 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meaning Representations from Trajectories in Autoregressive Models
Oct 23, 2023
We propose to extract meaning representations from autoregressive language models by considering the distribution of all possible trajectories extending an input text. This strategy is prompt-free, does not require fine-tuning, and is applicable to any pre-trained autoregressive model. Moreover, unlike vector-based representations, distribution-based representations can also model asymmetric relations (e.g., direction of logical entailment, hypernym/hyponym relations) by using algebraic operations between likelihood functions. These ideas are grounded in distributional perspectives on semantics and are connected to standard constructions in automata theory, but to our knowledge they have not been applied to modern language models. We empirically show that the representations obtained from large models align well with human annotations, outperform other zero-shot and prompt-free methods on semantic similarity tasks, and can be used to solve more complex entailment and containment tasks that standard embeddings cannot handle. Finally, we extend our method to represent data from different modalities (e.g., image and text) using multimodal autoregressive models.
LLM4SGG: Large Language Model for Weakly Supervised Scene Graph Generation
Oct 20, 2023Weakly-Supervised Scene Graph Generation (WSSGG) research has recently emerged as an alternative to the fully-supervised approach that heavily relies on costly annotations. In this regard, studies on WSSGG have utilized image captions to obtain unlocalized triplets while primarily focusing on grounding the unlocalized triplets over image regions. However, they have overlooked the two issues involved in the triplet formation process from the captions: 1) Semantic over-simplification issue arises when extracting triplets from captions, where fine-grained predicates in captions are undesirably converted into coarse-grained predicates, resulting in a long-tailed predicate distribution, and 2) Low-density scene graph issue arises when aligning the triplets in the caption with entity/predicate classes of interest, where many triplets are discarded and not used in training, leading to insufficient supervision. To tackle the two issues, we propose a new approach, i.e., Large Language Model for weakly-supervised SGG (LLM4SGG), where we mitigate the two issues by leveraging the LLM's in-depth understanding of language and reasoning ability during the extraction of triplets from captions and alignment of entity/predicate classes with target data. To further engage the LLM in these processes, we adopt the idea of Chain-of-Thought and the in-context few-shot learning strategy. To validate the effectiveness of LLM4SGG, we conduct extensive experiments on Visual Genome and GQA datasets, showing significant improvements in both Recall@K and mean Recall@K compared to the state-of-the-art WSSGG methods. A further appeal is that LLM4SGG is data-efficient, enabling effective model training with a small amount of training images.
A review of individual tree crown detection and delineation from optical remote sensing images
Oct 20, 2023Powered by the advances of optical remote sensing sensors, the production of very high spatial resolution multispectral images provides great potential for achieving cost-efficient and high-accuracy forest inventory and analysis in an automated way. Lots of studies that aim at providing an inventory to the level of each individual tree have generated a variety of methods for Individual Tree Crown Detection and Delineation (ITCD). This review covers ITCD methods for detecting and delineating individual tree crowns, and systematically reviews the past and present of ITCD-related researches applied to the optical remote sensing images. With the goal to provide a clear knowledge map of existing ITCD efforts, we conduct a comprehensive review of recent ITCD papers to build a meta-data analysis, including the algorithm, the study site, the tree species, the sensor type, the evaluation method, etc. We categorize the reviewed methods into three classes: (1) traditional image processing methods (such as local maximum filtering, image segmentation, etc.); (2) traditional machine learning methods (such as random forest, decision tree, etc.); and (3) deep learning based methods. With the deep learning-oriented approaches contributing a majority of the papers, we further discuss the deep learning-based methods as semantic segmentation and object detection methods. In addition, we discuss four ITCD-related issues to further comprehend the ITCD domain using optical remote sensing data, such as comparisons between multi-sensor based data and optical data in ITCD domain, comparisons among different algorithms and different ITCD tasks, etc. Finally, this review proposes some ITCD-related applications and a few exciting prospects and potential hot topics in future ITCD research.
Distributed Transfer Learning with 4th Gen Intel Xeon Processors
Oct 10, 2023In this paper, we explore how transfer learning, coupled with Intel Xeon, specifically 4th Gen Intel Xeon scalable processor, defies the conventional belief that training is primarily GPU-dependent. We present a case study where we achieved near state-of-the-art accuracy for image classification on a publicly available Image Classification TensorFlow dataset using Intel Advanced Matrix Extensions(AMX) and distributed training with Horovod.
Crowd Counting in Harsh Weather using Image Denoising with Pix2Pix GANs
Oct 11, 2023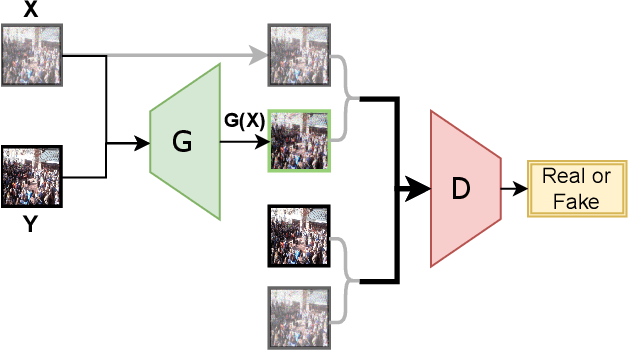
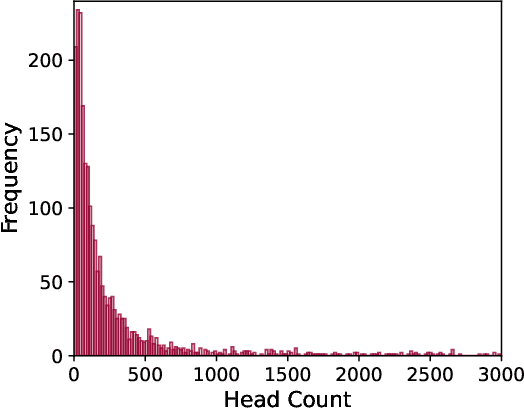

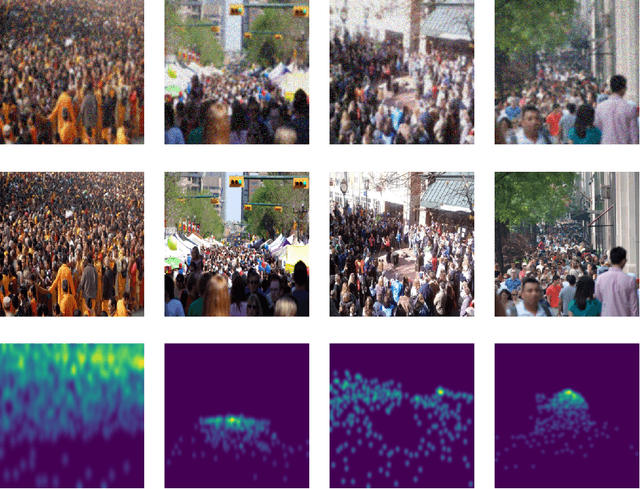
Visual crowd counting estimates the density of the crowd using deep learning models such as convolution neural networks (CNNs). The performance of the model heavily relies on the quality of the training data that constitutes crowd images. In harsh weather such as fog, dust, and low light conditions, the inference performance may severely degrade on the noisy and blur images. In this paper, we propose the use of Pix2Pix generative adversarial network (GAN) to first denoise the crowd images prior to passing them to the counting model. A Pix2Pix network is trained using synthetic noisy images generated from original crowd images and then the pretrained generator is then used in the inference engine to estimate the crowd density in unseen, noisy crowd images. The performance is tested on JHU-Crowd dataset to validate the significance of the proposed method particularly when high reliability and accuracy are required.
M$^{3}$3D: Learning 3D priors using Multi-Modal Masked Autoencoders for 2D image and video understanding
Sep 26, 2023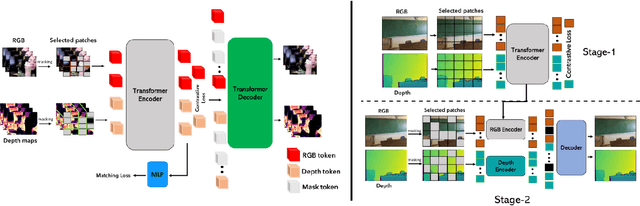
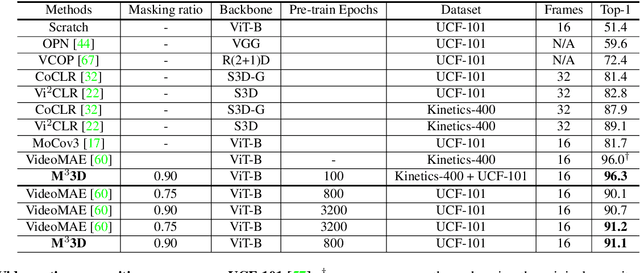
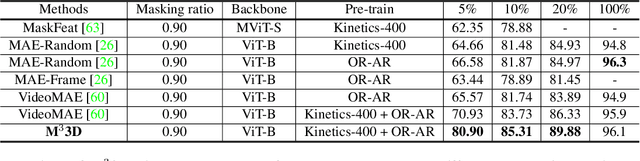
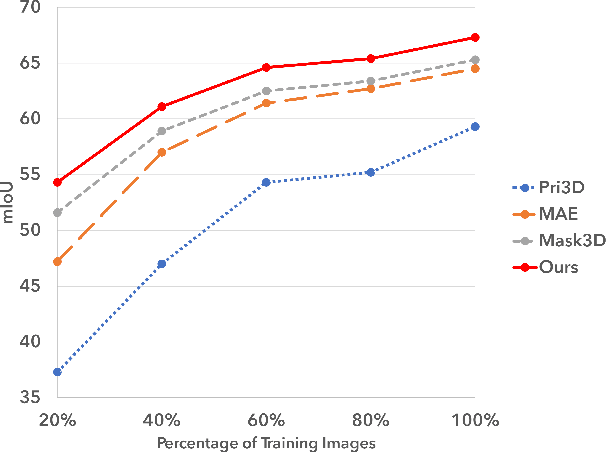
We present a new pre-training strategy called M$^{3}$3D ($\underline{M}$ulti-$\underline{M}$odal $\underline{M}$asked $\underline{3D}$) built based on Multi-modal masked autoencoders that can leverage 3D priors and learned cross-modal representations in RGB-D data. We integrate two major self-supervised learning frameworks; Masked Image Modeling (MIM) and contrastive learning; aiming to effectively embed masked 3D priors and modality complementary features to enhance the correspondence between modalities. In contrast to recent approaches which are either focusing on specific downstream tasks or require multi-view correspondence, we show that our pre-training strategy is ubiquitous, enabling improved representation learning that can transfer into improved performance on various downstream tasks such as video action recognition, video action detection, 2D semantic segmentation and depth estimation. Experiments show that M$^{3}$3D outperforms the existing state-of-the-art approaches on ScanNet, NYUv2, UCF-101 and OR-AR, particularly with an improvement of +1.3\% mIoU against Mask3D on ScanNet semantic segmentation. We further evaluate our method on low-data regime and demonstrate its superior data efficiency compared to current state-of-the-art approaches.
Semi-Supervised Panoptic Narrative Grounding
Oct 27, 2023Despite considerable progress, the advancement of Panoptic Narrative Grounding (PNG) remains hindered by costly annotations. In this paper, we introduce a novel Semi-Supervised Panoptic Narrative Grounding (SS-PNG) learning scheme, capitalizing on a smaller set of labeled image-text pairs and a larger set of unlabeled pairs to achieve competitive performance. Unlike visual segmentation tasks, PNG involves one pixel belonging to multiple open-ended nouns. As a result, existing multi-class based semi-supervised segmentation frameworks cannot be directly applied to this task. To address this challenge, we first develop a novel SS-PNG Network (SS-PNG-NW) tailored to the SS-PNG setting. We thoroughly investigate strategies such as Burn-In and data augmentation to determine the optimal generic configuration for the SS-PNG-NW. Additionally, to tackle the issue of imbalanced pseudo-label quality, we propose a Quality-Based Loss Adjustment (QLA) approach to adjust the semi-supervised objective, resulting in an enhanced SS-PNG-NW+. Employing our proposed QLA, we improve BCE Loss and Dice loss at pixel and mask levels, respectively. We conduct extensive experiments on PNG datasets, with our SS-PNG-NW+ demonstrating promising results comparable to fully-supervised models across all data ratios. Remarkably, our SS-PNG-NW+ outperforms fully-supervised models with only 30% and 50% supervision data, exceeding their performance by 0.8% and 1.1% respectively. This highlights the effectiveness of our proposed SS-PNG-NW+ in overcoming the challenges posed by limited annotations and enhancing the applicability of PNG tasks. The source code is available at https://github.com/nini0919/SSPNG.
The Road to On-board Change Detection: A Lightweight Patch-Level Change Detection Network via Exploring the Potential of Pruning and Pooling
Oct 16, 2023Existing satellite remote sensing change detection (CD) methods often crop original large-scale bi-temporal image pairs into small patch pairs and then use pixel-level CD methods to fairly process all the patch pairs. However, due to the sparsity of change in large-scale satellite remote sensing images, existing pixel-level CD methods suffer from a waste of computational cost and memory resources on lots of unchanged areas, which reduces the processing efficiency of on-board platform with extremely limited computation and memory resources. To address this issue, we propose a lightweight patch-level CD network (LPCDNet) to rapidly remove lots of unchanged patch pairs in large-scale bi-temporal image pairs. This is helpful to accelerate the subsequent pixel-level CD processing stage and reduce its memory costs. In our LPCDNet, a sensitivity-guided channel pruning method is proposed to remove unimportant channels and construct the lightweight backbone network on basis of ResNet18 network. Then, the multi-layer feature compression (MLFC) module is designed to compress and fuse the multi-level feature information of bi-temporal image patch. The output of MLFC module is fed into the fully-connected decision network to generate the predicted binary label. Finally, a weighted cross-entropy loss is utilized in the training process of network to tackle the change/unchange class imbalance problem. Experiments on two CD datasets demonstrate that our LPCDNet achieves more than 1000 frames per second on an edge computation platform, i.e., NVIDIA Jetson AGX Orin, which is more than 3 times that of the existing methods without noticeable CD performance loss. In addition, our method reduces more than 60% memory costs of the subsequent pixel-level CD processing stage.
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
Sep 12, 2023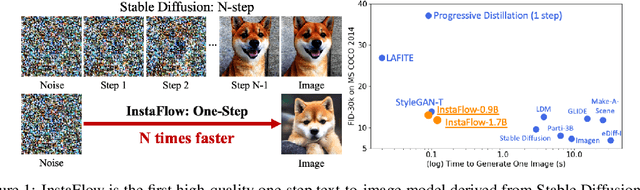
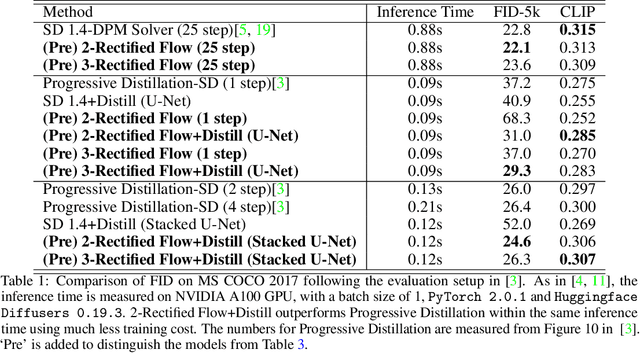

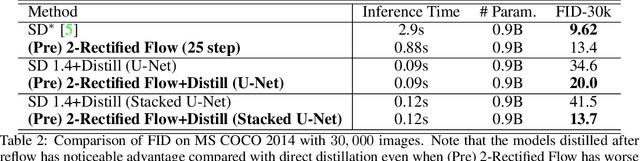
Diffusion models have revolutionized text-to-image generation with its exceptional quality and creativity. However, its multi-step sampling process is known to be slow, often requiring tens of inference steps to obtain satisfactory results. Previous attempts to improve its sampling speed and reduce computational costs through distillation have been unsuccessful in achieving a functional one-step model. In this paper, we explore a recent method called Rectified Flow, which, thus far, has only been applied to small datasets. The core of Rectified Flow lies in its \emph{reflow} procedure, which straightens the trajectories of probability flows, refines the coupling between noises and images, and facilitates the distillation process with student models. We propose a novel text-conditioned pipeline to turn Stable Diffusion (SD) into an ultra-fast one-step model, in which we find reflow plays a critical role in improving the assignment between noise and images. Leveraging our new pipeline, we create, to the best of our knowledge, the first one-step diffusion-based text-to-image generator with SD-level image quality, achieving an FID (Frechet Inception Distance) of $23.3$ on MS COCO 2017-5k, surpassing the previous state-of-the-art technique, progressive distillation, by a significant margin ($37.2$ $\rightarrow$ $23.3$ in FID). By utilizing an expanded network with 1.7B parameters, we further improve the FID to $22.4$. We call our one-step models \emph{InstaFlow}. On MS COCO 2014-30k, InstaFlow yields an FID of $13.1$ in just $0.09$ second, the best in $\leq 0.1$ second regime, outperforming the recent StyleGAN-T ($13.9$ in $0.1$ second). Notably, the training of InstaFlow only costs 199 A100 GPU days. Project page:~\url{https://github.com/gnobitab/InstaFlow}.
Human-Centered Evaluation of XAI Methods
Oct 16, 2023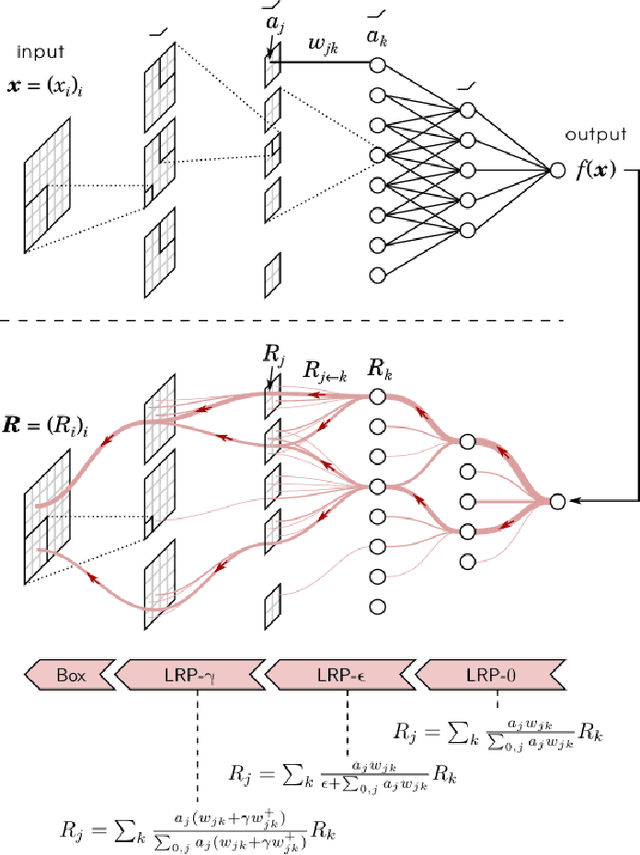

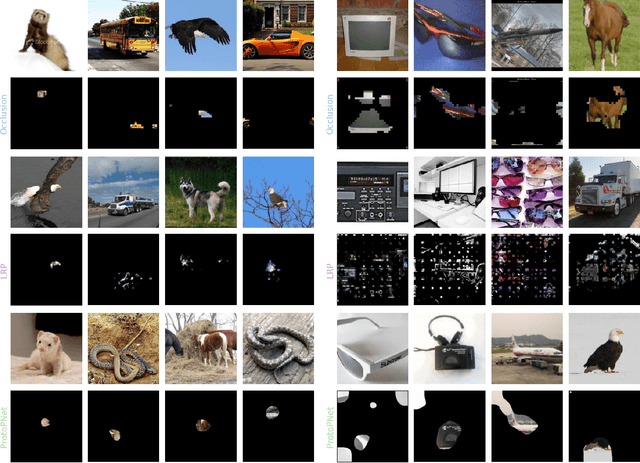
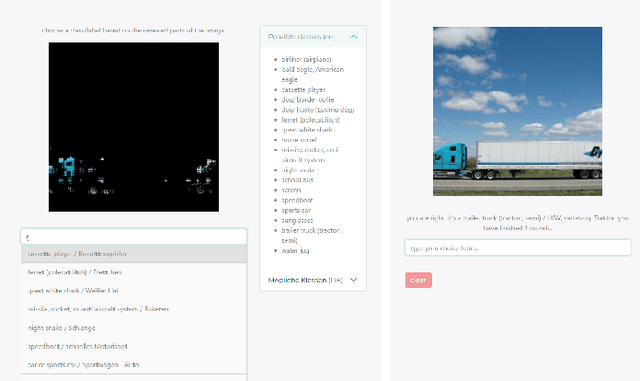
In the ever-evolving field of Artificial Intelligence, a critical challenge has been to decipher the decision-making processes within the so-called "black boxes" in deep learning. Over recent years, a plethora of methods have emerged, dedicated to explaining decisions across diverse tasks. Particularly in tasks like image classification, these methods typically identify and emphasize the pivotal pixels that most influence a classifier's prediction. Interestingly, this approach mirrors human behavior: when asked to explain our rationale for classifying an image, we often point to the most salient features or aspects. Capitalizing on this parallel, our research embarked on a user-centric study. We sought to objectively measure the interpretability of three leading explanation methods: (1) Prototypical Part Network, (2) Occlusion, and (3) Layer-wise Relevance Propagation. Intriguingly, our results highlight that while the regions spotlighted by these methods can vary widely, they all offer humans a nearly equivalent depth of understanding. This enables users to discern and categorize images efficiently, reinforcing the value of these methods in enhancing AI transparency.