 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Interpretable Controllability in Object-Centric Learning
Oct 16, 2023
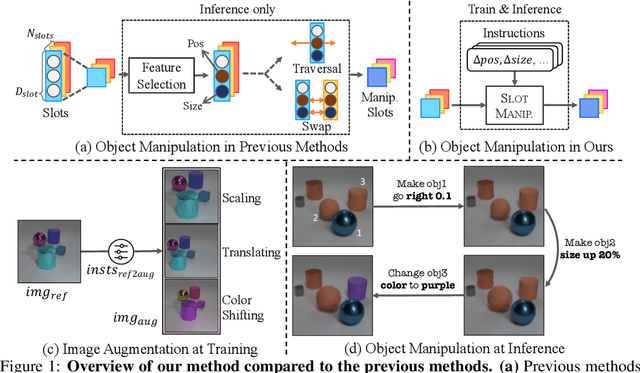
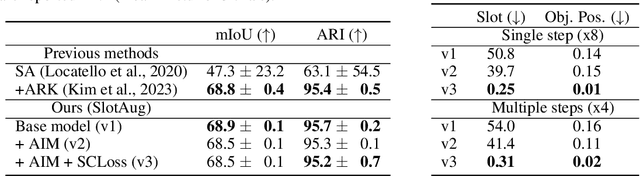
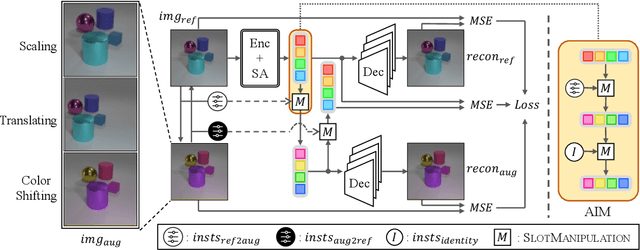
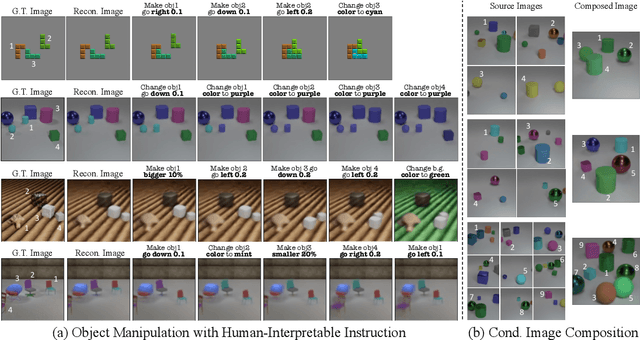
The binding problem in artificial neural networks is actively explored with the goal of achieving human-level recognition skills through the comprehension of the world in terms of symbol-like entities. Especially in the field of computer vision, object-centric learning (OCL) is extensively researched to better understand complex scenes by acquiring object representations or slots. While recent studies in OCL have made strides with complex images or videos, the interpretability and interactivity over object representation remain largely uncharted, still holding promise in the field of OCL. In this paper, we introduce a novel method, Slot Attention with Image Augmentation (SlotAug), to explore the possibility of learning interpretable controllability over slots in a self-supervised manner by utilizing an image augmentation strategy. We also devise the concept of sustainability in controllable slots by introducing iterative and reversible controls over slots with two proposed submethods: Auxiliary Identity Manipulation and Slot Consistency Loss. Extensive empirical studies and theoretical validation confirm the effectiveness of our approach, offering a novel capability for interpretable and sustainable control of object representations. Code will be available soon.
Provable Probabilistic Imaging using Score-Based Generative Priors
Oct 16, 2023Estimating high-quality images while also quantifying their uncertainty are two desired features in an image reconstruction algorithm for solving ill-posed inverse problems. In this paper, we propose plug-and-play Monte Carlo (PMC) as a principled framework for characterizing the space of possible solutions to a general inverse problem. PMC is able to incorporate expressive score-based generative priors for high-quality image reconstruction while also performing uncertainty quantification via posterior sampling. In particular, we introduce two PMC algorithms which can be viewed as the sampling analogues of the traditional plug-and-play priors (PnP) and regularization by denoising (RED) algorithms. We also establish a theoretical analysis for characterizing the convergence of the PMC algorithms. Our analysis provides non-asymptotic stationarity guarantees for both algorithms, even in the presence of non-log-concave likelihoods and imperfect score networks. We demonstrate the performance of the PMC algorithms on multiple representative inverse problems with both linear and nonlinear forward models. Experimental results show that PMC significantly improves reconstruction quality and enables high-fidelity uncertainty quantification.
Multi-stream Cell Segmentation with Low-level Cues for Multi-modality Images
Oct 22, 2023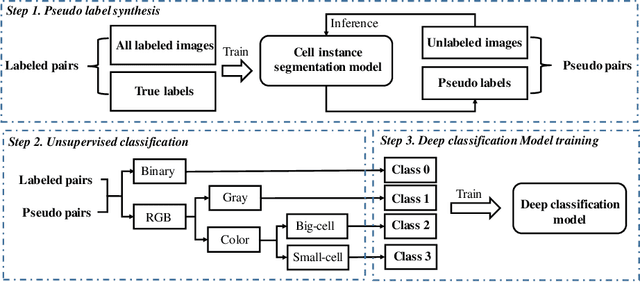
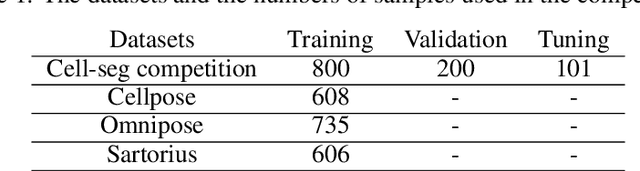
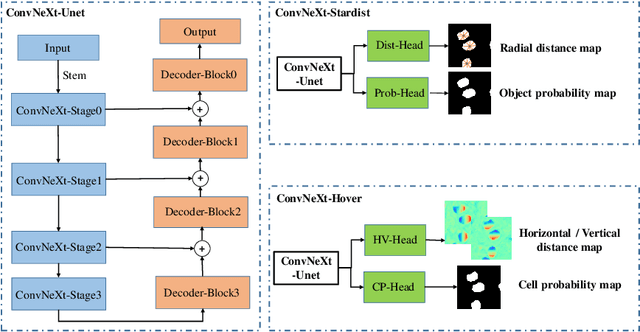

Cell segmentation for multi-modal microscopy images remains a challenge due to the complex textures, patterns, and cell shapes in these images. To tackle the problem, we first develop an automatic cell classification pipeline to label the microscopy images based on their low-level image characteristics, and then train a classification model based on the category labels. Afterward, we train a separate segmentation model for each category using the images in the corresponding category. Besides, we further deploy two types of segmentation models to segment cells with roundish and irregular shapes respectively. Moreover, an efficient and powerful backbone model is utilized to enhance the efficiency of our segmentation model. Evaluated on the Tuning Set of NeurIPS 2022 Cell Segmentation Challenge, our method achieves an F1-score of 0.8795 and the running time for all cases is within the time tolerance.
Animating Street View
Oct 12, 2023We present a system that automatically brings street view imagery to life by populating it with naturally behaving, animated pedestrians and vehicles. Our approach is to remove existing people and vehicles from the input image, insert moving objects with proper scale, angle, motion, and appearance, plan paths and traffic behavior, as well as render the scene with plausible occlusion and shadowing effects. The system achieves these by reconstructing the still image street scene, simulating crowd behavior, and rendering with consistent lighting, visibility, occlusions, and shadows. We demonstrate results on a diverse range of street scenes including regular still images and panoramas.
Diffusion Model with Clustering-based Conditioning for Food Image Generation
Sep 01, 2023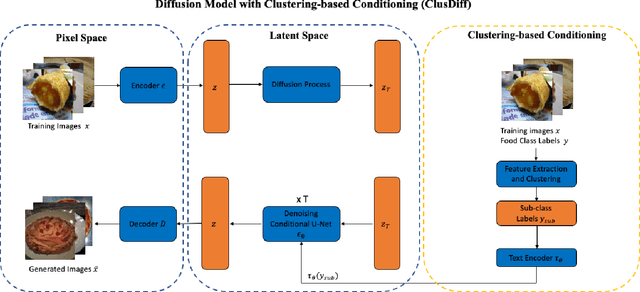

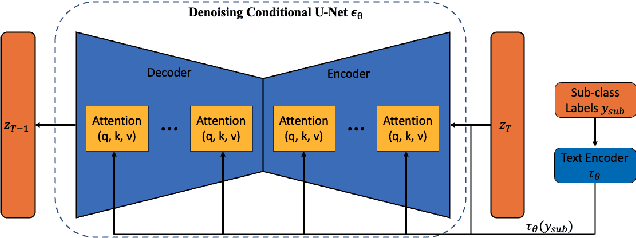
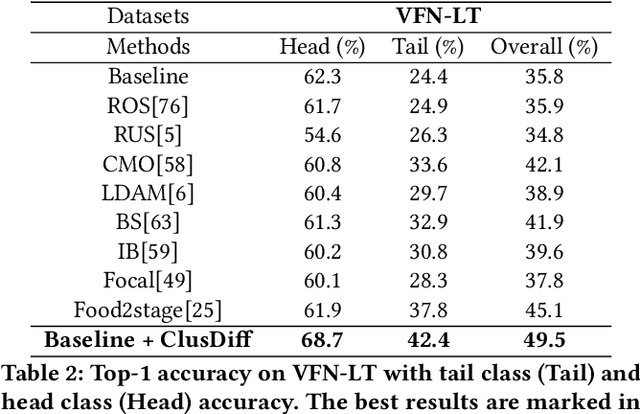
Image-based dietary assessment serves as an efficient and accurate solution for recording and analyzing nutrition intake using eating occasion images as input. Deep learning-based techniques are commonly used to perform image analysis such as food classification, segmentation, and portion size estimation, which rely on large amounts of food images with annotations for training. However, such data dependency poses significant barriers to real-world applications, because acquiring a substantial, diverse, and balanced set of food images can be challenging. One potential solution is to use synthetic food images for data augmentation. Although existing work has explored the use of generative adversarial networks (GAN) based structures for generation, the quality of synthetic food images still remains subpar. In addition, while diffusion-based generative models have shown promising results for general image generation tasks, the generation of food images can be challenging due to the substantial intra-class variance. In this paper, we investigate the generation of synthetic food images based on the conditional diffusion model and propose an effective clustering-based training framework, named ClusDiff, for generating high-quality and representative food images. The proposed method is evaluated on the Food-101 dataset and shows improved performance when compared with existing image generation works. We also demonstrate that the synthetic food images generated by ClusDiff can help address the severe class imbalance issue in long-tailed food classification using the VFN-LT dataset.
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images ... For Now
Oct 18, 2023The recent advances in diffusion models (DMs) have revolutionized the generation of complex and diverse images. However, these models also introduce potential safety hazards, such as the production of harmful content and infringement of data copyrights. Although there have been efforts to create safety-driven unlearning methods to counteract these challenges, doubts remain about their capabilities. To bridge this uncertainty, we propose an evaluation framework built upon adversarial attacks (also referred to as adversarial prompts), in order to discern the trustworthiness of these safety-driven unlearned DMs. Specifically, our research explores the (worst-case) robustness of unlearned DMs in eradicating unwanted concepts, styles, and objects, assessed by the generation of adversarial prompts. We develop a novel adversarial learning approach called UnlearnDiff that leverages the inherent classification capabilities of DMs to streamline the generation of adversarial prompts, making it as simple for DMs as it is for image classification attacks. This technique streamlines the creation of adversarial prompts, making the process as intuitive for generative modeling as it is for image classification assaults. Through comprehensive benchmarking, we assess the unlearning robustness of five prevalent unlearned DMs across multiple tasks. Our results underscore the effectiveness and efficiency of UnlearnDiff when compared to state-of-the-art adversarial prompting methods. Codes are available at https://github.com/OPTML-Group/Diffusion-MU-Attack. WARNING: This paper contains model outputs that may be offensive in nature.
Exploring Decision-based Black-box Attacks on Face Forgery Detection
Oct 18, 2023Face forgery generation technologies generate vivid faces, which have raised public concerns about security and privacy. Many intelligent systems, such as electronic payment and identity verification, rely on face forgery detection. Although face forgery detection has successfully distinguished fake faces, recent studies have demonstrated that face forgery detectors are very vulnerable to adversarial examples. Meanwhile, existing attacks rely on network architectures or training datasets instead of the predicted labels, which leads to a gap in attacking deployed applications. To narrow this gap, we first explore the decision-based attacks on face forgery detection. However, applying existing decision-based attacks directly suffers from perturbation initialization failure and low image quality. First, we propose cross-task perturbation to handle initialization failures by utilizing the high correlation of face features on different tasks. Then, inspired by using frequency cues by face forgery detection, we propose the frequency decision-based attack. We add perturbations in the frequency domain and then constrain the visual quality in the spatial domain. Finally, extensive experiments demonstrate that our method achieves state-of-the-art attack performance on FaceForensics++, CelebDF, and industrial APIs, with high query efficiency and guaranteed image quality. Further, the fake faces by our method can pass face forgery detection and face recognition, which exposes the security problems of face forgery detectors.
Hierarchy Flow For High-Fidelity Image-to-Image Translation
Aug 14, 2023
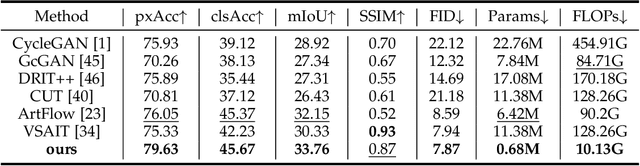
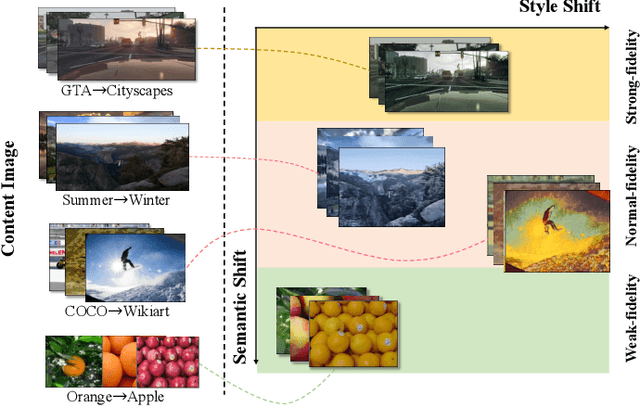
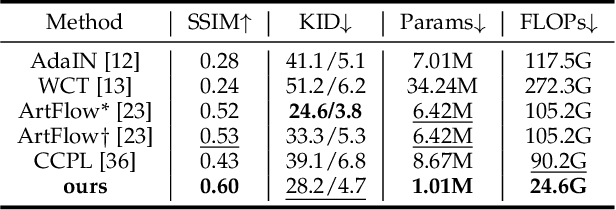
Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
HalluciDet: Hallucinating RGB Modality for Person Detection Through Privileged Information
Oct 07, 2023
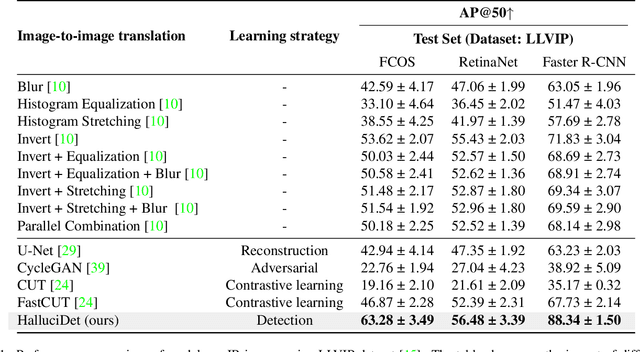
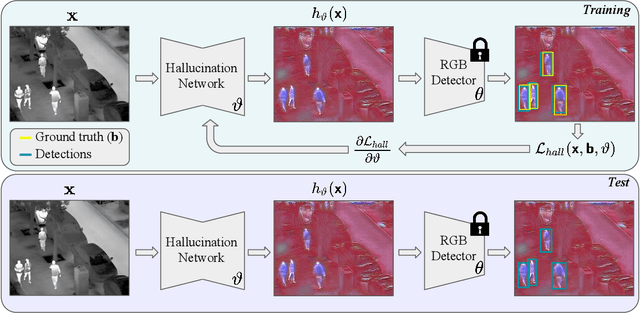
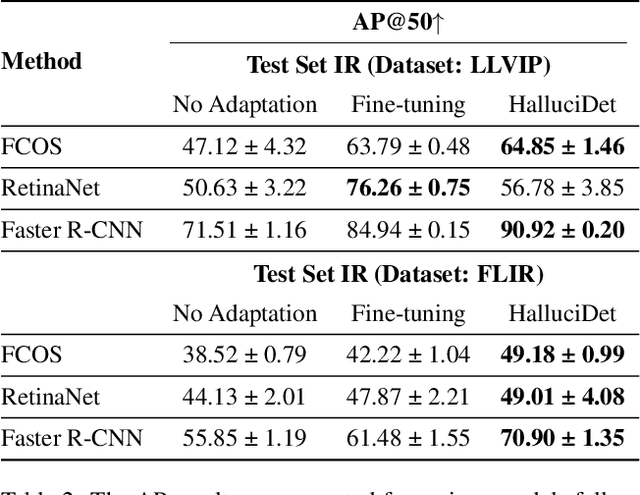
A powerful way to adapt a visual recognition model to a new domain is through image translation. However, common image translation approaches only focus on generating data from the same distribution of the target domain. In visual recognition tasks with complex images, such as pedestrian detection on aerial images with a large cross-modal shift in data distribution from Infrared (IR) to RGB images, a translation focused on generation might lead to poor performance as the loss focuses on irrelevant details for the task. In this paper, we propose HalluciDet, an IR-RGB image translation model for object detection that, instead of focusing on reconstructing the original image on the IR modality, is guided directly on reducing the detection loss of an RGB detector, and therefore avoids the need to access RGB data. This model produces a new image representation that enhances the object of interest in the scene and greatly improves detection performance. We empirically compare our approach against state-of-the-art image translation methods as well as with the commonly used fine-tuning on IR, and show that our method improves detection accuracy in most cases, by exploiting the privileged information encoded in a pre-trained RGB detector.
Assessing Robustness via Score-Based Adversarial Image Generation
Oct 06, 2023
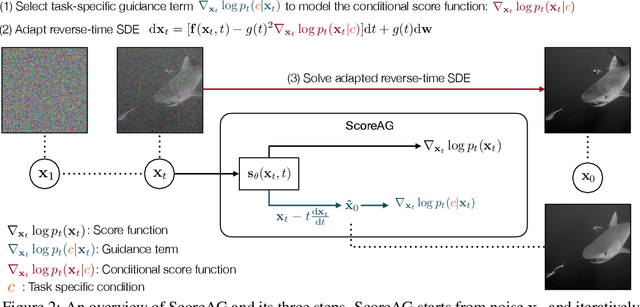
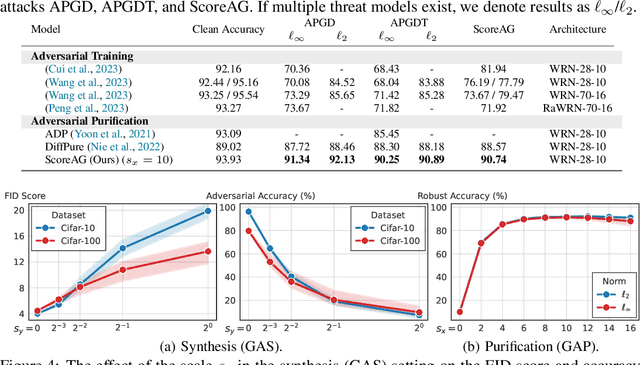
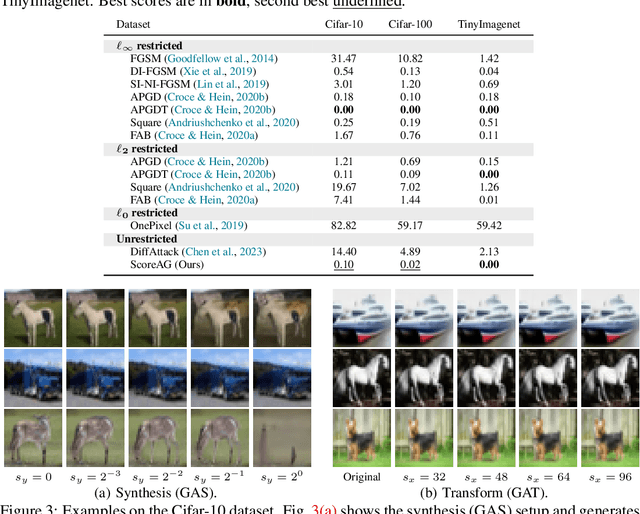
Most adversarial attacks and defenses focus on perturbations within small $\ell_p$-norm constraints. However, $\ell_p$ threat models cannot capture all relevant semantic-preserving perturbations, and hence, the scope of robustness evaluations is limited. In this work, we introduce Score-Based Adversarial Generation (ScoreAG), a novel framework that leverages the advancements in score-based generative models to generate adversarial examples beyond $\ell_p$-norm constraints, so-called unrestricted adversarial examples, overcoming their limitations. Unlike traditional methods, ScoreAG maintains the core semantics of images while generating realistic adversarial examples, either by transforming existing images or synthesizing new ones entirely from scratch. We further exploit the generative capability of ScoreAG to purify images, empirically enhancing the robustness of classifiers. Our extensive empirical evaluation demonstrates that ScoreAG matches the performance of state-of-the-art attacks and defenses across multiple benchmarks. This work highlights the importance of investigating adversarial examples bounded by semantics rather than $\ell_p$-norm constraints. ScoreAG represents an important step towards more encompassing robustness assessments.