 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023
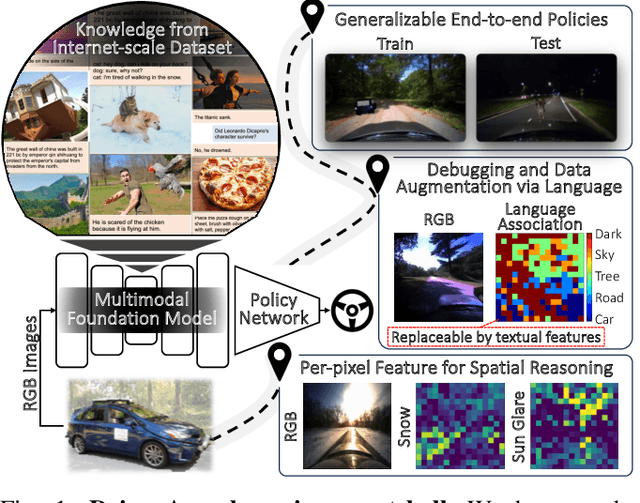
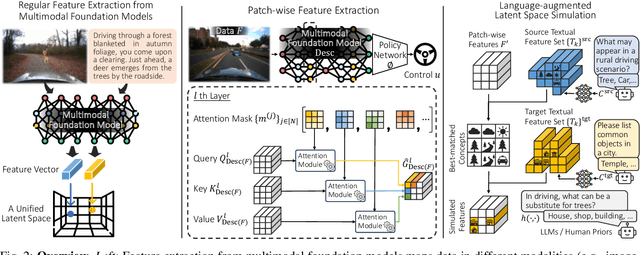
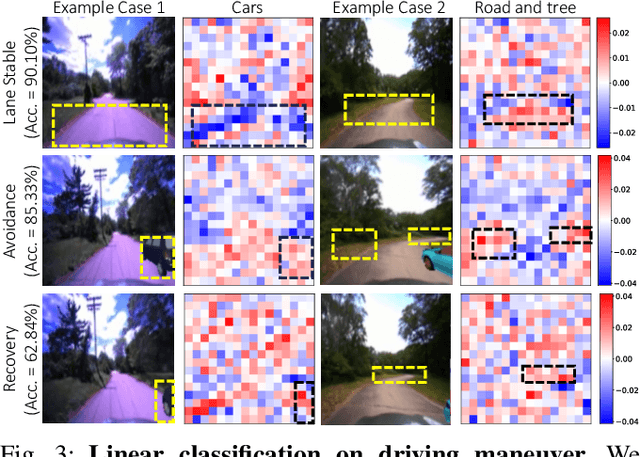
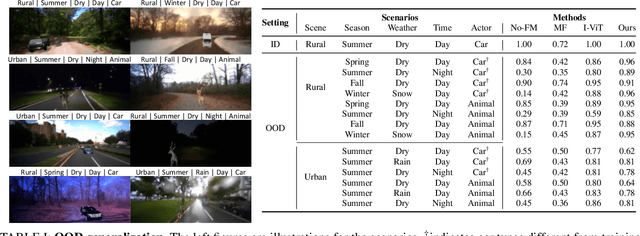
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
VLIS: Unimodal Language Models Guide Multimodal Language Generation
Oct 15, 2023Multimodal language generation, which leverages the synergy of language and vision, is a rapidly expanding field. However, existing vision-language models face challenges in tasks that require complex linguistic understanding. To address this issue, we introduce Visual-Language models as Importance Sampling weights (VLIS), a novel framework that combines the visual conditioning capability of vision-language models with the language understanding of unimodal text-only language models without further training. It extracts pointwise mutual information of each image and text from a visual-language model and uses the value as an importance sampling weight to adjust the token likelihood from a text-only model. VLIS improves vision-language models on diverse tasks, including commonsense understanding (WHOOPS, OK-VQA, and ScienceQA) and complex text generation (Concadia, Image Paragraph Captioning, and ROCStories). Our results suggest that VLIS represents a promising new direction for multimodal language generation.
Deep evidential fusion with uncertainty quantification and contextual discounting for multimodal medical image segmentation
Sep 12, 2023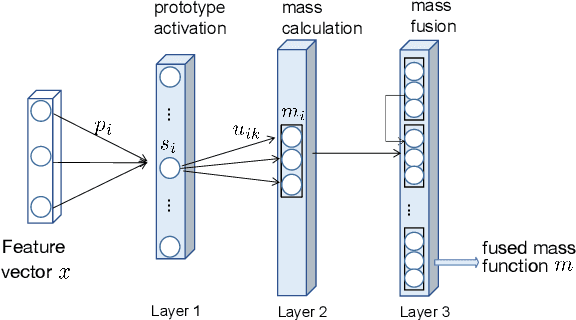
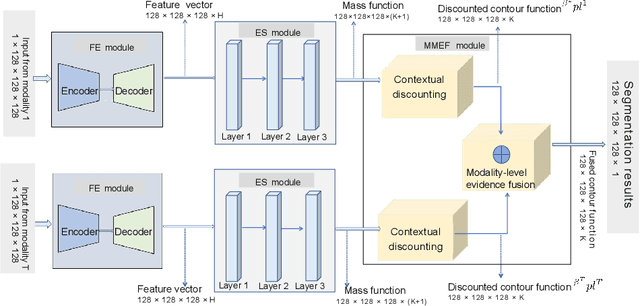
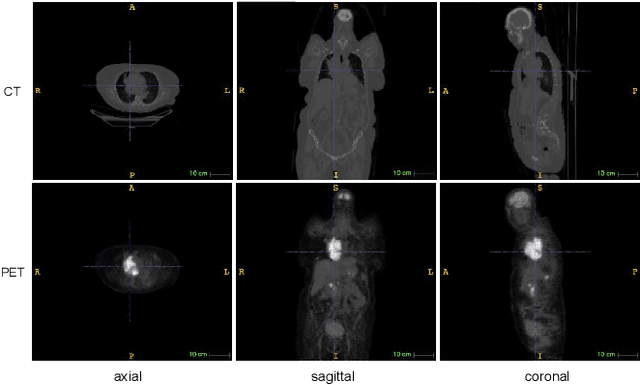
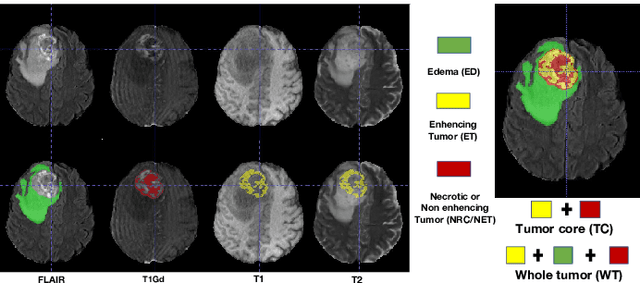
Single-modality medical images generally do not contain enough information to reach an accurate and reliable diagnosis. For this reason, physicians generally diagnose diseases based on multimodal medical images such as, e.g., PET/CT. The effective fusion of multimodal information is essential to reach a reliable decision and explain how the decision is made as well. In this paper, we propose a fusion framework for multimodal medical image segmentation based on deep learning and the Dempster-Shafer theory of evidence. In this framework, the reliability of each single modality image when segmenting different objects is taken into account by a contextual discounting operation. The discounted pieces of evidence from each modality are then combined by Dempster's rule to reach a final decision. Experimental results with a PET-CT dataset with lymphomas and a multi-MRI dataset with brain tumors show that our method outperforms the state-of-the-art methods in accuracy and reliability.
Contrastive Grouping with Transformer for Referring Image Segmentation
Sep 02, 2023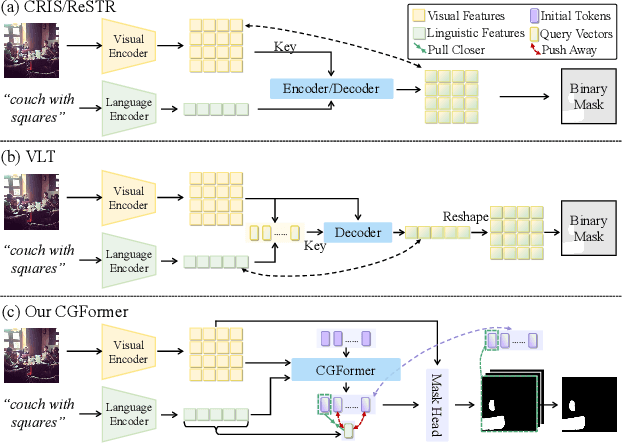
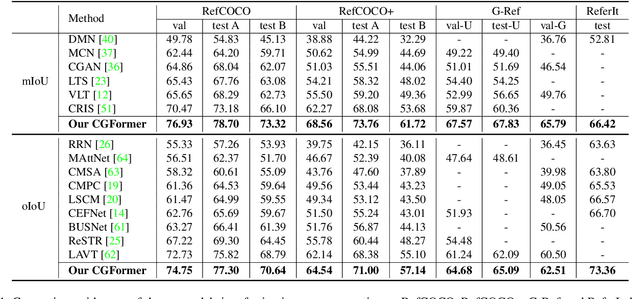
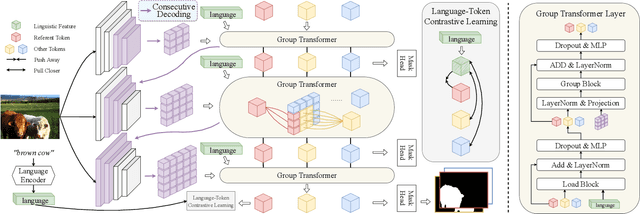
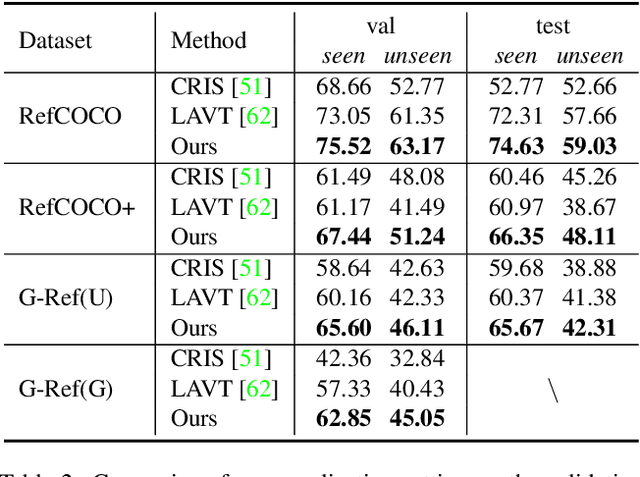
Referring image segmentation aims to segment the target referent in an image conditioning on a natural language expression. Existing one-stage methods employ per-pixel classification frameworks, which attempt straightforwardly to align vision and language at the pixel level, thus failing to capture critical object-level information. In this paper, we propose a mask classification framework, Contrastive Grouping with Transformer network (CGFormer), which explicitly captures object-level information via token-based querying and grouping strategy. Specifically, CGFormer first introduces learnable query tokens to represent objects and then alternately queries linguistic features and groups visual features into the query tokens for object-aware cross-modal reasoning. In addition, CGFormer achieves cross-level interaction by jointly updating the query tokens and decoding masks in every two consecutive layers. Finally, CGFormer cooperates contrastive learning to the grouping strategy to identify the token and its mask corresponding to the referent. Experimental results demonstrate that CGFormer outperforms state-of-the-art methods in both segmentation and generalization settings consistently and significantly.
The BLA Benchmark: Investigating Basic Language Abilities of Pre-Trained Multimodal Models
Oct 23, 2023Despite the impressive performance achieved by pre-trained language-and-vision models in downstream tasks, it remains an open question whether this reflects a proper understanding of image-text interaction. In this work, we explore to what extent they handle basic linguistic constructions -- active-passive voice, coordination, and relative clauses -- that even preschool children can typically master. We present BLA, a novel, automatically constructed benchmark to evaluate multimodal models on these Basic Language Abilities. We show that different types of Transformer-based systems, such as CLIP, ViLBERT, and BLIP2, generally struggle with BLA in a zero-shot setting, in line with previous findings. Our experiments, in particular, show that most of the tested models only marginally benefit when fine-tuned or prompted with construction-specific samples. Yet, the generative BLIP2 shows promising trends, especially in an in-context learning setting. This opens the door to using BLA not only as an evaluation benchmark but also to improve models' basic language abilities.
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 23, 2023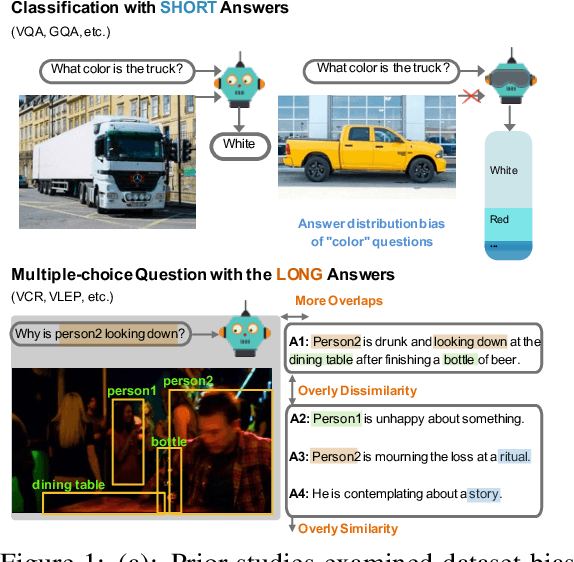
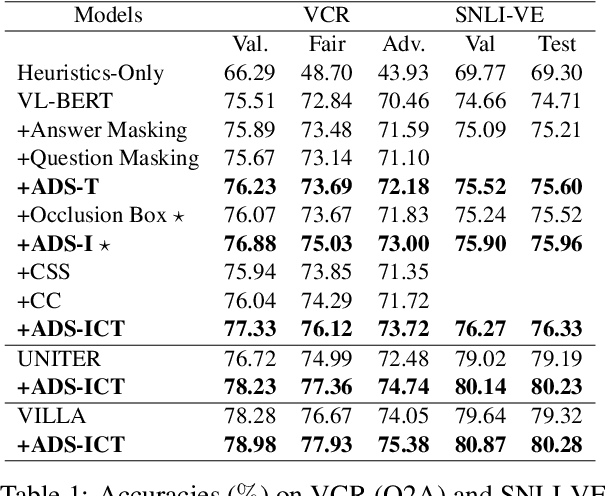
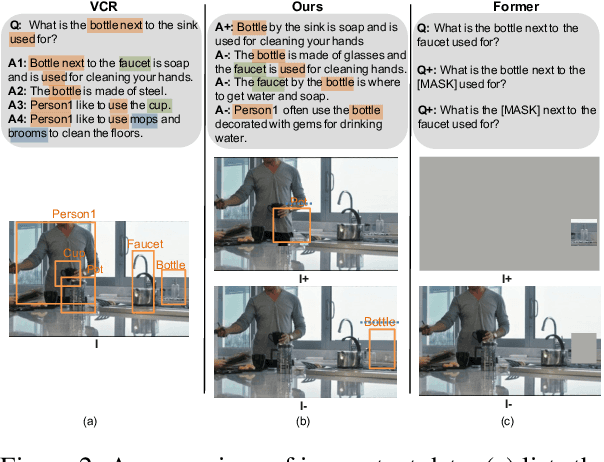
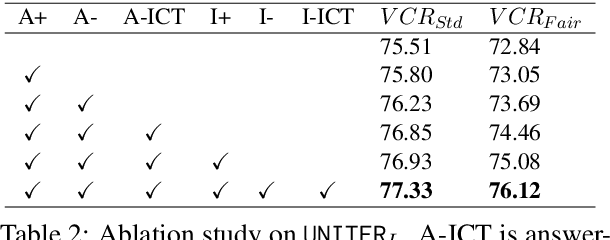
Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023
XTSC-Bench: Quantitative Benchmarking for Explainers on Time Series Classification
Oct 23, 2023Despite the growing body of work on explainable machine learning in time series classification (TSC), it remains unclear how to evaluate different explainability methods. Resorting to qualitative assessment and user studies to evaluate explainers for TSC is difficult since humans have difficulties understanding the underlying information contained in time series data. Therefore, a systematic review and quantitative comparison of explanation methods to confirm their correctness becomes crucial. While steps to standardized evaluations were taken for tabular, image, and textual data, benchmarking explainability methods on time series is challenging due to a) traditional metrics not being directly applicable, b) implementation and adaption of traditional metrics for time series in the literature vary, and c) varying baseline implementations. This paper proposes XTSC-Bench, a benchmarking tool providing standardized datasets, models, and metrics for evaluating explanation methods on TSC. We analyze 3 perturbation-, 6 gradient- and 2 example-based explanation methods to TSC showing that improvements in the explainers' robustness and reliability are necessary, especially for multivariate data.
Joint Non-Linear MRI Inversion with Diffusion Priors
Oct 23, 2023Magnetic resonance imaging (MRI) is a potent diagnostic tool, but suffers from long examination times. To accelerate the process, modern MRI machines typically utilize multiple coils that acquire sub-sampled data in parallel. Data-driven reconstruction approaches, in particular diffusion models, recently achieved remarkable success in reconstructing these data, but typically rely on estimating the coil sensitivities in an off-line step. This suffers from potential movement and misalignment artifacts and limits the application to Cartesian sampling trajectories. To obviate the need for off-line sensitivity estimation, we propose to jointly estimate the sensitivity maps with the image. In particular, we utilize a diffusion model -- trained on magnitude images only -- to generate high-fidelity images while imposing spatial smoothness of the sensitivity maps in the reverse diffusion. The proposed approach demonstrates consistent qualitative and quantitative performance across different sub-sampling patterns. In addition, experiments indicate a good fit of the estimated coil sensitivities.
Meaning Representations from Trajectories in Autoregressive Models
Oct 23, 2023We propose to extract meaning representations from autoregressive language models by considering the distribution of all possible trajectories extending an input text. This strategy is prompt-free, does not require fine-tuning, and is applicable to any pre-trained autoregressive model. Moreover, unlike vector-based representations, distribution-based representations can also model asymmetric relations (e.g., direction of logical entailment, hypernym/hyponym relations) by using algebraic operations between likelihood functions. These ideas are grounded in distributional perspectives on semantics and are connected to standard constructions in automata theory, but to our knowledge they have not been applied to modern language models. We empirically show that the representations obtained from large models align well with human annotations, outperform other zero-shot and prompt-free methods on semantic similarity tasks, and can be used to solve more complex entailment and containment tasks that standard embeddings cannot handle. Finally, we extend our method to represent data from different modalities (e.g., image and text) using multimodal autoregressive models.
LLM4SGG: Large Language Model for Weakly Supervised Scene Graph Generation
Oct 20, 2023Weakly-Supervised Scene Graph Generation (WSSGG) research has recently emerged as an alternative to the fully-supervised approach that heavily relies on costly annotations. In this regard, studies on WSSGG have utilized image captions to obtain unlocalized triplets while primarily focusing on grounding the unlocalized triplets over image regions. However, they have overlooked the two issues involved in the triplet formation process from the captions: 1) Semantic over-simplification issue arises when extracting triplets from captions, where fine-grained predicates in captions are undesirably converted into coarse-grained predicates, resulting in a long-tailed predicate distribution, and 2) Low-density scene graph issue arises when aligning the triplets in the caption with entity/predicate classes of interest, where many triplets are discarded and not used in training, leading to insufficient supervision. To tackle the two issues, we propose a new approach, i.e., Large Language Model for weakly-supervised SGG (LLM4SGG), where we mitigate the two issues by leveraging the LLM's in-depth understanding of language and reasoning ability during the extraction of triplets from captions and alignment of entity/predicate classes with target data. To further engage the LLM in these processes, we adopt the idea of Chain-of-Thought and the in-context few-shot learning strategy. To validate the effectiveness of LLM4SGG, we conduct extensive experiments on Visual Genome and GQA datasets, showing significant improvements in both Recall@K and mean Recall@K compared to the state-of-the-art WSSGG methods. A further appeal is that LLM4SGG is data-efficient, enabling effective model training with a small amount of training images.