 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Oct 14, 2023
Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. Towards this objective, we introduce MiniGPT-v2, a model that can be treated as a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After the three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question-answering and visual grounding benchmarks compared to other vision-language generalist models. Our model and codes are available at https://minigpt-v2.github.io/
Multimodal Dataset Distillation for Image-Text Retrieval
Aug 15, 2023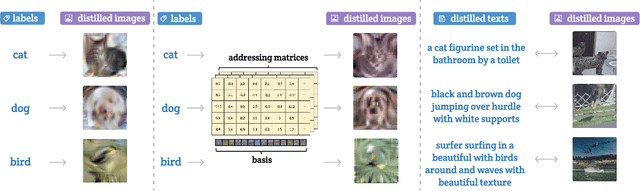
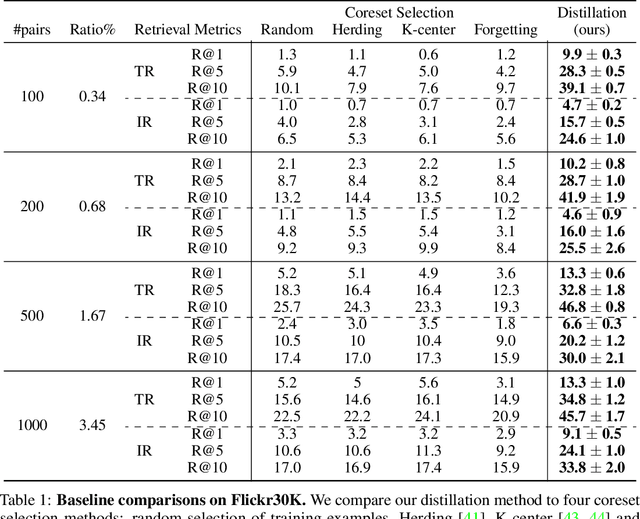
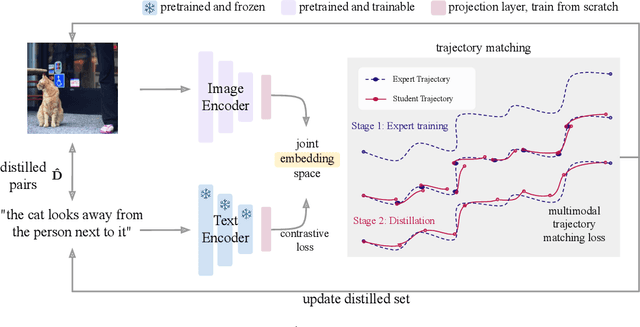
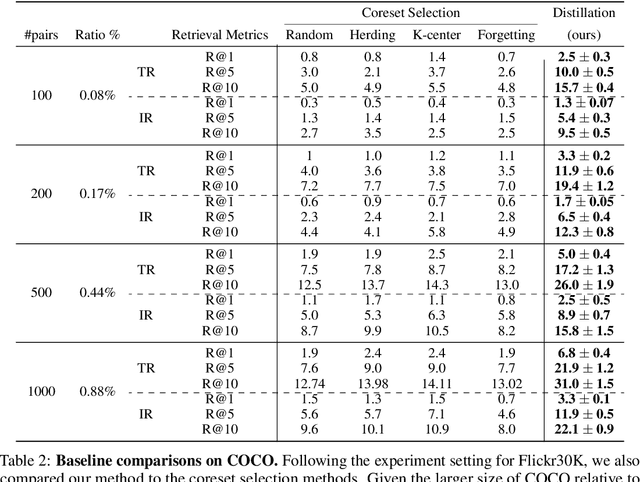
Dataset distillation methods offer the promise of reducing a large-scale dataset down to a significantly smaller set of (potentially synthetic) training examples, which preserve sufficient information for training a new model from scratch. So far dataset distillation methods have been developed for image classification. However, with the rise in capabilities of vision-language models, and especially given the scale of datasets necessary to train these models, the time is ripe to expand dataset distillation methods beyond image classification. In this work, we take the first steps towards this goal by expanding on the idea of trajectory matching to create a distillation method for vision-language datasets. The key challenge is that vision-language datasets do not have a set of discrete classes. To overcome this, our proposed multimodal dataset distillation method jointly distill the images and their corresponding language descriptions in a contrastive formulation. Since there are no existing baselines, we compare our approach to three coreset selection methods (strategic subsampling of the training dataset), which we adapt to the vision-language setting. We demonstrate significant improvements on the challenging Flickr30K and COCO retrieval benchmark: the best coreset selection method which selects 1000 image-text pairs for training is able to achieve only 5.6% image-to-text retrieval accuracy (recall@1); in contrast, our dataset distillation approach almost doubles that with just 100 (an order of magnitude fewer) training pairs.
Prompt-tuning latent diffusion models for inverse problems
Oct 02, 2023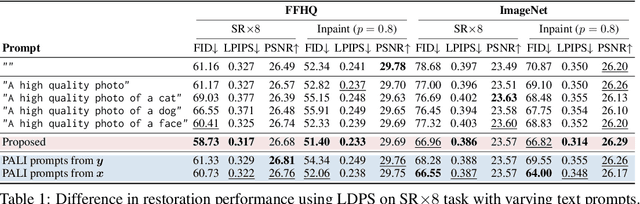
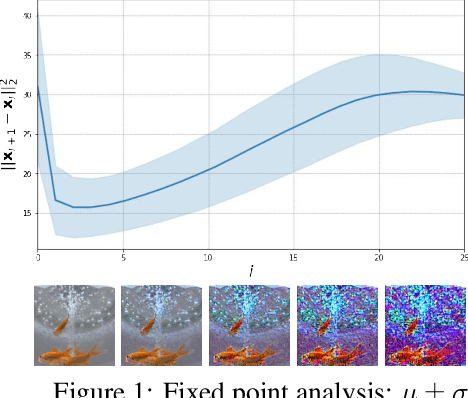
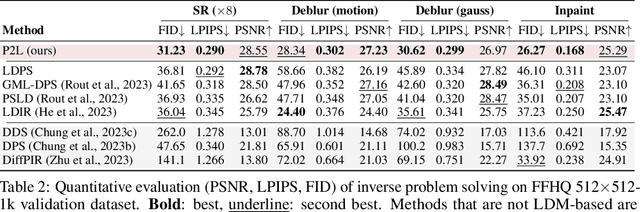

We propose a new method for solving imaging inverse problems using text-to-image latent diffusion models as general priors. Existing methods using latent diffusion models for inverse problems typically rely on simple null text prompts, which can lead to suboptimal performance. To address this limitation, we introduce a method for prompt tuning, which jointly optimizes the text embedding on-the-fly while running the reverse diffusion process. This allows us to generate images that are more faithful to the diffusion prior. In addition, we propose a method to keep the evolution of latent variables within the range space of the encoder, by projection. This helps to reduce image artifacts, a major problem when using latent diffusion models instead of pixel-based diffusion models. Our combined method, called P2L, outperforms both image- and latent-diffusion model-based inverse problem solvers on a variety of tasks, such as super-resolution, deblurring, and inpainting.
On the Localization of Ultrasound Image Slices within Point Distribution Models
Sep 01, 2023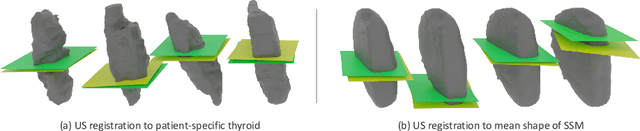
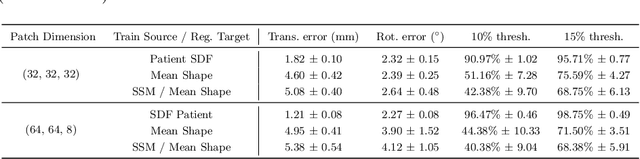
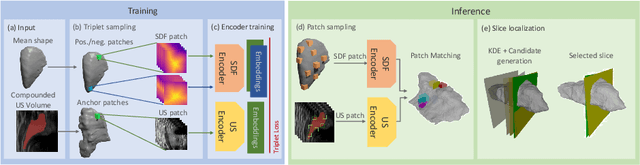
Thyroid disorders are most commonly diagnosed using high-resolution Ultrasound (US). Longitudinal nodule tracking is a pivotal diagnostic protocol for monitoring changes in pathological thyroid morphology. This task, however, imposes a substantial cognitive load on clinicians due to the inherent challenge of maintaining a mental 3D reconstruction of the organ. We thus present a framework for automated US image slice localization within a 3D shape representation to ease how such sonographic diagnoses are carried out. Our proposed method learns a common latent embedding space between US image patches and the 3D surface of an individual's thyroid shape, or a statistical aggregation in the form of a statistical shape model (SSM), via contrastive metric learning. Using cross-modality registration and Procrustes analysis, we leverage features from our model to register US slices to a 3D mesh representation of the thyroid shape. We demonstrate that our multi-modal registration framework can localize images on the 3D surface topology of a patient-specific organ and the mean shape of an SSM. Experimental results indicate slice positions can be predicted within an average of 1.2 mm of the ground-truth slice location on the patient-specific 3D anatomy and 4.6 mm on the SSM, exemplifying its usefulness for slice localization during sonographic acquisitions. Code is publically available: \href{https://github.com/vuenc/slice-to-shape}{https://github.com/vuenc/slice-to-shape}
MetaWeather: Few-Shot Weather-Degraded Image Restoration via Degradation Pattern Matching
Aug 28, 2023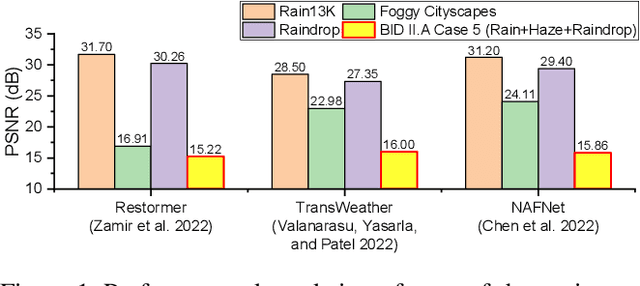
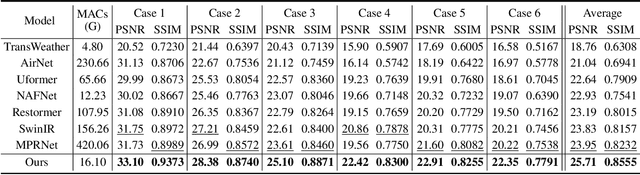
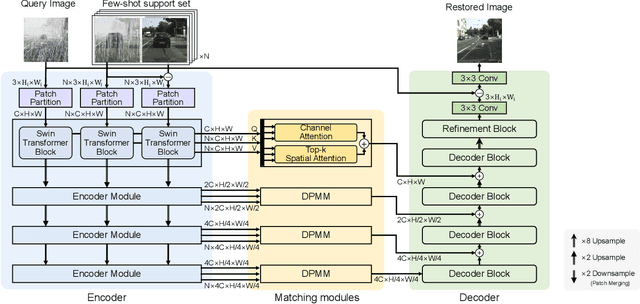

Real-world vision tasks frequently suffer from the appearance of adverse weather conditions including rain, fog, snow, and raindrops in captured images. Recently, several generic methods for restoring weather-degraded images have been proposed, aiming to remove multiple types of adverse weather effects present in the images. However, these methods have considered weather as discrete and mutually exclusive variables, leading to failure in generalizing to unforeseen weather conditions beyond the scope of the training data, such as the co-occurrence of rain, fog, and raindrops. To this end, weather-degraded image restoration models should have flexible adaptability to the current unknown weather condition to ensure reliable and optimal performance. The adaptation method should also be able to cope with data scarcity for real-world adaptation. This paper proposes MetaWeather, a few-shot weather-degraded image restoration method for arbitrary weather conditions. For this, we devise the core piece of MetaWeather, coined Degradation Pattern Matching Module (DPMM), which leverages representations from a few-shot support set by matching features between input and sample images under new weather conditions. In addition, we build meta-knowledge with episodic meta-learning on top of our MetaWeather architecture to provide flexible adaptability. In the meta-testing phase, we adopt a parameter-efficient fine-tuning method to preserve the prebuilt knowledge and avoid the overfitting problem. Experiments on the BID Task II.A dataset show our method achieves the best performance on PSNR and SSIM compared to state-of-the-art image restoration methods. Code is available at (TBA).
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Oct 09, 2023In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) for visual commonsense reasoning (VCR). We categorize the problem of VCR into visual commonsense understanding (VCU) and visual commonsense inference (VCI). For VCU, which involves perceiving the literal visual content, pre-trained VLMs exhibit strong cross-dataset generalization. On the other hand, in VCI, where the goal is to infer conclusions beyond image content, VLMs face difficulties. We find that a baseline where VLMs provide perception results (image captions) to LLMs leads to improved performance on VCI. However, we identify a challenge with VLMs' passive perception, which often misses crucial context information, leading to incorrect or uncertain reasoning by LLMs. To mitigate this issue, we suggest a collaborative approach where LLMs, when uncertain about their reasoning, actively direct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. In our method, named ViCor, pre-trained LLMs serve as problem classifiers to analyze the problem category, VLM commanders to leverage VLMs differently based on the problem classification, and visual commonsense reasoners to answer the question. VLMs will perform visual recognition and understanding. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain supervised fine-tuning.
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 18, 2023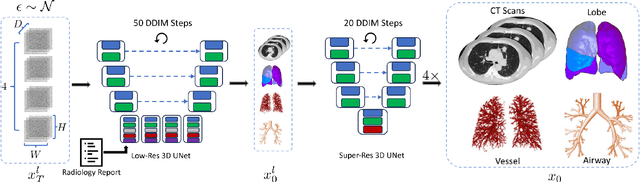
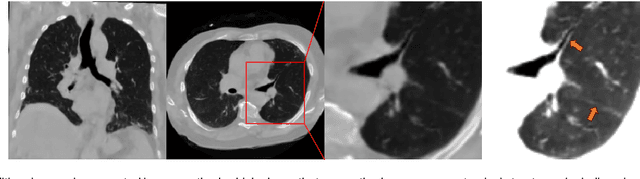
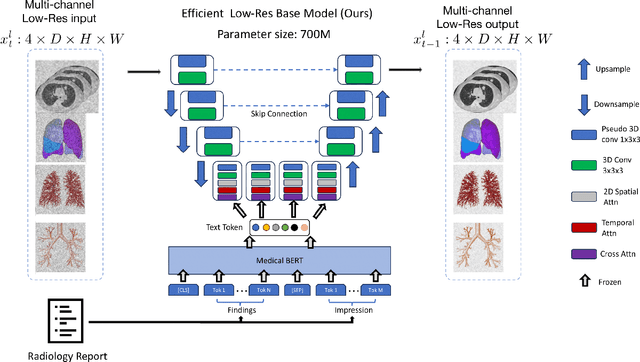
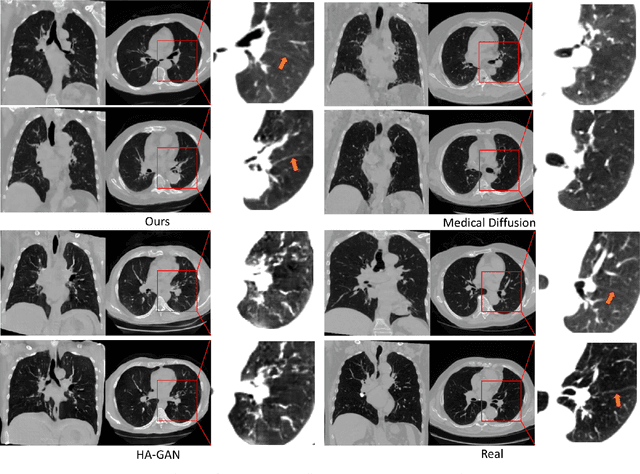
This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Oct 18, 2023Machine learning models are increasingly being scaled in both sequence length and model dimension to reach longer contexts and better performance. However, existing architectures such as Transformers scale quadratically along both these axes. We ask: are there performant architectures that can scale sub-quadratically along sequence length and model dimension? We introduce Monarch Mixer (M2), a new architecture that uses the same sub-quadratic primitive along both sequence length and model dimension: Monarch matrices, a simple class of expressive structured matrices that captures many linear transforms, achieves high hardware efficiency on GPUs, and scales sub-quadratically. As a proof of concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling. For non-causal BERT-style modeling, M2 matches BERT-base and BERT-large in downstream GLUE quality with up to 27% fewer parameters, and achieves up to 9.1$\times$ higher throughput at sequence length 4K. On ImageNet, M2 outperforms ViT-b by 1% in accuracy, with only half the parameters. Causal GPT-style models introduce a technical challenge: enforcing causality via masking introduces a quadratic bottleneck. To alleviate this bottleneck, we develop a novel theoretical view of Monarch matrices based on multivariate polynomial evaluation and interpolation, which lets us parameterize M2 to be causal while remaining sub-quadratic. Using this parameterization, M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on The PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
Beyond Self-Attention: Deformable Large Kernel Attention for Medical Image Segmentation
Aug 31, 2023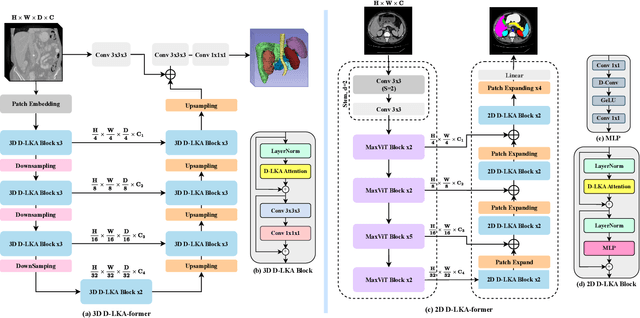
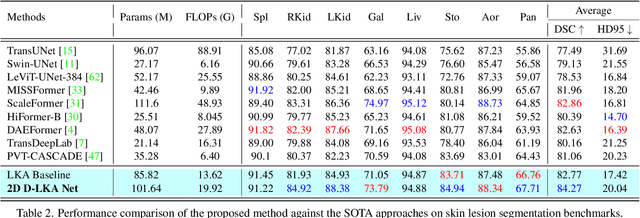
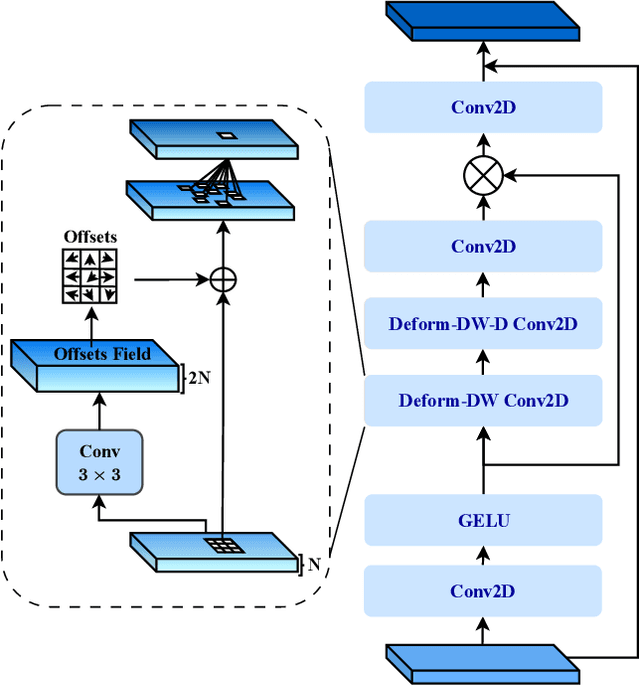
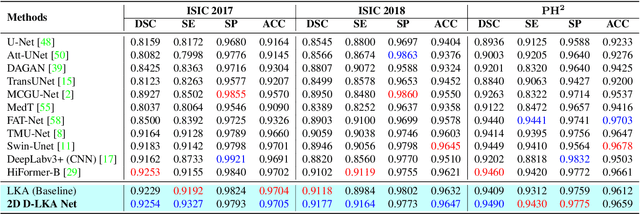
Medical image segmentation has seen significant improvements with transformer models, which excel in grasping far-reaching contexts and global contextual information. However, the increasing computational demands of these models, proportional to the squared token count, limit their depth and resolution capabilities. Most current methods process D volumetric image data slice-by-slice (called pseudo 3D), missing crucial inter-slice information and thus reducing the model's overall performance. To address these challenges, we introduce the concept of \textbf{Deformable Large Kernel Attention (D-LKA Attention)}, a streamlined attention mechanism employing large convolution kernels to fully appreciate volumetric context. This mechanism operates within a receptive field akin to self-attention while sidestepping the computational overhead. Additionally, our proposed attention mechanism benefits from deformable convolutions to flexibly warp the sampling grid, enabling the model to adapt appropriately to diverse data patterns. We designed both 2D and 3D adaptations of the D-LKA Attention, with the latter excelling in cross-depth data understanding. Together, these components shape our novel hierarchical Vision Transformer architecture, the \textit{D-LKA Net}. Evaluations of our model against leading methods on popular medical segmentation datasets (Synapse, NIH Pancreas, and Skin lesion) demonstrate its superior performance. Our code implementation is publicly available at the: https://github.com/mindflow-institue/deformableLKA
Foundation Model-oriented Robustness: Robust Image Model Evaluation with Pretrained Models
Aug 23, 2023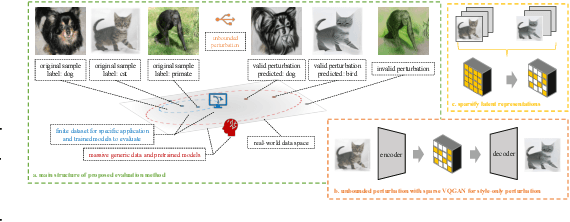
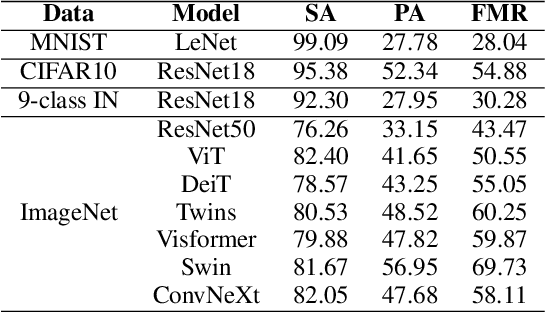
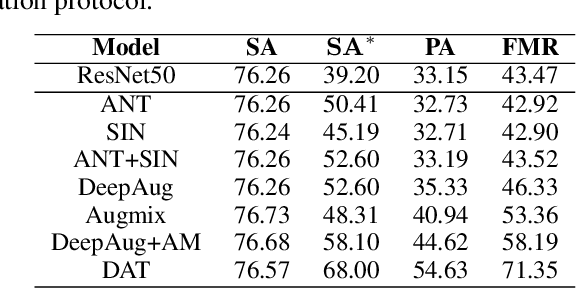

Machine learning has demonstrated remarkable performance over finite datasets, yet whether the scores over the fixed benchmarks can sufficiently indicate the model's performance in the real world is still in discussion. In reality, an ideal robust model will probably behave similarly to the oracle (e.g., the human users), thus a good evaluation protocol is probably to evaluate the models' behaviors in comparison to the oracle. In this paper, we introduce a new robustness measurement that directly measures the image classification model's performance compared with a surrogate oracle (i.e., a foundation model). Besides, we design a simple method that can accomplish the evaluation beyond the scope of the benchmarks. Our method extends the image datasets with new samples that are sufficiently perturbed to be distinct from the ones in the original sets, but are still bounded within the same image-label structure the original test image represents, constrained by a foundation model pretrained with a large amount of samples. As a result, our new method will offer us a new way to evaluate the models' robustness performance, free of limitations of fixed benchmarks or constrained perturbations, although scoped by the power of the oracle. In addition to the evaluation results, we also leverage our generated data to understand the behaviors of the model and our new evaluation strategies.