 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LocoNeRF: A NeRF-based Approach for Local Structure from Motion for Precise Localization
Oct 08, 2023



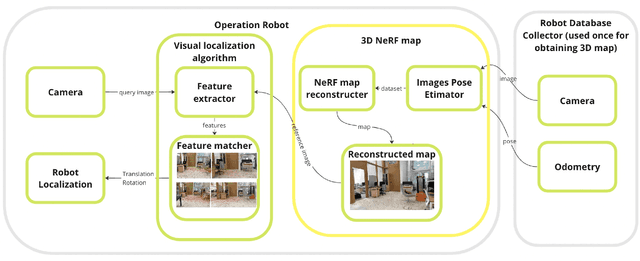
Visual localization is a critical task in mobile robotics, and researchers are continuously developing new approaches to enhance its efficiency. In this article, we propose a novel approach to improve the accuracy of visual localization using Structure from Motion (SfM) techniques. We highlight the limitations of global SfM, which suffers from high latency, and the challenges of local SfM, which requires large image databases for accurate reconstruction. To address these issues, we propose utilizing Neural Radiance Fields (NeRF), as opposed to image databases, to cut down on the space required for storage. We suggest that sampling reference images around the prior query position can lead to further improvements. We evaluate the accuracy of our proposed method against ground truth obtained using LIDAR and Advanced Lidar Odometry and Mapping in Real-time (A-LOAM), and compare its storage usage against local SfM with COLMAP in the conducted experiments. Our proposed method achieves an accuracy of 0.068 meters compared to the ground truth, which is slightly lower than the most advanced method COLMAP, which has an accuracy of 0.022 meters. However, the size of the database required for COLMAP is 400 megabytes, whereas the size of our NeRF model is only 160 megabytes. Finally, we perform an ablation study to assess the impact of using reference images from the NeRF reconstruction.
MosaiQ: Quantum Generative Adversarial Networks for Image Generation on NISQ Computers
Aug 22, 2023Quantum machine learning and vision have come to the fore recently, with hardware advances enabling rapid advancement in the capabilities of quantum machines. Recently, quantum image generation has been explored with many potential advantages over non-quantum techniques; however, previous techniques have suffered from poor quality and robustness. To address these problems, we introduce, MosaiQ, a high-quality quantum image generation GAN framework that can be executed on today's Near-term Intermediate Scale Quantum (NISQ) computers.
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Oct 18, 2023Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels. To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine 'diagram plans' (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision). We hope our work can inspire further research on diagram generation via T2I models and LLMs.
RL-based Stateful Neural Adaptive Sampling and Denoising for Real-Time Path Tracing
Oct 05, 2023Monte-Carlo path tracing is a powerful technique for realistic image synthesis but suffers from high levels of noise at low sample counts, limiting its use in real-time applications. To address this, we propose a framework with end-to-end training of a sampling importance network, a latent space encoder network, and a denoiser network. Our approach uses reinforcement learning to optimize the sampling importance network, thus avoiding explicit numerically approximated gradients. Our method does not aggregate the sampled values per pixel by averaging but keeps all sampled values which are then fed into the latent space encoder. The encoder replaces handcrafted spatiotemporal heuristics by learned representations in a latent space. Finally, a neural denoiser is trained to refine the output image. Our approach increases visual quality on several challenging datasets and reduces rendering times for equal quality by a factor of 1.6x compared to the previous state-of-the-art, making it a promising solution for real-time applications.
MOFA: A Model Simplification Roadmap for Image Restoration on Mobile Devices
Aug 24, 2023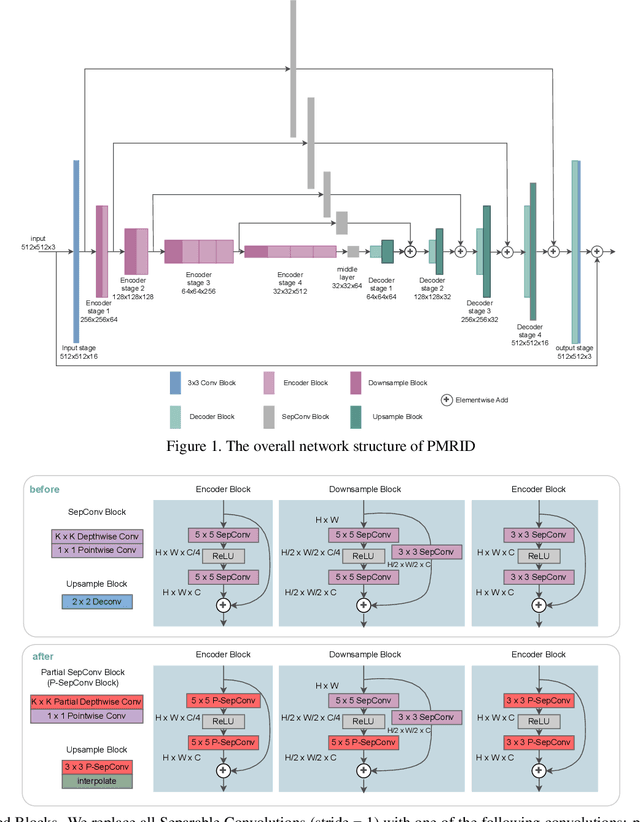
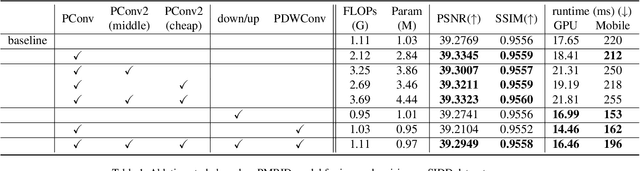
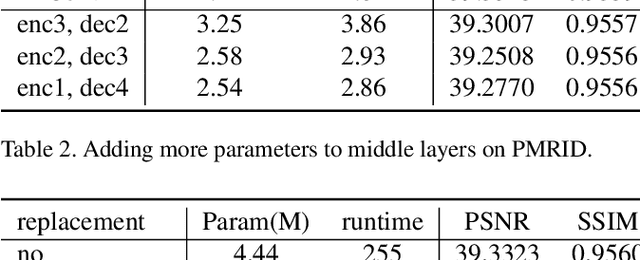

Image restoration aims to restore high-quality images from degraded counterparts and has seen significant advancements through deep learning techniques. The technique has been widely applied to mobile devices for tasks such as mobile photography. Given the resource limitations on mobile devices, such as memory constraints and runtime requirements, the efficiency of models during deployment becomes paramount. Nevertheless, most previous works have primarily concentrated on analyzing the efficiency of single modules and improving them individually. This paper examines the efficiency across different layers. We propose a roadmap that can be applied to further accelerate image restoration models prior to deployment while simultaneously increasing PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index). The roadmap first increases the model capacity by adding more parameters to partial convolutions on FLOPs non-sensitive layers. Then, it applies partial depthwise convolution coupled with decoupling upsampling/downsampling layers to accelerate the model speed. Extensive experiments demonstrate that our approach decreases runtime by up to 13% and reduces the number of parameters by up to 23%, while increasing PSNR and SSIM on several image restoration datasets. Source Code of our method is available at \href{https://github.com/xiangyu8/MOFA}{https://github.com/xiangyu8/MOFA}.
Transformer Fusion with Optimal Transport
Oct 15, 2023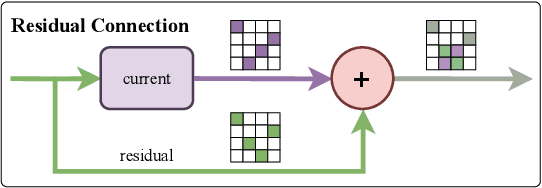
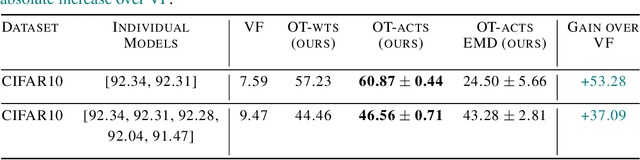
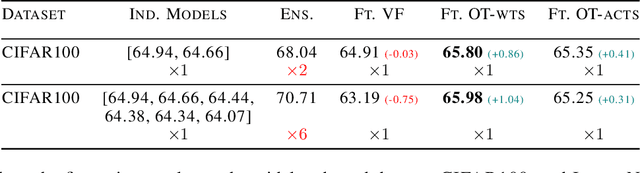
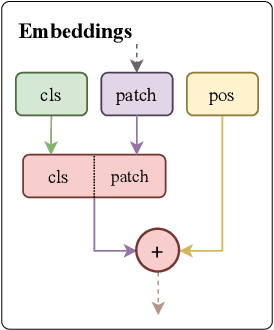
Fusion is a technique for merging multiple independently-trained neural networks in order to combine their capabilities. Past attempts have been restricted to the case of fully-connected, convolutional, and residual networks. In this paper, we present a systematic approach for fusing two or more transformer-based networks exploiting Optimal Transport to (soft-)align the various architectural components. We flesh out an abstraction for layer alignment, that can generalize to arbitrary architectures -- in principle -- and we apply this to the key ingredients of Transformers such as multi-head self-attention, layer-normalization, and residual connections, and we discuss how to handle them via various ablation studies. Furthermore, our method allows the fusion of models of different sizes (heterogeneous fusion), providing a new and efficient way for compression of Transformers. The proposed approach is evaluated on both image classification tasks via Vision Transformer and natural language modeling tasks using BERT. Our approach consistently outperforms vanilla fusion, and, after a surprisingly short finetuning, also outperforms the individual converged parent models. In our analysis, we uncover intriguing insights about the significant role of soft alignment in the case of Transformers. Our results showcase the potential of fusing multiple Transformers, thus compounding their expertise, in the budding paradigm of model fusion and recombination.
Improving Few-shot Image Generation by Structural Discrimination and Textural Modulation
Aug 30, 2023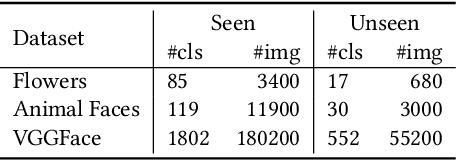
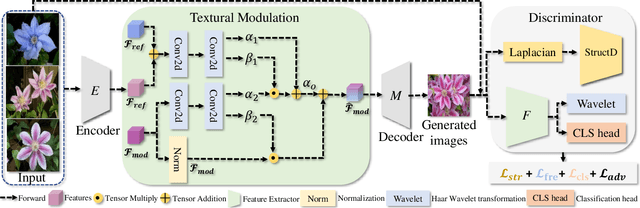
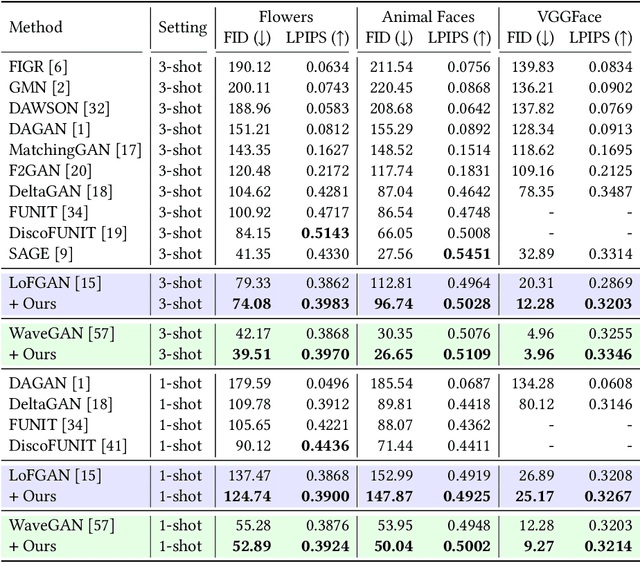

Few-shot image generation, which aims to produce plausible and diverse images for one category given a few images from this category, has drawn extensive attention. Existing approaches either globally interpolate different images or fuse local representations with pre-defined coefficients. However, such an intuitive combination of images/features only exploits the most relevant information for generation, leading to poor diversity and coarse-grained semantic fusion. To remedy this, this paper proposes a novel textural modulation (TexMod) mechanism to inject external semantic signals into internal local representations. Parameterized by the feedback from the discriminator, our TexMod enables more fined-grained semantic injection while maintaining the synthesis fidelity. Moreover, a global structural discriminator (StructD) is developed to explicitly guide the model to generate images with reasonable layout and outline. Furthermore, the frequency awareness of the model is reinforced by encouraging the model to distinguish frequency signals. Together with these techniques, we build a novel and effective model for few-shot image generation. The effectiveness of our model is identified by extensive experiments on three popular datasets and various settings. Besides achieving state-of-the-art synthesis performance on these datasets, our proposed techniques could be seamlessly integrated into existing models for a further performance boost.
SamDSK: Combining Segment Anything Model with Domain-Specific Knowledge for Semi-Supervised Learning in Medical Image Segmentation
Aug 26, 2023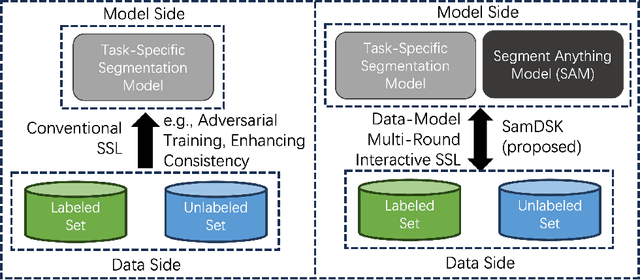
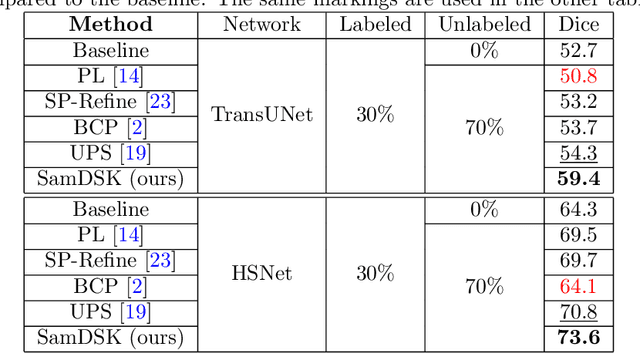
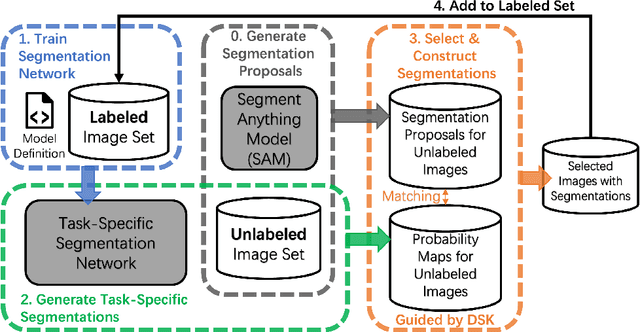
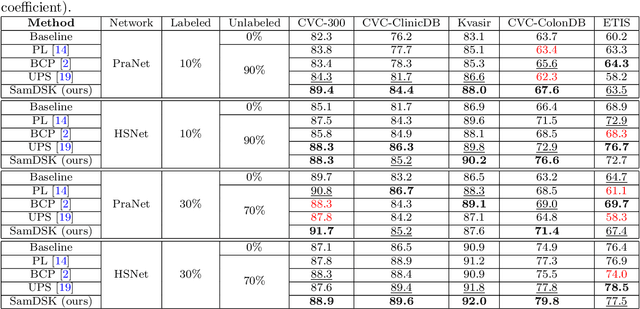
The Segment Anything Model (SAM) exhibits a capability to segment a wide array of objects in natural images, serving as a versatile perceptual tool for various downstream image segmentation tasks. In contrast, medical image segmentation tasks often rely on domain-specific knowledge (DSK). In this paper, we propose a novel method that combines the segmentation foundation model (i.e., SAM) with domain-specific knowledge for reliable utilization of unlabeled images in building a medical image segmentation model. Our new method is iterative and consists of two main stages: (1) segmentation model training; (2) expanding the labeled set by using the trained segmentation model, an unlabeled set, SAM, and domain-specific knowledge. These two stages are repeated until no more samples are added to the labeled set. A novel optimal-matching-based method is developed for combining the SAM-generated segmentation proposals and pixel-level and image-level DSK for constructing annotations of unlabeled images in the iterative stage (2). In experiments, we demonstrate the effectiveness of our proposed method for breast cancer segmentation in ultrasound images, polyp segmentation in endoscopic images, and skin lesion segmentation in dermoscopic images. Our work initiates a new direction of semi-supervised learning for medical image segmentation: the segmentation foundation model can be harnessed as a valuable tool for label-efficient segmentation learning in medical image segmentation.
UAVs and Neural Networks for search and rescue missions
Oct 09, 2023In this paper, we present a method for detecting objects of interest, including cars, humans, and fire, in aerial images captured by unmanned aerial vehicles (UAVs) usually during vegetation fires. To achieve this, we use artificial neural networks and create a dataset for supervised learning. We accomplish the assisted labeling of the dataset through the implementation of an object detection pipeline that combines classic image processing techniques with pretrained neural networks. In addition, we develop a data augmentation pipeline to augment the dataset with automatically labeled images. Finally, we evaluate the performance of different neural networks.
ByteStack-ID: Integrated Stacked Model Leveraging Payload Byte Frequency for Grayscale Image-based Network Intrusion Detection
Oct 06, 2023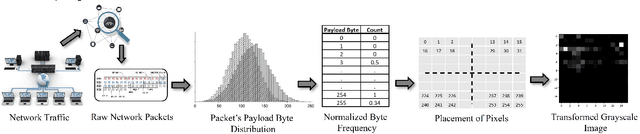

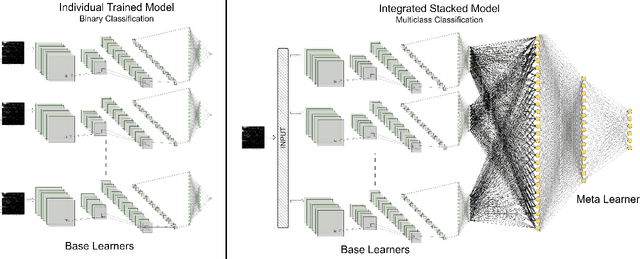
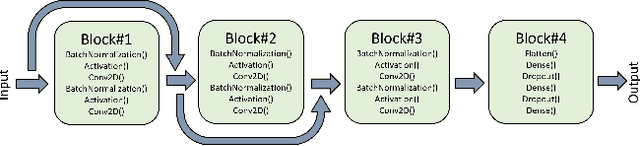
In the ever-evolving realm of network security, the swift and accurate identification of diverse attack classes within network traffic is of paramount importance. This paper introduces "ByteStack-ID," a pioneering approach tailored for packet-level intrusion detection. At its core, ByteStack-ID leverages grayscale images generated from the frequency distributions of payload data, a groundbreaking technique that greatly enhances the model's ability to discern intricate data patterns. Notably, our approach is exclusively grounded in packet-level information, a departure from conventional Network Intrusion Detection Systems (NIDS) that predominantly rely on flow-based data. While building upon the fundamental concept of stacking methodology, ByteStack-ID diverges from traditional stacking approaches. It seamlessly integrates additional meta learner layers into the concatenated base learners, creating a highly optimized, unified model. Empirical results unequivocally confirm the outstanding effectiveness of the ByteStack-ID framework, consistently outperforming baseline models and state-of-the-art approaches across pivotal performance metrics, including precision, recall, and F1-score. Impressively, our proposed approach achieves an exceptional 81\% macro F1-score in multiclass classification tasks. In a landscape marked by the continuous evolution of network threats, ByteStack-ID emerges as a robust and versatile security solution, relying solely on packet-level information extracted from network traffic data.