 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DualAug: Exploiting Additional Heavy Augmentation with OOD Data Rejection
Oct 16, 2023
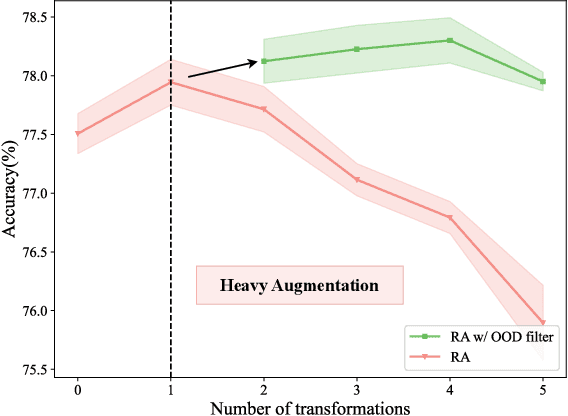

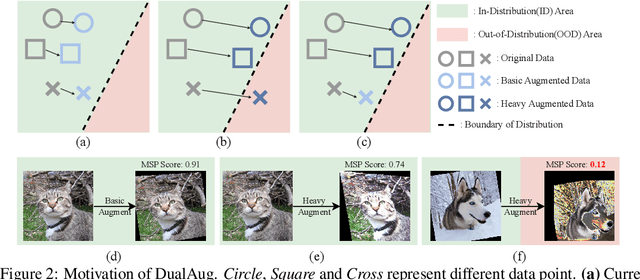
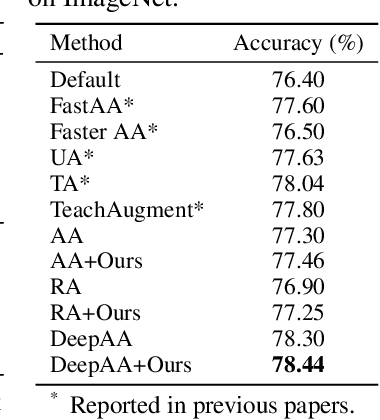
Data augmentation is a dominant method for reducing model overfitting and improving generalization. Most existing data augmentation methods tend to find a compromise in augmenting the data, \textit{i.e.}, increasing the amplitude of augmentation carefully to avoid degrading some data too much and doing harm to the model performance. We delve into the relationship between data augmentation and model performance, revealing that the performance drop with heavy augmentation comes from the presence of out-of-distribution (OOD) data. Nonetheless, as the same data transformation has different effects for different training samples, even for heavy augmentation, there remains part of in-distribution data which is beneficial to model training. Based on the observation, we propose a novel data augmentation method, named \textbf{DualAug}, to keep the augmentation in distribution as much as possible at a reasonable time and computational cost. We design a data mixing strategy to fuse augmented data from both the basic- and the heavy-augmentation branches. Extensive experiments on supervised image classification benchmarks show that DualAug improve various automated data augmentation method. Moreover, the experiments on semi-supervised learning and contrastive self-supervised learning demonstrate that our DualAug can also improve related method. Code is available at \href{https://github.com/shuguang99/DualAug}{https://github.com/shuguang99/DualAug}.
Combating Label Noise With A General Surrogate Model For Sample Selection
Oct 16, 2023Modern deep learning systems are data-hungry. Learning with web data is one of the feasible solutions, but will introduce label noise inevitably, which can hinder the performance of deep neural networks. Sample selection is an effective way to deal with label noise. The key is to separate clean samples based on some criterion. Previous methods pay more attention to the small loss criterion where small-loss samples are regarded as clean ones. Nevertheless, such a strategy relies on the learning dynamics of each data instance. Some noisy samples are still memorized due to frequently occurring corrupted learning patterns. To tackle this problem, a training-free surrogate model is preferred, freeing from the effect of memorization. In this work, we propose to leverage the vision-language surrogate model CLIP to filter noisy samples automatically. CLIP brings external knowledge to facilitate the selection of clean samples with its ability of text-image alignment. Furthermore, a margin adaptive loss is designed to regularize the selection bias introduced by CLIP, providing robustness to label noise. We validate the effectiveness of our proposed method on both real-world and synthetic noisy datasets. Our method achieves significant improvement without CLIP involved during the inference stage.
RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets
Oct 16, 2023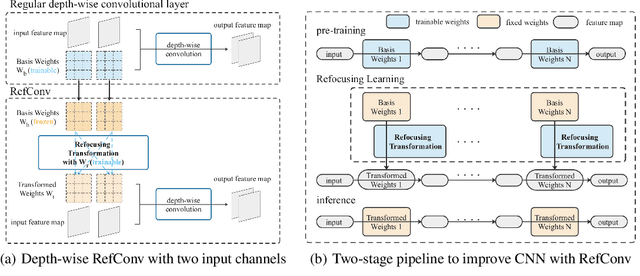
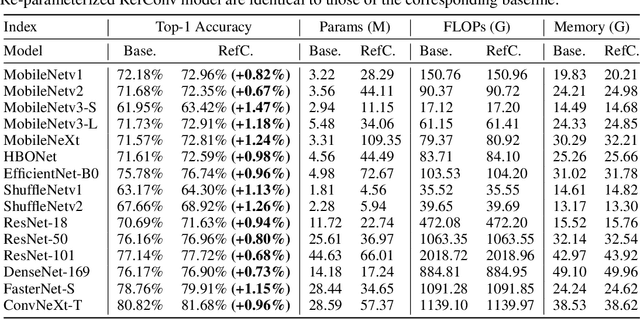
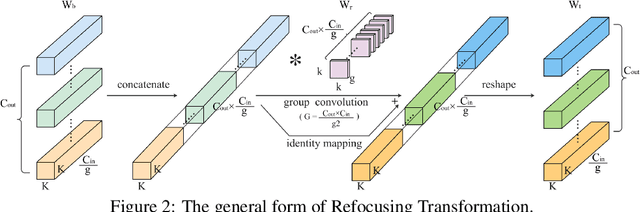
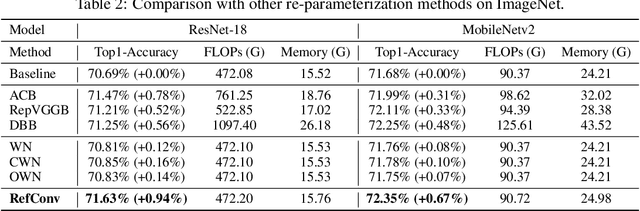
We propose Re-parameterized Refocusing Convolution (RefConv) as a replacement for regular convolutional layers, which is a plug-and-play module to improve the performance without any inference costs. Specifically, given a pre-trained model, RefConv applies a trainable Refocusing Transformation to the basis kernels inherited from the pre-trained model to establish connections among the parameters. For example, a depth-wise RefConv can relate the parameters of a specific channel of convolution kernel to the parameters of the other kernel, i.e., make them refocus on the other parts of the model they have never attended to, rather than focus on the input features only. From another perspective, RefConv augments the priors of existing model structures by utilizing the representations encoded in the pre-trained parameters as the priors and refocusing on them to learn novel representations, thus further enhancing the representational capacity of the pre-trained model. Experimental results validated that RefConv can improve multiple CNN-based models by a clear margin on image classification (up to 1.47% higher top-1 accuracy on ImageNet), object detection and semantic segmentation without introducing any extra inference costs or altering the original model structure. Further studies demonstrated that RefConv can reduce the redundancy of channels and smooth the loss landscape, which explains its effectiveness.
Model Selection of Anomaly Detectors in the Absence of Labeled Validation Data
Oct 16, 2023Anomaly detection requires detecting abnormal samples in large unlabeled datasets. While progress in deep learning and the advent of foundation models has produced powerful unsupervised anomaly detection methods, their deployment in practice is often hindered by the lack of labeled data -- without it, the detection accuracy of an anomaly detector cannot be evaluated reliably. In this work, we propose a general-purpose framework for evaluating image-based anomaly detectors with synthetically generated validation data. Our method assumes access to a small support set of normal images which are processed with a pre-trained diffusion model (our proposed method requires no training or fine-tuning) to produce synthetic anomalies. When mixed with normal samples from the support set, the synthetic anomalies create detection tasks that compose a validation framework for anomaly detection evaluation and model selection. In an extensive empirical study, ranging from natural images to industrial applications, we find that our synthetic validation framework selects the same models and hyper-parameters as selection with a ground-truth validation set. In addition, we find that prompts selected by our method for CLIP-based anomaly detection outperforms all other prompt selection strategies, and leads to the overall best detection accuracy, even on the challenging MVTec-AD dataset.
Foundation Model-oriented Robustness: Robust Image Model Evaluation with Pretrained Models
Aug 23, 2023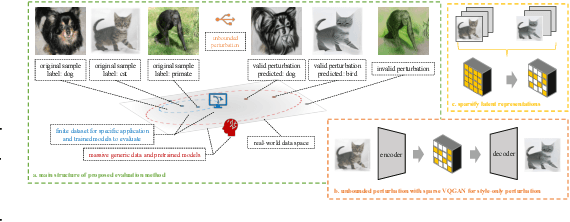
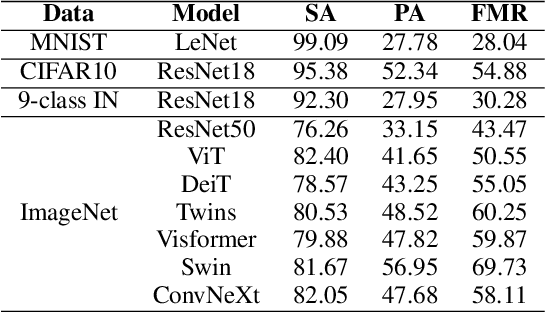
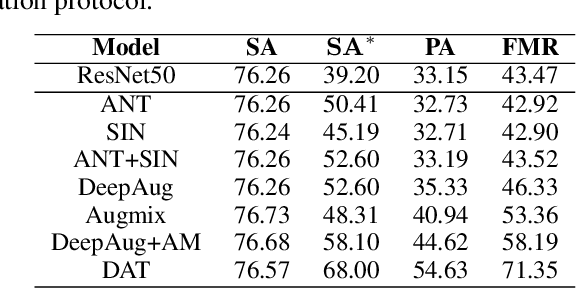

Machine learning has demonstrated remarkable performance over finite datasets, yet whether the scores over the fixed benchmarks can sufficiently indicate the model's performance in the real world is still in discussion. In reality, an ideal robust model will probably behave similarly to the oracle (e.g., the human users), thus a good evaluation protocol is probably to evaluate the models' behaviors in comparison to the oracle. In this paper, we introduce a new robustness measurement that directly measures the image classification model's performance compared with a surrogate oracle (i.e., a foundation model). Besides, we design a simple method that can accomplish the evaluation beyond the scope of the benchmarks. Our method extends the image datasets with new samples that are sufficiently perturbed to be distinct from the ones in the original sets, but are still bounded within the same image-label structure the original test image represents, constrained by a foundation model pretrained with a large amount of samples. As a result, our new method will offer us a new way to evaluate the models' robustness performance, free of limitations of fixed benchmarks or constrained perturbations, although scoped by the power of the oracle. In addition to the evaluation results, we also leverage our generated data to understand the behaviors of the model and our new evaluation strategies.
AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models
Sep 29, 2023Classifiers built upon vision-language models such as CLIP have shown remarkable zero-shot performance across a broad range of image classification tasks. Prior work has studied different ways of automatically creating descriptor sets for every class based on prompt templates, ranging from manually engineered templates over templates obtained from a large language model to templates built from random words and characters. Up until now, deriving zero-shot classifiers from the respective encoded class descriptors has remained nearly unchanged, i.e., classify to the class that maximizes cosine similarity between its averaged encoded class descriptors and the image encoding. However, weighing all class descriptors equally can be suboptimal when certain descriptors match visual clues on a given image better than others. In this work, we propose AutoCLIP, a method for auto-tuning zero-shot classifiers. AutoCLIP tunes per-image weights to each prompt template at inference time, based on statistics of class descriptor-image similarities. AutoCLIP is fully unsupervised, has very low computational overhead, and can be easily implemented in few lines of code. We show that AutoCLIP outperforms baselines across a broad range of vision-language models, datasets, and prompt templates consistently and by up to 3 percent point accuracy.
Beyond Self-Attention: Deformable Large Kernel Attention for Medical Image Segmentation
Aug 31, 2023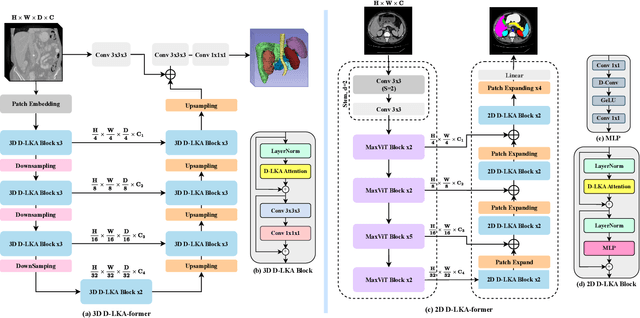
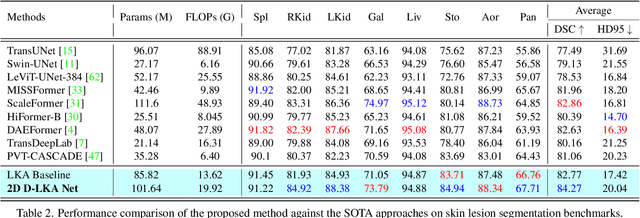
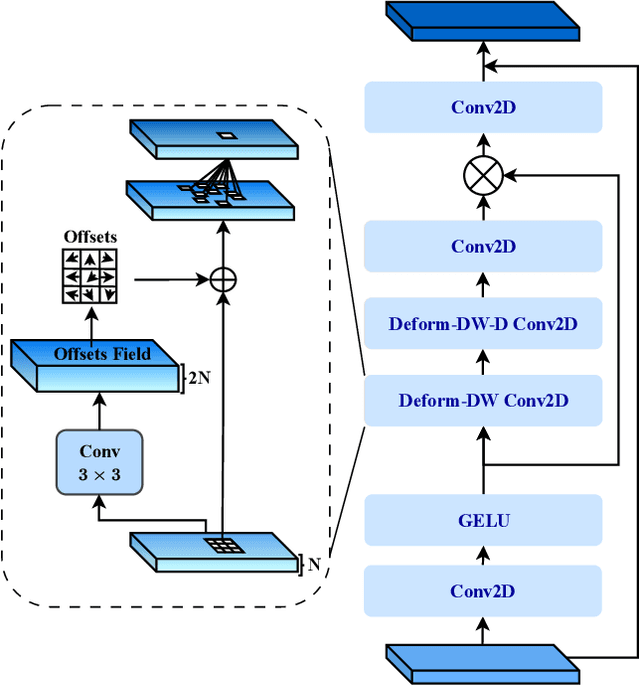
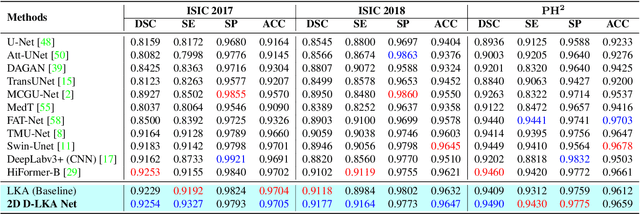
Medical image segmentation has seen significant improvements with transformer models, which excel in grasping far-reaching contexts and global contextual information. However, the increasing computational demands of these models, proportional to the squared token count, limit their depth and resolution capabilities. Most current methods process D volumetric image data slice-by-slice (called pseudo 3D), missing crucial inter-slice information and thus reducing the model's overall performance. To address these challenges, we introduce the concept of \textbf{Deformable Large Kernel Attention (D-LKA Attention)}, a streamlined attention mechanism employing large convolution kernels to fully appreciate volumetric context. This mechanism operates within a receptive field akin to self-attention while sidestepping the computational overhead. Additionally, our proposed attention mechanism benefits from deformable convolutions to flexibly warp the sampling grid, enabling the model to adapt appropriately to diverse data patterns. We designed both 2D and 3D adaptations of the D-LKA Attention, with the latter excelling in cross-depth data understanding. Together, these components shape our novel hierarchical Vision Transformer architecture, the \textit{D-LKA Net}. Evaluations of our model against leading methods on popular medical segmentation datasets (Synapse, NIH Pancreas, and Skin lesion) demonstrate its superior performance. Our code implementation is publicly available at the: https://github.com/mindflow-institue/deformableLKA
Dark Side Augmentation: Generating Diverse Night Examples for Metric Learning
Sep 28, 2023Image retrieval methods based on CNN descriptors rely on metric learning from a large number of diverse examples of positive and negative image pairs. Domains, such as night-time images, with limited availability and variability of training data suffer from poor retrieval performance even with methods performing well on standard benchmarks. We propose to train a GAN-based synthetic-image generator, translating available day-time image examples into night images. Such a generator is used in metric learning as a form of augmentation, supplying training data to the scarce domain. Various types of generators are evaluated and analyzed. We contribute with a novel light-weight GAN architecture that enforces the consistency between the original and translated image through edge consistency. The proposed architecture also allows a simultaneous training of an edge detector that operates on both night and day images. To further increase the variability in the training examples and to maximize the generalization of the trained model, we propose a novel method of diverse anchor mining. The proposed method improves over the state-of-the-art results on a standard Tokyo 24/7 day-night retrieval benchmark while preserving the performance on Oxford and Paris datasets. This is achieved without the need of training image pairs of matching day and night images. The source code is available at https://github.com/mohwald/gandtr .
* 11 pages, 4 figures, 8 tables
Lightweight In-Context Tuning for Multimodal Unified Models
Oct 08, 2023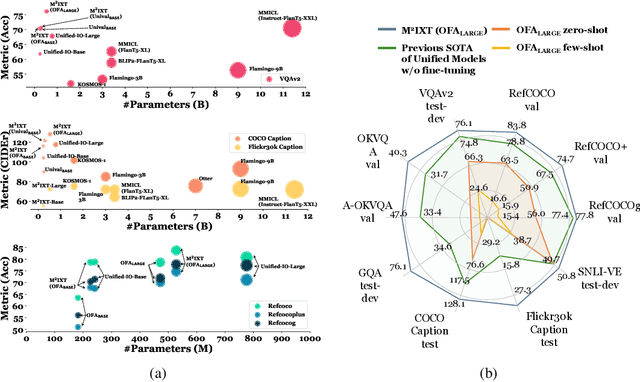
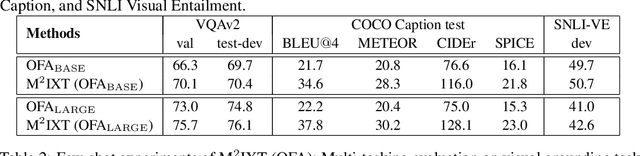
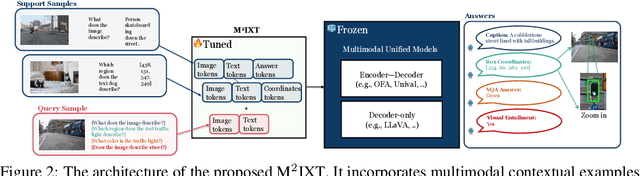
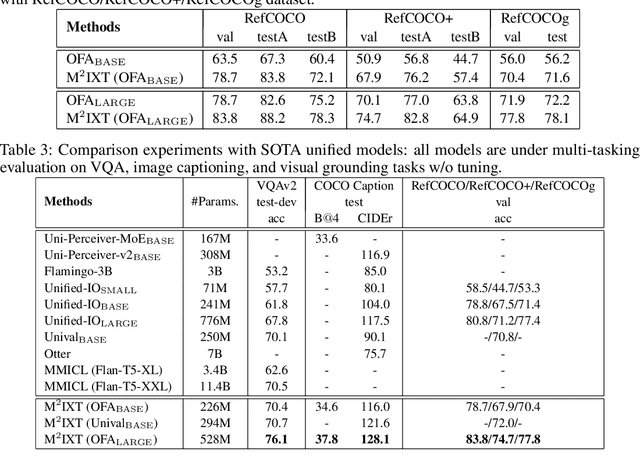
In-context learning (ICL) involves reasoning from given contextual examples. As more modalities comes, this procedure is becoming more challenging as the interleaved input modalities convolutes the understanding process. This is exemplified by the observation that multimodal models often struggle to effectively extrapolate from contextual examples to perform ICL. To address these challenges, we introduce MultiModal In-conteXt Tuning (M$^2$IXT), a lightweight module to enhance the ICL capabilities of multimodal unified models. The proposed M$^2$IXT module perceives an expandable context window to incorporate various labeled examples of multiple modalities (e.g., text, image, and coordinates). It can be prepended to various multimodal unified models (e.g., OFA, Unival, LLaVA) of different architectures and trained via a mixed-tasks strategy to enable rapid few-shot adaption on multiple tasks and datasets. When tuned on as little as 50K multimodal data, M$^2$IXT can boost the few-shot ICL performance significantly (e.g., 18\% relative increase for OFA), and obtained state-of-the-art results across an array of tasks including visual question answering, image captioning, visual grounding, and visual entailment, while being considerably small in terms of model parameters (e.g., $\sim$$20\times$ smaller than Flamingo or MMICL), highlighting the flexibility and effectiveness of M$^2$IXT as a multimodal in-context learner.
PanoMixSwap Panorama Mixing via Structural Swapping for Indoor Scene Understanding
Sep 27, 2023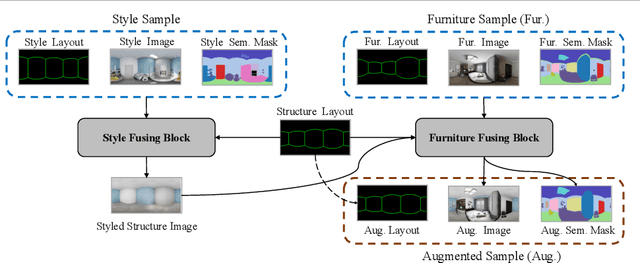
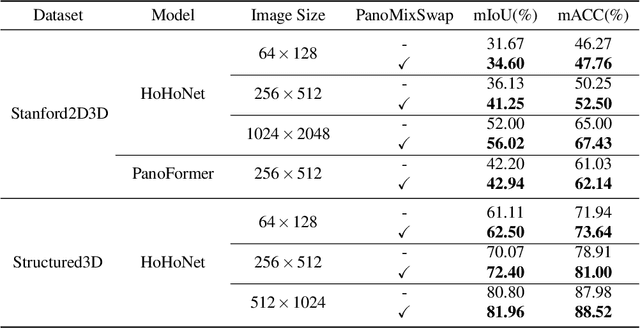
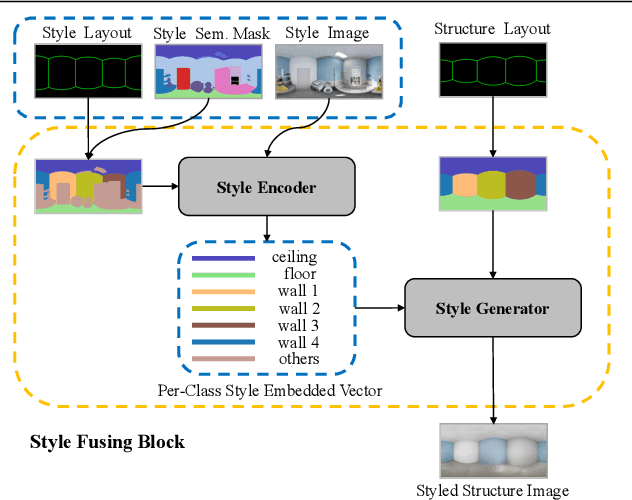

The volume and diversity of training data are critical for modern deep learningbased methods. Compared to the massive amount of labeled perspective images, 360 panoramic images fall short in both volume and diversity. In this paper, we propose PanoMixSwap, a novel data augmentation technique specifically designed for indoor panoramic images. PanoMixSwap explicitly mixes various background styles, foreground furniture, and room layouts from the existing indoor panorama datasets and generates a diverse set of new panoramic images to enrich the datasets. We first decompose each panoramic image into its constituent parts: background style, foreground furniture, and room layout. Then, we generate an augmented image by mixing these three parts from three different images, such as the foreground furniture from one image, the background style from another image, and the room structure from the third image. Our method yields high diversity since there is a cubical increase in image combinations. We also evaluate the effectiveness of PanoMixSwap on two indoor scene understanding tasks: semantic segmentation and layout estimation. Our experiments demonstrate that state-of-the-art methods trained with PanoMixSwap outperform their original setting on both tasks consistently.