 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LocoNeRF: A NeRF-based Approach for Local Structure from Motion for Precise Localization
Oct 08, 2023



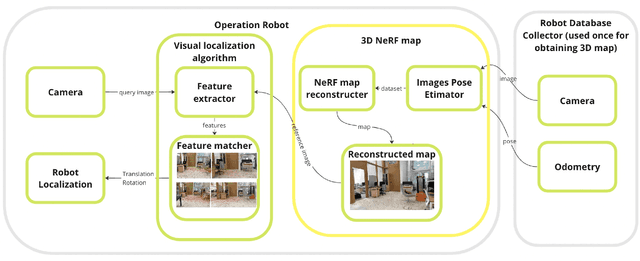
Visual localization is a critical task in mobile robotics, and researchers are continuously developing new approaches to enhance its efficiency. In this article, we propose a novel approach to improve the accuracy of visual localization using Structure from Motion (SfM) techniques. We highlight the limitations of global SfM, which suffers from high latency, and the challenges of local SfM, which requires large image databases for accurate reconstruction. To address these issues, we propose utilizing Neural Radiance Fields (NeRF), as opposed to image databases, to cut down on the space required for storage. We suggest that sampling reference images around the prior query position can lead to further improvements. We evaluate the accuracy of our proposed method against ground truth obtained using LIDAR and Advanced Lidar Odometry and Mapping in Real-time (A-LOAM), and compare its storage usage against local SfM with COLMAP in the conducted experiments. Our proposed method achieves an accuracy of 0.068 meters compared to the ground truth, which is slightly lower than the most advanced method COLMAP, which has an accuracy of 0.022 meters. However, the size of the database required for COLMAP is 400 megabytes, whereas the size of our NeRF model is only 160 megabytes. Finally, we perform an ablation study to assess the impact of using reference images from the NeRF reconstruction.
HairCLIPv2: Unifying Hair Editing via Proxy Feature Blending
Oct 16, 2023Hair editing has made tremendous progress in recent years. Early hair editing methods use well-drawn sketches or masks to specify the editing conditions. Even though they can enable very fine-grained local control, such interaction modes are inefficient for the editing conditions that can be easily specified by language descriptions or reference images. Thanks to the recent breakthrough of cross-modal models (e.g., CLIP), HairCLIP is the first work that enables hair editing based on text descriptions or reference images. However, such text-driven and reference-driven interaction modes make HairCLIP unable to support fine-grained controls specified by sketch or mask. In this paper, we propose HairCLIPv2, aiming to support all the aforementioned interactions with one unified framework. Simultaneously, it improves upon HairCLIP with better irrelevant attributes (e.g., identity, background) preservation and unseen text descriptions support. The key idea is to convert all the hair editing tasks into hair transfer tasks, with editing conditions converted into different proxies accordingly. The editing effects are added upon the input image by blending the corresponding proxy features within the hairstyle or hair color feature spaces. Besides the unprecedented user interaction mode support, quantitative and qualitative experiments demonstrate the superiority of HairCLIPv2 in terms of editing effects, irrelevant attribute preservation and visual naturalness. Our code is available at \url{https://github.com/wty-ustc/HairCLIPv2}.
ZoomTrack: Target-aware Non-uniform Resizing for Efficient Visual Tracking
Oct 16, 2023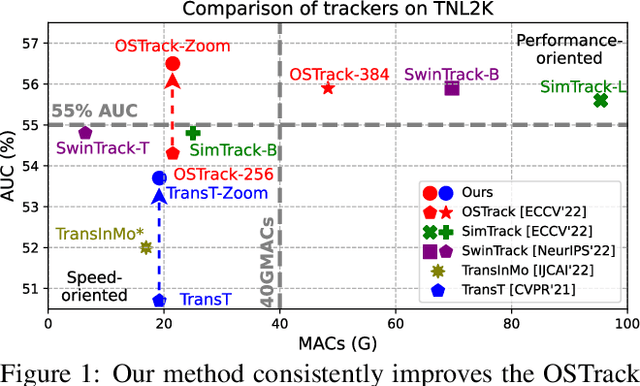
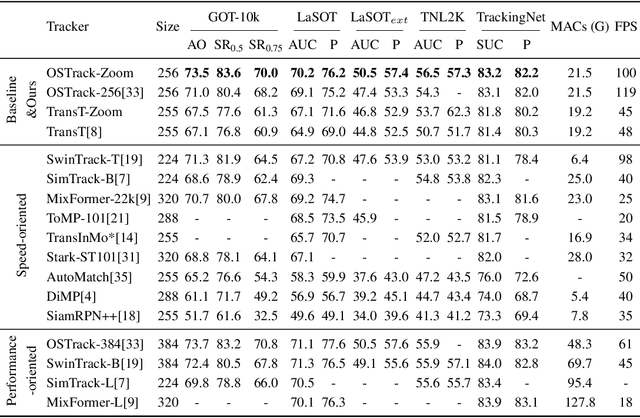
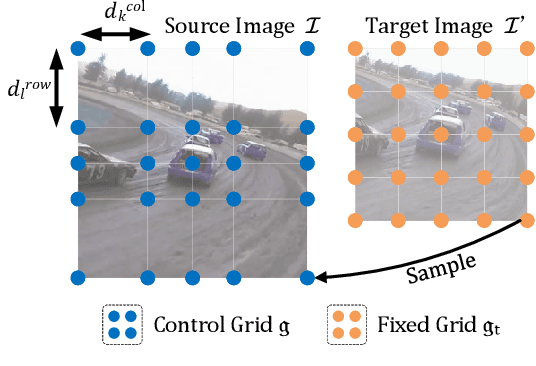
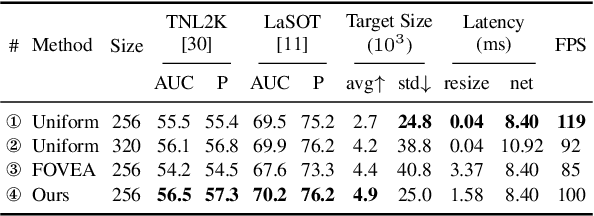
Recently, the transformer has enabled the speed-oriented trackers to approach state-of-the-art (SOTA) performance with high-speed thanks to the smaller input size or the lighter feature extraction backbone, though they still substantially lag behind their corresponding performance-oriented versions. In this paper, we demonstrate that it is possible to narrow or even close this gap while achieving high tracking speed based on the smaller input size. To this end, we non-uniformly resize the cropped image to have a smaller input size while the resolution of the area where the target is more likely to appear is higher and vice versa. This enables us to solve the dilemma of attending to a larger visual field while retaining more raw information for the target despite a smaller input size. Our formulation for the non-uniform resizing can be efficiently solved through quadratic programming (QP) and naturally integrated into most of the crop-based local trackers. Comprehensive experiments on five challenging datasets based on two kinds of transformer trackers, \ie, OSTrack and TransT, demonstrate consistent improvements over them. In particular, applying our method to the speed-oriented version of OSTrack even outperforms its performance-oriented counterpart by 0.6% AUC on TNL2K, while running 50% faster and saving over 55% MACs. Codes and models are available at https://github.com/Kou-99/ZoomTrack.
Generating Image-Specific Text Improves Fine-grained Image Classification
Jul 21, 2023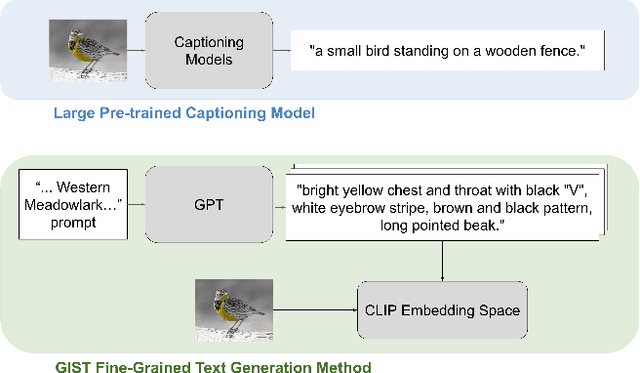
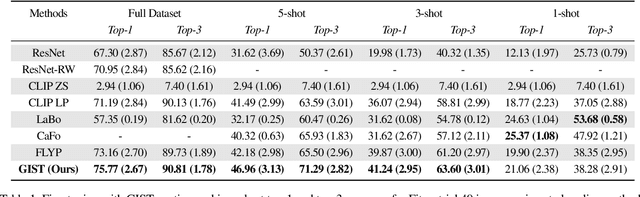
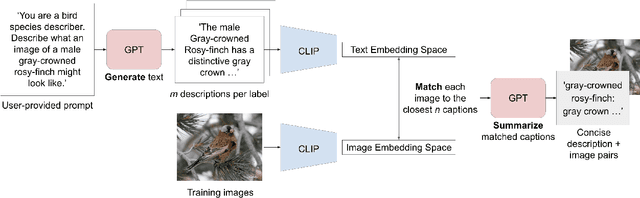
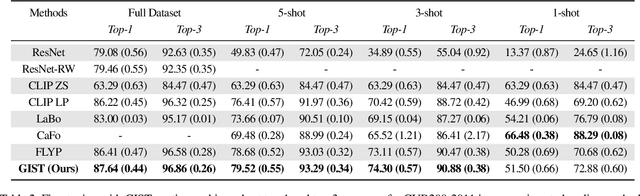
Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.
Imperceptible Adversarial Attack on Deep Neural Networks from Image Boundary
Aug 29, 2023
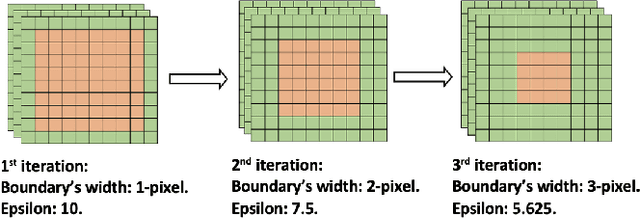
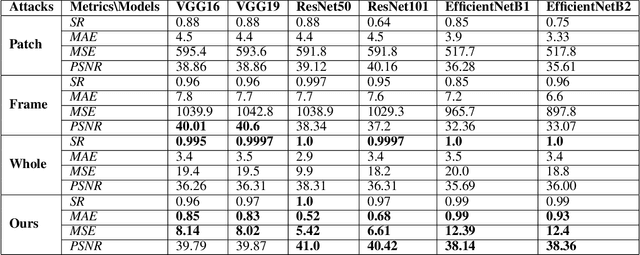
Although Deep Neural Networks (DNNs), such as the convolutional neural networks (CNN) and Vision Transformers (ViTs), have been successfully applied in the field of computer vision, they are demonstrated to be vulnerable to well-sought Adversarial Examples (AEs) that can easily fool the DNNs. The research in AEs has been active, and many adversarial attacks and explanations have been proposed since they were discovered in 2014. The mystery of the AE's existence is still an open question, and many studies suggest that DNN training algorithms have blind spots. The salient objects usually do not overlap with boundaries; hence, the boundaries are not the DNN model's attention. Nevertheless, recent studies show that the boundaries can dominate the behavior of the DNN models. Hence, this study aims to look at the AEs from a different perspective and proposes an imperceptible adversarial attack that systemically attacks the input image boundary for finding the AEs. The experimental results have shown that the proposed boundary attacking method effectively attacks six CNN models and the ViT using only 32% of the input image content (from the boundaries) with an average success rate (SR) of 95.2% and an average peak signal-to-noise ratio of 41.37 dB. Correlation analyses are conducted, including the relation between the adversarial boundary's width and the SR and how the adversarial boundary changes the DNN model's attention. This paper's discoveries can potentially advance the understanding of AEs and provide a different perspective on how AEs can be constructed.
Occlusion-Free Image Based Visual Servoing using Probabilistic Control Barrier Certificates
Sep 07, 2023Image-based visual servoing (IBVS) is a widely-used approach in robotics that employs visual information to guide robots towards desired positions. However, occlusions in this approach can lead to visual servoing failure and degrade the control performance due to the obstructed vision feature points that are essential for providing visual feedback. In this paper, we propose a Control Barrier Function (CBF) based controller that enables occlusion-free IBVS tasks by automatically adjusting the robot's configuration to keep the feature points in the field of view and away from obstacles. In particular, to account for measurement noise of the feature points, we develop the Probabilistic Control Barrier Certificates (PrCBC) using control barrier functions that encode the chance-constrained occlusion avoidance constraints under uncertainty into deterministic admissible control space for the robot, from which the resulting configuration of robot ensures that the feature points stay occlusion free from obstacles with a satisfying predefined probability. By integrating such constraints with a Model Predictive Control (MPC) framework, the sequence of optimized control inputs can be derived to achieve the primary IBVS task while enforcing the occlusion avoidance during robot movements. Simulation results are provided to validate the performance of our proposed method.
An automated approach for improving the inference latency and energy efficiency of pretrained CNNs by removing irrelevant pixels with focused convolutions
Oct 11, 2023Computer vision often uses highly accurate Convolutional Neural Networks (CNNs), but these deep learning models are associated with ever-increasing energy and computation requirements. Producing more energy-efficient CNNs often requires model training which can be cost-prohibitive. We propose a novel, automated method to make a pretrained CNN more energy-efficient without re-training. Given a pretrained CNN, we insert a threshold layer that filters activations from the preceding layers to identify regions of the image that are irrelevant, i.e. can be ignored by the following layers while maintaining accuracy. Our modified focused convolution operation saves inference latency (by up to 25%) and energy costs (by up to 22%) on various popular pretrained CNNs, with little to no loss in accuracy.
Mapping Memes to Words for Multimodal Hateful Meme Classification
Oct 12, 2023Multimodal image-text memes are prevalent on the internet, serving as a unique form of communication that combines visual and textual elements to convey humor, ideas, or emotions. However, some memes take a malicious turn, promoting hateful content and perpetuating discrimination. Detecting hateful memes within this multimodal context is a challenging task that requires understanding the intertwined meaning of text and images. In this work, we address this issue by proposing a novel approach named ISSUES for multimodal hateful meme classification. ISSUES leverages a pre-trained CLIP vision-language model and the textual inversion technique to effectively capture the multimodal semantic content of the memes. The experiments show that our method achieves state-of-the-art results on the Hateful Memes Challenge and HarMeme datasets. The code and the pre-trained models are publicly available at https://github.com/miccunifi/ISSUES.
Self-Reference Deep Adaptive Curve Estimation for Low-Light Image Enhancement
Aug 21, 2023
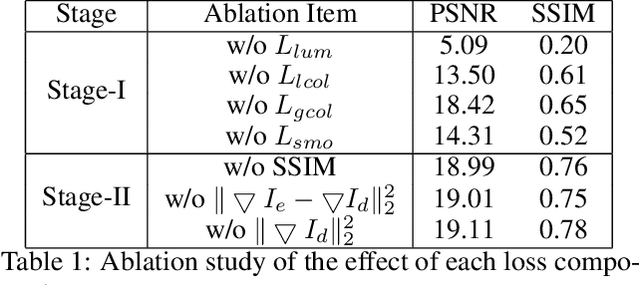
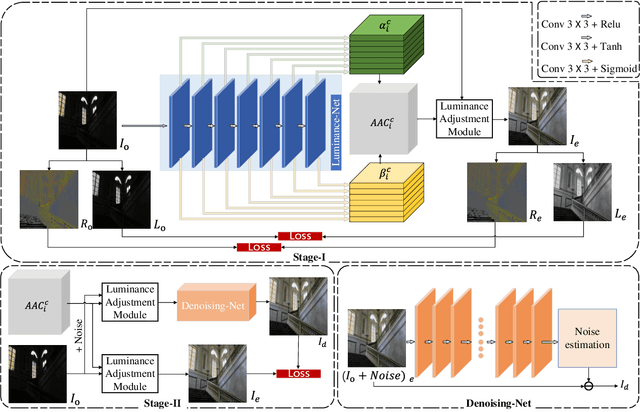
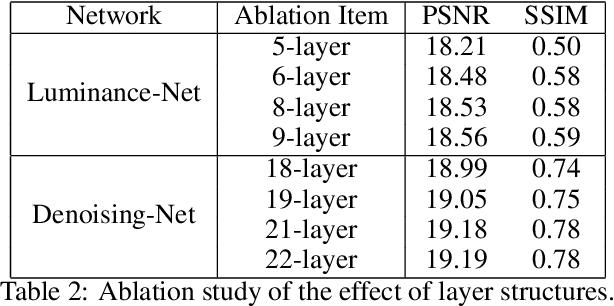
In this paper, we propose a 2-stage low-light image enhancement method called Self-Reference Deep Adaptive Curve Estimation (Self-DACE). In the first stage, we present an intuitive, lightweight, fast, and unsupervised luminance enhancement algorithm. The algorithm is based on a novel low-light enhancement curve that can be used to locally boost image brightness. We also propose a new loss function with a simplified physical model designed to preserve natural images' color, structure, and fidelity. We use a vanilla CNN to map each pixel through deep Adaptive Adjustment Curves (AAC) while preserving the local image structure. Secondly, we introduce the corresponding denoising scheme to remove the latent noise in the darkness. We approximately model the noise in the dark and deploy a Denoising-Net to estimate and remove the noise after the first stage. Exhaustive qualitative and quantitative analysis shows that our method outperforms existing state-of-the-art algorithms on multiple real-world datasets.
Self-Supervised Single-Image Deconvolution with Siamese Neural Networks
Aug 18, 2023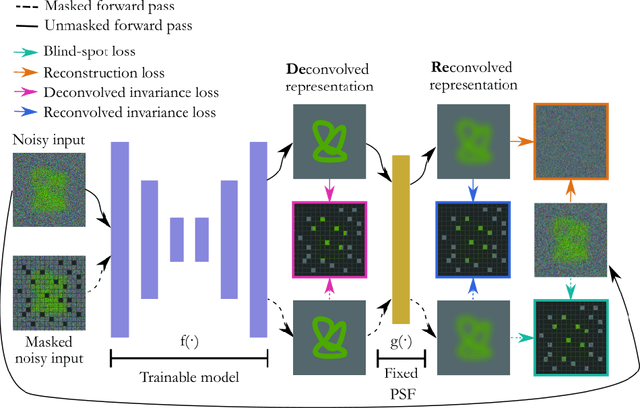
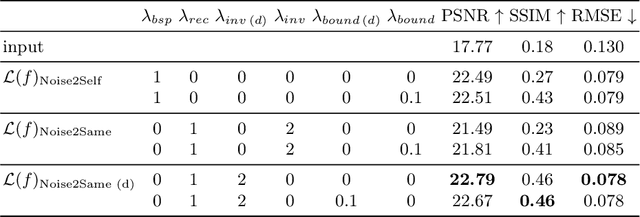
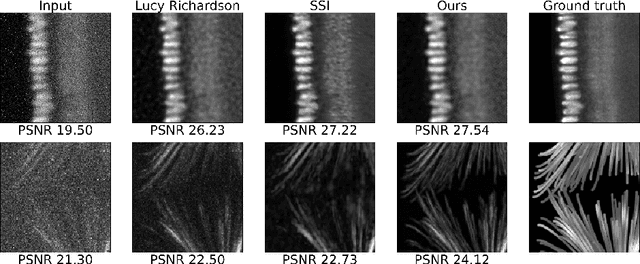
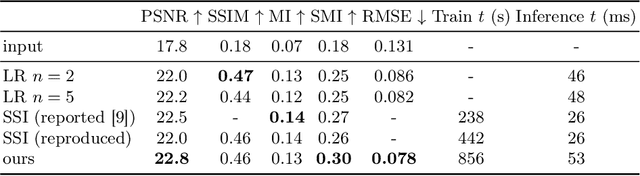
Inverse problems in image reconstruction are fundamentally complicated by unknown noise properties. Classical iterative deconvolution approaches amplify noise and require careful parameter selection for an optimal trade-off between sharpness and grain. Deep learning methods allow for flexible parametrization of the noise and learning its properties directly from the data. Recently, self-supervised blind-spot neural networks were successfully adopted for image deconvolution by including a known point-spread function in the end-to-end training. However, their practical application has been limited to 2D images in the biomedical domain because it implies large kernels that are poorly optimized. We tackle this problem with Fast Fourier Transform convolutions that provide training speed-up in 3D microscopy deconvolution tasks. Further, we propose to adopt a Siamese invariance loss for deconvolution and empirically identify its optimal position in the neural network between blind-spot and full image branches. The experimental results show that our improved framework outperforms the previous state-of-the-art deconvolution methods with a known point spread function.