 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enabling Neural Radiance Fields (NeRF) for Large-scale Aerial Images -- A Multi-tiling Approach and the Geometry Assessment of NeRF
Oct 17, 2023
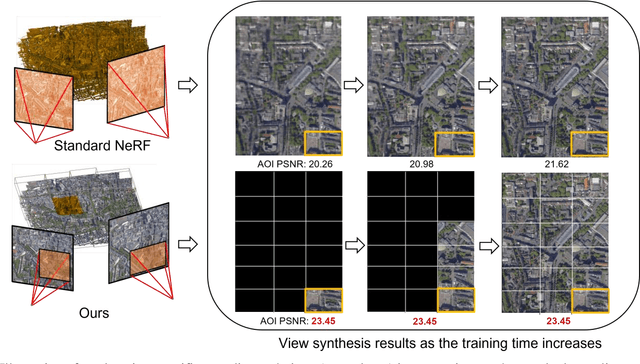

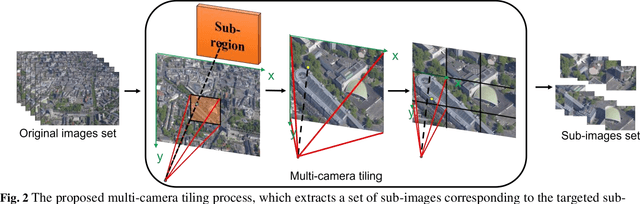

Neural Radiance Fields (NeRF) offer the potential to benefit 3D reconstruction tasks, including aerial photogrammetry. However, the scalability and accuracy of the inferred geometry are not well-documented for large-scale aerial assets,since such datasets usually result in very high memory consumption and slow convergence.. In this paper, we aim to scale the NeRF on large-scael aerial datasets and provide a thorough geometry assessment of NeRF. Specifically, we introduce a location-specific sampling technique as well as a multi-camera tiling (MCT) strategy to reduce memory consumption during image loading for RAM, representation training for GPU memory, and increase the convergence rate within tiles. MCT decomposes a large-frame image into multiple tiled images with different camera models, allowing these small-frame images to be fed into the training process as needed for specific locations without a loss of accuracy. We implement our method on a representative approach, Mip-NeRF, and compare its geometry performance with threephotgrammetric MVS pipelines on two typical aerial datasets against LiDAR reference data. Both qualitative and quantitative results suggest that the proposed NeRF approach produces better completeness and object details than traditional approaches, although as of now, it still falls short in terms of accuracy.
Diver Interest via Pointing in Three Dimensions: 3D Pointing Reconstruction for Diver-AUV Communication
Oct 17, 2023This paper presents Diver Interest via Pointing in Three Dimensions (DIP-3D), a method to relay an object of interest from a diver to an autonomous underwater vehicle (AUV) by pointing that includes three-dimensional distance information to discriminate between multiple objects in the AUV's camera image. Traditional dense stereo vision for distance estimation underwater is challenging because of the relative lack of saliency of scene features and degraded lighting conditions. Yet, including distance information is necessary for robotic perception of diver pointing when multiple objects appear within the robot's image plane. We subvert the challenges of underwater distance estimation by using sparse reconstruction of keypoints to perform pose estimation on both the left and right images from the robot's stereo camera. Triangulated pose keypoints, along with a classical object detection method, enable DIP-3D to infer the location of an object of interest when multiple objects are in the AUV's field of view. By allowing the scuba diver to point at an arbitrary object of interest and enabling the AUV to autonomously decide which object the diver is pointing to, this method will permit more natural interaction between AUVs and human scuba divers in underwater-human robot collaborative tasks.
United We Stand: Using Epoch-wise Agreement of Ensembles to Combat Overfit
Oct 17, 2023Deep neural networks have become the method of choice for solving many image classification tasks, largely because they can fit very complex functions defined over raw images. The downside of such powerful learners is the danger of overfitting the training set, leading to poor generalization, which is usually avoided by regularization and "early stopping" of the training. In this paper, we propose a new deep network ensemble classifier that is very effective against overfit. We begin with the theoretical analysis of a regression model, whose predictions - that the variance among classifiers increases when overfit occurs - is demonstrated empirically in deep networks in common use. Guided by these results, we construct a new ensemble-based prediction method designed to combat overfit, where the prediction is determined by the most consensual prediction throughout the training. On multiple image and text classification datasets, we show that when regular ensembles suffer from overfit, our method eliminates the harmful reduction in generalization due to overfit, and often even surpasses the performance obtained by early stopping. Our method is easy to implement, and can be integrated with any training scheme and architecture, without additional prior knowledge beyond the training set. Accordingly, it is a practical and useful tool to overcome overfit.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Oct 13, 2023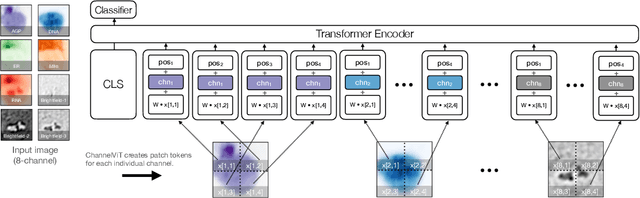
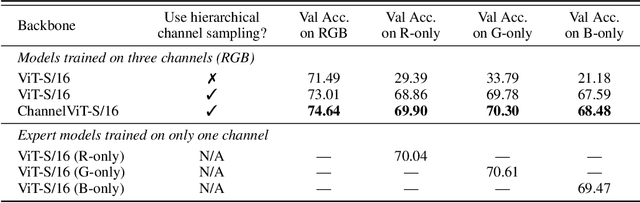
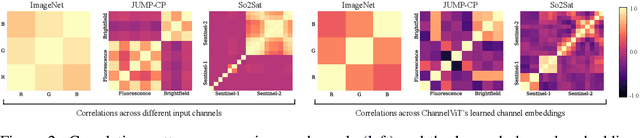
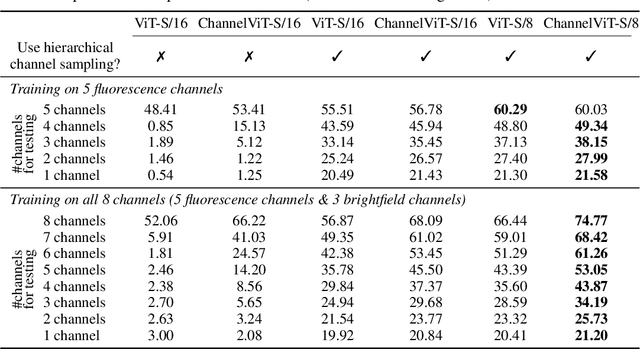
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
PaLI-3 Vision Language Models: Smaller, Faster, Stronger
Oct 13, 2023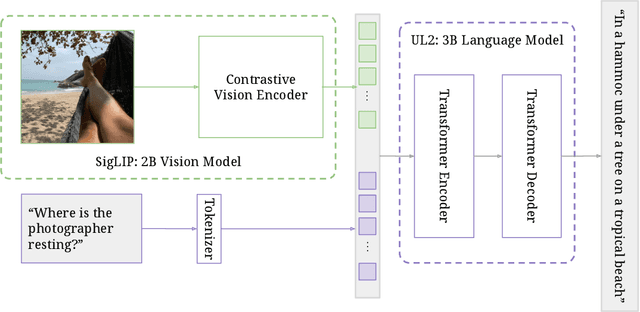
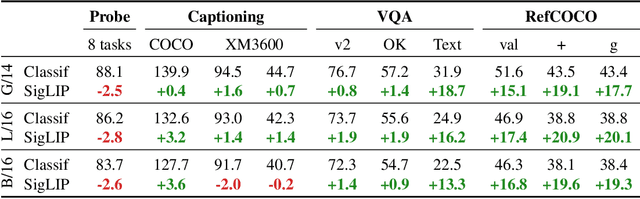
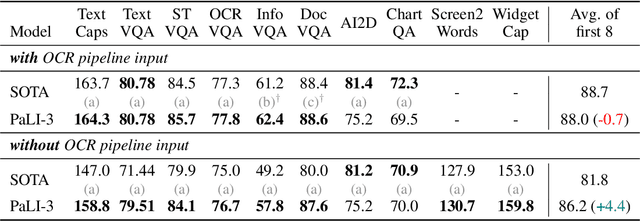
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
APP-RUSS: Automated Path Planning for Robotic Ultrasound System
Oct 22, 2023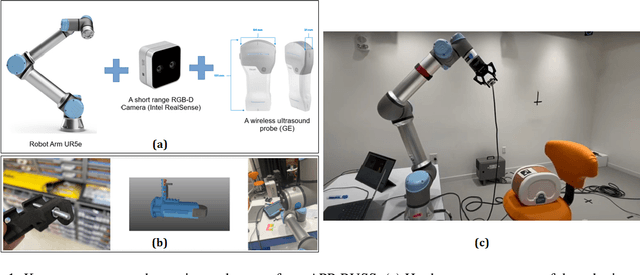
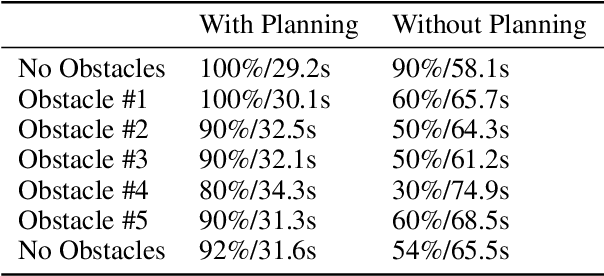
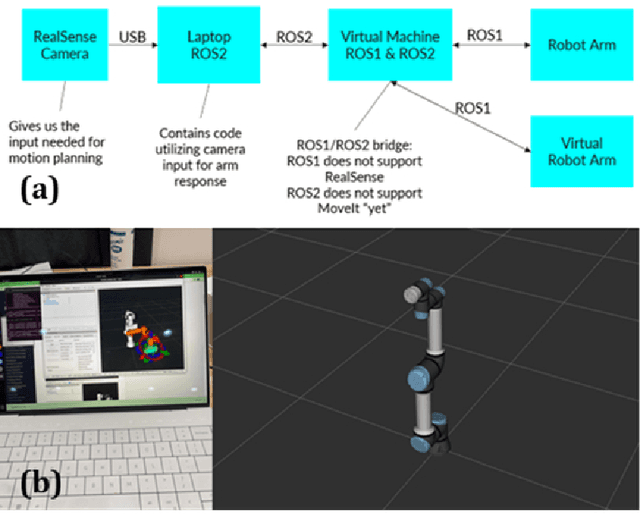
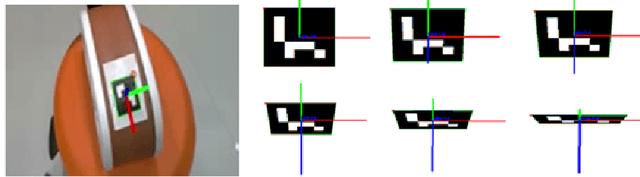
Autonomous robotic ultrasound System (RUSS) has been extensively studied. However, fully automated ultrasound image acquisition is still challenging, partly due to the lack of study in combining two phases of path planning: guiding the ultrasound probe to the scan target and covering the scan surface or volume. This paper presents a system of Automated Path Planning for RUSS (APP-RUSS). Our focus is on the first phase of automation, which emphasizes directing the ultrasound probe's path toward the target over extended distances. Specifically, our APP-RUSS system consists of a RealSense D405 RGB-D camera that is employed for visual guidance of the UR5e robotic arm and a cubic Bezier curve path planning model that is customized for delivering the probe to the recognized target. APP-RUSS can contribute to understanding the integration of the two phases of path planning in robotic ultrasound imaging, paving the way for its clinical adoption.
Pix2HDR -- A pixel-wise acquisition and deep learning-based synthesis approach for high-speed HDR videos
Oct 24, 2023Accurately capturing dynamic scenes with wide-ranging motion and light intensity is crucial for many vision applications. However, acquiring high-speed high dynamic range (HDR) video is challenging because the camera's frame rate restricts its dynamic range. Existing methods sacrifice speed to acquire multi-exposure frames. Yet, misaligned motion in these frames can still pose complications for HDR fusion algorithms, resulting in artifacts. Instead of frame-based exposures, we sample the videos using individual pixels at varying exposures and phase offsets. Implemented on a pixel-wise programmable image sensor, our sampling pattern simultaneously captures fast motion at a high dynamic range. We then transform pixel-wise outputs into an HDR video using end-to-end learned weights from deep neural networks, achieving high spatiotemporal resolution with minimized motion blurring. We demonstrate aliasing-free HDR video acquisition at 1000 FPS, resolving fast motion under low-light conditions and against bright backgrounds - both challenging conditions for conventional cameras. By combining the versatility of pixel-wise sampling patterns with the strength of deep neural networks at decoding complex scenes, our method greatly enhances the vision system's adaptability and performance in dynamic conditions.
Deep Learning Models for Classification of COVID-19 Cases by Medical Images
Oct 24, 2023
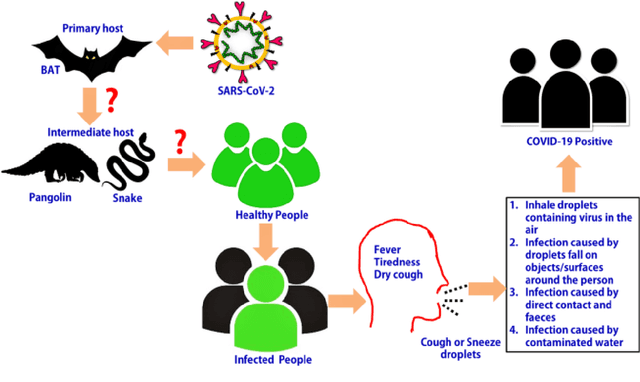
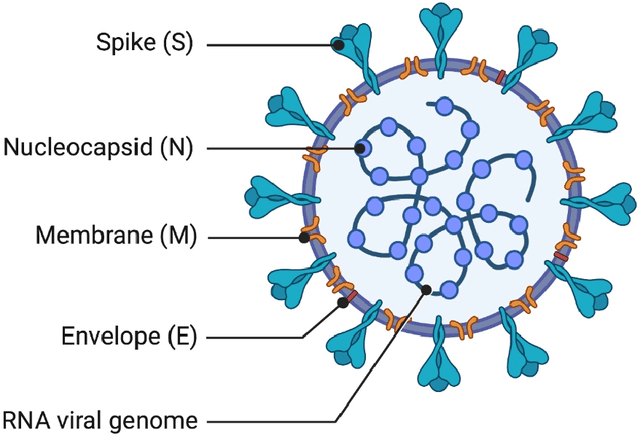
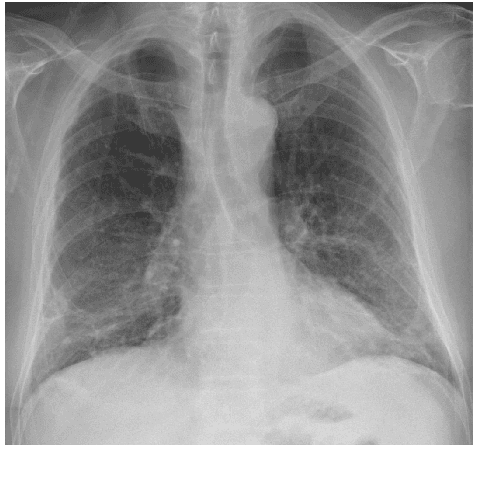
In recent times, the use of chest Computed Tomography (CT) images for detecting coronavirus infections has gained significant attention, owing to their ability to reveal bilateral changes in affected individuals. However, classifying patients from medical images presents a formidable challenge, particularly in identifying such bilateral changes. To tackle this challenge, our study harnesses the power of deep learning models for the precise classification of infected patients. Our research involves a comparative analysis of deep transfer learning-based classification models, including DenseNet201, GoogleNet, and AlexNet, against carefully chosen supervised learning models. Additionally, our work encompasses Covid-19 classification, which involves the identification and differentiation of medical images, such as X-rays and electrocardiograms, that exhibit telltale signs of Covid-19 infection. This comprehensive approach ensures that our models can handle a wide range of medical image types and effectively identify characteristic patterns indicative of Covid-19. By conducting meticulous research and employing advanced deep learning techniques, we have made significant strides in enhancing the accuracy and speed of Covid-19 diagnosis. Our results demonstrate the effectiveness of these models and their potential to make substantial contributions to the global effort to combat COVID-19.
Hierarchical Randomized Smoothing
Oct 24, 2023Real-world data is complex and often consists of objects that can be decomposed into multiple entities (e.g. images into pixels, graphs into interconnected nodes). Randomized smoothing is a powerful framework for making models provably robust against small changes to their inputs - by guaranteeing robustness of the majority vote when randomly adding noise before classification. Yet, certifying robustness on such complex data via randomized smoothing is challenging when adversaries do not arbitrarily perturb entire objects (e.g. images) but only a subset of their entities (e.g. pixels). As a solution, we introduce hierarchical randomized smoothing: We partially smooth objects by adding random noise only on a randomly selected subset of their entities. By adding noise in a more targeted manner than existing methods we obtain stronger robustness guarantees while maintaining high accuracy. We initialize hierarchical smoothing using different noising distributions, yielding novel robustness certificates for discrete and continuous domains. We experimentally demonstrate the importance of hierarchical smoothing in image and node classification, where it yields superior robustness-accuracy trade-offs. Overall, hierarchical smoothing is an important contribution towards models that are both - certifiably robust to perturbations and accurate.
ShadowSense: Unsupervised Domain Adaptation and Feature Fusion for Shadow-Agnostic Tree Crown Detection from RGB-Thermal Drone Imagery
Oct 24, 2023Accurate detection of individual tree crowns from remote sensing data poses a significant challenge due to the dense nature of forest canopy and the presence of diverse environmental variations, e.g., overlapping canopies, occlusions, and varying lighting conditions. Additionally, the lack of data for training robust models adds another limitation in effectively studying complex forest conditions. This paper presents a novel method for detecting shadowed tree crowns and provides a challenging dataset comprising roughly 50k paired RGB-thermal images to facilitate future research for illumination-invariant detection. The proposed method (ShadowSense) is entirely self-supervised, leveraging domain adversarial training without source domain annotations for feature extraction and foreground feature alignment for feature pyramid networks to adapt domain-invariant representations by focusing on visible foreground regions, respectively. It then fuses complementary information of both modalities to effectively improve upon the predictions of an RGB-trained detector and boost the overall accuracy. Extensive experiments demonstrate the superiority of the proposed method over both the baseline RGB-trained detector and state-of-the-art techniques that rely on unsupervised domain adaptation or early image fusion. Our code and data are available: https://github.com/rudrakshkapil/ShadowSense