 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretable Image Quality Assessment via CLIP with Multiple Antonym-Prompt Pairs
Aug 24, 2023

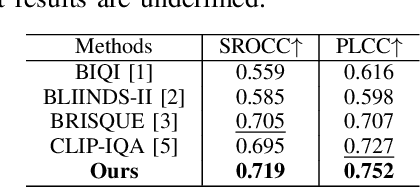
No reference image quality assessment (NR-IQA) is a task to estimate the perceptual quality of an image without its corresponding original image. It is even more difficult to perform this task in a zero-shot manner, i.e., without task-specific training. In this paper, we propose a new zero-shot and interpretable NRIQA method that exploits the ability of a pre-trained visionlanguage model to estimate the correlation between an image and a textual prompt. The proposed method employs a prompt pairing strategy and multiple antonym-prompt pairs corresponding to carefully selected descriptive features corresponding to the perceptual image quality. Thus, the proposed method is able to identify not only the perceptual quality evaluation of the image, but also the cause on which the quality evaluation is based. Experimental results show that the proposed method outperforms existing zero-shot NR-IQA methods in terms of accuracy and can evaluate the causes of perceptual quality degradation.
PE-MED: Prompt Enhancement for Interactive Medical Image Segmentation
Aug 26, 2023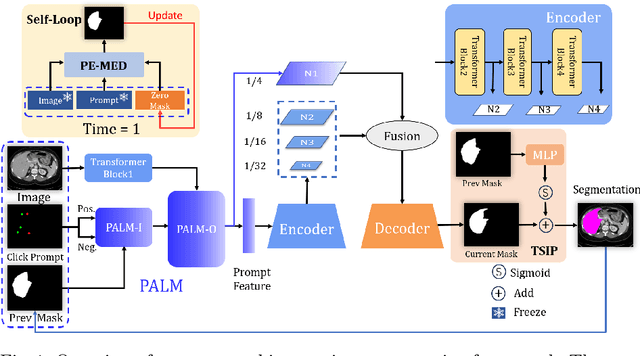
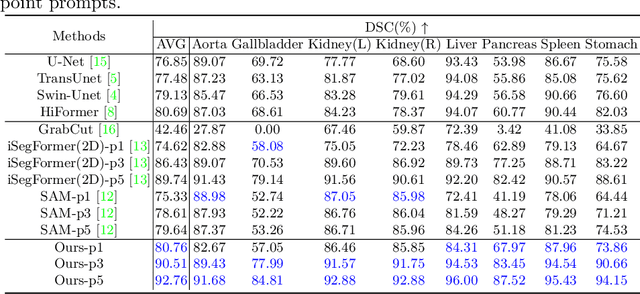
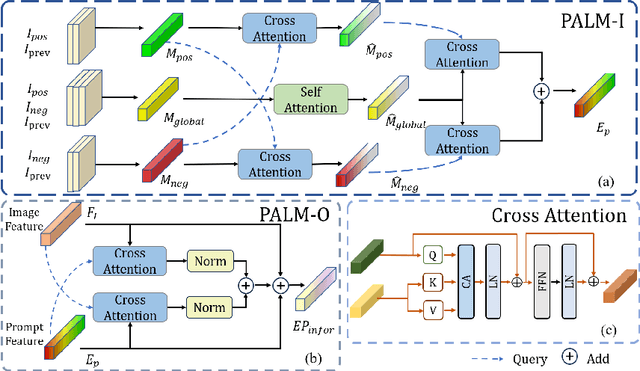

Interactive medical image segmentation refers to the accurate segmentation of the target of interest through interaction (e.g., click) between the user and the image. It has been widely studied in recent years as it is less dependent on abundant annotated data and more flexible than fully automated segmentation. However, current studies have not fully explored user-provided prompt information (e.g., points), including the knowledge mined in one interaction, and the relationship between multiple interactions. Thus, in this paper, we introduce a novel framework equipped with prompt enhancement, called PE-MED, for interactive medical image segmentation. First, we introduce a Self-Loop strategy to generate warm initial segmentation results based on the first prompt. It can prevent the highly unfavorable scenarios, such as encountering a blank mask as the initial input after the first interaction. Second, we propose a novel Prompt Attention Learning Module (PALM) to mine useful prompt information in one interaction, enhancing the responsiveness of the network to user clicks. Last, we build a Time Series Information Propagation (TSIP) mechanism to extract the temporal relationships between multiple interactions and increase the model stability. Comparative experiments with other state-of-the-art (SOTA) medical image segmentation algorithms show that our method exhibits better segmentation accuracy and stability.
Fusion framework and multimodality for the Laplacian approximation of Bayesian neural networks
Oct 12, 2023This paper considers the problem of sequential fusion of predictions from neural networks (NN) and fusion of predictions from multiple NN. This fusion strategy increases the robustness, i.e., reduces the impact of one incorrect classification and detection of outliers the \nn has not seen during training. This paper uses Laplacian approximation of Bayesian NNs (BNNs) to quantify the uncertainty necessary for fusion. Here, an extension is proposed such that the prediction of the NN can be represented by multimodal distributions. Regarding calibration of the estimated uncertainty in the prediction, the performance is significantly improved by having the flexibility to represent a multimodal distribution. Two class classical image classification tasks, i.e., MNIST and CFAR10, and image sequences from camera traps of carnivores in Swedish forests have been used to demonstrate the fusion strategies and proposed extension to the Laplacian approximation.
Training and Predicting Visual Error for Real-Time Applications
Oct 13, 2023
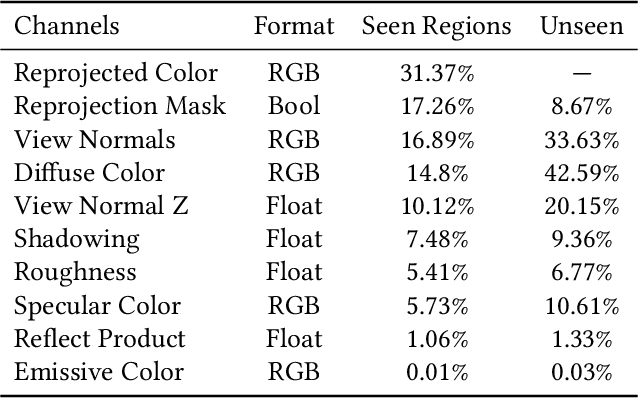
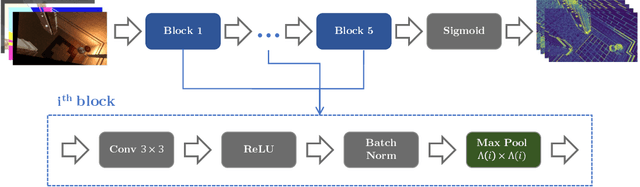
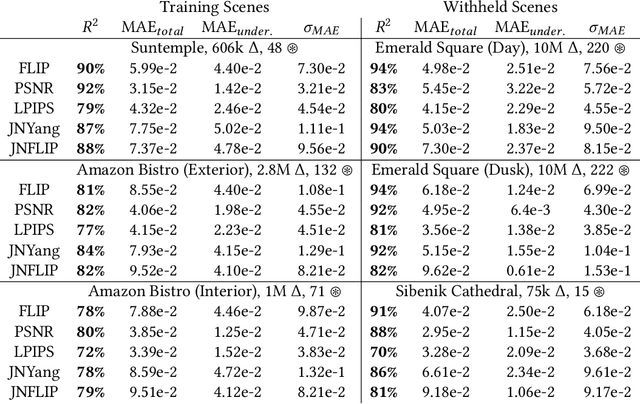
Visual error metrics play a fundamental role in the quantification of perceived image similarity. Most recently, use cases for them in real-time applications have emerged, such as content-adaptive shading and shading reuse to increase performance and improve efficiency. A wide range of different metrics has been established, with the most sophisticated being capable of capturing the perceptual characteristics of the human visual system. However, their complexity, computational expense, and reliance on reference images to compare against prevent their generalized use in real-time, restricting such applications to using only the simplest available metrics. In this work, we explore the abilities of convolutional neural networks to predict a variety of visual metrics without requiring either reference or rendered images. Specifically, we train and deploy a neural network to estimate the visual error resulting from reusing shading or using reduced shading rates. The resulting models account for 70%-90% of the variance while achieving up to an order of magnitude faster computation times. Our solution combines image-space information that is readily available in most state-of-the-art deferred shading pipelines with reprojection from previous frames to enable an adequate estimate of visual errors, even in previously unseen regions. We describe a suitable convolutional network architecture and considerations for data preparation for training. We demonstrate the capability of our network to predict complex error metrics at interactive rates in a real-time application that implements content-adaptive shading in a deferred pipeline. Depending on the portion of unseen image regions, our approach can achieve up to $2\times$ performance compared to state-of-the-art methods.
* Published at Proceedings of the ACM in Computer Graphics and Interactive Techniques. 14 Pages, 16 Figures, 3 Tables. For paper website and higher quality figures, see https://jaliborc.github.io/rt-percept/
Generate Your Own Scotland: Satellite Image Generation Conditioned on Maps
Aug 31, 2023Despite recent advancements in image generation, diffusion models still remain largely underexplored in Earth Observation. In this paper we show that state-of-the-art pretrained diffusion models can be conditioned on cartographic data to generate realistic satellite images. We provide two large datasets of paired OpenStreetMap images and satellite views over the region of Mainland Scotland and the Central Belt. We train a ControlNet model and qualitatively evaluate the results, demonstrating that both image quality and map fidelity are possible. Finally, we provide some insights on the opportunities and challenges of applying these models for remote sensing. Our model weights and code for creating the dataset are publicly available at https://github.com/miquel-espinosa/map-sat.
Class-Specific Data Augmentation: Bridging the Imbalance in Multiclass Breast Cancer Classification
Oct 15, 2023Breast Cancer is the most common cancer among women, which is also visible in men, and accounts for more than 1 in 10 new cancer diagnoses each year. It is also the second most common cause of women who die from cancer. Hence, it necessitates early detection and tailored treatment. Early detection can provide appropriate and patient-based therapeutic schedules. Moreover, early detection can also provide the type of cyst. This paper employs class-level data augmentation, addressing the undersampled classes and raising their detection rate. This approach suggests two key components: class-level data augmentation on structure-preserving stain normalization techniques to hematoxylin and eosin-stained images and transformer-based ViTNet architecture via transfer learning for multiclass classification of breast cancer images. This merger enables categorizing breast cancer images with advanced image processing and deep learning as either benign or as one of four distinct malignant subtypes by focusing on class-level augmentation and catering to unique characteristics of each class with increasing precision of classification on undersampled classes, which leads to lower mortality rates associated with breast cancer. The paper aims to ease the duties of the medical specialist by operating multiclass classification and categorizing the image into benign or one of four different malignant types of breast cancers.
Explanation-Based Training with Differentiable Insertion/Deletion Metric-Aware Regularizers
Oct 20, 2023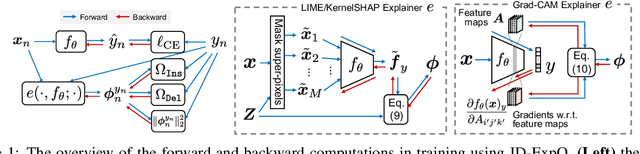
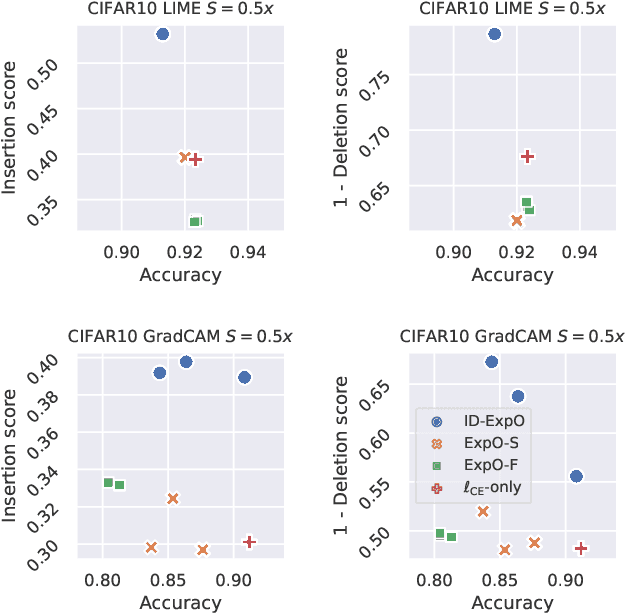
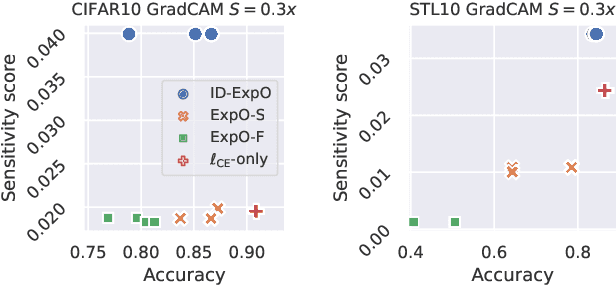
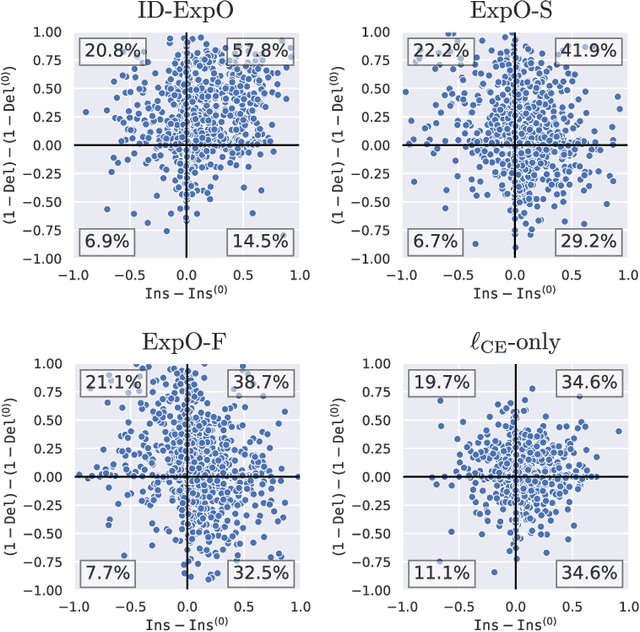
The quality of explanations for the predictions of complex machine learning predictors is often measured using insertion and deletion metrics, which assess the faithfulness of the explanations, i.e., how correctly the explanations reflect the predictor's behavior. To improve the faithfulness, we propose insertion/deletion metric-aware explanation-based optimization (ID-ExpO), which optimizes differentiable predictors to improve both insertion and deletion scores of the explanations while keeping their predictive accuracy. Since the original insertion and deletion metrics are indifferentiable with respect to the explanations and directly unavailable for gradient-based optimization, we extend the metrics to be differentiable and use them to formalize insertion and deletion metric-based regularizers. The experimental results on image and tabular datasets show that the deep neural networks-based predictors fine-tuned using ID-ExpO enable popular post-hoc explainers to produce more faithful and easy-to-interpret explanations while keeping high predictive accuracy.
Using Logic Programming and Kernel-Grouping for Improving Interpretability of Convolutional Neural Networks
Oct 19, 2023Within the realm of deep learning, the interpretability of Convolutional Neural Networks (CNNs), particularly in the context of image classification tasks, remains a formidable challenge. To this end we present a neurosymbolic framework, NeSyFOLD-G that generates a symbolic rule-set using the last layer kernels of the CNN to make its underlying knowledge interpretable. What makes NeSyFOLD-G different from other similar frameworks is that we first find groups of similar kernels in the CNN (kernel-grouping) using the cosine-similarity between the feature maps generated by various kernels. Once such kernel groups are found, we binarize each kernel group's output in the CNN and use it to generate a binarization table which serves as input data to FOLD-SE-M which is a Rule Based Machine Learning (RBML) algorithm. FOLD-SE-M then generates a rule-set that can be used to make predictions. We present a novel kernel grouping algorithm and show that grouping similar kernels leads to a significant reduction in the size of the rule-set generated by FOLD-SE-M, consequently, improving the interpretability. This rule-set symbolically encapsulates the connectionist knowledge of the trained CNN. The rule-set can be viewed as a normal logic program wherein each predicate's truth value depends on a kernel group in the CNN. Each predicate in the rule-set is mapped to a concept using a few semantic segmentation masks of the images used for training, to make it human-understandable. The last layers of the CNN can then be replaced by this rule-set to obtain the NeSy-G model which can then be used for the image classification task. The goal directed ASP system s(CASP) can be used to obtain the justification of any prediction made using the NeSy-G model. We also propose a novel algorithm for labeling each predicate in the rule-set with the semantic concept(s) that its corresponding kernel group represents.
High-quality Image Dehazing with Diffusion Model
Aug 23, 2023



Image dehazing is quite challenging in dense-haze scenarios, where quite less original information remains in the hazy image. Though previous methods have made marvelous progress, they still suffer from information loss in content and color in dense-haze scenarios. The recently emerged Denoising Diffusion Probabilistic Model (DDPM) exhibits strong generation ability, showing potential for solving this problem. However, DDPM fails to consider the physics property of dehazing task, limiting its information completion capacity. In this work, we propose DehazeDDPM: A DDPM-based and physics-aware image dehazing framework that applies to complex hazy scenarios. Specifically, DehazeDDPM works in two stages. The former stage physically models the dehazing task with the Atmospheric Scattering Model (ASM), pulling the distribution closer to the clear data and endowing DehazeDDPM with fog-aware ability. The latter stage exploits the strong generation ability of DDPM to compensate for the haze-induced huge information loss, by working in conjunction with the physical modelling. Extensive experiments demonstrate that our method attains state-of-the-art performance on both synthetic and real-world hazy datasets.
Robust Visual Imitation Learning with Inverse Dynamics Representations
Oct 22, 2023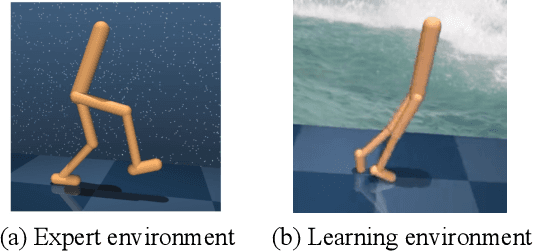
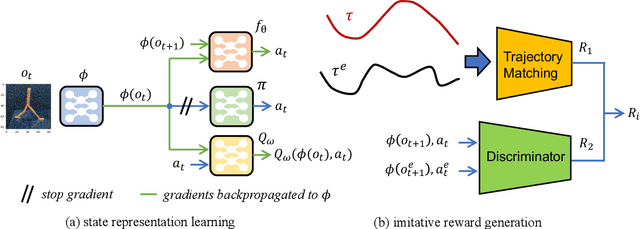
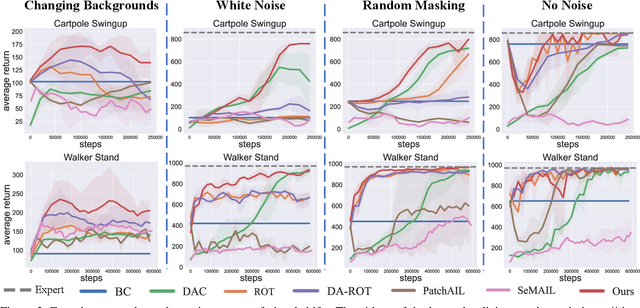
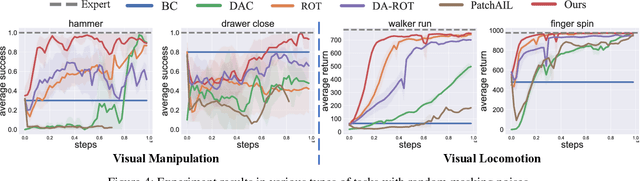
Imitation learning (IL) has achieved considerable success in solving complex sequential decision-making problems. However, current IL methods mainly assume that the environment for learning policies is the same as the environment for collecting expert datasets. Therefore, these methods may fail to work when there are slight differences between the learning and expert environments, especially for challenging problems with high-dimensional image observations. However, in real-world scenarios, it is rare to have the chance to collect expert trajectories precisely in the target learning environment. To address this challenge, we propose a novel robust imitation learning approach, where we develop an inverse dynamics state representation learning objective to align the expert environment and the learning environment. With the abstract state representation, we design an effective reward function, which thoroughly measures the similarity between behavior data and expert data not only element-wise, but also from the trajectory level. We conduct extensive experiments to evaluate the proposed approach under various visual perturbations and in diverse visual control tasks. Our approach can achieve a near-expert performance in most environments, and significantly outperforms the state-of-the-art visual IL methods and robust IL methods.