 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SegmATRon: Embodied Adaptive Semantic Segmentation for Indoor Environment
Oct 18, 2023
This paper presents an adaptive transformer model named SegmATRon for embodied image semantic segmentation. Its distinctive feature is the adaptation of model weights during inference on several images using a hybrid multicomponent loss function. We studied this model on datasets collected in the photorealistic Habitat and the synthetic AI2-THOR Simulators. We showed that obtaining additional images using the agent's actions in an indoor environment can improve the quality of semantic segmentation. The code of the proposed approach and datasets are publicly available at https://github.com/wingrune/SegmATRon.
Active Learning for Fine-Grained Sketch-Based Image Retrieval
Sep 15, 2023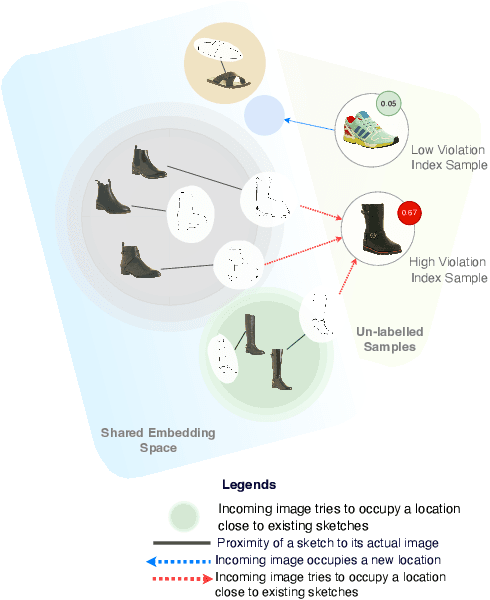
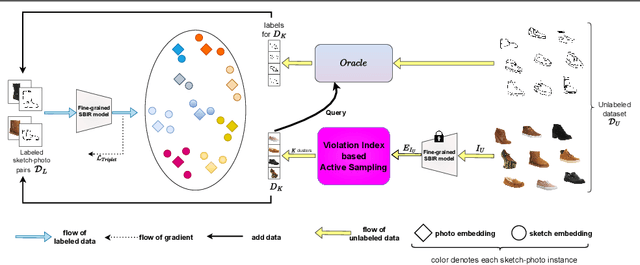
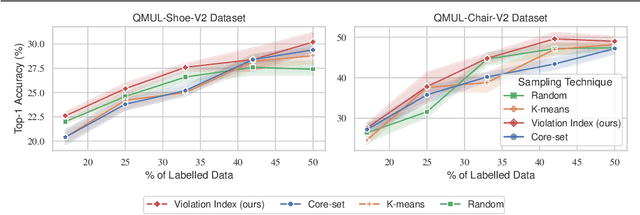
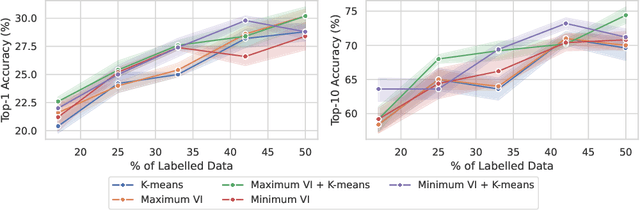
The ability to retrieve a photo by mere free-hand sketching highlights the immense potential of Fine-grained sketch-based image retrieval (FG-SBIR). However, its rapid practical adoption, as well as scalability, is limited by the expense of acquiring faithful sketches for easily available photo counterparts. A solution to this problem is Active Learning, which could minimise the need for labeled sketches while maximising performance. Despite extensive studies in the field, there exists no work that utilises it for reducing sketching effort in FG-SBIR tasks. To this end, we propose a novel active learning sampling technique that drastically minimises the need for drawing photo sketches. Our proposed approach tackles the trade-off between uncertainty and diversity by utilising the relationship between the existing photo-sketch pair to a photo that does not have its sketch and augmenting this relation with its intermediate representations. Since our approach relies only on the underlying data distribution, it is agnostic of the modelling approach and hence is applicable to other cross-modal instance-level retrieval tasks as well. With experimentation over two publicly available fine-grained SBIR datasets ChairV2 and ShoeV2, we validate our approach and reveal its superiority over adapted baselines.
Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned Data
Oct 10, 2023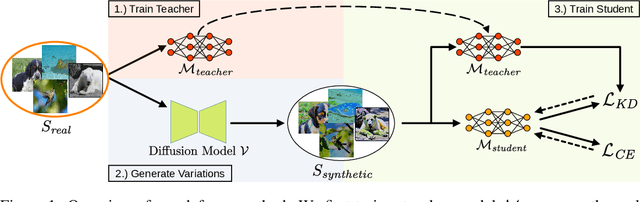
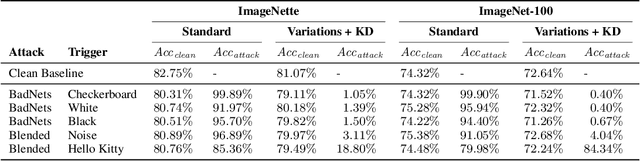

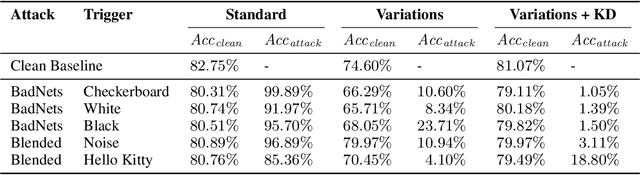
Backdoor attacks pose a serious security threat for training neural networks as they surreptitiously introduce hidden functionalities into a model. Such backdoors remain silent during inference on clean inputs, evading detection due to inconspicuous behavior. However, once a specific trigger pattern appears in the input data, the backdoor activates, causing the model to execute its concealed function. Detecting such poisoned samples within vast datasets is virtually impossible through manual inspection. To address this challenge, we propose a novel approach that enables model training on potentially poisoned datasets by utilizing the power of recent diffusion models. Specifically, we create synthetic variations of all training samples, leveraging the inherent resilience of diffusion models to potential trigger patterns in the data. By combining this generative approach with knowledge distillation, we produce student models that maintain their general performance on the task while exhibiting robust resistance to backdoor triggers.
Relay Diffusion: Unifying diffusion process across resolutions for image synthesis
Sep 04, 2023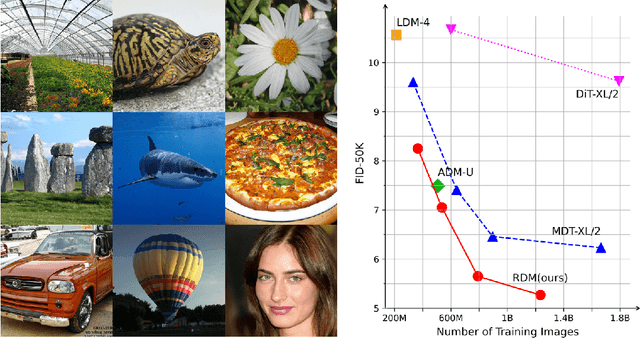
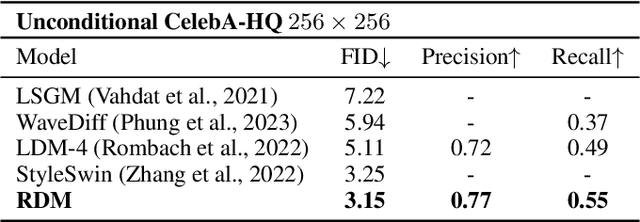
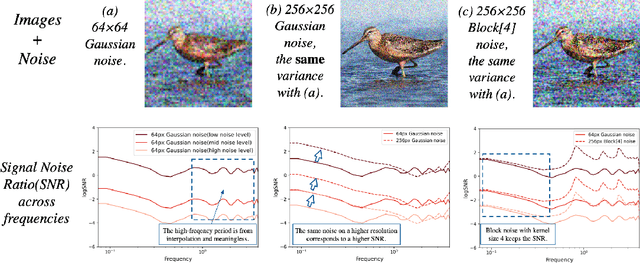
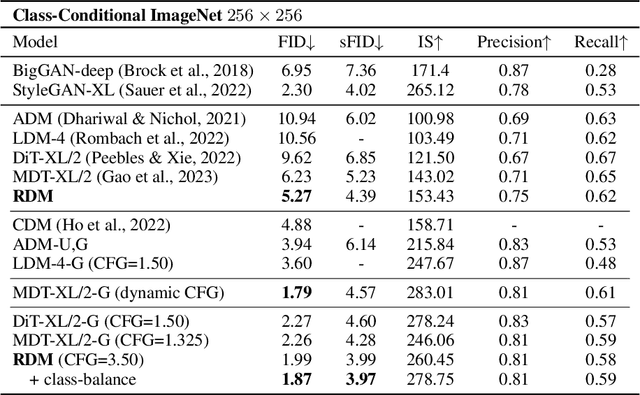
Diffusion models achieved great success in image synthesis, but still face challenges in high-resolution generation. Through the lens of discrete cosine transformation, we find the main reason is that \emph{the same noise level on a higher resolution results in a higher Signal-to-Noise Ratio in the frequency domain}. In this work, we present Relay Diffusion Model (RDM), which transfers a low-resolution image or noise into an equivalent high-resolution one for diffusion model via blurring diffusion and block noise. Therefore, the diffusion process can continue seamlessly in any new resolution or model without restarting from pure noise or low-resolution conditioning. RDM achieves state-of-the-art FID on CelebA-HQ and sFID on ImageNet 256$\times$256, surpassing previous works such as ADM, LDM and DiT by a large margin. All the codes and checkpoints are open-sourced at \url{https://github.com/THUDM/RelayDiffusion}.
DiPS: Discriminative Pseudo-Label Sampling with Self-Supervised Transformers for Weakly Supervised Object Localization
Oct 09, 2023Self-supervised vision transformers (SSTs) have shown great potential to yield rich localization maps that highlight different objects in an image. However, these maps remain class-agnostic since the model is unsupervised. They often tend to decompose the image into multiple maps containing different objects while being unable to distinguish the object of interest from background noise objects. In this paper, Discriminative Pseudo-label Sampling (DiPS) is introduced to leverage these class-agnostic maps for weakly-supervised object localization (WSOL), where only image-class labels are available. Given multiple attention maps, DiPS relies on a pre-trained classifier to identify the most discriminative regions of each attention map. This ensures that the selected ROIs cover the correct image object while discarding the background ones, and, as such, provides a rich pool of diverse and discriminative proposals to cover different parts of the object. Subsequently, these proposals are used as pseudo-labels to train our new transformer-based WSOL model designed to perform classification and localization tasks. Unlike standard WSOL methods, DiPS optimizes performance in both tasks by using a transformer encoder and a dedicated output head for each task, each trained using dedicated loss functions. To avoid overfitting a single proposal and promote better object coverage, a single proposal is randomly selected among the top ones for a training image at each training step. Experimental results on the challenging CUB, ILSVRC, OpenImages, and TelDrone datasets indicate that our architecture, in combination with our transformer-based proposals, can yield better localization performance than state-of-the-art methods.
PHD: Pixel-Based Language Modeling of Historical Documents
Oct 22, 2023The digitisation of historical documents has provided historians with unprecedented research opportunities. Yet, the conventional approach to analysing historical documents involves converting them from images to text using OCR, a process that overlooks the potential benefits of treating them as images and introduces high levels of noise. To bridge this gap, we take advantage of recent advancements in pixel-based language models trained to reconstruct masked patches of pixels instead of predicting token distributions. Due to the scarcity of real historical scans, we propose a novel method for generating synthetic scans to resemble real historical documents. We then pre-train our model, PHD, on a combination of synthetic scans and real historical newspapers from the 1700-1900 period. Through our experiments, we demonstrate that PHD exhibits high proficiency in reconstructing masked image patches and provide evidence of our model's noteworthy language understanding capabilities. Notably, we successfully apply our model to a historical QA task, highlighting its usefulness in this domain.
Conditional Generative Modeling for Images, 3D Animations, and Video
Oct 19, 2023
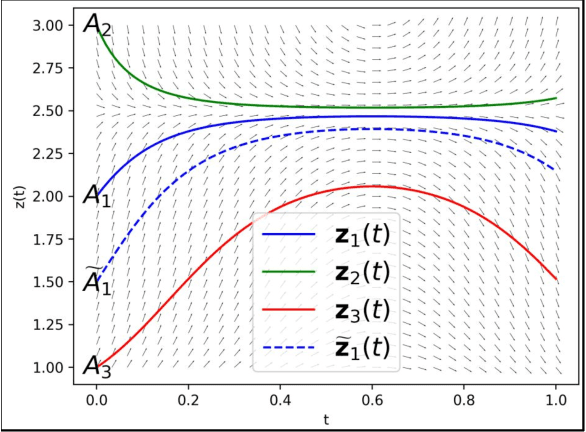

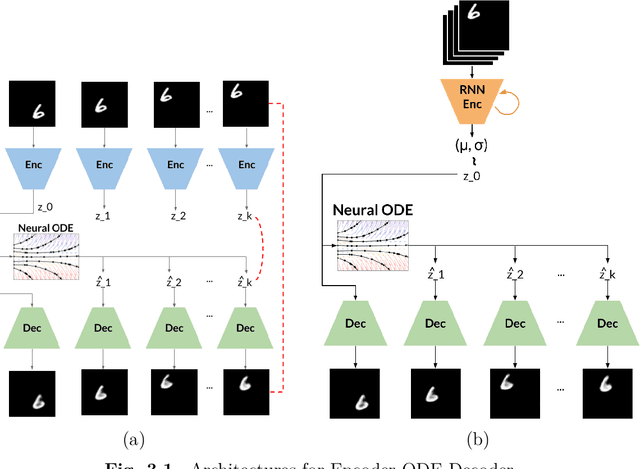
This dissertation attempts to drive innovation in the field of generative modeling for computer vision, by exploring novel formulations of conditional generative models, and innovative applications in images, 3D animations, and video. Our research focuses on architectures that offer reversible transformations of noise and visual data, and the application of encoder-decoder architectures for generative tasks and 3D content manipulation. In all instances, we incorporate conditional information to enhance the synthesis of visual data, improving the efficiency of the generation process as well as the generated content. We introduce the use of Neural ODEs to model video dynamics using an encoder-decoder architecture, demonstrating their ability to predict future video frames despite being trained solely to reconstruct current frames. Next, we propose a conditional variant of continuous normalizing flows that enables higher-resolution image generation based on lower-resolution input, achieving comparable image quality while reducing parameters and training time. Our next contribution presents a pipeline that takes human images as input, automatically aligns a user-specified 3D character with the pose of the human, and facilitates pose editing based on partial inputs. Next, we derive the relevant mathematical details for denoising diffusion models that use non-isotropic Gaussian processes, and show comparable generation quality. Finally, we devise a novel denoising diffusion framework capable of solving all three video tasks of prediction, generation, and interpolation. We perform ablation studies, and show SOTA results on multiple datasets. Our contributions are published articles at peer-reviewed venues. Overall, our research aims to make a meaningful contribution to the pursuit of more efficient and flexible generative models, with the potential to shape the future of computer vision.
LLM4SGG: Large Language Model for Weakly Supervised Scene Graph Generation
Oct 19, 2023Weakly-Supervised Scene Graph Generation (WSSGG) research has recently emerged as an alternative to the fully-supervised approach that heavily relies on costly annotations. In this regard, studies on WSSGG have utilized image captions to obtain unlocalized triplets while primarily focusing on grounding the unlocalized triplets over image regions. However, they have overlooked the two issues involved in the triplet formation process from the captions: 1) Semantic over-simplification issue arises when extracting triplets from captions, where fine-grained predicates in captions are undesirably converted into coarse-grained predicates, resulting in a long-tailed predicate distribution, and 2) Low-density scene graph issue arises when aligning the triplets in the caption with entity/predicate classes of interest, where many triplets are discarded and not used in training, leading to insufficient supervision. To tackle the two issues, we propose a new approach, i.e., Large Language Model for weakly-supervised SGG (LLM4SGG), where we mitigate the two issues by leveraging the LLM's in-depth understanding of language and reasoning ability during the extraction of triplets from captions and alignment of entity/predicate classes with target data. To further engage the LLM in these processes, we adopt the idea of Chain-of-Thought and the in-context few-shot learning strategy. To validate the effectiveness of LLM4SGG, we conduct extensive experiments on Visual Genome and GQA datasets, showing significant improvements in both Recall@K and mean Recall@K compared to the state-of-the-art WSSGG methods. A further appeal is that LLM4SGG is data-efficient, enabling effective model training with a small amount of training images.
LLP-Bench: A Large Scale Tabular Benchmark for Learning from Label Proportions
Oct 16, 2023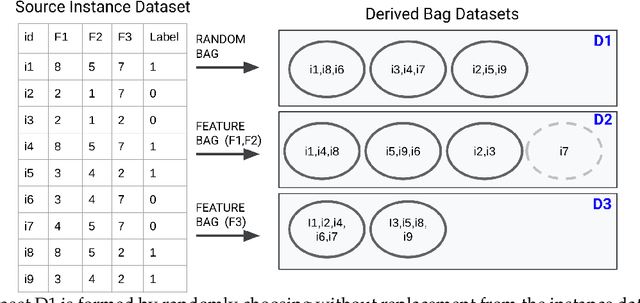
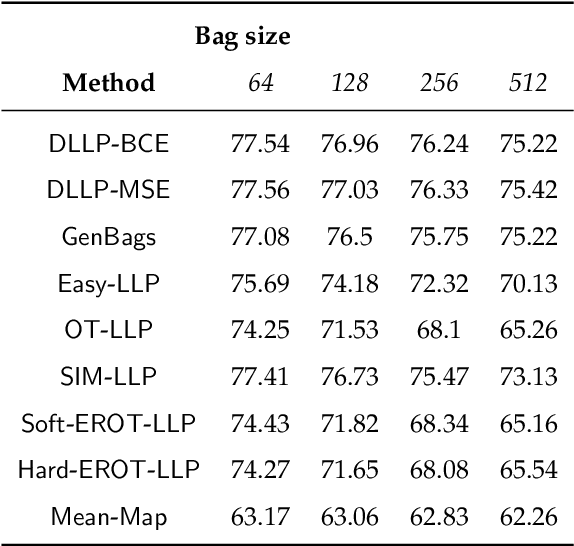
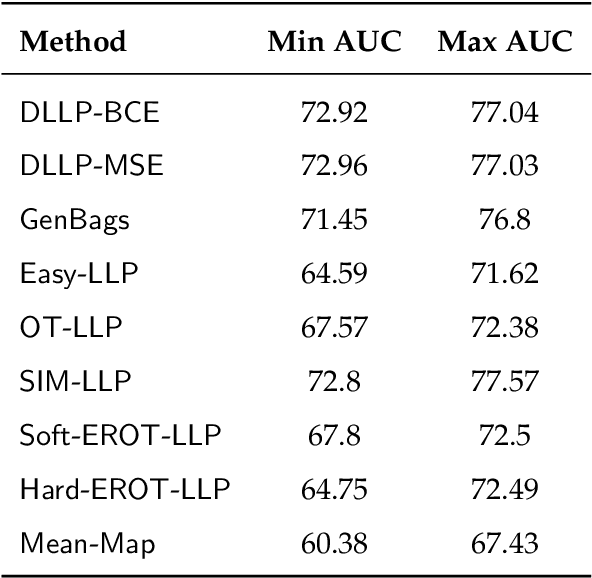
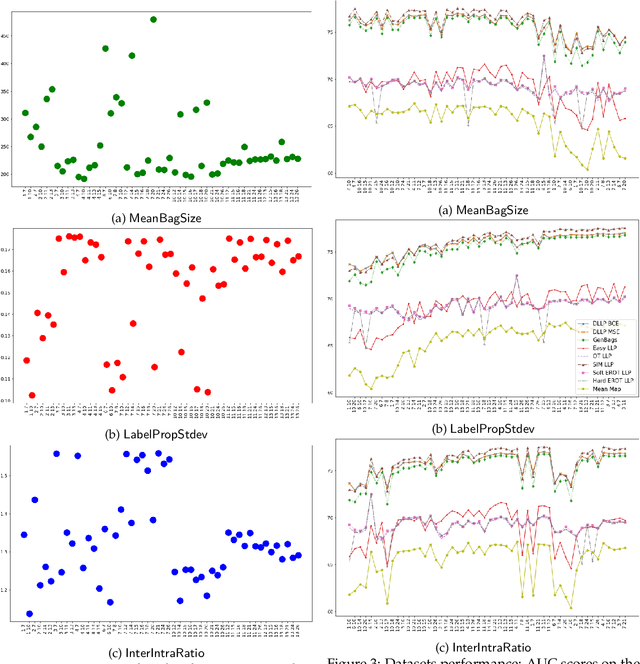
In the task of Learning from Label Proportions (LLP), a model is trained on groups (a.k.a bags) of instances and their corresponding label proportions to predict labels for individual instances. LLP has been applied pre-dominantly on two types of datasets - image and tabular. In image LLP, bags of fixed size are created by randomly sampling instances from an underlying dataset. Bags created via this methodology are called random bags. Experimentation on Image LLP has been mostly on random bags on CIFAR-* and MNIST datasets. Despite being a very crucial task in privacy sensitive applications, tabular LLP does not yet have a open, large scale LLP benchmark. One of the unique properties of tabular LLP is the ability to create feature bags where all the instances in a bag have the same value for a given feature. It has been shown in prior research that feature bags are very common in practical, real world applications [Chen et. al '23, Saket et. al. '22]. In this paper, we address the lack of a open, large scale tabular benchmark. First we propose LLP-Bench, a suite of 56 LLP datasets (52 feature bag and 4 random bag datasets) created from the Criteo CTR prediction dataset consisting of 45 million instances. The 56 datasets represent diverse ways in which bags can be constructed from underlying tabular data. To the best of our knowledge, LLP-Bench is the first large scale tabular LLP benchmark with an extensive diversity in constituent datasets. Second, we propose four metrics that characterize and quantify the hardness of a LLP dataset. Using these four metrics we present deep analysis of the 56 datasets in LLP-Bench. Finally we present the performance of 9 SOTA and popular tabular LLP techniques on all the 56 datasets. To the best of our knowledge, our study consisting of more than 2500 experiments is the most extensive study of popular tabular LLP techniques in literature.
TransCC: Transformer Network for Coronary Artery CCTA Segmentation
Oct 07, 2023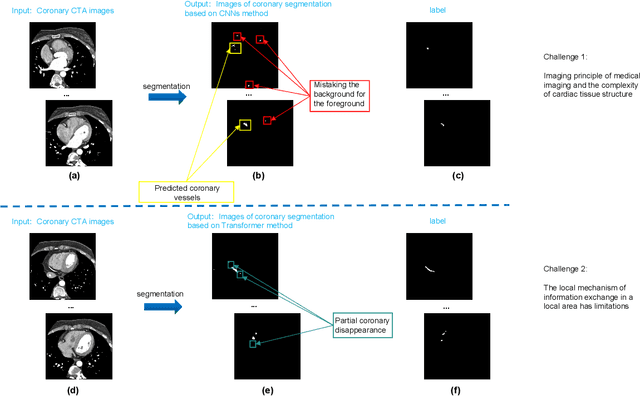
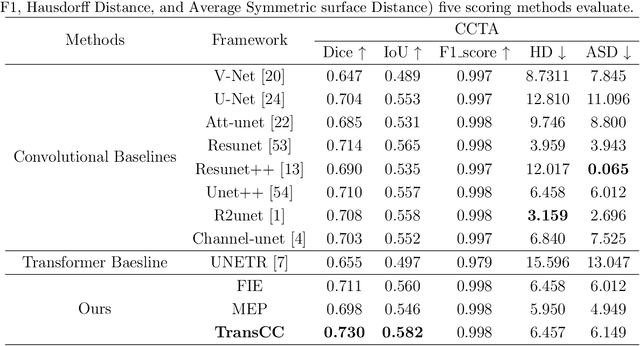
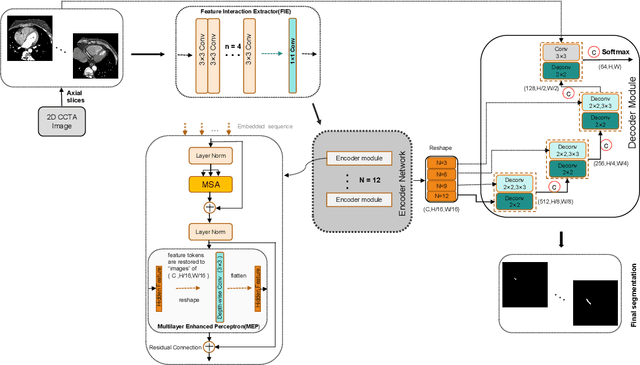
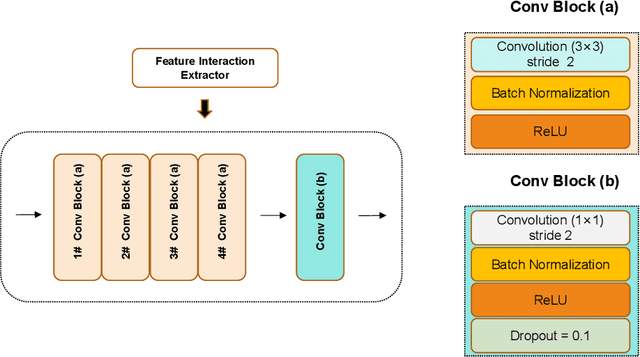
The accurate segmentation of Coronary Computed Tomography Angiography (CCTA) images holds substantial clinical value for the early detection and treatment of Coronary Heart Disease (CHD). The Transformer, utilizing a self-attention mechanism, has demonstrated commendable performance in the realm of medical image processing. However, challenges persist in coronary segmentation tasks due to (1) the damage to target local structures caused by fixed-size image patch embedding, and (2) the critical role of both global and local features in medical image segmentation tasks.To address these challenges, we propose a deep learning framework, TransCC, that effectively amalgamates the Transformer and convolutional neural networks for CCTA segmentation. Firstly, we introduce a Feature Interaction Extraction (FIE) module designed to capture the characteristics of image patches, thereby circumventing the loss of semantic information inherent in the original method. Secondly, we devise a Multilayer Enhanced Perceptron (MEP) to augment attention to local information within spatial dimensions, serving as a complement to the self-attention mechanism. Experimental results indicate that TransCC outperforms existing methods in segmentation performance, boasting an average Dice coefficient of 0.730 and an average Intersection over Union (IoU) of 0.582. These results underscore the effectiveness of TransCC in CCTA image segmentation.