 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fed-Safe: Securing Federated Learning in Healthcare Against Adversarial Attacks
Oct 12, 2023
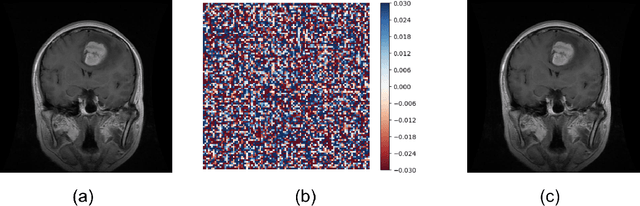
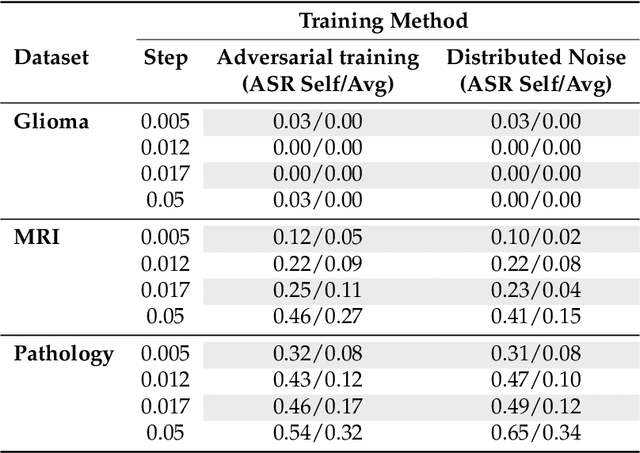
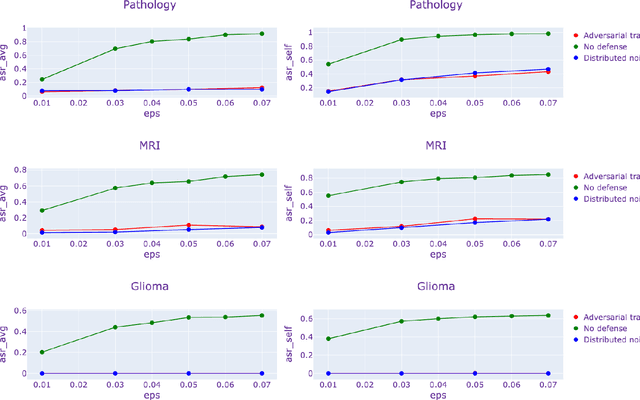
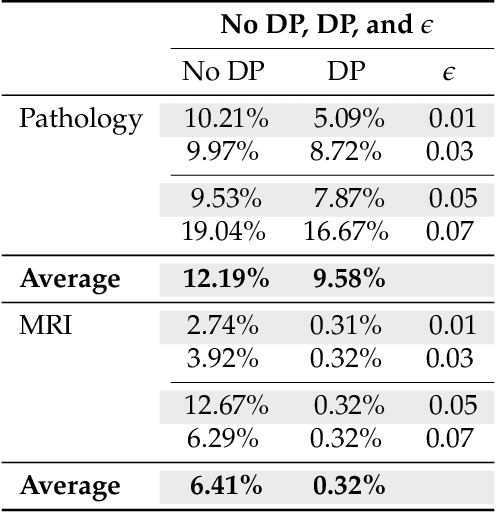
This paper explores the security aspects of federated learning applications in medical image analysis. Current robustness-oriented methods like adversarial training, secure aggregation, and homomorphic encryption often risk privacy compromises. The central aim is to defend the network against potential privacy breaches while maintaining model robustness against adversarial manipulations. We show that incorporating distributed noise, grounded in the privacy guarantees in federated settings, enables the development of a adversarially robust model that also meets federated privacy standards. We conducted comprehensive evaluations across diverse attack scenarios, parameters, and use cases in cancer imaging, concentrating on pathology, meningioma, and glioma. The results reveal that the incorporation of distributed noise allows for the attainment of security levels comparable to those of conventional adversarial training while requiring fewer retraining samples to establish a robust model.
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 24, 2023

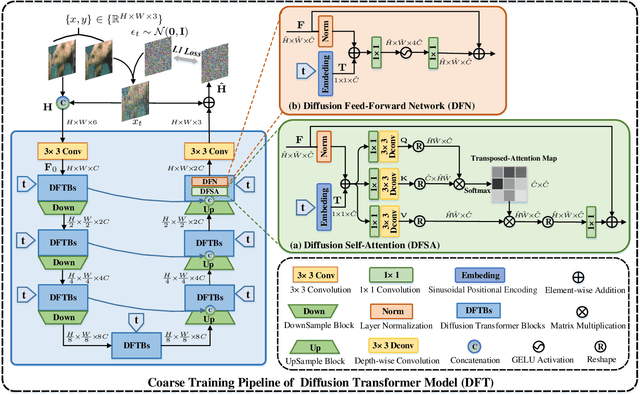
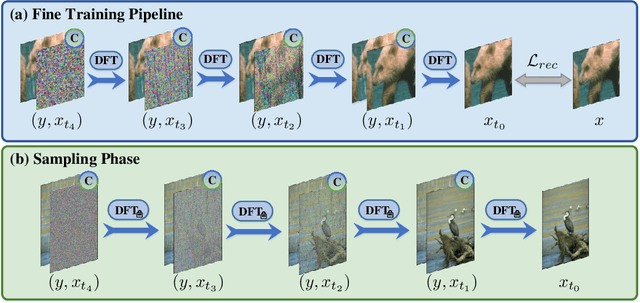
Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising. The code is available at https://github.com/wlydlut/C2F-DFT.
Prompting Scientific Names for Zero-Shot Species Recognition
Oct 15, 2023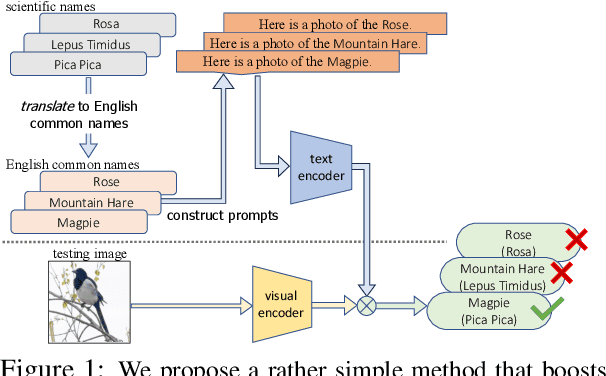
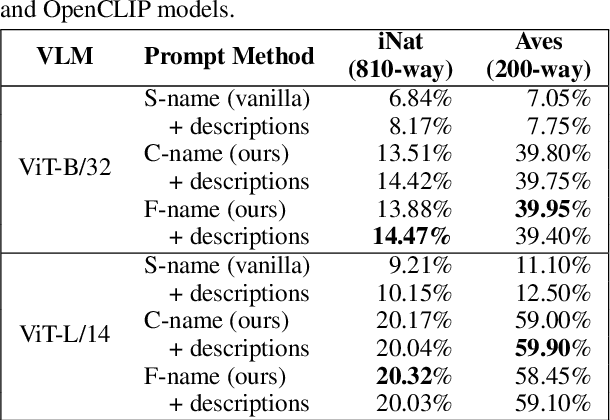

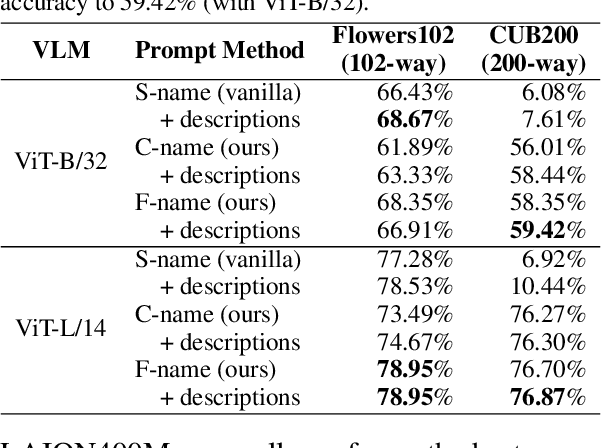
Trained on web-scale image-text pairs, Vision-Language Models (VLMs) such as CLIP can recognize images of common objects in a zero-shot fashion. However, it is underexplored how to use CLIP for zero-shot recognition of highly specialized concepts, e.g., species of birds, plants, and animals, for which their scientific names are written in Latin or Greek. Indeed, CLIP performs poorly for zero-shot species recognition with prompts that use scientific names, e.g., "a photo of Lepus Timidus" (which is a scientific name in Latin). Because these names are usually not included in CLIP's training set. To improve performance, prior works propose to use large-language models (LLMs) to generate descriptions (e.g., of species color and shape) and additionally use them in prompts. We find that they bring only marginal gains. Differently, we are motivated to translate scientific names (e.g., Lepus Timidus) to common English names (e.g., mountain hare) and use such in the prompts. We find that common names are more likely to be included in CLIP's training set, and prompting them achieves 2$\sim$5 times higher accuracy on benchmarking datasets of fine-grained species recognition.
Superpixel Transformers for Efficient Semantic Segmentation
Oct 02, 2023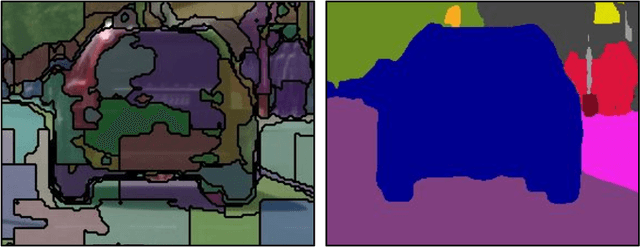
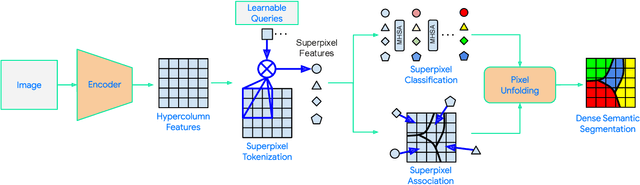


Semantic segmentation, which aims to classify every pixel in an image, is a key task in machine perception, with many applications across robotics and autonomous driving. Due to the high dimensionality of this task, most existing approaches use local operations, such as convolutions, to generate per-pixel features. However, these methods are typically unable to effectively leverage global context information due to the high computational costs of operating on a dense image. In this work, we propose a solution to this issue by leveraging the idea of superpixels, an over-segmentation of the image, and applying them with a modern transformer framework. In particular, our model learns to decompose the pixel space into a spatially low dimensional superpixel space via a series of local cross-attentions. We then apply multi-head self-attention to the superpixels to enrich the superpixel features with global context and then directly produce a class prediction for each superpixel. Finally, we directly project the superpixel class predictions back into the pixel space using the associations between the superpixels and the image pixel features. Reasoning in the superpixel space allows our method to be substantially more computationally efficient compared to convolution-based decoder methods. Yet, our method achieves state-of-the-art performance in semantic segmentation due to the rich superpixel features generated by the global self-attention mechanism. Our experiments on Cityscapes and ADE20K demonstrate that our method matches the state of the art in terms of accuracy, while outperforming in terms of model parameters and latency.
NICE: Improving Panoptic Narrative Detection and Segmentation with Cascading Collaborative Learning
Oct 17, 2023Panoptic Narrative Detection (PND) and Segmentation (PNS) are two challenging tasks that involve identifying and locating multiple targets in an image according to a long narrative description. In this paper, we propose a unified and effective framework called NICE that can jointly learn these two panoptic narrative recognition tasks. Existing visual grounding tasks use a two-branch paradigm, but applying this directly to PND and PNS can result in prediction conflict due to their intrinsic many-to-many alignment property. To address this, we introduce two cascading modules based on the barycenter of the mask, which are Coordinate Guided Aggregation (CGA) and Barycenter Driven Localization (BDL), responsible for segmentation and detection, respectively. By linking PNS and PND in series with the barycenter of segmentation as the anchor, our approach naturally aligns the two tasks and allows them to complement each other for improved performance. Specifically, CGA provides the barycenter as a reference for detection, reducing BDL's reliance on a large number of candidate boxes. BDL leverages its excellent properties to distinguish different instances, which improves the performance of CGA for segmentation. Extensive experiments demonstrate that NICE surpasses all existing methods by a large margin, achieving 4.1% for PND and 2.9% for PNS over the state-of-the-art. These results validate the effectiveness of our proposed collaborative learning strategy. The project of this work is made publicly available at https://github.com/Mr-Neko/NICE.
FocDepthFormer: Transformer with LSTM for Depth Estimation from Focus
Oct 17, 2023Depth estimation from focal stacks is a fundamental computer vision problem that aims to infer depth from focus/defocus cues in the image stacks. Most existing methods tackle this problem by applying convolutional neural networks (CNNs) with 2D or 3D convolutions over a set of fixed stack images to learn features across images and stacks. Their performance is restricted due to the local properties of the CNNs, and they are constrained to process a fixed number of stacks consistent in train and inference, limiting the generalization to the arbitrary length of stacks. To handle the above limitations, we develop a novel Transformer-based network, FocDepthFormer, composed mainly of a Transformer with an LSTM module and a CNN decoder. The self-attention in Transformer enables learning more informative features via an implicit non-local cross reference. The LSTM module is learned to integrate the representations across the stack with arbitrary images. To directly capture the low-level features of various degrees of focus/defocus, we propose to use multi-scale convolutional kernels in an early-stage encoder. Benefiting from the design with LSTM, our FocDepthFormer can be pre-trained with abundant monocular RGB depth estimation data for visual pattern capturing, alleviating the demand for the hard-to-collect focal stack data. Extensive experiments on various focal stack benchmark datasets show that our model outperforms the state-of-the-art models on multiple metrics.
Relearning Forgotten Knowledge: on Forgetting, Overfit and Training-Free Ensembles of DNNs
Oct 17, 2023The infrequent occurrence of overfit in deep neural networks is perplexing. On the one hand, theory predicts that as models get larger they should eventually become too specialized for a specific training set, with ensuing decrease in generalization. In contrast, empirical results in image classification indicate that increasing the training time of deep models or using bigger models almost never hurts generalization. Is it because the way we measure overfit is too limited? Here, we introduce a novel score for quantifying overfit, which monitors the forgetting rate of deep models on validation data. Presumably, this score indicates that even while generalization improves overall, there are certain regions of the data space where it deteriorates. When thus measured, we show that overfit can occur with and without a decrease in validation accuracy, and may be more common than previously appreciated. This observation may help to clarify the aforementioned confusing picture. We use our observations to construct a new ensemble method, based solely on the training history of a single network, which provides significant improvement in performance without any additional cost in training time. An extensive empirical evaluation with modern deep models shows our method's utility on multiple datasets, neural networks architectures and training schemes, both when training from scratch and when using pre-trained networks in transfer learning. Notably, our method outperforms comparable methods while being easier to implement and use, and further improves the performance of competitive networks on Imagenet by 1\%.
Deep Image Harmonization with Learnable Augmentation
Aug 01, 2023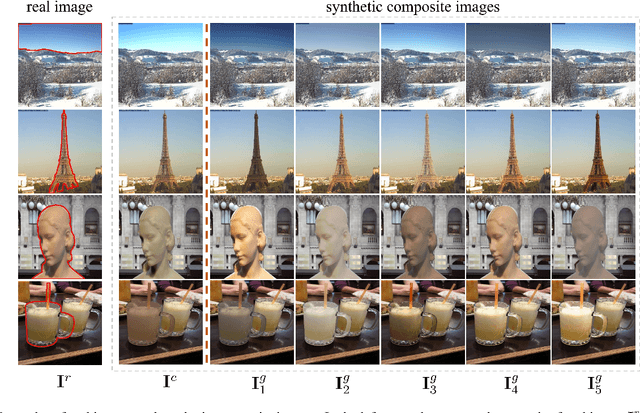
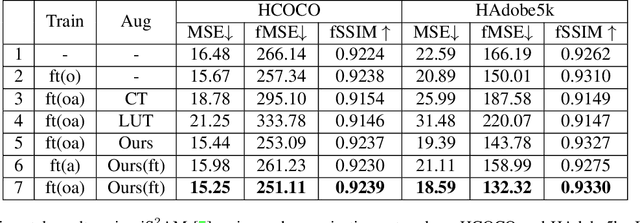


The goal of image harmonization is adjusting the foreground appearance in a composite image to make the whole image harmonious. To construct paired training images, existing datasets adopt different ways to adjust the illumination statistics of foregrounds of real images to produce synthetic composite images. However, different datasets have considerable domain gap and the performances on small-scale datasets are limited by insufficient training data. In this work, we explore learnable augmentation to enrich the illumination diversity of small-scale datasets for better harmonization performance. In particular, our designed SYthetic COmposite Network (SycoNet) takes in a real image with foreground mask and a random vector to learn suitable color transformation, which is applied to the foreground of this real image to produce a synthetic composite image. Comprehensive experiments demonstrate the effectiveness of our proposed learnable augmentation for image harmonization. The code of SycoNet is released at https://github.com/bcmi/SycoNet-Adaptive-Image-Harmonization.
Panoptic-Depth Color Map for Combination of Depth and Image Segmentation
Aug 24, 2023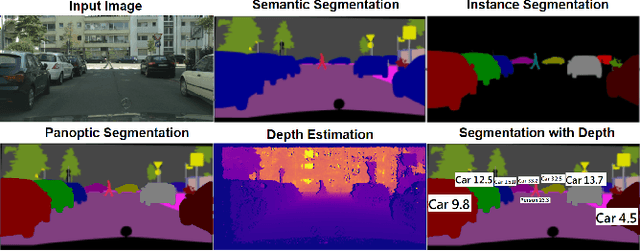

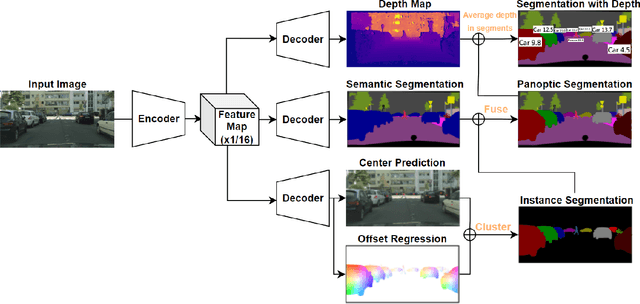
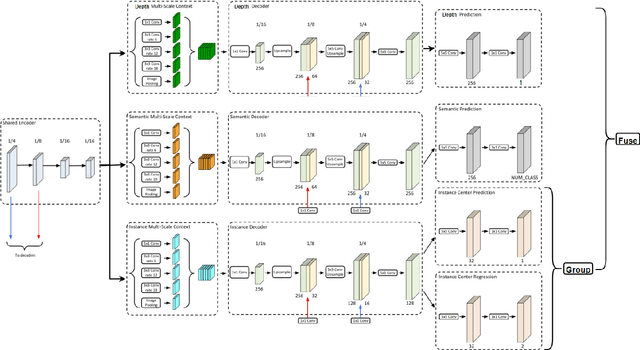
Image segmentation and depth estimation are crucial tasks in computer vision, especially in autonomous driving scenarios. Although these tasks are typically addressed separately, we propose an innovative approach to combine them in our novel deep learning network, Panoptic-DepthLab. By incorporating an additional depth estimation branch into the segmentation network, it can predict the depth of each instance segment. Evaluating on Cityscape dataset, we demonstrate the effectiveness of our method in achieving high-quality segmentation results with depth and visualize it with a color map. Our proposed method demonstrates a new possibility of combining different tasks and networks to generate a more comprehensive image recognition result to facilitate the safety of autonomous driving vehicles.
Unified Pre-training with Pseudo Texts for Text-To-Image Person Re-identification
Sep 04, 2023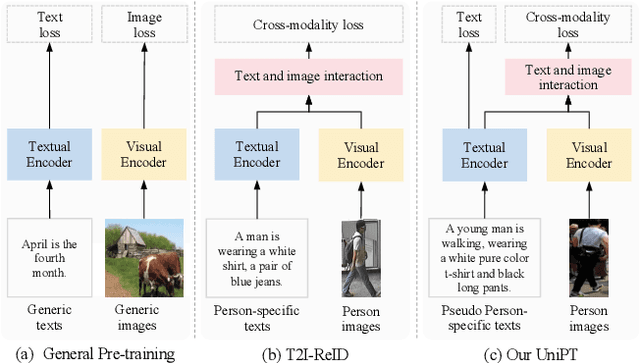
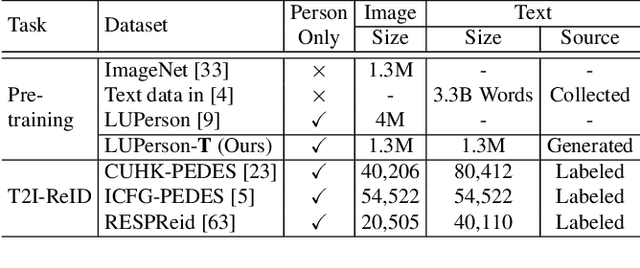
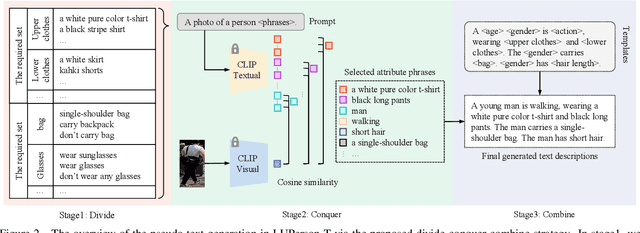
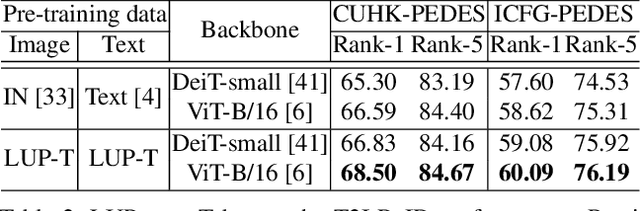
The pre-training task is indispensable for the text-to-image person re-identification (T2I-ReID) task. However, there are two underlying inconsistencies between these two tasks that may impact the performance; i) Data inconsistency. A large domain gap exists between the generic images/texts used in public pre-trained models and the specific person data in the T2I-ReID task. This gap is especially severe for texts, as general textual data are usually unable to describe specific people in fine-grained detail. ii) Training inconsistency. The processes of pre-training of images and texts are independent, despite cross-modality learning being critical to T2I-ReID. To address the above issues, we present a new unified pre-training pipeline (UniPT) designed specifically for the T2I-ReID task. We first build a large-scale text-labeled person dataset "LUPerson-T", in which pseudo-textual descriptions of images are automatically generated by the CLIP paradigm using a divide-conquer-combine strategy. Benefiting from this dataset, we then utilize a simple vision-and-language pre-training framework to explicitly align the feature space of the image and text modalities during pre-training. In this way, the pre-training task and the T2I-ReID task are made consistent with each other on both data and training levels. Without the need for any bells and whistles, our UniPT achieves competitive Rank-1 accuracy of, ie, 68.50%, 60.09%, and 51.85% on CUHK-PEDES, ICFG-PEDES and RSTPReid, respectively. Both the LUPerson-T dataset and code are available at https;//github.com/ZhiyinShao-H/UniPT.