 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey on Video Diffusion Models
Oct 16, 2023
The recent wave of AI-generated content (AIGC) has witnessed substantial success in computer vision, with the diffusion model playing a crucial role in this achievement. Due to their impressive generative capabilities, diffusion models are gradually superseding methods based on GANs and auto-regressive Transformers, demonstrating exceptional performance not only in image generation and editing, but also in the realm of video-related research. However, existing surveys mainly focus on diffusion models in the context of image generation, with few up-to-date reviews on their application in the video domain. To address this gap, this paper presents a comprehensive review of video diffusion models in the AIGC era. Specifically, we begin with a concise introduction to the fundamentals and evolution of diffusion models. Subsequently, we present an overview of research on diffusion models in the video domain, categorizing the work into three key areas: video generation, video editing, and other video understanding tasks. We conduct a thorough review of the literature in these three key areas, including further categorization and practical contributions in the field. Finally, we discuss the challenges faced by research in this domain and outline potential future developmental trends. A comprehensive list of video diffusion models studied in this survey is available at https://github.com/ChenHsing/Awesome-Video-Diffusion-Models.
BiLL-VTG: Bridging Large Language Models and Lightweight Visual Tools for Video-based Texts Generation
Oct 16, 2023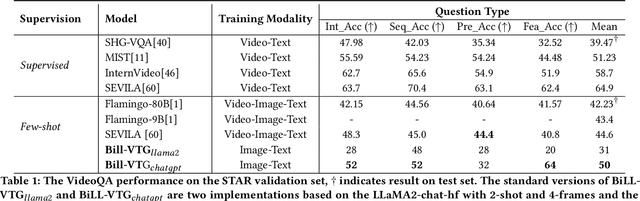
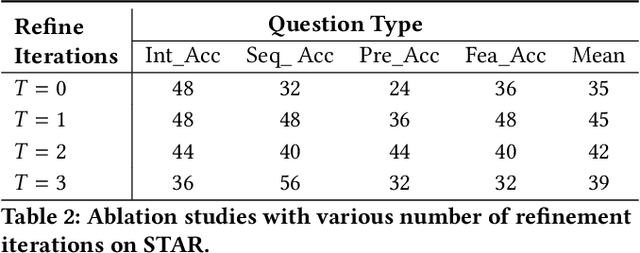
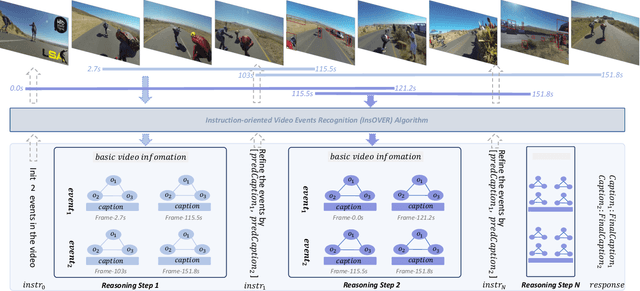
Building models that generate textual responses to user instructions for videos is a practical and challenging topic, as it requires both vision understanding and knowledge reasoning. Compared to language and image modalities, training efficiency remains a serious problem as existing studies train models on massive sparse videos aligned with brief descriptions. In this paper, we introduce BiLL-VTG, a fast adaptive framework that leverages large language models (LLMs) to reasoning on videos based on essential lightweight visual tools. Specifically, we reveal the key to response specific instructions is the concentration on relevant video events, and utilize two visual tools of structured scene graph generation and descriptive image caption generation to gather and represent the events information. Thus, a LLM equipped with world knowledge is adopted as the reasoning agent to achieve the response by performing multiple reasoning steps on specified video events.To address the difficulty of specifying events from agent, we further propose an Instruction-oriented Video Events Recognition (InsOVER) algorithm based on the efficient Hungarian matching to localize corresponding video events using linguistic instructions, enabling LLMs to interact with long videos. Extensive experiments on two typical video-based texts generations tasks show that our tuning-free framework outperforms the pre-trained models including Flamingo-80B, to achieve the state-of-the-art performance.
ConsistNet: Enforcing 3D Consistency for Multi-view Images Diffusion
Oct 16, 2023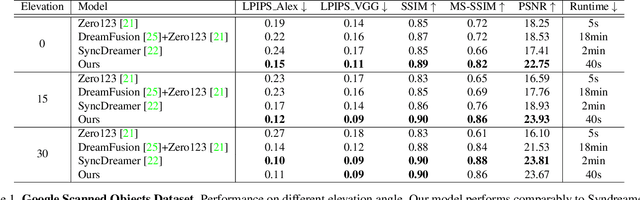
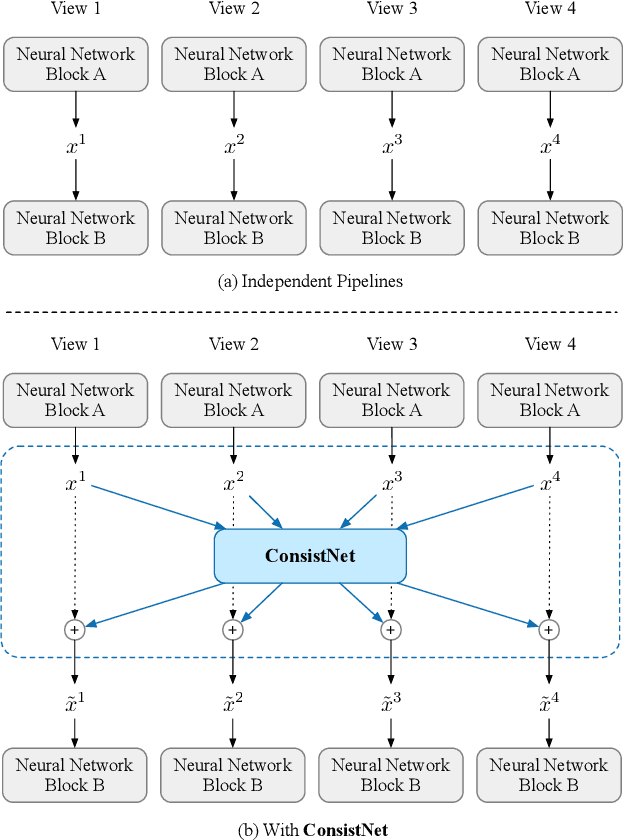
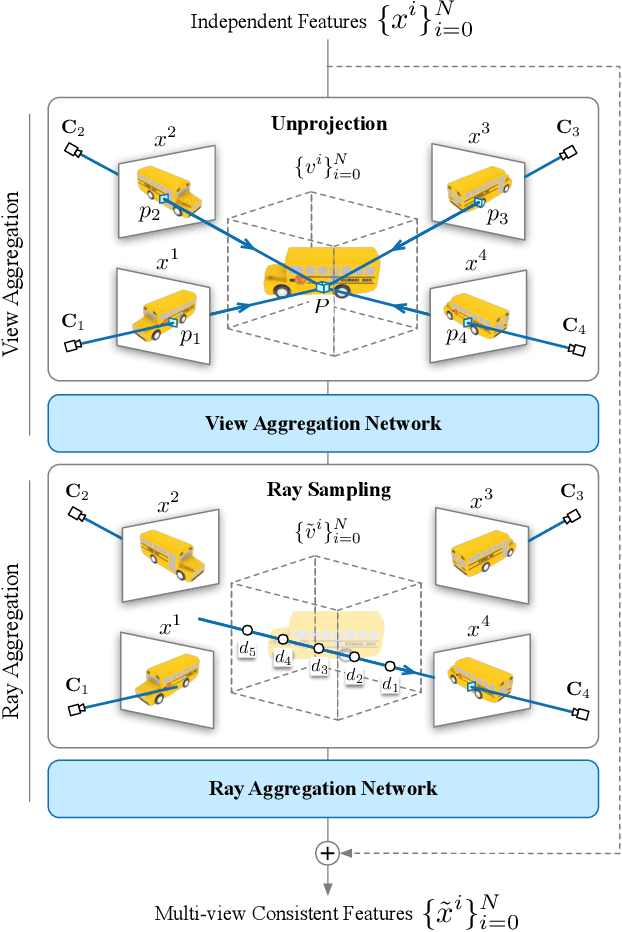
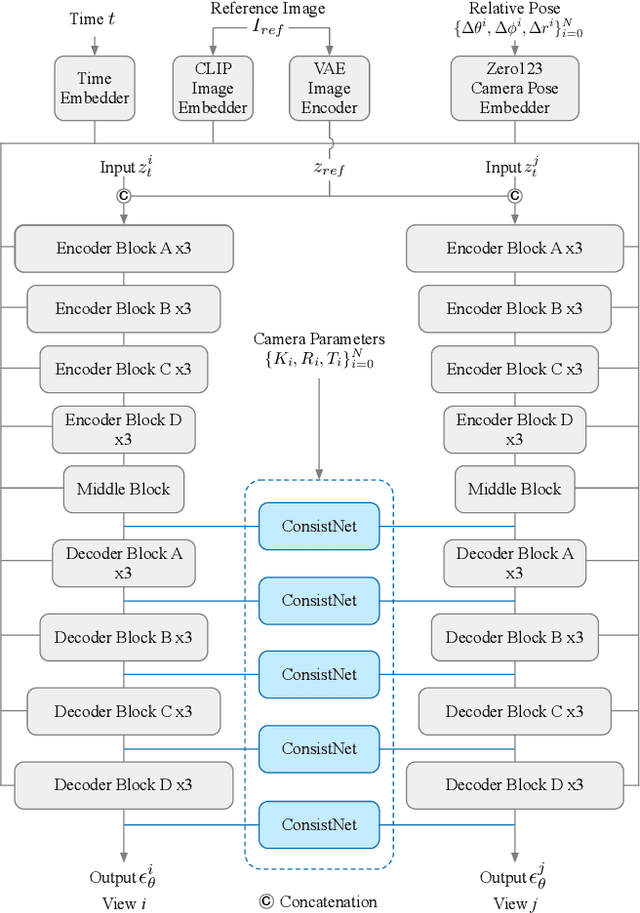
Given a single image of a 3D object, this paper proposes a novel method (named ConsistNet) that is able to generate multiple images of the same object, as if seen they are captured from different viewpoints, while the 3D (multi-view) consistencies among those multiple generated images are effectively exploited. Central to our method is a multi-view consistency block which enables information exchange across multiple single-view diffusion processes based on the underlying multi-view geometry principles. ConsistNet is an extension to the standard latent diffusion model, and consists of two sub-modules: (a) a view aggregation module that unprojects multi-view features into global 3D volumes and infer consistency, and (b) a ray aggregation module that samples and aggregate 3D consistent features back to each view to enforce consistency. Our approach departs from previous methods in multi-view image generation, in that it can be easily dropped-in pre-trained LDMs without requiring explicit pixel correspondences or depth prediction. Experiments show that our method effectively learns 3D consistency over a frozen Zero123 backbone and can generate 16 surrounding views of the object within 40 seconds on a single A100 GPU. Our code will be made available on https://github.com/JiayuYANG/ConsistNet
GRaMuFeN: Graph-based Multi-modal Fake News Detection in Social Media
Oct 11, 2023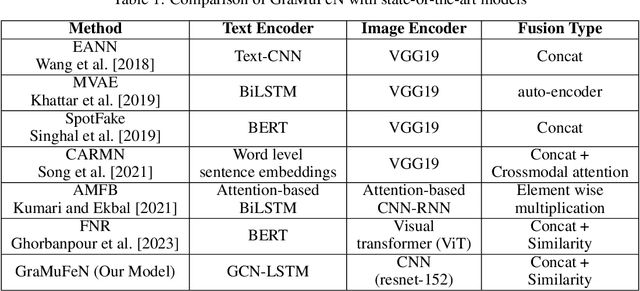
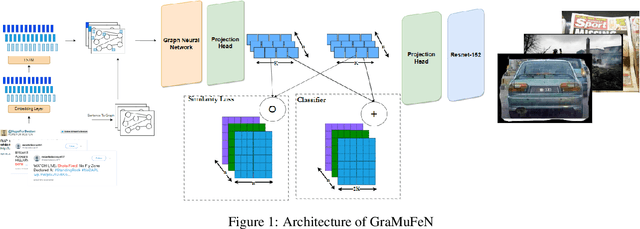
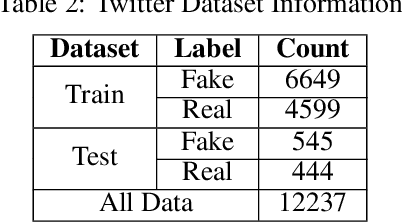
The proliferation of social media platforms such as Twitter, Instagram, and Weibo has significantly enhanced the dissemination of false information. This phenomenon grants both individuals and governmental entities the ability to shape public opinions, highlighting the need for deploying effective detection methods. In this paper, we propose GraMuFeN, a model designed to detect fake content by analyzing both the textual and image content of news. GraMuFeN comprises two primary components: a text encoder and an image encoder. For textual analysis, GraMuFeN treats each text as a graph and employs a Graph Convolutional Neural Network (GCN) as the text encoder. Additionally, the pre-trained ResNet-152, as a Convolutional Neural Network (CNN), has been utilized as the image encoder. By integrating the outputs from these two encoders and implementing a contrastive similarity loss function, GraMuFeN achieves remarkable results. Extensive evaluations conducted on two publicly available benchmark datasets for social media news indicate a 10 % increase in micro F1-Score, signifying improvement over existing state-of-the-art models. These findings underscore the effectiveness of combining GCN and CNN models for detecting fake news in multi-modal data, all while minimizing the additional computational burden imposed by model parameters.
Ferret: Refer and Ground Anything Anywhere at Any Granularity
Oct 11, 2023

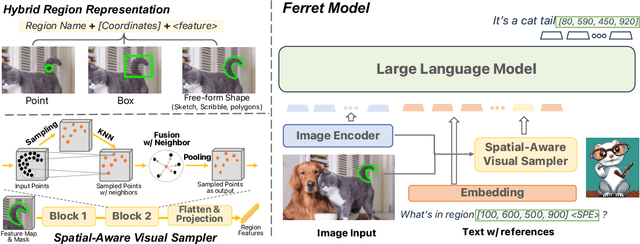
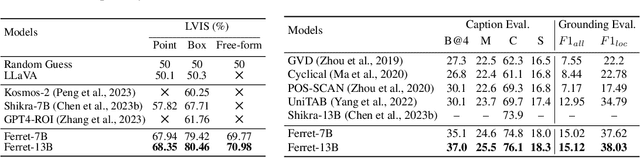
We introduce Ferret, a new Multimodal Large Language Model (MLLM) capable of understanding spatial referring of any shape or granularity within an image and accurately grounding open-vocabulary descriptions. To unify referring and grounding in the LLM paradigm, Ferret employs a novel and powerful hybrid region representation that integrates discrete coordinates and continuous features jointly to represent a region in the image. To extract the continuous features of versatile regions, we propose a spatial-aware visual sampler, adept at handling varying sparsity across different shapes. Consequently, Ferret can accept diverse region inputs, such as points, bounding boxes, and free-form shapes. To bolster the desired capability of Ferret, we curate GRIT, a comprehensive refer-and-ground instruction tuning dataset including 1.1M samples that contain rich hierarchical spatial knowledge, with 95K hard negative data to promote model robustness. The resulting model not only achieves superior performance in classical referring and grounding tasks, but also greatly outperforms existing MLLMs in region-based and localization-demanded multimodal chatting. Our evaluations also reveal a significantly improved capability of describing image details and a remarkable alleviation in object hallucination. Code and data will be available at https://github.com/apple/ml-ferret
Attribute Localization and Revision Network for Zero-Shot Learning
Oct 11, 2023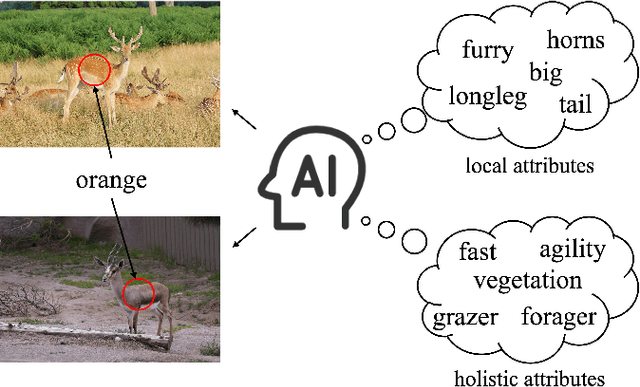
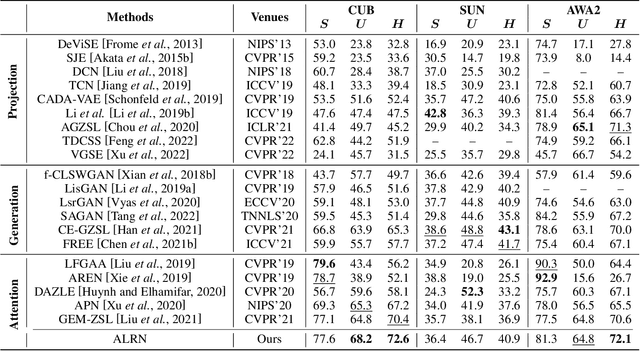
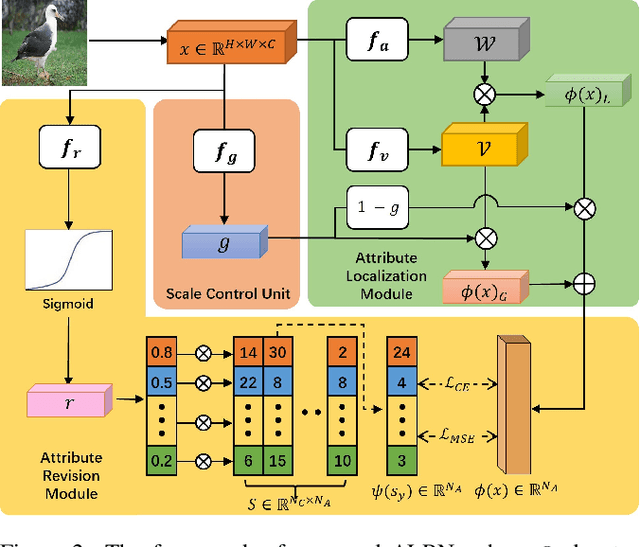
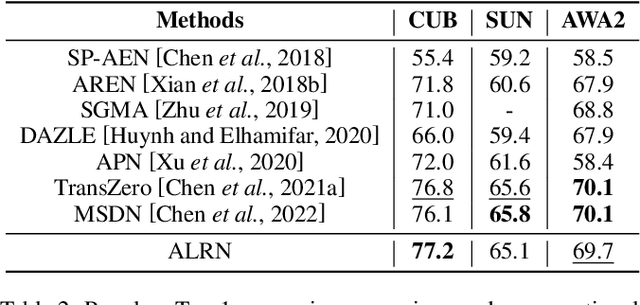
Zero-shot learning enables the model to recognize unseen categories with the aid of auxiliary semantic information such as attributes. Current works proposed to detect attributes from local image regions and align extracted features with class-level semantics. In this paper, we find that the choice between local and global features is not a zero-sum game, global features can also contribute to the understanding of attributes. In addition, aligning attribute features with class-level semantics ignores potential intra-class attribute variation. To mitigate these disadvantages, we present Attribute Localization and Revision Network in this paper. First, we design Attribute Localization Module (ALM) to capture both local and global features from image regions, a novel module called Scale Control Unit is incorporated to fuse global and local representations. Second, we propose Attribute Revision Module (ARM), which generates image-level semantics by revising the ground-truth value of each attribute, compensating for performance degradation caused by ignoring intra-class variation. Finally, the output of ALM will be aligned with revised semantics produced by ARM to achieve the training process. Comprehensive experimental results on three widely used benchmarks demonstrate the effectiveness of our model in the zero-shot prediction task.
Universal Domain Adaptation for Robust Handling of Distributional Shifts in NLP
Oct 23, 2023When deploying machine learning systems to the wild, it is highly desirable for them to effectively leverage prior knowledge to the unfamiliar domain while also firing alarms to anomalous inputs. In order to address these requirements, Universal Domain Adaptation (UniDA) has emerged as a novel research area in computer vision, focusing on achieving both adaptation ability and robustness (i.e., the ability to detect out-of-distribution samples). While UniDA has led significant progress in computer vision, its application on language input still needs to be explored despite its feasibility. In this paper, we propose a comprehensive benchmark for natural language that offers thorough viewpoints of the model's generalizability and robustness. Our benchmark encompasses multiple datasets with varying difficulty levels and characteristics, including temporal shifts and diverse domains. On top of our testbed, we validate existing UniDA methods from computer vision and state-of-the-art domain adaptation techniques from NLP literature, yielding valuable findings: We observe that UniDA methods originally designed for image input can be effectively transferred to the natural language domain while also underscoring the effect of adaptation difficulty in determining the model's performance.
Delayed Memory Unit: Modelling Temporal Dependency Through Delay Gate
Oct 23, 2023Recurrent Neural Networks (RNNs) are renowned for their adeptness in modeling temporal dependencies, a trait that has driven their widespread adoption for sequential data processing. Nevertheless, vanilla RNNs are confronted with the well-known issue of gradient vanishing and exploding, posing a significant challenge for learning and establishing long-range dependencies. Additionally, gated RNNs tend to be over-parameterized, resulting in poor network generalization. To address these challenges, we propose a novel Delayed Memory Unit (DMU) in this paper, wherein a delay line structure, coupled with delay gates, is introduced to facilitate temporal interaction and temporal credit assignment, so as to enhance the temporal modeling capabilities of vanilla RNNs. Particularly, the DMU is designed to directly distribute the input information to the optimal time instant in the future, rather than aggregating and redistributing it over time through intricate network dynamics. Our proposed DMU demonstrates superior temporal modeling capabilities across a broad range of sequential modeling tasks, utilizing considerably fewer parameters than other state-of-the-art gated RNN models in applications such as speech recognition, radar gesture recognition, ECG waveform segmentation, and permuted sequential image classification.
Player Re-Identification Using Body Part Appearences
Oct 23, 2023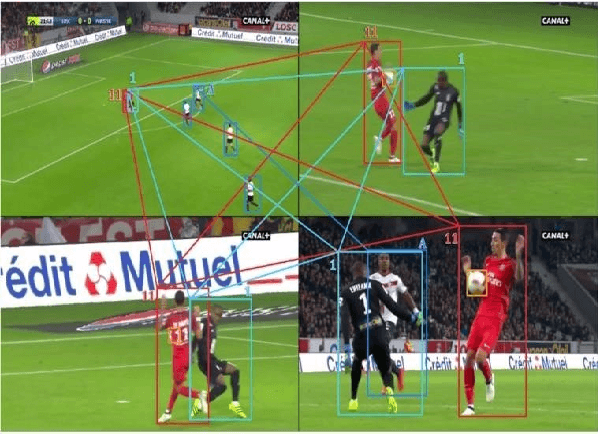
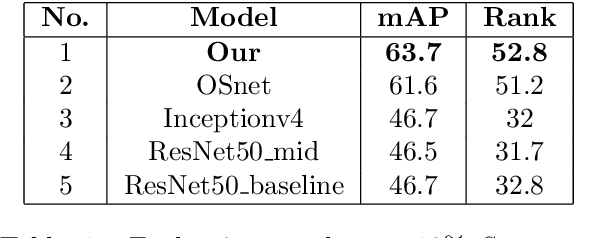
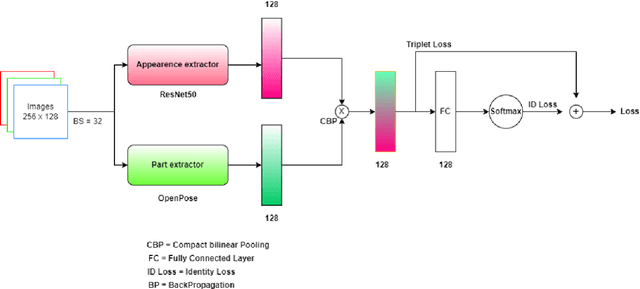
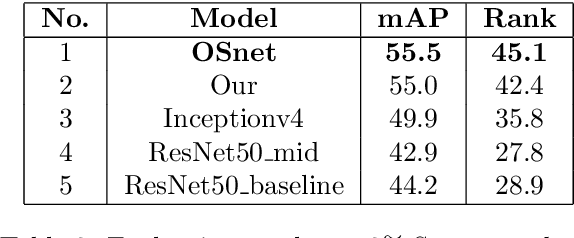
We propose a neural network architecture that learns body part appearances for soccer player re-identification. Our model consists of a two-stream network (one stream for appearance map extraction and the other for body part map extraction) and a bilinear-pooling layer that generates and spatially pools the body part map. Each local feature of the body part map is obtained by a bilinear mapping of the corresponding local appearance and body part descriptors. Our novel representation yields a robust image-matching feature map, which results from combining the local similarities of the relevant body parts with the weighted appearance similarity. Our model does not require any part annotation on the SoccerNet-V3 re-identification dataset to train the network. Instead, we use a sub-network of an existing pose estimation network (OpenPose) to initialize the part substream and then train the entire network to minimize the triplet loss. The appearance stream is pre-trained on the ImageNet dataset, and the part stream is trained from scratch for the SoccerNet-V3 dataset. We demonstrate the validity of our model by showing that it outperforms state-of-the-art models such as OsNet and InceptionNet.
DiffuGen: Adaptable Approach for Generating Labeled Image Datasets using Stable Diffusion Models
Sep 01, 2023
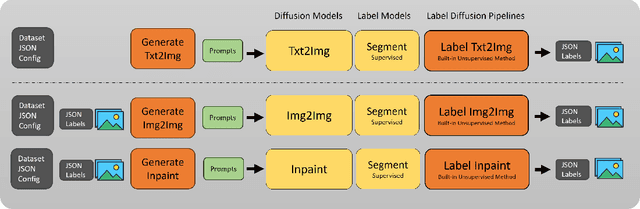


Generating high-quality labeled image datasets is crucial for training accurate and robust machine learning models in the field of computer vision. However, the process of manually labeling real images is often time-consuming and costly. To address these challenges associated with dataset generation, we introduce "DiffuGen," a simple and adaptable approach that harnesses the power of stable diffusion models to create labeled image datasets efficiently. By leveraging stable diffusion models, our approach not only ensures the quality of generated datasets but also provides a versatile solution for label generation. In this paper, we present the methodology behind DiffuGen, which combines the capabilities of diffusion models with two distinct labeling techniques: unsupervised and supervised. Distinctively, DiffuGen employs prompt templating for adaptable image generation and textual inversion to enhance diffusion model capabilities.