 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Building Privacy-Preserving and Secure Geospatial Artificial Intelligence Foundation Models
Oct 12, 2023
In recent years we have seen substantial advances in foundation models for artificial intelligence, including language, vision, and multimodal models. Recent studies have highlighted the potential of using foundation models in geospatial artificial intelligence, known as GeoAI Foundation Models, for geographic question answering, remote sensing image understanding, map generation, and location-based services, among others. However, the development and application of GeoAI foundation models can pose serious privacy and security risks, which have not been fully discussed or addressed to date. This paper introduces the potential privacy and security risks throughout the lifecycle of GeoAI foundation models and proposes a comprehensive blueprint for research directions and preventative and control strategies. Through this vision paper, we hope to draw the attention of researchers and policymakers in geospatial domains to these privacy and security risks inherent in GeoAI foundation models and advocate for the development of privacy-preserving and secure GeoAI foundation models.
* 1 figure
Deep Image Harmonization with Learnable Augmentation
Aug 01, 2023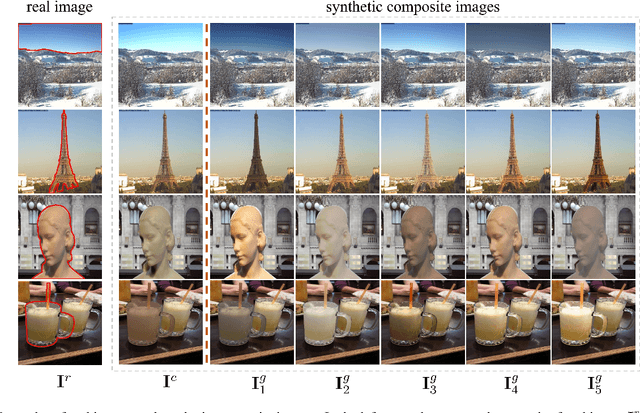
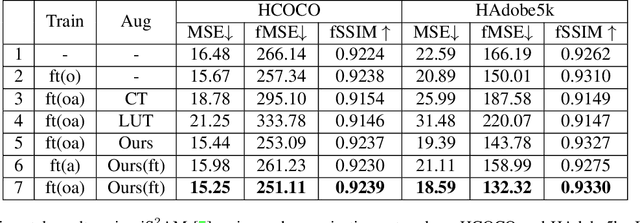


The goal of image harmonization is adjusting the foreground appearance in a composite image to make the whole image harmonious. To construct paired training images, existing datasets adopt different ways to adjust the illumination statistics of foregrounds of real images to produce synthetic composite images. However, different datasets have considerable domain gap and the performances on small-scale datasets are limited by insufficient training data. In this work, we explore learnable augmentation to enrich the illumination diversity of small-scale datasets for better harmonization performance. In particular, our designed SYthetic COmposite Network (SycoNet) takes in a real image with foreground mask and a random vector to learn suitable color transformation, which is applied to the foreground of this real image to produce a synthetic composite image. Comprehensive experiments demonstrate the effectiveness of our proposed learnable augmentation for image harmonization. The code of SycoNet is released at https://github.com/bcmi/SycoNet-Adaptive-Image-Harmonization.
SelfGraphVQA: A Self-Supervised Graph Neural Network for Scene-based Question Answering
Oct 03, 2023The intersection of vision and language is of major interest due to the increased focus on seamless integration between recognition and reasoning. Scene graphs (SGs) have emerged as a useful tool for multimodal image analysis, showing impressive performance in tasks such as Visual Question Answering (VQA). In this work, we demonstrate that despite the effectiveness of scene graphs in VQA tasks, current methods that utilize idealized annotated scene graphs struggle to generalize when using predicted scene graphs extracted from images. To address this issue, we introduce the SelfGraphVQA framework. Our approach extracts a scene graph from an input image using a pre-trained scene graph generator and employs semantically-preserving augmentation with self-supervised techniques. This method improves the utilization of graph representations in VQA tasks by circumventing the need for costly and potentially biased annotated data. By creating alternative views of the extracted graphs through image augmentations, we can learn joint embeddings by optimizing the informational content in their representations using an un-normalized contrastive approach. As we work with SGs, we experiment with three distinct maximization strategies: node-wise, graph-wise, and permutation-equivariant regularization. We empirically showcase the effectiveness of the extracted scene graph for VQA and demonstrate that these approaches enhance overall performance by highlighting the significance of visual information. This offers a more practical solution for VQA tasks that rely on SGs for complex reasoning questions.
Occlusion-Free Image Based Visual Servoing using Probabilistic Control Barrier Certificates
Sep 07, 2023Image-based visual servoing (IBVS) is a widely-used approach in robotics that employs visual information to guide robots towards desired positions. However, occlusions in this approach can lead to visual servoing failure and degrade the control performance due to the obstructed vision feature points that are essential for providing visual feedback. In this paper, we propose a Control Barrier Function (CBF) based controller that enables occlusion-free IBVS tasks by automatically adjusting the robot's configuration to keep the feature points in the field of view and away from obstacles. In particular, to account for measurement noise of the feature points, we develop the Probabilistic Control Barrier Certificates (PrCBC) using control barrier functions that encode the chance-constrained occlusion avoidance constraints under uncertainty into deterministic admissible control space for the robot, from which the resulting configuration of robot ensures that the feature points stay occlusion free from obstacles with a satisfying predefined probability. By integrating such constraints with a Model Predictive Control (MPC) framework, the sequence of optimized control inputs can be derived to achieve the primary IBVS task while enforcing the occlusion avoidance during robot movements. Simulation results are provided to validate the performance of our proposed method.
Evading Detection Actively: Toward Anti-Forensics against Forgery Localization
Oct 16, 2023Anti-forensics seeks to eliminate or conceal traces of tampering artifacts. Typically, anti-forensic methods are designed to deceive binary detectors and persuade them to misjudge the authenticity of an image. However, to the best of our knowledge, no attempts have been made to deceive forgery detectors at the pixel level and mis-locate forged regions. Traditional adversarial attack methods cannot be directly used against forgery localization due to the following defects: 1) they tend to just naively induce the target forensic models to flip their pixel-level pristine or forged decisions; 2) their anti-forensics performance tends to be severely degraded when faced with the unseen forensic models; 3) they lose validity once the target forensic models are retrained with the anti-forensics images generated by them. To tackle the three defects, we propose SEAR (Self-supErvised Anti-foRensics), a novel self-supervised and adversarial training algorithm that effectively trains deep-learning anti-forensic models against forgery localization. SEAR sets a pretext task to reconstruct perturbation for self-supervised learning. In adversarial training, SEAR employs a forgery localization model as a supervisor to explore tampering features and constructs a deep-learning concealer to erase corresponding traces. We have conducted largescale experiments across diverse datasets. The experimental results demonstrate that, through the combination of self-supervised learning and adversarial learning, SEAR successfully deceives the state-of-the-art forgery localization methods, as well as tackle the three defects regarding traditional adversarial attack methods mentioned above.
Prior-Free Continual Learning with Unlabeled Data in the Wild
Oct 16, 2023Continual Learning (CL) aims to incrementally update a trained model on new tasks without forgetting the acquired knowledge of old ones. Existing CL methods usually reduce forgetting with task priors, \ie using task identity or a subset of previously seen samples for model training. However, these methods would be infeasible when such priors are unknown in real-world applications. To address this fundamental but seldom-studied problem, we propose a Prior-Free Continual Learning (PFCL) method, which learns new tasks without knowing the task identity or any previous data. First, based on a fixed single-head architecture, we eliminate the need for task identity to select the task-specific output head. Second, we employ a regularization-based strategy for consistent predictions between the new and old models, avoiding revisiting previous samples. However, using this strategy alone often performs poorly in class-incremental scenarios, particularly for a long sequence of tasks. By analyzing the effectiveness and limitations of conventional regularization-based methods, we propose enhancing model consistency with an auxiliary unlabeled dataset additionally. Moreover, since some auxiliary data may degrade the performance, we further develop a reliable sample selection strategy to obtain consistent performance improvement. Extensive experiments on multiple image classification benchmark datasets show that our PFCL method significantly mitigates forgetting in all three learning scenarios. Furthermore, when compared to the most recent rehearsal-based methods that replay a limited number of previous samples, PFCL achieves competitive accuracy. Our code is available at: https://github.com/visiontao/pfcl
On the Transferability of Learning Models for Semantic Segmentation for Remote Sensing Data
Oct 16, 2023Recent deep learning-based methods outperform traditional learning methods on remote sensing (RS) semantic segmentation/classification tasks. However, they require large training datasets and are generally known for lack of transferability due to the highly disparate RS image content across different geographical regions. Yet, there is no comprehensive analysis of their transferability, i.e., to which extent a model trained on a source domain can be readily applicable to a target domain. Therefore, in this paper, we aim to investigate the raw transferability of traditional and deep learning (DL) models, as well as the effectiveness of domain adaptation (DA) approaches in enhancing the transferability of the DL models (adapted transferability). By utilizing four highly diverse RS datasets, we train six models with and without three DA approaches to analyze their transferability between these datasets quantitatively. Furthermore, we developed a straightforward method to quantify the transferability of a model using the spectral indices as a medium and have demonstrated its effectiveness in evaluating the model transferability at the target domain when the labels are unavailable. Our experiments yield several generally important yet not well-reported observations regarding the raw and adapted transferability. Moreover, our proposed label-free transferability assessment method is validated to be better than posterior model confidence. The findings can guide the future development of generalized RS learning models. The trained models are released under this link: https://github.com/GDAOSU/Transferability-Remote-Sensing
Towards Free Data Selection with General-Purpose Models
Oct 14, 2023

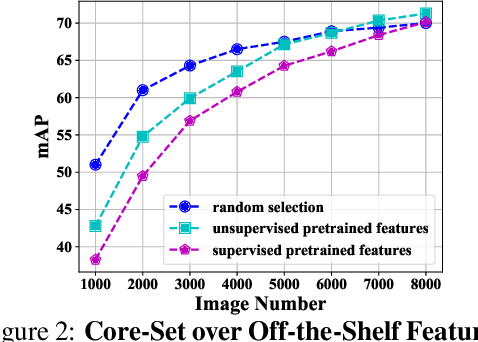
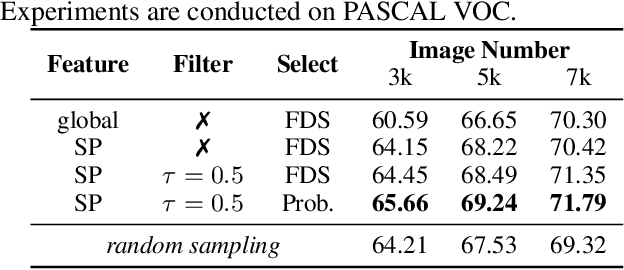
A desirable data selection algorithm can efficiently choose the most informative samples to maximize the utility of limited annotation budgets. However, current approaches, represented by active learning methods, typically follow a cumbersome pipeline that iterates the time-consuming model training and batch data selection repeatedly. In this paper, we challenge this status quo by designing a distinct data selection pipeline that utilizes existing general-purpose models to select data from various datasets with a single-pass inference without the need for additional training or supervision. A novel free data selection (FreeSel) method is proposed following this new pipeline. Specifically, we define semantic patterns extracted from inter-mediate features of the general-purpose model to capture subtle local information in each image. We then enable the selection of all data samples in a single pass through distance-based sampling at the fine-grained semantic pattern level. FreeSel bypasses the heavy batch selection process, achieving a significant improvement in efficiency and being 530x faster than existing active learning methods. Extensive experiments verify the effectiveness of FreeSel on various computer vision tasks. Our code is available at https://github.com/yichen928/FreeSel.
UCM-Net: A Lightweight and Efficient Solution for Skin Lesion Segmentation using MLP and CNN
Oct 14, 2023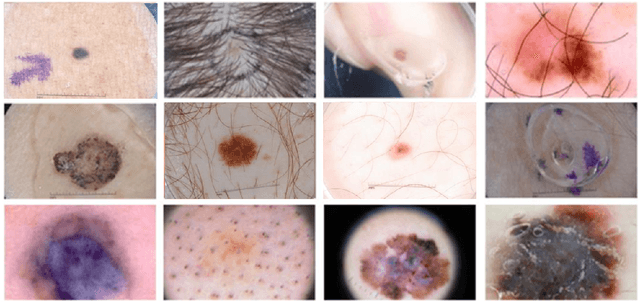
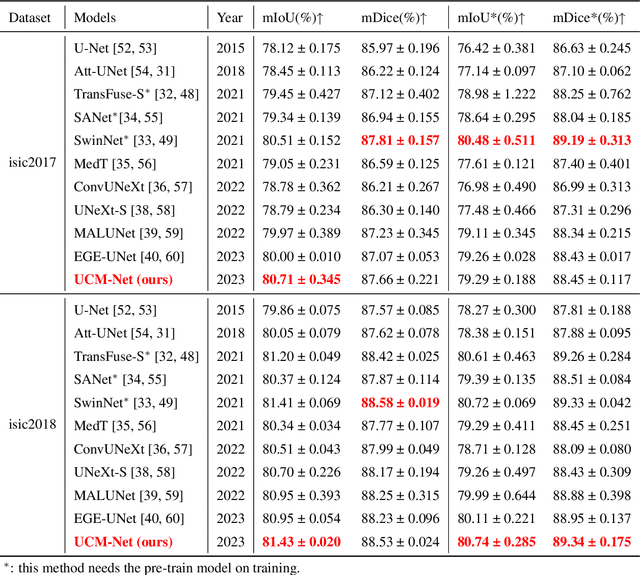

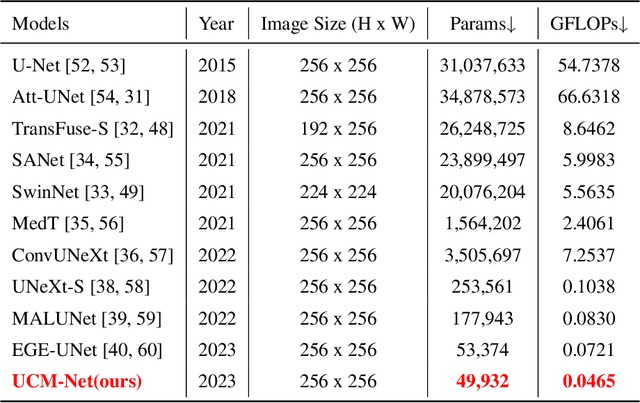
Skin cancer is a significant public health problem, and computer-aided diagnosis can help to prevent and treat it. A crucial step for computer-aided diagnosis is accurately segmenting skin lesions in images, which allows for lesion detection, classification, and analysis. However, this task is challenging due to the diverse characteristics of lesions, such as appearance, shape, size, color, texture, and location, as well as image quality issues like noise, artifacts, and occlusions. Deep learning models have recently been applied to skin lesion segmentation, but they have high parameter counts and computational demands, making them unsuitable for mobile health applications. To address this challenge, we propose UCM-Net, a novel, efficient, and lightweight solution that integrates Multi-Layer Perceptions (MLP) and Convolutional Neural Networks (CNN). Unlike conventional UNet architectures, our UCMNet-Block reduces parameter overhead and enhances UCM-Net's learning capabilities, leading to robust segmentation performance. We validate UCM-Net's competitiveness through extensive experiments on isic2017 and isic2018 datasets. Remarkably, UCM-Net has less than 50KB parameters and less than 0.05 Giga-Operations Per Second (GLOPs), setting a new possible standard for efficiency in skin lesion segmentation. The source code will be publicly available.
Towards More Accurate Diffusion Model Acceleration with A Timestep Aligner
Oct 14, 2023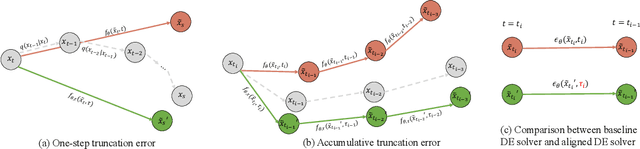
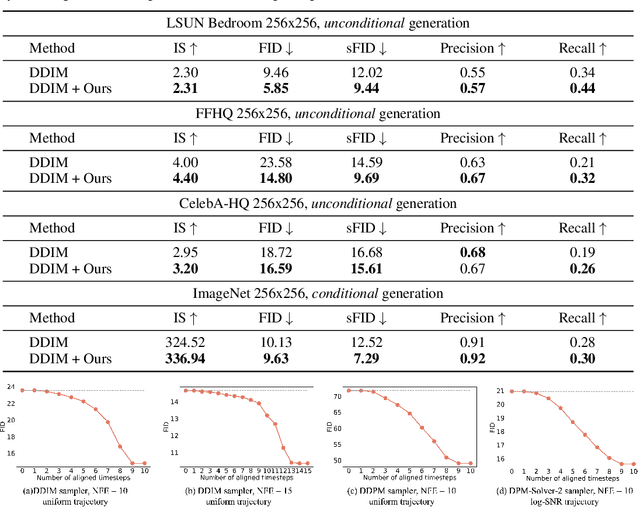
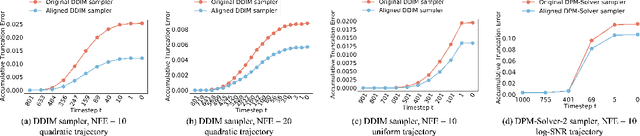

A diffusion model, which is formulated to produce an image using thousands of denoising steps, usually suffers from a slow inference speed. Existing acceleration algorithms simplify the sampling by skipping most steps yet exhibit considerable performance degradation. By viewing the generation of diffusion models as a discretized integrating process, we argue that the quality drop is partly caused by applying an inaccurate integral direction to a timestep interval. To rectify this issue, we propose a timestep aligner that helps find a more accurate integral direction for a particular interval at the minimum cost. Specifically, at each denoising step, we replace the original parameterization by conditioning the network on a new timestep, which is obtained by aligning the sampling distribution to the real distribution. Extensive experiments show that our plug-in design can be trained efficiently and boost the inference performance of various state-of-the-art acceleration methods, especially when there are few denoising steps. For example, when using 10 denoising steps on the popular LSUN Bedroom dataset, we improve the FID of DDIM from 9.65 to 6.07, simply by adopting our method for a more appropriate set of timesteps. Code will be made publicly available.