 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Top-K Pooling with Patch Contrastive Learning for Weakly-Supervised Semantic Segmentation
Oct 15, 2023
Weakly Supervised Semantic Segmentation (WSSS) using only image-level labels has gained significant attention due to cost-effectiveness. Recently, Vision Transformer (ViT) based methods without class activation map (CAM) have shown greater capability in generating reliable pseudo labels than previous methods using CAM. However, the current ViT-based methods utilize max pooling to select the patch with the highest prediction score to map the patch-level classification to the image-level one, which may affect the quality of pseudo labels due to the inaccurate classification of the patches. In this paper, we introduce a novel ViT-based WSSS method named top-K pooling with patch contrastive learning (TKP-PCL), which employs a top-K pooling layer to alleviate the limitations of previous max pooling selection. A patch contrastive error (PCE) is also proposed to enhance the patch embeddings to further improve the final results. The experimental results show that our approach is very efficient and outperforms other state-of-the-art WSSS methods on the PASCAL VOC 2012 dataset.
Relay Diffusion: Unifying diffusion process across resolutions for image synthesis
Sep 04, 2023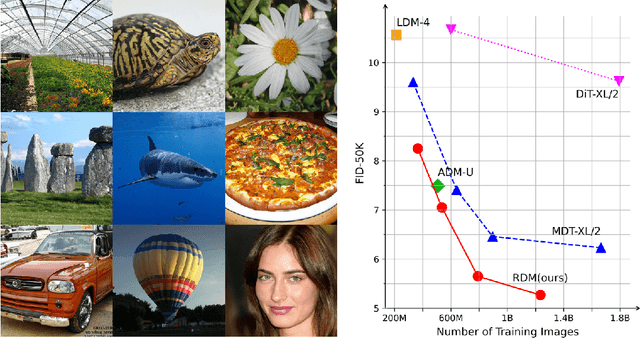
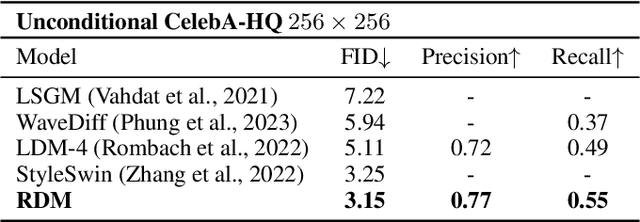
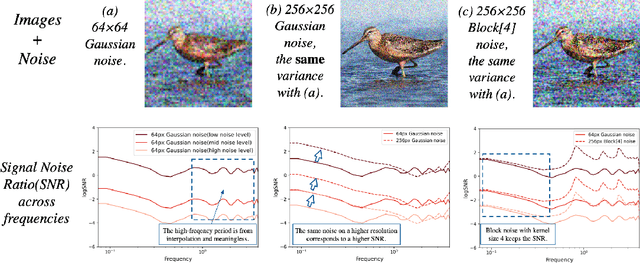
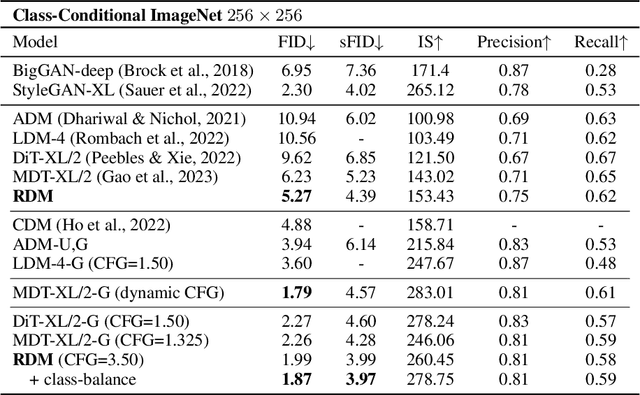
Diffusion models achieved great success in image synthesis, but still face challenges in high-resolution generation. Through the lens of discrete cosine transformation, we find the main reason is that \emph{the same noise level on a higher resolution results in a higher Signal-to-Noise Ratio in the frequency domain}. In this work, we present Relay Diffusion Model (RDM), which transfers a low-resolution image or noise into an equivalent high-resolution one for diffusion model via blurring diffusion and block noise. Therefore, the diffusion process can continue seamlessly in any new resolution or model without restarting from pure noise or low-resolution conditioning. RDM achieves state-of-the-art FID on CelebA-HQ and sFID on ImageNet 256$\times$256, surpassing previous works such as ADM, LDM and DiT by a large margin. All the codes and checkpoints are open-sourced at \url{https://github.com/THUDM/RelayDiffusion}.
Sliceformer: Make Multi-head Attention as Simple as Sorting in Discriminative Tasks
Oct 26, 2023
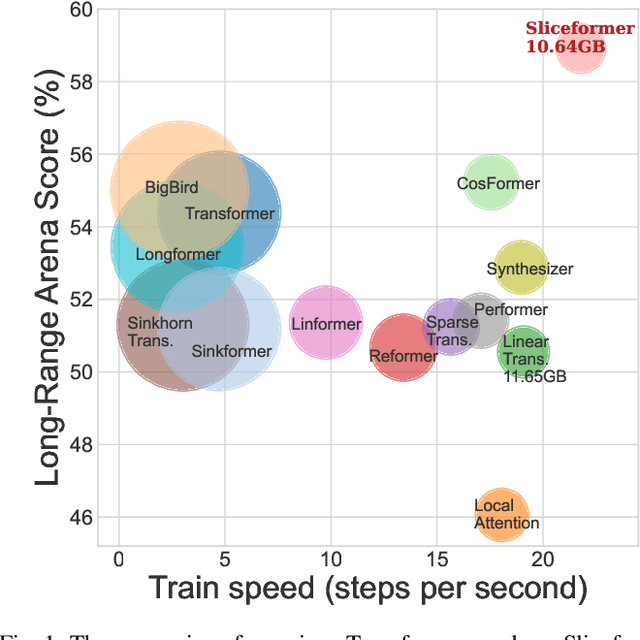
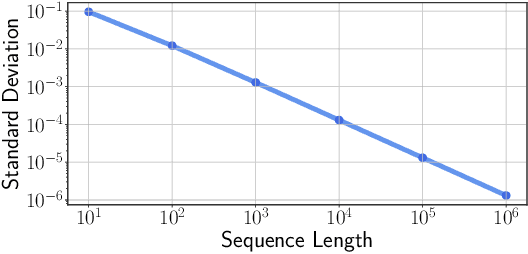
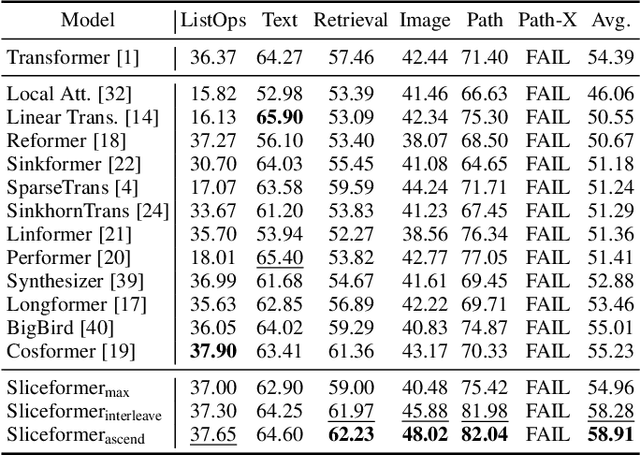
As one of the most popular neural network modules, Transformer plays a central role in many fundamental deep learning models, e.g., the ViT in computer vision and the BERT and GPT in natural language processing. The effectiveness of the Transformer is often attributed to its multi-head attention (MHA) mechanism. In this study, we discuss the limitations of MHA, including the high computational complexity due to its ``query-key-value'' architecture and the numerical issue caused by its softmax operation. Considering the above problems and the recent development tendency of the attention layer, we propose an effective and efficient surrogate of the Transformer, called Sliceformer. Our Sliceformer replaces the classic MHA mechanism with an extremely simple ``slicing-sorting'' operation, i.e., projecting inputs linearly to a latent space and sorting them along different feature dimensions (or equivalently, called channels). For each feature dimension, the sorting operation implicitly generates an implicit attention map with sparse, full-rank, and doubly-stochastic structures. We consider different implementations of the slicing-sorting operation and analyze their impacts on the Sliceformer. We test the Sliceformer in the Long-Range Arena benchmark, image classification, text classification, and molecular property prediction, demonstrating its advantage in computational complexity and universal effectiveness in discriminative tasks. Our Sliceformer achieves comparable or better performance with lower memory cost and faster speed than the Transformer and its variants. Moreover, the experimental results reveal that applying our Sliceformer can empirically suppress the risk of mode collapse when representing data. The code is available at \url{https://github.com/SDS-Lab/sliceformer}.
CausalImages: An R Package for Causal Inference with Earth Observation, Bio-medical, and Social Science Images
Oct 03, 2023The causalimages R package enables causal inference with image and image sequence data, providing new tools for integrating novel data sources like satellite and bio-medical imagery into the study of cause and effect. One set of functions enables image-based causal inference analyses. For example, one key function decomposes treatment effect heterogeneity by images using an interpretable Bayesian framework. This allows for determining which types of images or image sequences are most responsive to interventions. A second modeling function allows researchers to control for confounding using images. The package also allows investigators to produce embeddings that serve as vector summaries of the image or video content. Finally, infrastructural functions are also provided, such as tools for writing large-scale image and image sequence data as sequentialized byte strings for more rapid image analysis. causalimages therefore opens new capabilities for causal inference in R, letting researchers use informative imagery in substantive analyses in a fast and accessible manner.
Exploring Driving Behavior for Autonomous Vehicles Based on Gramian Angular Field Vision Transformer
Oct 21, 2023Effective classification of autonomous vehicle (AV) driving behavior emerges as a critical area for diagnosing AV operation faults, enhancing autonomous driving algorithms, and reducing accident rates. This paper presents the Gramian Angular Field Vision Transformer (GAF-ViT) model, designed to analyze AV driving behavior. The proposed GAF-ViT model consists of three key components: GAF Transformer Module, Channel Attention Module, and Multi-Channel ViT Module. These modules collectively convert representative sequences of multivariate behavior into multi-channel images and employ image recognition techniques for behavior classification. A channel attention mechanism is applied to multi-channel images to discern the impact of various driving behavior features. Experimental evaluation on the Waymo Open Dataset of trajectories demonstrates that the proposed model achieves state-of-the-art performance. Furthermore, an ablation study effectively substantiates the efficacy of individual modules within the model.
AMLP:Adaptive Masking Lesion Patches for Self-supervised Medical Image Segmentation
Sep 08, 2023Self-supervised masked image modeling has shown promising results on natural images. However, directly applying such methods to medical images remains challenging. This difficulty stems from the complexity and distinct characteristics of lesions compared to natural images, which impedes effective representation learning. Additionally, conventional high fixed masking ratios restrict reconstructing fine lesion details, limiting the scope of learnable information. To tackle these limitations, we propose a novel self-supervised medical image segmentation framework, Adaptive Masking Lesion Patches (AMLP). Specifically, we design a Masked Patch Selection (MPS) strategy to identify and focus learning on patches containing lesions. Lesion regions are scarce yet critical, making their precise reconstruction vital. To reduce misclassification of lesion and background patches caused by unsupervised clustering in MPS, we introduce an Attention Reconstruction Loss (ARL) to focus on hard-to-reconstruct patches likely depicting lesions. We further propose a Category Consistency Loss (CCL) to refine patch categorization based on reconstruction difficulty, strengthening distinction between lesions and background. Moreover, we develop an Adaptive Masking Ratio (AMR) strategy that gradually increases the masking ratio to expand reconstructible information and improve learning. Extensive experiments on two medical segmentation datasets demonstrate AMLP's superior performance compared to existing self-supervised approaches. The proposed strategies effectively address limitations in applying masked modeling to medical images, tailored to capturing fine lesion details vital for segmentation tasks.
RenAIssance: A Survey into AI Text-to-Image Generation in the Era of Large Model
Sep 02, 2023Text-to-image generation (TTI) refers to the usage of models that could process text input and generate high fidelity images based on text descriptions. Text-to-image generation using neural networks could be traced back to the emergence of Generative Adversial Network (GAN), followed by the autoregressive Transformer. Diffusion models are one prominent type of generative model used for the generation of images through the systematic introduction of noises with repeating steps. As an effect of the impressive results of diffusion models on image synthesis, it has been cemented as the major image decoder used by text-to-image models and brought text-to-image generation to the forefront of machine-learning (ML) research. In the era of large models, scaling up model size and the integration with large language models have further improved the performance of TTI models, resulting the generation result nearly indistinguishable from real-world images, revolutionizing the way we retrieval images. Our explorative study has incentivised us to think that there are further ways of scaling text-to-image models with the combination of innovative model architectures and prediction enhancement techniques. We have divided the work of this survey into five main sections wherein we detail the frameworks of major literature in order to delve into the different types of text-to-image generation methods. Following this we provide a detailed comparison and critique of these methods and offer possible pathways of improvement for future work. In the future work, we argue that TTI development could yield impressive productivity improvements for creation, particularly in the context of the AIGC era, and could be extended to more complex tasks such as video generation and 3D generation.
CorrEmbed: Evaluating Pre-trained Model Image Similarity Efficacy with a Novel Metric
Aug 30, 2023
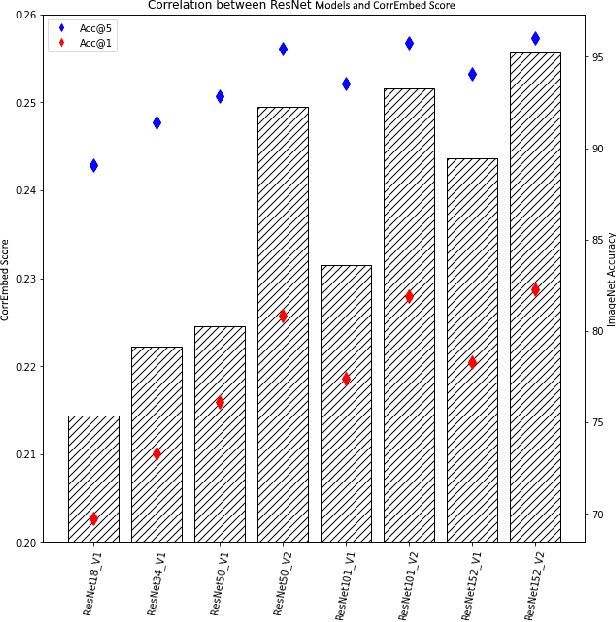
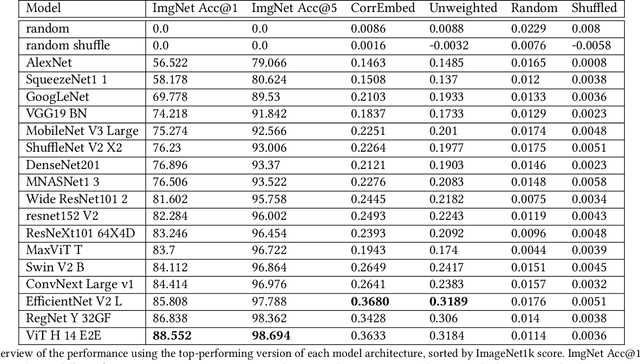
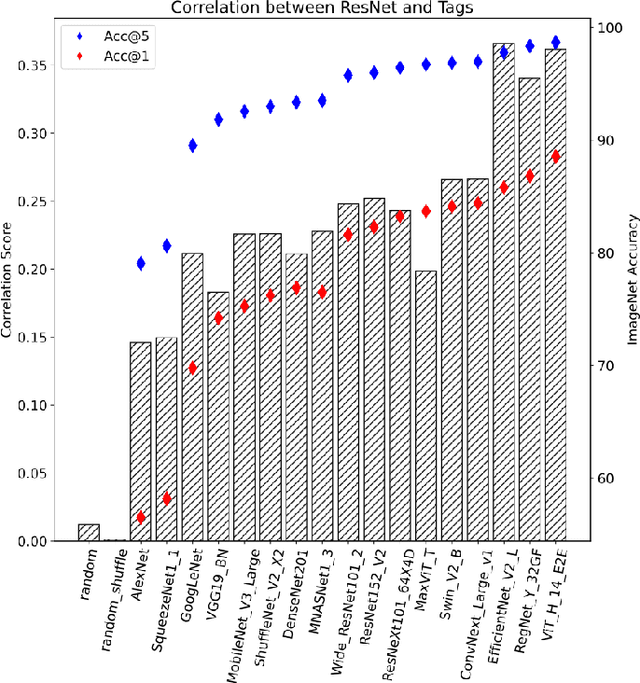
Detecting visually similar images is a particularly useful attribute to look to when calculating product recommendations. Embedding similarity, which utilizes pre-trained computer vision models to extract high-level image features, has demonstrated remarkable efficacy in identifying images with similar compositions. However, there is a lack of methods for evaluating the embeddings generated by these models, as conventional loss and performance metrics do not adequately capture their performance in image similarity search tasks. In this paper, we evaluate the viability of the image embeddings from numerous pre-trained computer vision models using a novel approach named CorrEmbed. Our approach computes the correlation between distances in image embeddings and distances in human-generated tag vectors. We extensively evaluate numerous pre-trained Torchvision models using this metric, revealing an intuitive relationship of linear scaling between ImageNet1k accuracy scores and tag-correlation scores. Importantly, our method also identifies deviations from this pattern, providing insights into how different models capture high-level image features. By offering a robust performance evaluation of these pre-trained models, CorrEmbed serves as a valuable tool for researchers and practitioners seeking to develop effective, data-driven approaches to similar item recommendations in fashion retail.
DLIP: Distilling Language-Image Pre-training
Aug 24, 2023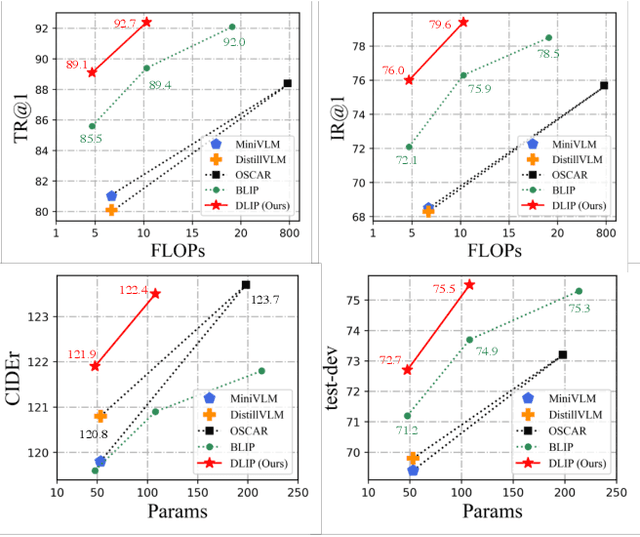
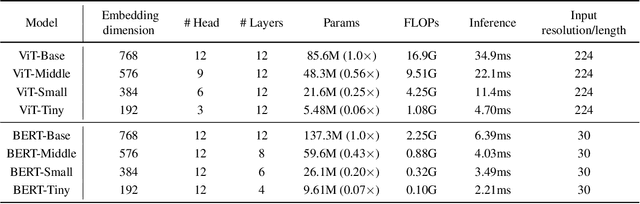
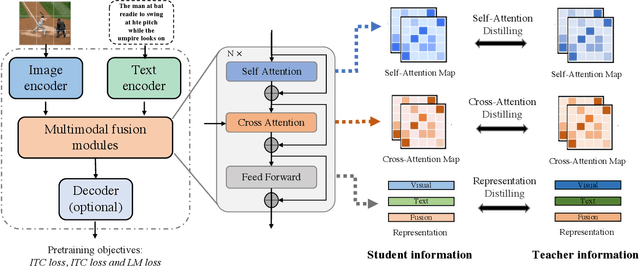
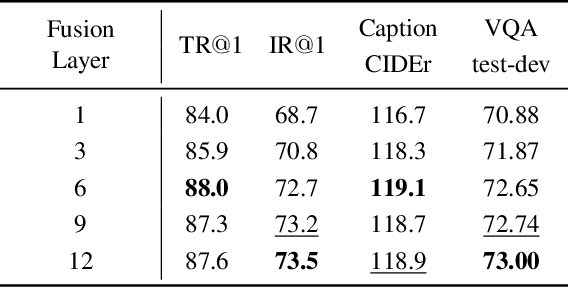
Vision-Language Pre-training (VLP) shows remarkable progress with the assistance of extremely heavy parameters, which challenges deployment in real applications. Knowledge distillation is well recognized as the essential procedure in model compression. However, existing knowledge distillation techniques lack an in-depth investigation and analysis of VLP, and practical guidelines for VLP-oriented distillation are still not yet explored. In this paper, we present DLIP, a simple yet efficient Distilling Language-Image Pre-training framework, through which we investigate how to distill a light VLP model. Specifically, we dissect the model distillation from multiple dimensions, such as the architecture characteristics of different modules and the information transfer of different modalities. We conduct comprehensive experiments and provide insights on distilling a light but performant VLP model. Experimental results reveal that DLIP can achieve a state-of-the-art accuracy/efficiency trade-off across diverse cross-modal tasks, e.g., image-text retrieval, image captioning and visual question answering. For example, DLIP compresses BLIP by 1.9x, from 213M to 108M parameters, while achieving comparable or better performance. Furthermore, DLIP succeeds in retaining more than 95% of the performance with 22.4% parameters and 24.8% FLOPs compared to the teacher model and accelerates inference speed by 2.7x.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
Oct 17, 2023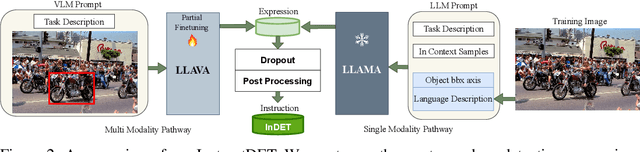

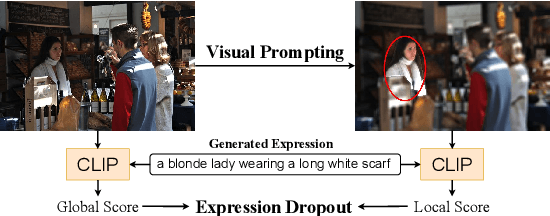
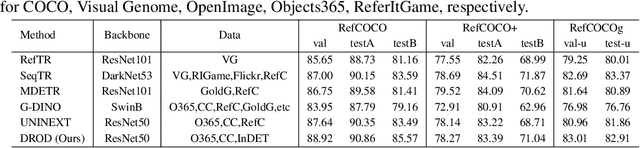
We propose InstructDET, a data-centric method for referring object detection (ROD) that localizes target objects based on user instructions. While deriving from referring expressions (REC), the instructions we leverage are greatly diversified to encompass common user intentions related to object detection. For one image, we produce tremendous instructions that refer to every single object and different combinations of multiple objects. Each instruction and its corresponding object bounding boxes (bbxs) constitute one training data pair. In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e.g., describing object property, category, and relationship). We name our constructed dataset as InDET. It contains images, bbxs and generalized instructions that are from foundation models. Our InDET is developed from existing REC datasets and object detection datasets, with the expanding potential that any image with object bbxs can be incorporated through using our InstructDET method. By using our InDET dataset, we show that a conventional ROD model surpasses existing methods on standard REC datasets and our InDET test set. Our data-centric method InstructDET, with automatic data expansion by leveraging foundation models, directs a promising field that ROD can be greatly diversified to execute common object detection instructions.