mask. Then, the component image and attention mask are decoded from each latent vector. The loss function of MONet consists of 1) the sum of reconstruction losses between the input image and decoded component image, 2) the VAE regularization loss of the latent vector, and 3) the reconstruction loss of the attention mask to explicitly encode shape information. We conducted an ablation study on these three loss functions to investigate the effect on segmentation performance. Our results showed that the VAE regularization loss did not affect segmentation performance and the others losses did affect it. Based on this result, we hypothesize that it is important to maximize the attention mask of the image region best represented by a single latent vector corresponding to the attention mask. We confirmed this hypothesis by evaluating a new loss function with the same mechanism as the hypothesis.
Hierarchical Uncertainty Estimation for Medical Image Segmentation Networks
Aug 16, 2023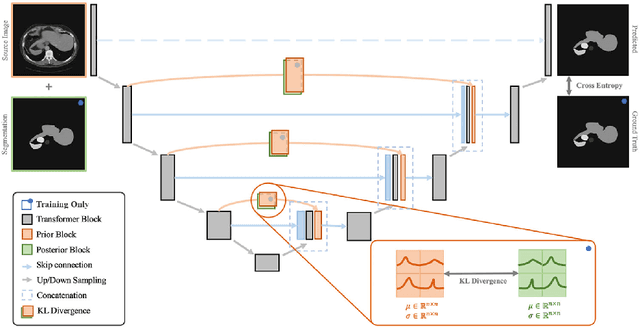
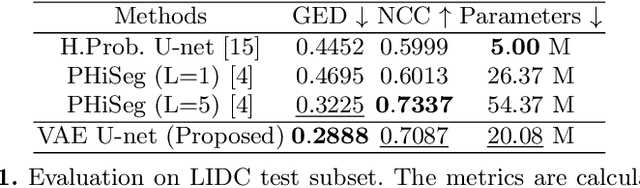
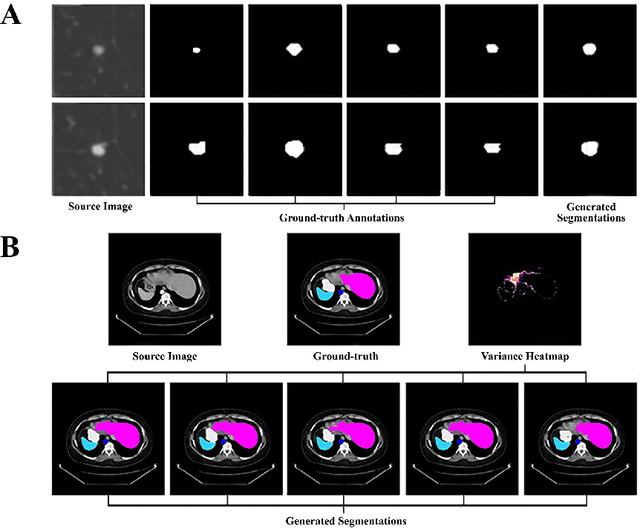
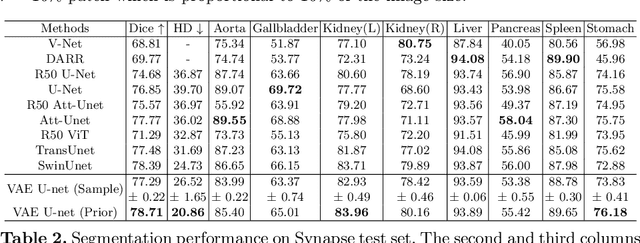
Learning a medical image segmentation model is an inherently ambiguous task, as uncertainties exist in both images (noise) and manual annotations (human errors and bias) used for model training. To build a trustworthy image segmentation model, it is important to not just evaluate its performance but also estimate the uncertainty of the model prediction. Most state-of-the-art image segmentation networks adopt a hierarchical encoder architecture, extracting image features at multiple resolution levels from fine to coarse. In this work, we leverage this hierarchical image representation and propose a simple yet effective method for estimating uncertainties at multiple levels. The multi-level uncertainties are modelled via the skip-connection module and then sampled to generate an uncertainty map for the predicted image segmentation. We demonstrate that a deep learning segmentation network such as U-net, when implemented with such hierarchical uncertainty estimation module, can achieve a high segmentation performance, while at the same time provide meaningful uncertainty maps that can be used for out-of-distribution detection.