 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Modeling with Phase Stochastic Bridges
Oct 13, 2023
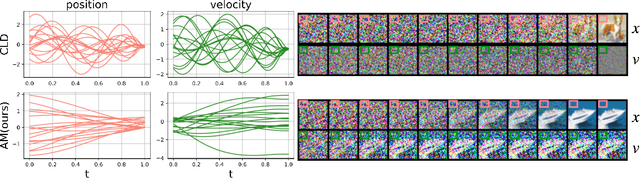

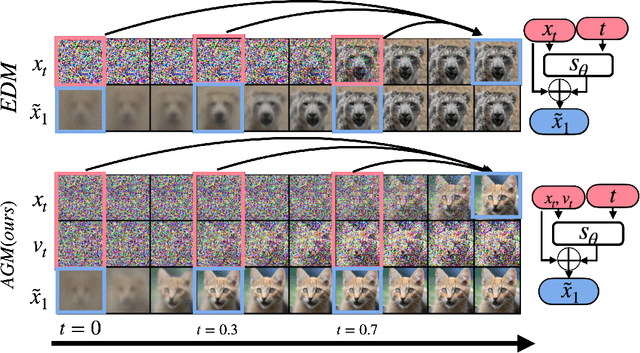

Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space), and using a neural network to reverse it. In this work, we introduce a novel generative modeling framework grounded in \textbf{phase space dynamics}, where a phase space is defined as {an augmented space encompassing both position and velocity.} Leveraging insights from Stochastic Optimal Control, we construct a path measure in the phase space that enables efficient sampling. {In contrast to DMs, our framework demonstrates the capability to generate realistic data points at an early stage of dynamics propagation.} This early prediction sets the stage for efficient data generation by leveraging additional velocity information along the trajectory. On standard image generation benchmarks, our model yields favorable performance over baselines in the regime of small Number of Function Evaluations (NFEs). Furthermore, our approach rivals the performance of diffusion models equipped with efficient sampling techniques, underscoring its potential as a new tool generative modeling.
ECPC-IDS:A benchmark endometrail cancer PET/CT image dataset for evaluation of semantic segmentation and detection of hypermetabolic regions
Sep 02, 2023
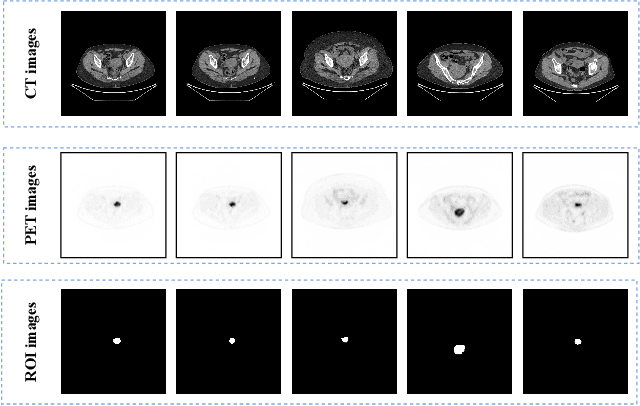
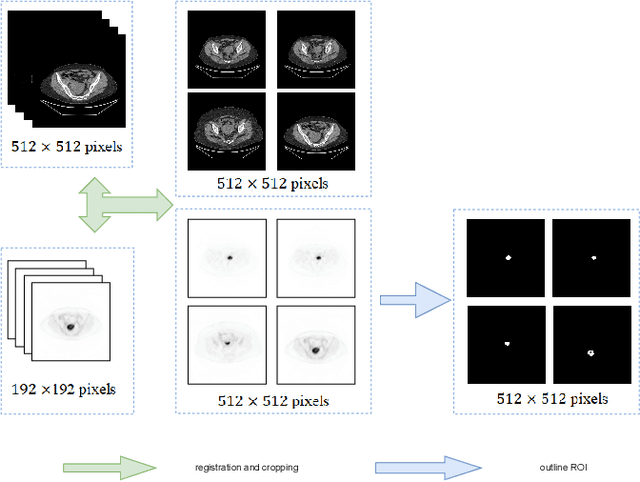
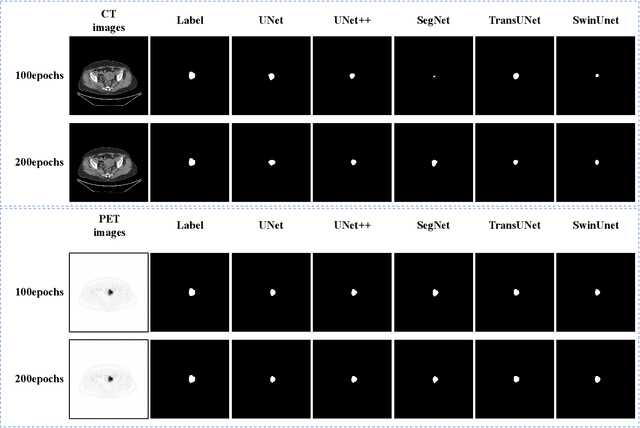
Endometrial cancer is one of the most common tumors in the female reproductive system and is the third most common gynecological malignancy that causes death after ovarian and cervical cancer. Early diagnosis can significantly improve the 5-year survival rate of patients. With the development of artificial intelligence, computer-assisted diagnosis plays an increasingly important role in improving the accuracy and objectivity of diagnosis, as well as reducing the workload of doctors. However, the absence of publicly available endometrial cancer image datasets restricts the application of computer-assisted diagnostic techniques.In this paper, a publicly available Endometrial Cancer PET/CT Image Dataset for Evaluation of Semantic Segmentation and Detection of Hypermetabolic Regions (ECPC-IDS) are published. Specifically, the segmentation section includes PET and CT images, with a total of 7159 images in multiple formats. In order to prove the effectiveness of segmentation methods on ECPC-IDS, five classical deep learning semantic segmentation methods are selected to test the image segmentation task. The object detection section also includes PET and CT images, with a total of 3579 images and XML files with annotation information. Six deep learning methods are selected for experiments on the detection task.This study conduct extensive experiments using deep learning-based semantic segmentation and object detection methods to demonstrate the differences between various methods on ECPC-IDS. As far as we know, this is the first publicly available dataset of endometrial cancer with a large number of multiple images, including a large amount of information required for image and target detection. ECPC-IDS can aid researchers in exploring new algorithms to enhance computer-assisted technology, benefiting both clinical doctors and patients greatly.
A Complementary Global and Local Knowledge Network for Ultrasound denoising with Fine-grained Refinement
Oct 05, 2023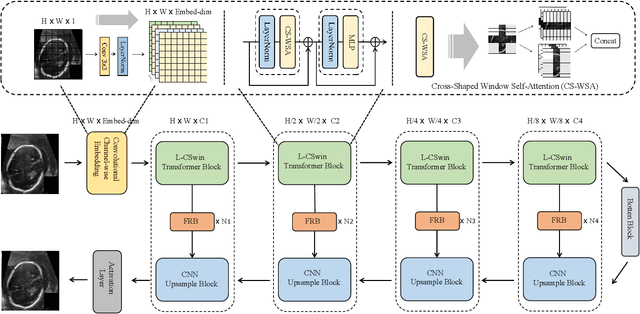
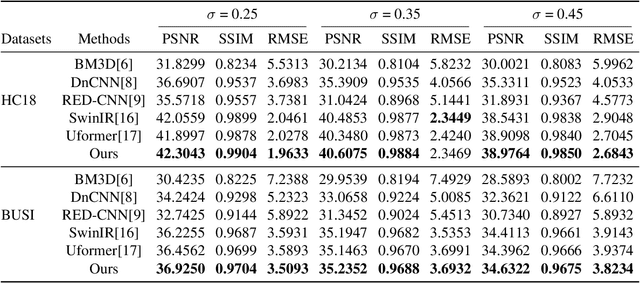
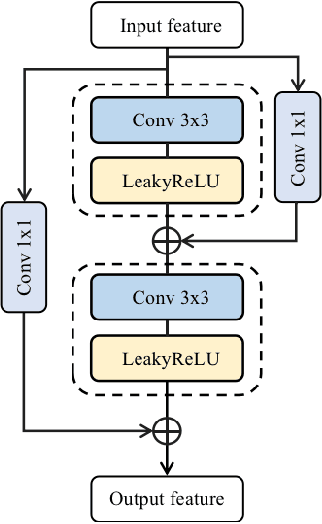
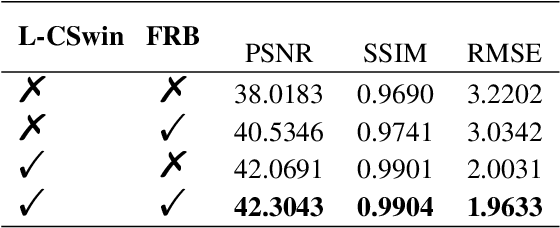
Ultrasound imaging serves as an effective and non-invasive diagnostic tool commonly employed in clinical examinations. However, the presence of speckle noise in ultrasound images invariably degrades image quality, impeding the performance of subsequent tasks, such as segmentation and classification. Existing methods for speckle noise reduction frequently induce excessive image smoothing or fail to preserve detailed information adequately. In this paper, we propose a complementary global and local knowledge network for ultrasound denoising with fine-grained refinement. Initially, the proposed architecture employs the L-CSwinTransformer as encoder to capture global information, incorporating CNN as decoder to fuse local features. We expand the resolution of the feature at different stages to extract more global information compared to the original CSwinTransformer. Subsequently, we integrate Fine-grained Refinement Block (FRB) within the skip-connection stage to further augment features. We validate our model on two public datasets, HC18 and BUSI. Experimental results demonstrate that our model can achieve competitive performance in both quantitative metrics and visual performance. Our code will be available at https://github.com/AAlkaid/USDenoising.
USB-NeRF: Unrolling Shutter Bundle Adjusted Neural Radiance Fields
Oct 05, 2023

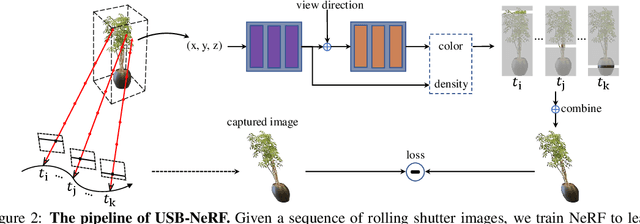
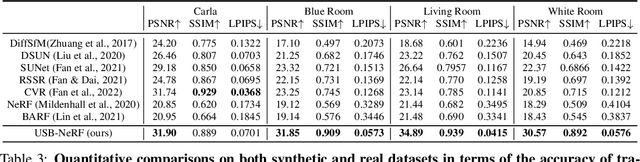
Neural Radiance Fields (NeRF) has received much attention recently due to its impressive capability to represent 3D scene and synthesize novel view images. Existing works usually assume that the input images are captured by a global shutter camera. Thus, rolling shutter (RS) images cannot be trivially applied to an off-the-shelf NeRF algorithm for novel view synthesis. Rolling shutter effect would also affect the accuracy of the camera pose estimation (e.g. via COLMAP), which further prevents the success of NeRF algorithm with RS images. In this paper, we propose Unrolling Shutter Bundle Adjusted Neural Radiance Fields (USB-NeRF). USB-NeRF is able to correct rolling shutter distortions and recover accurate camera motion trajectory simultaneously under the framework of NeRF, by modeling the physical image formation process of a RS camera. Experimental results demonstrate that USB-NeRF achieves better performance compared to prior works, in terms of RS effect removal, novel view image synthesis as well as camera motion estimation. Furthermore, our algorithm can also be used to recover high-fidelity high frame-rate global shutter video from a sequence of RS images.
Learning Interactive Real-World Simulators
Oct 09, 2023

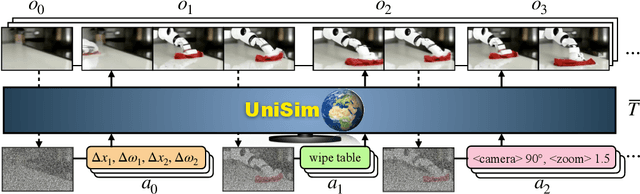

Generative models trained on internet data have revolutionized how text, image, and video content can be created. Perhaps the next milestone for generative models is to simulate realistic experience in response to actions taken by humans, robots, and other interactive agents. Applications of a real-world simulator range from controllable content creation in games and movies, to training embodied agents purely in simulation that can be directly deployed in the real world. We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling. We first make the important observation that natural datasets available for learning a real-world simulator are often rich along different axes (e.g., abundant objects in image data, densely sampled actions in robotics data, and diverse movements in navigation data). With careful orchestration of diverse datasets, each providing a different aspect of the overall experience, UniSim can emulate how humans and agents interact with the world by simulating the visual outcome of both high-level instructions such as "open the drawer" and low-level controls such as "move by x, y" from otherwise static scenes and objects. There are numerous use cases for such a real-world simulator. As an example, we use UniSim to train both high-level vision-language planners and low-level reinforcement learning policies, each of which exhibit zero-shot real-world transfer after training purely in a learned real-world simulator. We also show that other types of intelligence such as video captioning models can benefit from training with simulated experience in UniSim, opening up even wider applications. Video demos can be found at https://universal-simulator.github.io.
Safe and Robust Watermark Injection with a Single OoD Image
Sep 04, 2023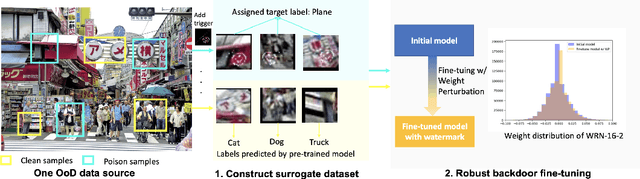

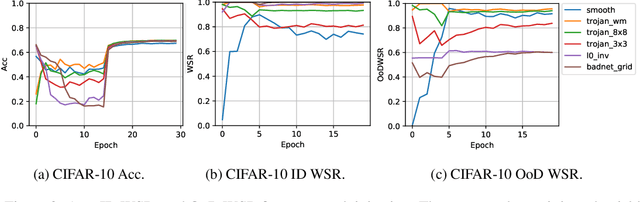
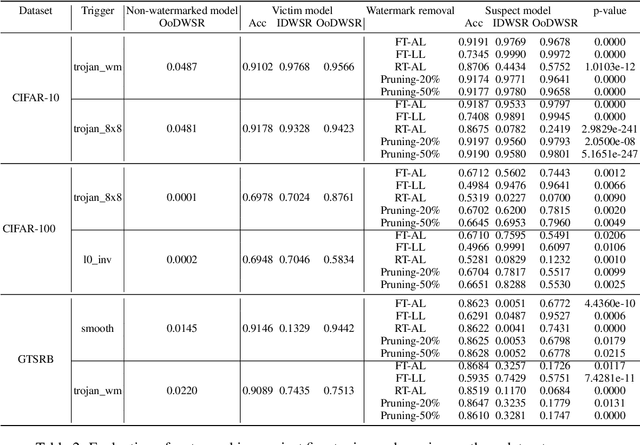
Training a high-performance deep neural network requires large amounts of data and computational resources. Protecting the intellectual property (IP) and commercial ownership of a deep model is challenging yet increasingly crucial. A major stream of watermarking strategies implants verifiable backdoor triggers by poisoning training samples, but these are often unrealistic due to data privacy and safety concerns and are vulnerable to minor model changes such as fine-tuning. To overcome these challenges, we propose a safe and robust backdoor-based watermark injection technique that leverages the diverse knowledge from a single out-of-distribution (OoD) image, which serves as a secret key for IP verification. The independence of training data makes it agnostic to third-party promises of IP security. We induce robustness via random perturbation of model parameters during watermark injection to defend against common watermark removal attacks, including fine-tuning, pruning, and model extraction. Our experimental results demonstrate that the proposed watermarking approach is not only time- and sample-efficient without training data, but also robust against the watermark removal attacks above.
Small Visual Language Models can also be Open-Ended Few-Shot Learners
Sep 30, 2023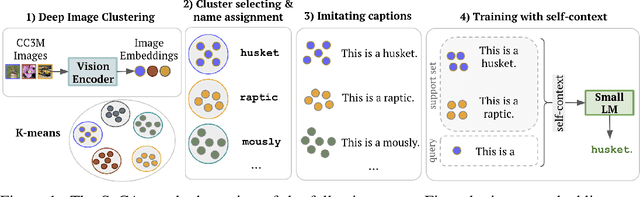
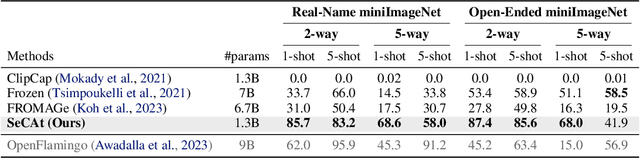
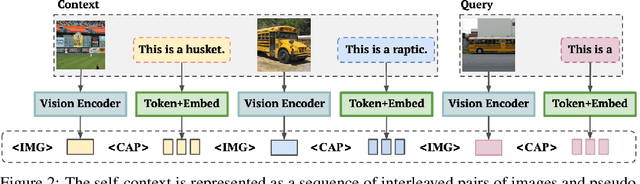
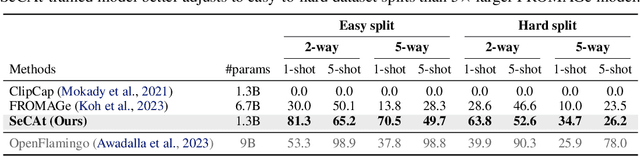
We present Self-Context Adaptation (SeCAt), a self-supervised approach that unlocks open-ended few-shot abilities of small visual language models. Our proposed adaptation algorithm explicitly learns from symbolic, yet self-supervised training tasks. Specifically, our approach imitates image captions in a self-supervised way based on clustering a large pool of images followed by assigning semantically-unrelated names to clusters. By doing so, we construct the `self-context', a training signal consisting of interleaved sequences of image and pseudo-caption pairs and a query image for which the model is trained to produce the right pseudo-caption. We demonstrate the performance and flexibility of SeCAt on several multimodal few-shot datasets, spanning various granularities. By using models with approximately 1B parameters we outperform the few-shot abilities of much larger models, such as Frozen and FROMAGe. SeCAt opens new possibilities for research in open-ended few-shot learning that otherwise requires access to large or proprietary models.
LOVECon: Text-driven Training-Free Long Video Editing with ControlNet
Oct 15, 2023Leveraging pre-trained conditional diffusion models for video editing without further tuning has gained increasing attention due to its promise in film production, advertising, etc. Yet, seminal works in this line fall short in generation length, temporal coherence, or fidelity to the source video. This paper aims to bridge the gap, establishing a simple and effective baseline for training-free diffusion model-based long video editing. As suggested by prior arts, we build the pipeline upon ControlNet, which excels at various image editing tasks based on text prompts. To break down the length constraints caused by limited computational memory, we split the long video into consecutive windows and develop a novel cross-window attention mechanism to ensure the consistency of global style and maximize the smoothness among windows. To achieve more accurate control, we extract the information from the source video via DDIM inversion and integrate the outcomes into the latent states of the generations. We also incorporate a video frame interpolation model to mitigate the frame-level flickering issue. Extensive empirical studies verify the superior efficacy of our method over competing baselines across scenarios, including the replacement of the attributes of foreground objects, style transfer, and background replacement. In particular, our method manages to edit videos with up to 128 frames according to user requirements. Code is available at https://github.com/zhijie-group/LOVECon.
FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
Oct 15, 2023The workload of real-time rendering is steeply increasing as the demand for high resolution, high refresh rates, and high realism rises, overwhelming most graphics cards. To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a.k.a. super-resolution techniques. Most existing methods focus on exploiting information from low-resolution inputs, such as historical frames. The absence of high frequency details in those LR inputs makes them hard to recover fine details in their high-resolution predictions. In this paper, we propose an efficient and effective super-resolution method that predicts high-quality upsampled reconstructions utilizing low-cost high-resolution auxiliary G-Buffers as additional input. With LR images and HR G-buffers as input, the network requires to align and fuse features at multi resolution levels. We introduce an efficient and effective H-Net architecture to solve this problem and significantly reduce rendering overhead without noticeable quality deterioration. Experiments show that our method is able to produce temporally consistent reconstructions in $4 \times 4$ and even challenging $8 \times 8$ upsampling cases at 4K resolution with real-time performance, with substantially improved quality and significant performance boost compared to existing works.
Provably Robust Cost-Sensitive Learning via Randomized Smoothing
Oct 12, 2023We focus on learning adversarially robust classifiers under a cost-sensitive scenario, where the potential harm of different classwise adversarial transformations is encoded in a binary cost matrix. Existing methods are either empirical that cannot certify robustness or suffer from inherent scalability issues. In this work, we study whether randomized smoothing, a more scalable robustness certification framework, can be leveraged to certify cost-sensitive robustness. Built upon a notion of cost-sensitive certified radius, we show how to adapt the standard randomized smoothing certification pipeline to produce tight robustness guarantees for any cost matrix. In addition, with fine-grained certified radius optimization schemes specifically designed for different data subgroups, we propose an algorithm to train smoothed classifiers that are optimized for cost-sensitive robustness. Extensive experiments on image benchmarks and a real-world medical dataset demonstrate the superiority of our method in achieving significantly improved performance of certified cost-sensitive robustness while having a negligible impact on overall accuracy.