 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections
Sep 05, 2023
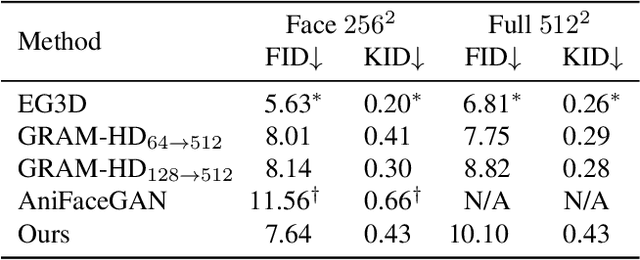
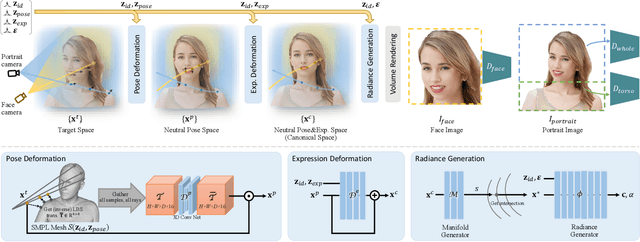


Previous animatable 3D-aware GANs for human generation have primarily focused on either the human head or full body. However, head-only videos are relatively uncommon in real life, and full body generation typically does not deal with facial expression control and still has challenges in generating high-quality results. Towards applicable video avatars, we present an animatable 3D-aware GAN that generates portrait images with controllable facial expression, head pose, and shoulder movements. It is a generative model trained on unstructured 2D image collections without using 3D or video data. For the new task, we base our method on the generative radiance manifold representation and equip it with learnable facial and head-shoulder deformations. A dual-camera rendering and adversarial learning scheme is proposed to improve the quality of the generated faces, which is critical for portrait images. A pose deformation processing network is developed to generate plausible deformations for challenging regions such as long hair. Experiments show that our method, trained on unstructured 2D images, can generate diverse and high-quality 3D portraits with desired control over different properties.
Multi-Depth Branches Network for Efficient Image Super-Resolution
Sep 29, 2023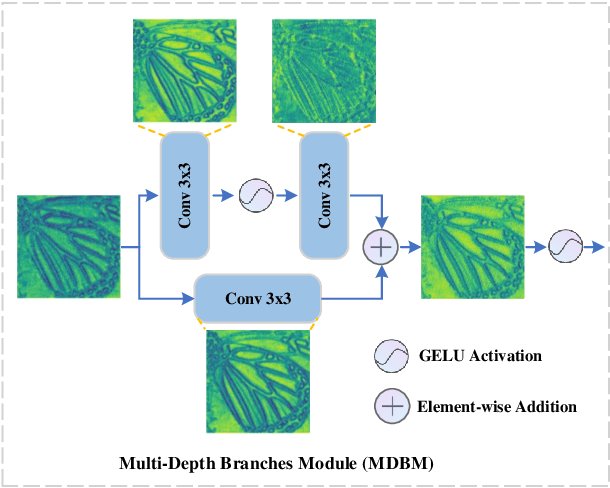
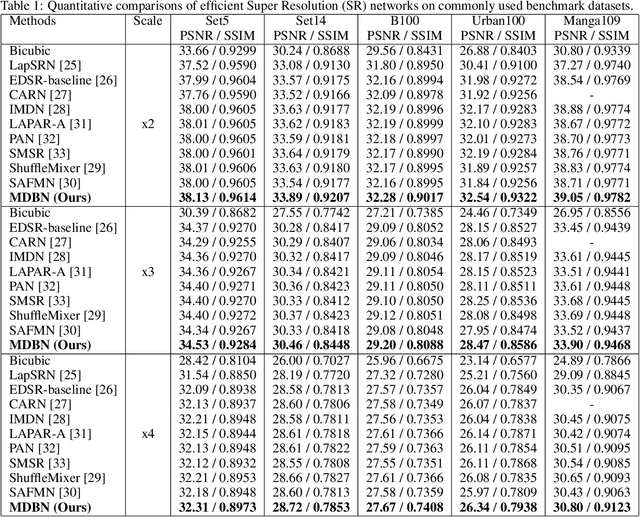
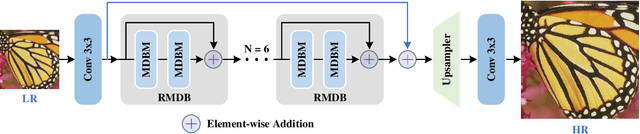
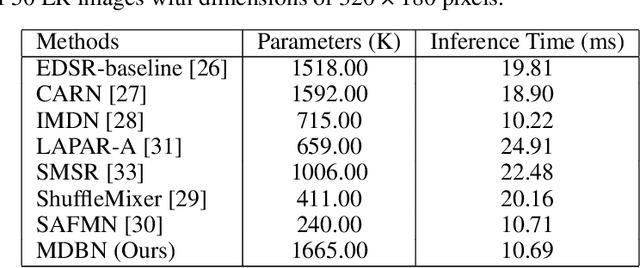
Significant progress has been made in the field of super-resolution (SR), yet many convolutional neural networks (CNNs) based SR models primarily focus on restoring high-frequency details, often overlooking crucial low-frequency contour information. Transformer-based SR methods, while incorporating global structural details, frequently come with an abundance of parameters, leading to high computational overhead. In this paper, we address these challenges by introducing a Multi-Depth Branches Network (MDBN). This framework extends the ResNet architecture by integrating an additional branch that captures vital structural characteristics of images. Our proposed multi-depth branches module (MDBM) involves the stacking of convolutional kernels of identical size at varying depths within distinct branches. By conducting a comprehensive analysis of the feature maps, we observe that branches with differing depths can extract contour and detail information respectively. By integrating these branches, the overall architecture can preserve essential low-frequency semantic structural information during the restoration of high-frequency visual elements, which is more closely with human visual cognition. Compared to GoogLeNet-like models, our basic multi-depth branches structure has fewer parameters, higher computational efficiency, and improved performance. Our model outperforms state-of-the-art (SOTA) lightweight SR methods with less inference time. Our code is available at https://github.com/thy960112/MDBN
Asymmetric Co-Training with Explainable Cell Graph Ensembling for Histopathological Image Classification
Aug 24, 2023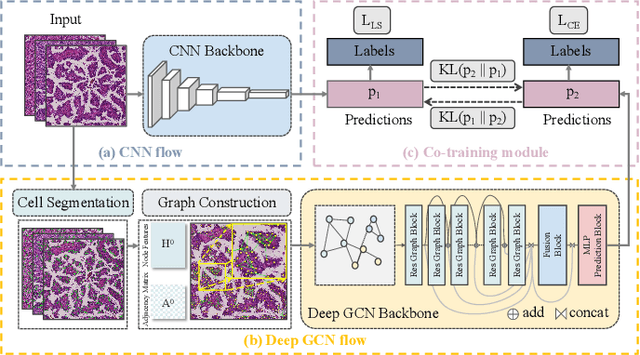
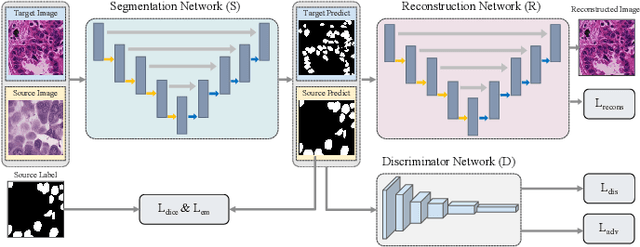
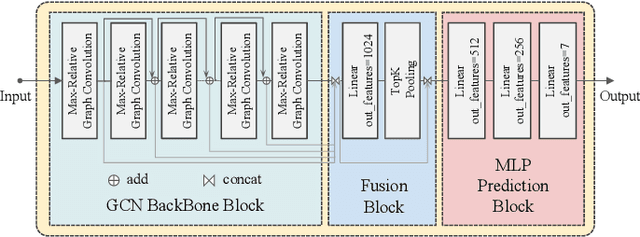
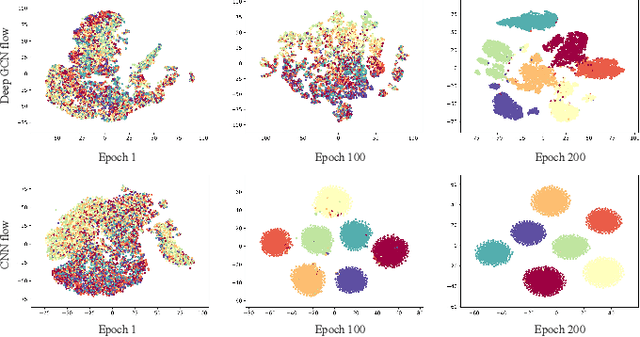
Convolutional neural networks excel in histopathological image classification, yet their pixel-level focus hampers explainability. Conversely, emerging graph convolutional networks spotlight cell-level features and medical implications. However, limited by their shallowness and suboptimal use of high-dimensional pixel data, GCNs underperform in multi-class histopathological image classification. To make full use of pixel-level and cell-level features dynamically, we propose an asymmetric co-training framework combining a deep graph convolutional network and a convolutional neural network for multi-class histopathological image classification. To improve the explainability of the entire framework by embedding morphological and topological distribution of cells, we build a 14-layer deep graph convolutional network to handle cell graph data. For the further utilization and dynamic interactions between pixel-level and cell-level information, we also design a co-training strategy to integrate the two asymmetric branches. Notably, we collect a private clinically acquired dataset termed LUAD7C, including seven subtypes of lung adenocarcinoma, which is rare and more challenging. We evaluated our approach on the private LUAD7C and public colorectal cancer datasets, showcasing its superior performance, explainability, and generalizability in multi-class histopathological image classification.
Hierarchical Concept Discovery Models: A Concept Pyramid Scheme
Oct 03, 2023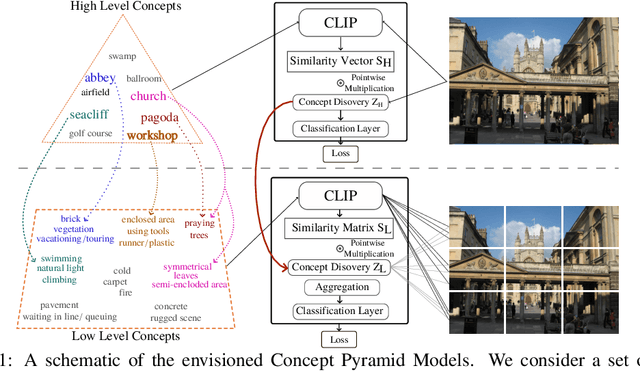
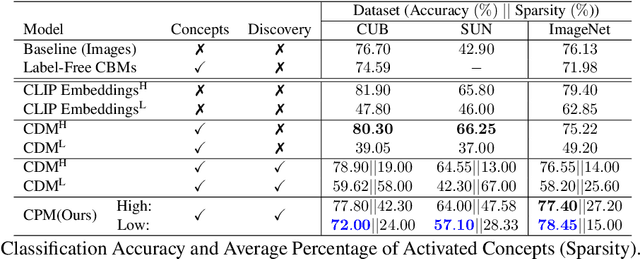
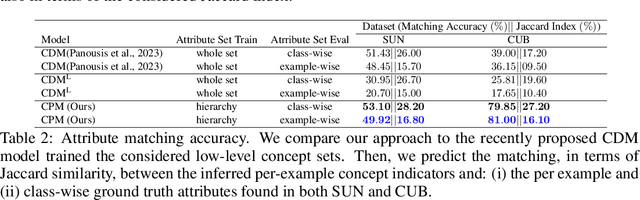

Deep Learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on multiple levels of granularity. To this end, we propose a novel hierarchical concept discovery formulation leveraging: (i) recent advances in image-text models, and (ii) an innovative formulation for multi-level concept selection via data-driven and sparsity inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.
Beyond Segmentation: Road Network Generation with Multi-Modal LLMs
Oct 15, 2023This paper introduces an innovative approach to road network generation through the utilization of a multi-modal Large Language Model (LLM). Our model is specifically designed to process aerial images of road layouts and produce detailed, navigable road networks within the input images. The core innovation of our system lies in the unique training methodology employed for the large language model to generate road networks as its output. This approach draws inspiration from the BLIP-2 architecture arXiv:2301.12597, leveraging pre-trained frozen image encoders and large language models to create a versatile multi-modal LLM. Our work also offers an alternative to the reasoning segmentation method proposed in the LISA paper arXiv:2308.00692. By training the large language model with our approach, the necessity for generating binary segmentation masks, as suggested in the LISA paper arXiv:2308.00692, is effectively eliminated. Experimental results underscore the efficacy of our multi-modal LLM in providing precise and valuable navigational guidance. This research represents a significant stride in bolstering autonomous navigation systems, especially in road network scenarios, where accurate guidance is of paramount importance.
Estimating Uncertainty in Multimodal Foundation Models using Public Internet Data
Oct 15, 2023Foundation models are trained on vast amounts of data at scale using self-supervised learning, enabling adaptation to a wide range of downstream tasks. At test time, these models exhibit zero-shot capabilities through which they can classify previously unseen (user-specified) categories. In this paper, we address the problem of quantifying uncertainty in these zero-shot predictions. We propose a heuristic approach for uncertainty estimation in zero-shot settings using conformal prediction with web data. Given a set of classes at test time, we conduct zero-shot classification with CLIP-style models using a prompt template, e.g., "an image of a <category>", and use the same template as a search query to source calibration data from the open web. Given a web-based calibration set, we apply conformal prediction with a novel conformity score that accounts for potential errors in retrieved web data. We evaluate the utility of our proposed method in Biomedical foundation models; our preliminary results show that web-based conformal prediction sets achieve the target coverage with satisfactory efficiency on a variety of biomedical datasets.
Bridging Distribution Learning and Image Clustering in High-dimensional Space
Aug 29, 2023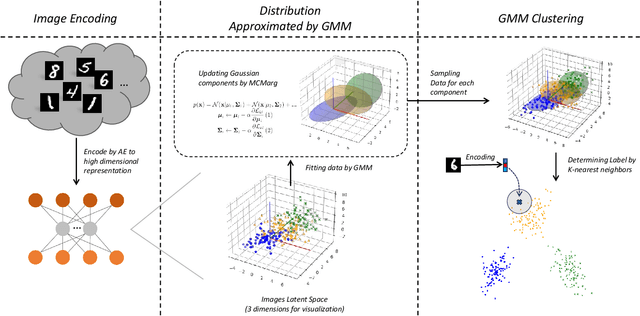
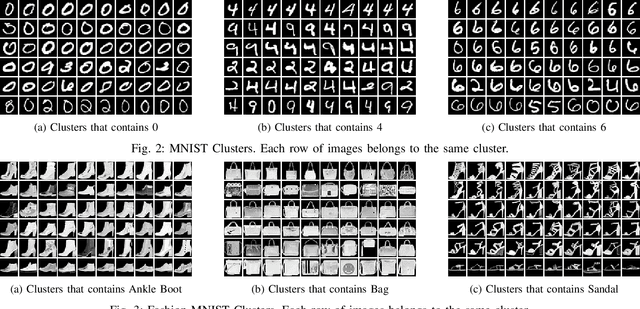
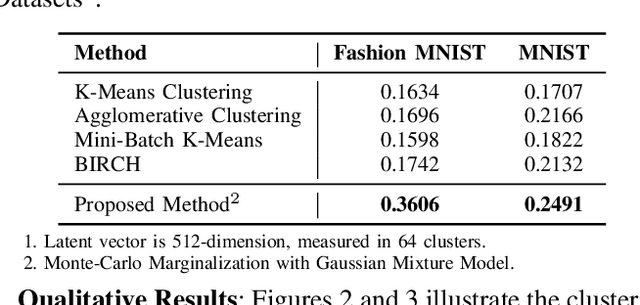

Distribution learning focuses on learning the probability density function from a set of data samples. In contrast, clustering aims to group similar objects together in an unsupervised manner. Usually, these two tasks are considered unrelated. However, the relationship between the two may be indirectly correlated, with Gaussian Mixture Models (GMM) acting as a bridge. In this paper, we focus on exploring the correlation between distribution learning and clustering, with the motivation to fill the gap between these two fields, utilizing an autoencoder (AE) to encode images into a high-dimensional latent space. Then, Monte-Carlo Marginalization (MCMarg) and Kullback-Leibler (KL) divergence loss are used to fit the Gaussian components of the GMM and learn the data distribution. Finally, image clustering is achieved through each Gaussian component of GMM. Yet, the "curse of dimensionality" poses severe challenges for most clustering algorithms. Compared with the classic Expectation-Maximization (EM) Algorithm, experimental results show that MCMarg and KL divergence can greatly alleviate the difficulty. Based on the experimental results, we believe distribution learning can exploit the potential of GMM in image clustering within high-dimensional space.
EXMODD: An EXplanatory Multimodal Open-Domain Dialogue dataset
Oct 17, 2023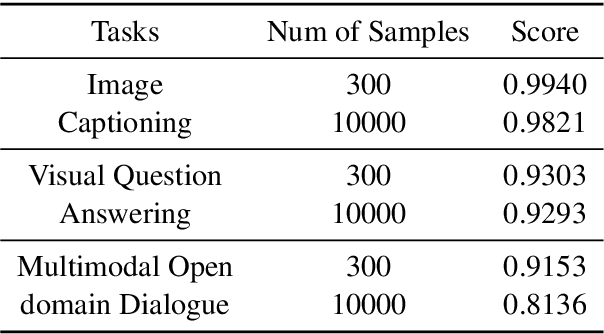

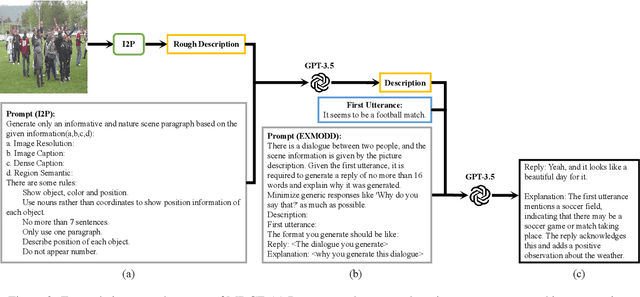
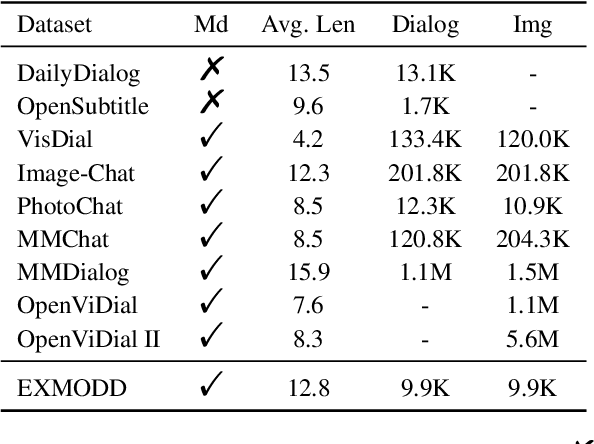
The need for high-quality data has been a key issue hindering the research of dialogue tasks. Recent studies try to build datasets through manual, web crawling, and large pre-trained models. However, man-made data is expensive and data collected from the internet often includes generic responses, meaningless statements, and toxic dialogues. Automatic data generation through large models is a cost-effective method, but for open-domain multimodal dialogue tasks, there are still three drawbacks: 1) There is currently no open-source large model that can accept multimodal input; 2) The content generated by the model lacks interpretability; 3) The generated data is usually difficult to quality control and require extensive resource to collect. To alleviate the significant human and resource expenditure in data collection, we propose a Multimodal Data Construction Framework (MDCF). MDCF designs proper prompts to spur the large-scale pre-trained language model to generate well-formed and satisfactory content. Additionally, MDCF also automatically provides explanation for a given image and its corresponding dialogue, which can provide a certain degree of interpretability and facilitate manual follow-up quality inspection. Based on this, we release an Explanatory Multimodal Open-Domain dialogue dataset (EXMODD). Experiments indicate a positive correlation between the model's ability to generate accurate understandings and high-quality responses. Our code and data can be found at https://github.com/poplpr/EXMODD.
Can GPT-4V(ision) Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis
Oct 17, 2023Driven by the large foundation models, the development of artificial intelligence has witnessed tremendous progress lately, leading to a surge of general interest from the public. In this study, we aim to assess the performance of OpenAI's newest model, GPT-4V(ision), specifically in the realm of multimodal medical diagnosis. Our evaluation encompasses 17 human body systems, including Central Nervous System, Head and Neck, Cardiac, Chest, Hematology, Hepatobiliary, Gastrointestinal, Urogenital, Gynecology, Obstetrics, Breast, Musculoskeletal, Spine, Vascular, Oncology, Trauma, Pediatrics, with images taken from 8 modalities used in daily clinic routine, e.g., X-ray, Computed Tomography (CT), Magnetic Resonance Imaging (MRI), Positron Emission Tomography (PET), Digital Subtraction Angiography (DSA), Mammography, Ultrasound, and Pathology. We probe the GPT-4V's ability on multiple clinical tasks with or without patent history provided, including imaging modality and anatomy recognition, disease diagnosis, report generation, disease localisation. Our observation shows that, while GPT-4V demonstrates proficiency in distinguishing between medical image modalities and anatomy, it faces significant challenges in disease diagnosis and generating comprehensive reports. These findings underscore that while large multimodal models have made significant advancements in computer vision and natural language processing, it remains far from being used to effectively support real-world medical applications and clinical decision-making. All images used in this report can be found in https://github.com/chaoyi-wu/GPT-4V_Medical_Evaluation.
Learning Neural Implicit through Volume Rendering with Attentive Depth Fusion Priors
Oct 17, 2023Learning neural implicit representations has achieved remarkable performance in 3D reconstruction from multi-view images. Current methods use volume rendering to render implicit representations into either RGB or depth images that are supervised by multi-view ground truth. However, rendering a view each time suffers from incomplete depth at holes and unawareness of occluded structures from the depth supervision, which severely affects the accuracy of geometry inference via volume rendering. To resolve this issue, we propose to learn neural implicit representations from multi-view RGBD images through volume rendering with an attentive depth fusion prior. Our prior allows neural networks to perceive coarse 3D structures from the Truncated Signed Distance Function (TSDF) fused from all depth images available for rendering. The TSDF enables accessing the missing depth at holes on one depth image and the occluded parts that are invisible from the current view. By introducing a novel attention mechanism, we allow neural networks to directly use the depth fusion prior with the inferred occupancy as the learned implicit function. Our attention mechanism works with either a one-time fused TSDF that represents a whole scene or an incrementally fused TSDF that represents a partial scene in the context of Simultaneous Localization and Mapping (SLAM). Our evaluations on widely used benchmarks including synthetic and real-world scans show our superiority over the latest neural implicit methods. Project page: https://machineperceptionlab.github.io/Attentive_DF_Prior/