 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Technical Report for ICCV 2023 Visual Continual Learning Challenge: Continuous Test-time Adaptation for Semantic Segmentation
Oct 20, 2023
The goal of the challenge is to develop a test-time adaptation (TTA) method, which could adapt the model to gradually changing domains in video sequences for semantic segmentation task. It is based on a synthetic driving video dataset - SHIFT. The source model is trained on images taken during daytime in clear weather. Domain changes at test-time are mainly caused by varying weather conditions and times of day. The TTA methods are evaluated in each image sequence (video) separately, meaning the model is reset to the source model state before the next sequence. Images come one by one and a prediction has to be made at the arrival of each frame. Each sequence is composed of 401 images and starts with the source domain, then gradually drifts to a different one (changing weather or time of day) until the middle of the sequence. In the second half of the sequence, the domain gradually shifts back to the source one. Ground truth data is available only for the validation split of the SHIFT dataset, in which there are only six sequences that start and end with the source domain. We conduct an analysis specifically on those sequences. Ground truth data for test split, on which the developed TTA methods are evaluated for leader board ranking, are not publicly available. The proposed solution secured a 3rd place in a challenge and received an innovation award. Contrary to the solutions that scored better, we did not use any external pretrained models or specialized data augmentations, to keep the solutions as general as possible. We have focused on analyzing the distributional shift and developing a method that could adapt to changing data dynamics and generalize across different scenarios.
Diffusion Models for Image Restoration and Enhancement -- A Comprehensive Survey
Aug 18, 2023
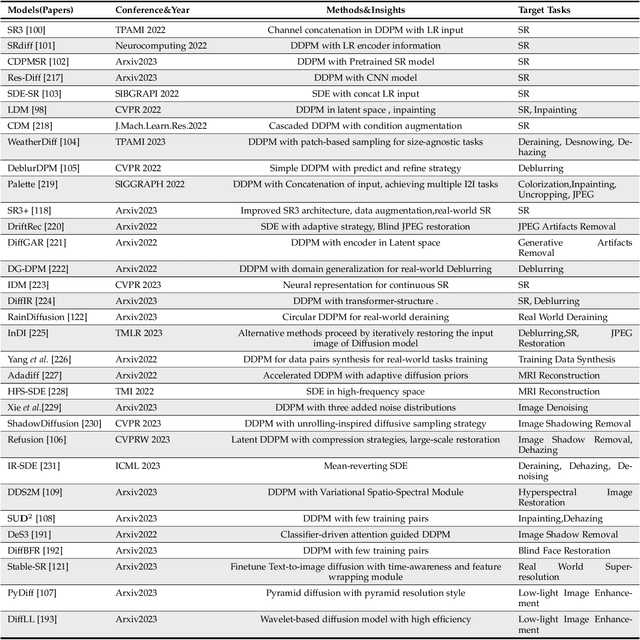
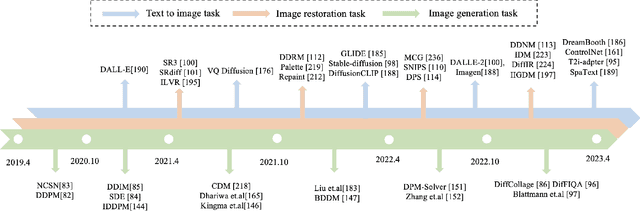
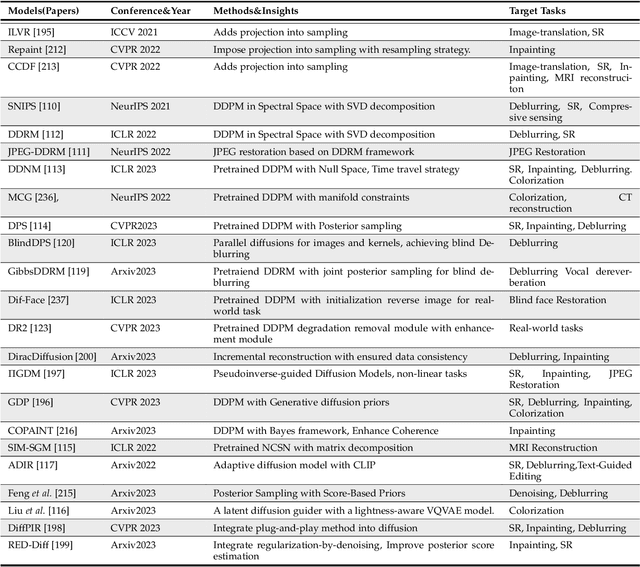
Image restoration (IR) has been an indispensable and challenging task in the low-level vision field, which strives to improve the subjective quality of images distorted by various forms of degradation. Recently, the diffusion model has achieved significant advancements in the visual generation of AIGC, thereby raising an intuitive question, "whether diffusion model can boost image restoration". To answer this, some pioneering studies attempt to integrate diffusion models into the image restoration task, resulting in superior performances than previous GAN-based methods. Despite that, a comprehensive and enlightening survey on diffusion model-based image restoration remains scarce. In this paper, we are the first to present a comprehensive review of recent diffusion model-based methods on image restoration, encompassing the learning paradigm, conditional strategy, framework design, modeling strategy, and evaluation. Concretely, we first introduce the background of the diffusion model briefly and then present two prevalent workflows that exploit diffusion models in image restoration. Subsequently, we classify and emphasize the innovative designs using diffusion models for both IR and blind/real-world IR, intending to inspire future development. To evaluate existing methods thoroughly, we summarize the commonly-used dataset, implementation details, and evaluation metrics. Additionally, we present the objective comparison for open-sourced methods across three tasks, including image super-resolution, deblurring, and inpainting. Ultimately, informed by the limitations in existing works, we propose five potential and challenging directions for the future research of diffusion model-based IR, including sampling efficiency, model compression, distortion simulation and estimation, distortion invariant learning, and framework design.
Learning Lens Blur Fields
Oct 17, 2023
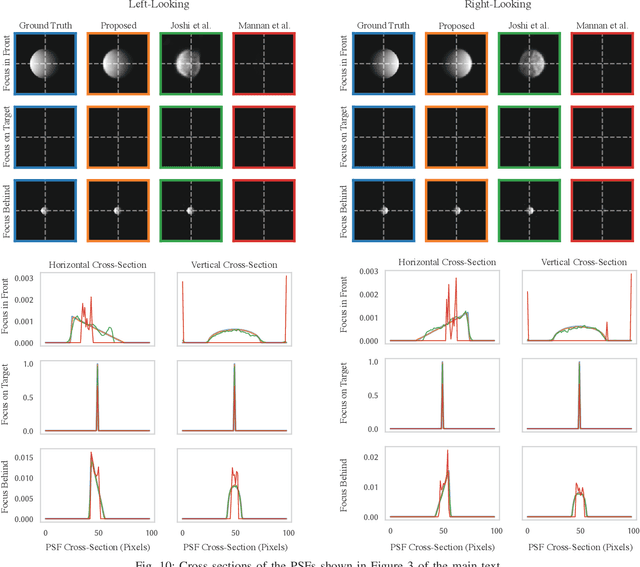


Optical blur is an inherent property of any lens system and is challenging to model in modern cameras because of their complex optical elements. To tackle this challenge, we introduce a high-dimensional neural representation of blur$-$$\textit{the lens blur field}$$-$and a practical method for acquiring it. The lens blur field is a multilayer perceptron (MLP) designed to (1) accurately capture variations of the lens 2D point spread function over image plane location, focus setting and, optionally, depth and (2) represent these variations parametrically as a single, sensor-specific function. The representation models the combined effects of defocus, diffraction, aberration, and accounts for sensor features such as pixel color filters and pixel-specific micro-lenses. To learn the real-world blur field of a given device, we formulate a generalized non-blind deconvolution problem that directly optimizes the MLP weights using a small set of focal stacks as the only input. We also provide a first-of-its-kind dataset of 5D blur fields$-$for smartphone cameras, camera bodies equipped with a variety of lenses, etc. Lastly, we show that acquired 5D blur fields are expressive and accurate enough to reveal, for the first time, differences in optical behavior of smartphone devices of the same make and model.
Balance Act: Mitigating Hubness in Cross-Modal Retrieval with Query and Gallery Banks
Oct 17, 2023In this work, we present a post-processing solution to address the hubness problem in cross-modal retrieval, a phenomenon where a small number of gallery data points are frequently retrieved, resulting in a decline in retrieval performance. We first theoretically demonstrate the necessity of incorporating both the gallery and query data for addressing hubness as hubs always exhibit high similarity with gallery and query data. Second, building on our theoretical results, we propose a novel framework, Dual Bank Normalization (DBNorm). While previous work has attempted to alleviate hubness by only utilizing the query samples, DBNorm leverages two banks constructed from the query and gallery samples to reduce the occurrence of hubs during inference. Next, to complement DBNorm, we introduce two novel methods, dual inverted softmax and dual dynamic inverted softmax, for normalizing similarity based on the two banks. Specifically, our proposed methods reduce the similarity between hubs and queries while improving the similarity between non-hubs and queries. Finally, we present extensive experimental results on diverse language-grounded benchmarks, including text-image, text-video, and text-audio, demonstrating the superior performance of our approaches compared to previous methods in addressing hubness and boosting retrieval performance. Our code is available at https://github.com/yimuwangcs/Better_Cross_Modal_Retrieval.
Super resolution of histopathological frozen sections via deep learning preserving tissue structure
Oct 17, 2023Histopathology plays a pivotal role in medical diagnostics. In contrast to preparing permanent sections for histopathology, a time-consuming process, preparing frozen sections is significantly faster and can be performed during surgery, where the sample scanning time should be optimized. Super-resolution techniques allow imaging the sample in lower magnification and sparing scanning time. In this paper, we present a new approach to super resolution for histopathological frozen sections, with focus on achieving better distortion measures, rather than pursuing photorealistic images that may compromise critical diagnostic information. Our deep-learning architecture focuses on learning the error between interpolated images and real images, thereby it generates high-resolution images while preserving critical image details, reducing the risk of diagnostic misinterpretation. This is done by leveraging the loss functions in the frequency domain, assigning higher weights to the reconstruction of complex, high-frequency components. In comparison to existing methods, we obtained significant improvements in terms of Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR), as well as indicated details that lost in the low-resolution frozen-section images, affecting the pathologist's clinical decisions. Our approach has a great potential in providing more-rapid frozen-section imaging, with less scanning, while preserving the high resolution in the imaged sample.
Elucidating The Design Space of Classifier-Guided Diffusion Generation
Oct 17, 2023Guidance in conditional diffusion generation is of great importance for sample quality and controllability. However, existing guidance schemes are to be desired. On one hand, mainstream methods such as classifier guidance and classifier-free guidance both require extra training with labeled data, which is time-consuming and unable to adapt to new conditions. On the other hand, training-free methods such as universal guidance, though more flexible, have yet to demonstrate comparable performance. In this work, through a comprehensive investigation into the design space, we show that it is possible to achieve significant performance improvements over existing guidance schemes by leveraging off-the-shelf classifiers in a training-free fashion, enjoying the best of both worlds. Employing calibration as a general guideline, we propose several pre-conditioning techniques to better exploit pretrained off-the-shelf classifiers for guiding diffusion generation. Extensive experiments on ImageNet validate our proposed method, showing that state-of-the-art diffusion models (DDPM, EDM, DiT) can be further improved (up to 20%) using off-the-shelf classifiers with barely any extra computational cost. With the proliferation of publicly available pretrained classifiers, our proposed approach has great potential and can be readily scaled up to text-to-image generation tasks. The code is available at https://github.com/AlexMaOLS/EluCD/tree/main.
Collaborative Camouflaged Object Detection: A Large-Scale Dataset and Benchmark
Oct 06, 2023
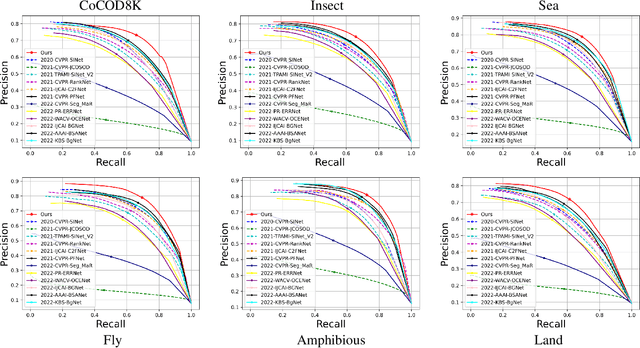

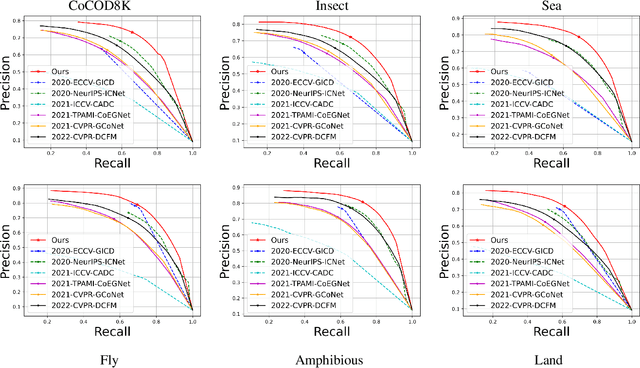
In this paper, we provide a comprehensive study on a new task called collaborative camouflaged object detection (CoCOD), which aims to simultaneously detect camouflaged objects with the same properties from a group of relevant images. To this end, we meticulously construct the first large-scale dataset, termed CoCOD8K, which consists of 8,528 high-quality and elaborately selected images with object mask annotations, covering 5 superclasses and 70 subclasses. The dataset spans a wide range of natural and artificial camouflage scenes with diverse object appearances and backgrounds, making it a very challenging dataset for CoCOD. Besides, we propose the first baseline model for CoCOD, named bilateral-branch network (BBNet), which explores and aggregates co-camouflaged cues within a single image and between images within a group, respectively, for accurate camouflaged object detection in given images. This is implemented by an inter-image collaborative feature exploration (CFE) module, an intra-image object feature search (OFS) module, and a local-global refinement (LGR) module. We benchmark 18 state-of-the-art models, including 12 COD algorithms and 6 CoSOD algorithms, on the proposed CoCOD8K dataset under 5 widely used evaluation metrics. Extensive experiments demonstrate the effectiveness of the proposed method and the significantly superior performance compared to other competitors. We hope that our proposed dataset and model will boost growth in the COD community. The dataset, model, and results will be available at: https://github.com/zc199823/BBNet--CoCOD.
TSI-Net: A Timing Sequence Image Segmentation Network for Intracranial Artery Segmentation in Digital Subtraction Angiography
Sep 07, 2023Cerebrovascular disease is one of the major diseases facing the world today. Automatic segmentation of intracranial artery (IA) in digital subtraction angiography (DSA) sequences is an important step in the diagnosis of vascular related diseases and in guiding neurointerventional procedures. While, a single image can only show part of the IA within the contrast medium according to the imaging principle of DSA technology. Therefore, 2D DSA segmentation methods are unable to capture the complete IA information and treatment of cerebrovascular diseases. We propose A timing sequence image segmentation network with U-shape, called TSI-Net, which incorporates a bi-directional ConvGRU module (BCM) in the encoder. The network incorporates a bi-directional ConvGRU module (BCM) in the encoder, which can input variable-length DSA sequences, retain past and future information, segment them into 2D images. In addition, we introduce a sensitive detail branch (SDB) at the end for supervising fine vessels. Experimented on the DSA sequence dataset DIAS, the method performs significantly better than state-of-the-art networks in recent years. In particular, it achieves a Sen evaluation metric of 0.797, which is a 3% improvement compared to other methods.
Does resistance to Style-Transfer equal Shape Bias? Evaluating Shape Bias by Distorted Shape
Oct 11, 2023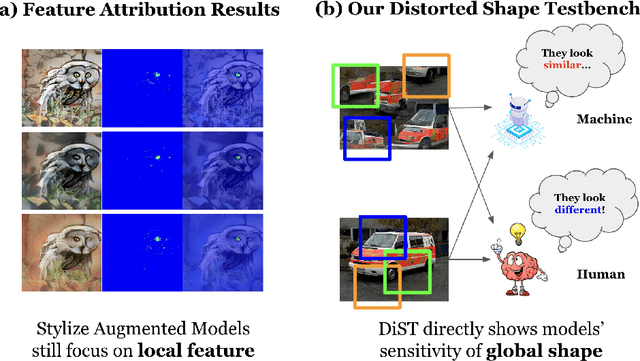
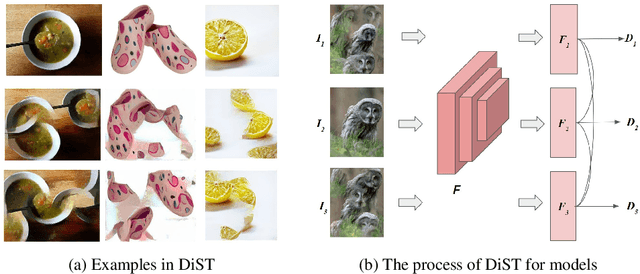
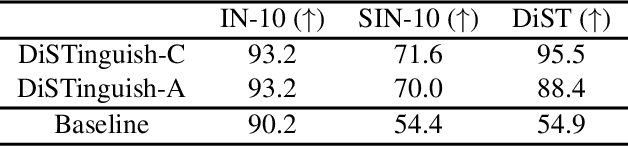
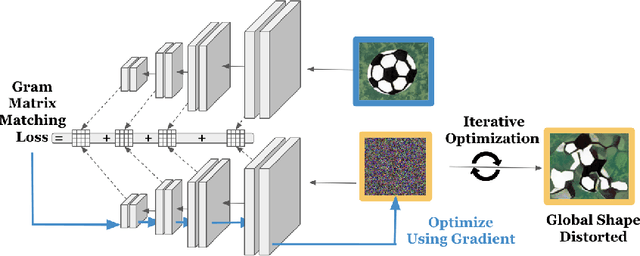
Deep learning models are known to exhibit a strong texture bias, while human tends to rely heavily on global shape for object recognition. The current benchmark for evaluating a model's shape bias is a set of style-transferred images with the assumption that resistance to the attack of style transfer is related to the development of shape sensitivity in the model. In this work, we show that networks trained with style-transfer images indeed learn to ignore style, but its shape bias arises primarily from local shapes. We provide a Distorted Shape Testbench (DiST) as an alternative measurement of global shape sensitivity. Our test includes 2400 original images from ImageNet-1K, each of which is accompanied by two images with the global shapes of the original image distorted while preserving its texture via the texture synthesis program. We found that (1) models that performed well on the previous shape bias evaluation do not fare well in the proposed DiST; (2) the widely adopted ViT models do not show significant advantages over Convolutional Neural Networks (CNNs) on this benchmark despite that ViTs rank higher on the previous shape bias tests. (3) training with DiST images bridges the significant gap between human and existing SOTA models' performance while preserving the models' accuracy on standard image classification tasks; training with DiST images and style-transferred images are complementary, and can be combined to train network together to enhance both the global and local shape sensitivity of the network. Our code will be host at: https://github.com/leelabcnbc/DiST
rpcPRF: Generalizable MPI Neural Radiance Field for Satellite Camera
Oct 11, 2023Novel view synthesis of satellite images holds a wide range of practical applications. While recent advances in the Neural Radiance Field have predominantly targeted pin-hole cameras, and models for satellite cameras often demand sufficient input views. This paper presents rpcPRF, a Multiplane Images (MPI) based Planar neural Radiance Field for Rational Polynomial Camera (RPC). Unlike coordinate-based neural radiance fields in need of sufficient views of one scene, our model is applicable to single or few inputs and performs well on images from unseen scenes. To enable generalization across scenes, we propose to use reprojection supervision to induce the predicted MPI to learn the correct geometry between the 3D coordinates and the images. Moreover, we remove the stringent requirement of dense depth supervision from deep multiview-stereo-based methods by introducing rendering techniques of radiance fields. rpcPRF combines the superiority of implicit representations and the advantages of the RPC model, to capture the continuous altitude space while learning the 3D structure. Given an RGB image and its corresponding RPC, the end-to-end model learns to synthesize the novel view with a new RPC and reconstruct the altitude of the scene. When multiple views are provided as inputs, rpcPRF exerts extra supervision provided by the extra views. On the TLC dataset from ZY-3, and the SatMVS3D dataset with urban scenes from WV-3, rpcPRF outperforms state-of-the-art nerf-based methods by a significant margin in terms of image fidelity, reconstruction accuracy, and efficiency, for both single-view and multiview task.