 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text Similarity from Image Contents using Statistical and Semantic Analysis Techniques
Aug 24, 2023
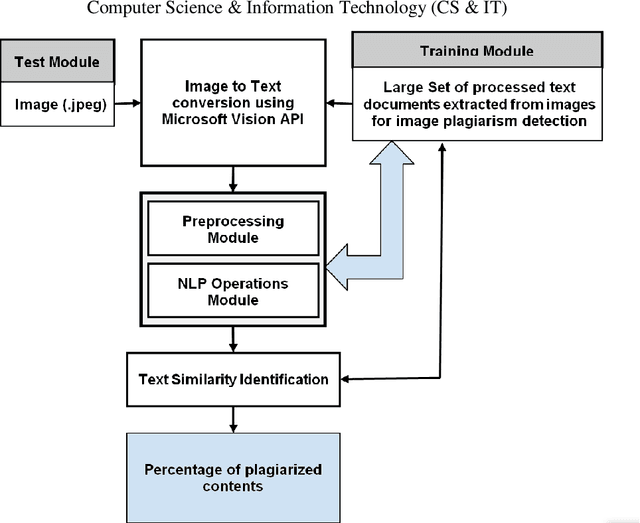
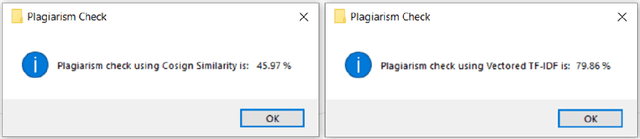
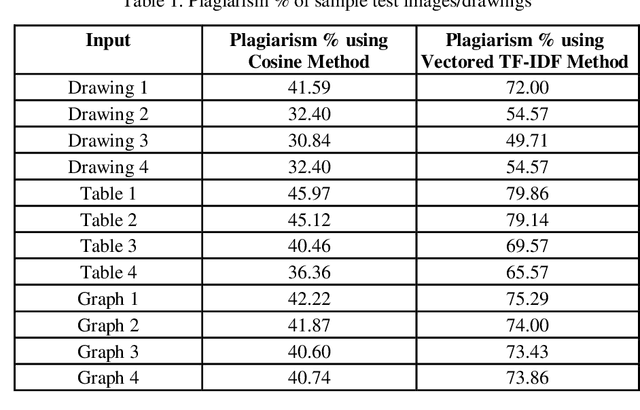
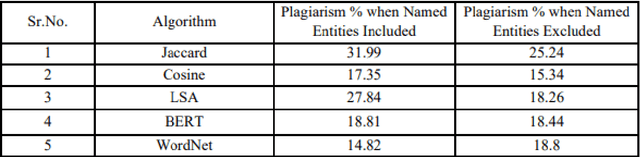
Plagiarism detection is one of the most researched areas among the Natural Language Processing(NLP) community. A good plagiarism detection covers all the NLP methods including semantics, named entities, paraphrases etc. and produces detailed plagiarism reports. Detection of Cross Lingual Plagiarism requires deep knowledge of various advanced methods and algorithms to perform effective text similarity checking. Nowadays the plagiarists are also advancing themselves from hiding the identity from being catch in such offense. The plagiarists are bypassed from being detected with techniques like paraphrasing, synonym replacement, mismatching citations, translating one language to another. Image Content Plagiarism Detection (ICPD) has gained importance, utilizing advanced image content processing to identify instances of plagiarism to ensure the integrity of image content. The issue of plagiarism extends beyond textual content, as images such as figures, graphs, and tables also have the potential to be plagiarized. However, image content plagiarism detection remains an unaddressed challenge. Therefore, there is a critical need to develop methods and systems for detecting plagiarism in image content. In this paper, the system has been implemented to detect plagiarism form contents of Images such as Figures, Graphs, Tables etc. Along with statistical algorithms such as Jaccard and Cosine, introducing semantic algorithms such as LSA, BERT, WordNet outperformed in detecting efficient and accurate plagiarism.
HNAS-reg: hierarchical neural architecture search for deformable medical image registration
Aug 23, 2023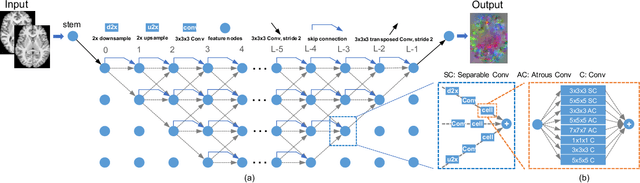
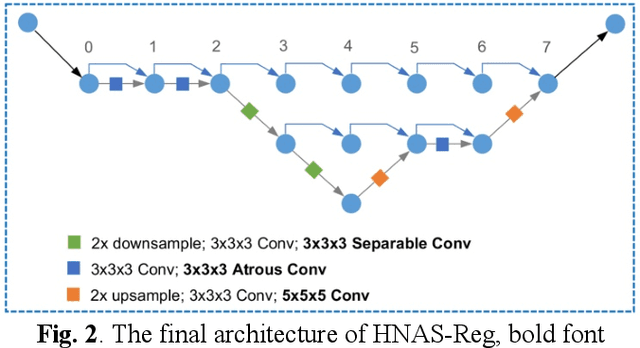
Convolutional neural networks (CNNs) have been widely used to build deep learning models for medical image registration, but manually designed network architectures are not necessarily optimal. This paper presents a hierarchical NAS framework (HNAS-Reg), consisting of both convolutional operation search and network topology search, to identify the optimal network architecture for deformable medical image registration. To mitigate the computational overhead and memory constraints, a partial channel strategy is utilized without losing optimization quality. Experiments on three datasets, consisting of 636 T1-weighted magnetic resonance images (MRIs), have demonstrated that the proposal method can build a deep learning model with improved image registration accuracy and reduced model size, compared with state-of-the-art image registration approaches, including one representative traditional approach and two unsupervised learning-based approaches.
Cousins Of The Vendi Score: A Family Of Similarity-Based Diversity Metrics For Science And Machine Learning
Oct 19, 2023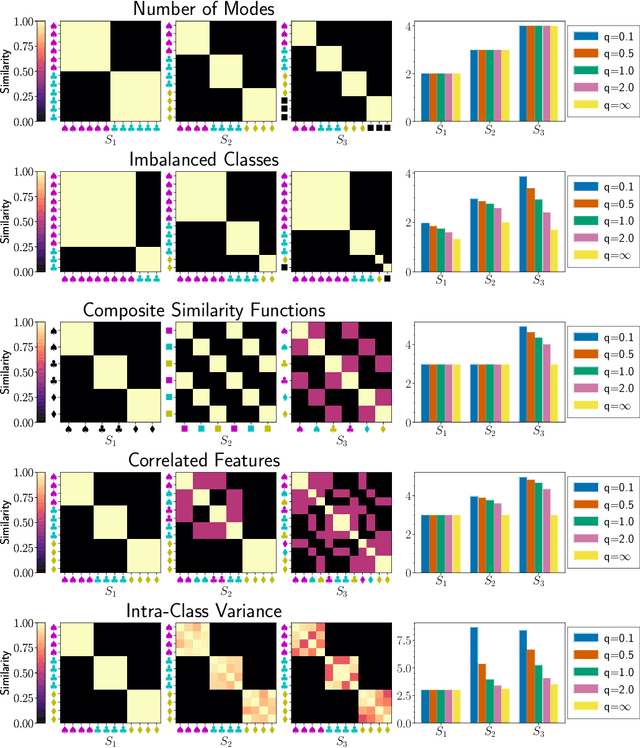
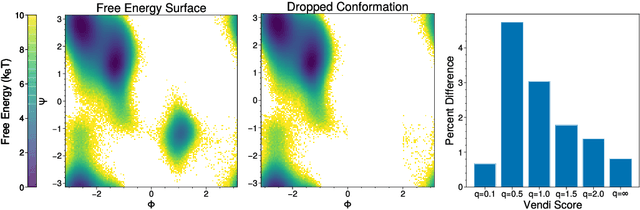
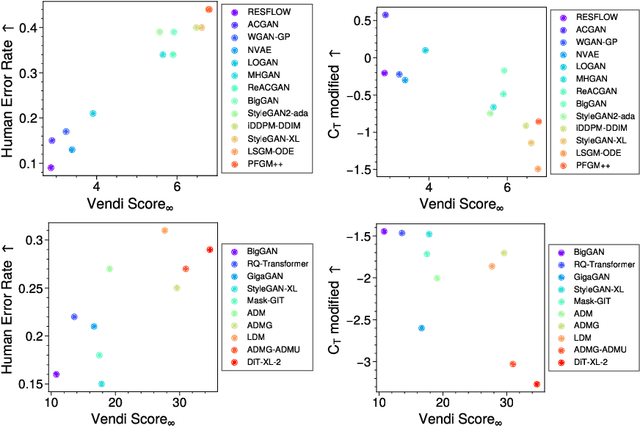
Measuring diversity accurately is important for many scientific fields, including machine learning (ML), ecology, and chemistry. The Vendi Score was introduced as a generic similarity-based diversity metric that extends the Hill number of order q=1 by leveraging ideas from quantum statistical mechanics. Contrary to many diversity metrics in ecology, the Vendi Score accounts for similarity and does not require knowledge of the prevalence of the categories in the collection to be evaluated for diversity. However, the Vendi Score treats each item in a given collection with a level of sensitivity proportional to the item's prevalence. This is undesirable in settings where there is a significant imbalance in item prevalence. In this paper, we extend the other Hill numbers using similarity to provide flexibility in allocating sensitivity to rare or common items. This leads to a family of diversity metrics -- Vendi scores with different levels of sensitivity -- that can be used in a variety of applications. We study the properties of the scores in a synthetic controlled setting where the ground truth diversity is known. We then test their utility in improving molecular simulations via Vendi Sampling. Finally, we use the Vendi scores to better understand the behavior of image generative models in terms of memorization, duplication, diversity, and sample quality.
Rethinking Image Forgery Detection via Contrastive Learning and Unsupervised Clustering
Aug 18, 2023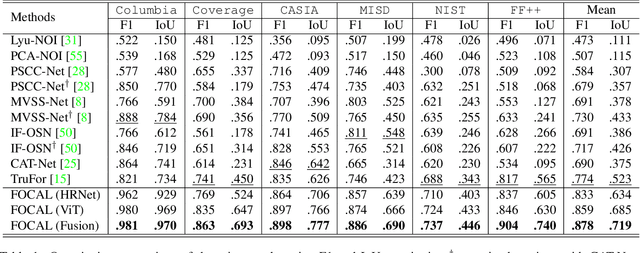

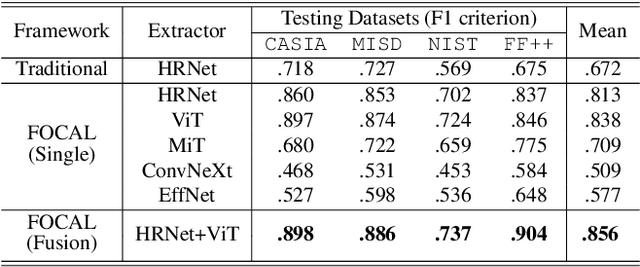
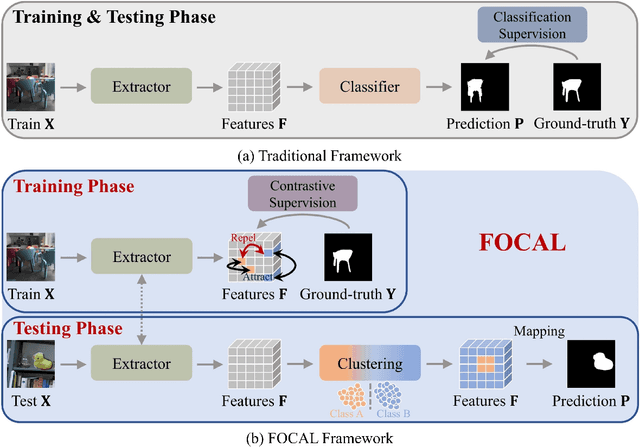
Image forgery detection aims to detect and locate forged regions in an image. Most existing forgery detection algorithms formulate classification problems to classify pixels into forged or pristine. However, the definition of forged and pristine pixels is only relative within one single image, e.g., a forged region in image A is actually a pristine one in its source image B (splicing forgery). Such a relative definition has been severely overlooked by existing methods, which unnecessarily mix forged (pristine) regions across different images into the same category. To resolve this dilemma, we propose the FOrensic ContrAstive cLustering (FOCAL) method, a novel, simple yet very effective paradigm based on contrastive learning and unsupervised clustering for the image forgery detection. Specifically, FOCAL 1) utilizes pixel-level contrastive learning to supervise the high-level forensic feature extraction in an image-by-image manner, explicitly reflecting the above relative definition; 2) employs an on-the-fly unsupervised clustering algorithm (instead of a trained one) to cluster the learned features into forged/pristine categories, further suppressing the cross-image influence from training data; and 3) allows to further boost the detection performance via simple feature-level concatenation without the need of retraining. Extensive experimental results over six public testing datasets demonstrate that our proposed FOCAL significantly outperforms the state-of-the-art competing algorithms by big margins: +24.3% on Coverage, +18.6% on Columbia, +17.5% on FF++, +14.2% on MISD, +13.5% on CASIA and +10.3% on NIST in terms of IoU. The paradigm of FOCAL could bring fresh insights and serve as a novel benchmark for the image forgery detection task. The code is available at https://github.com/HighwayWu/FOCAL.
A flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023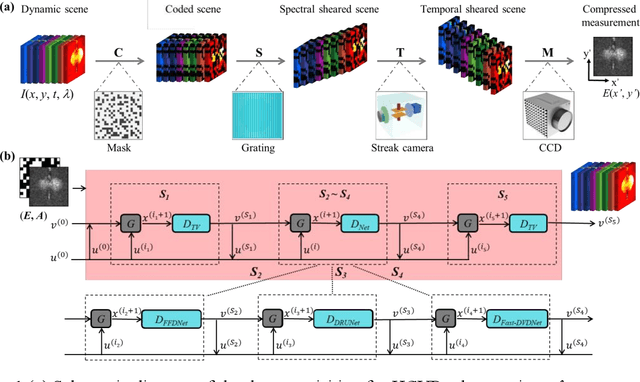
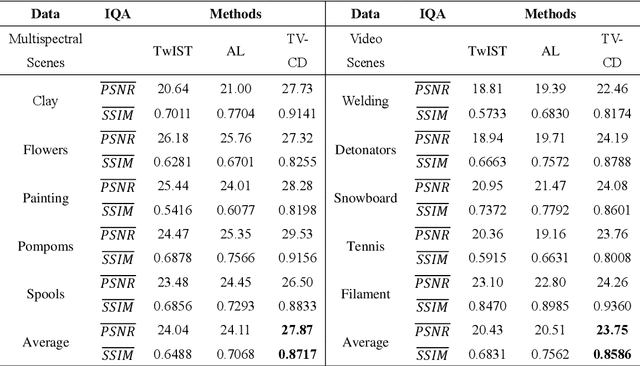
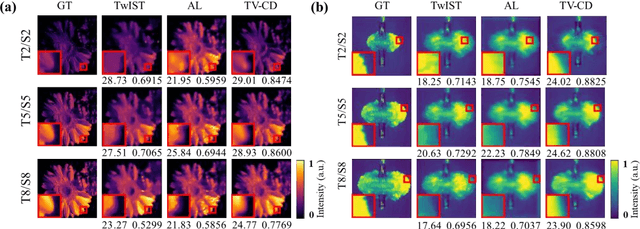
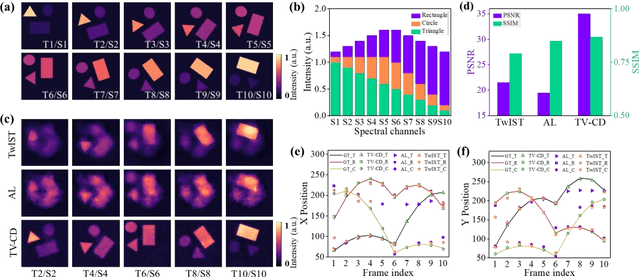
Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 29, 2023

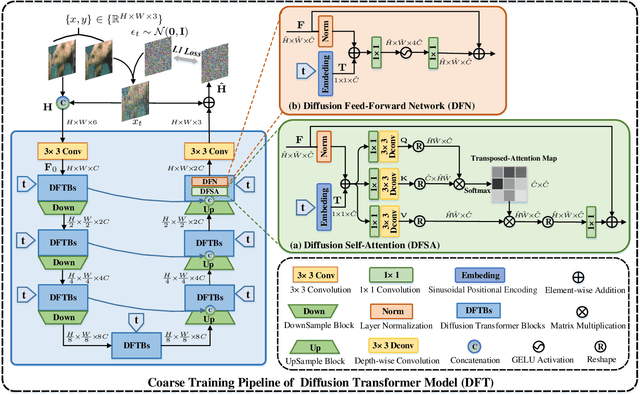
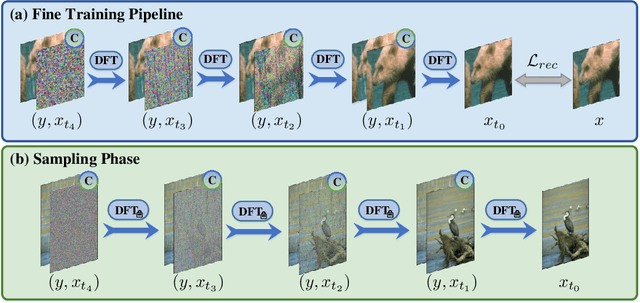
Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising. The code is available at https://github.com/wlydlut/C2F-DFT.
DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics
Oct 20, 2023Diffusion probabilistic models (DPMs) have exhibited excellent performance for high-fidelity image generation while suffering from inefficient sampling. Recent works accelerate the sampling procedure by proposing fast ODE solvers that leverage the specific ODE form of DPMs. However, they highly rely on specific parameterization during inference (such as noise/data prediction), which might not be the optimal choice. In this work, we propose a novel formulation towards the optimal parameterization during sampling that minimizes the first-order discretization error of the ODE solution. Based on such formulation, we propose \textit{DPM-Solver-v3}, a new fast ODE solver for DPMs by introducing several coefficients efficiently computed on the pretrained model, which we call \textit{empirical model statistics}. We further incorporate multistep methods and a predictor-corrector framework, and propose some techniques for improving sample quality at small numbers of function evaluations (NFE) or large guidance scales. Experiments show that DPM-Solver-v3 achieves consistently better or comparable performance in both unconditional and conditional sampling with both pixel-space and latent-space DPMs, especially in 5$\sim$10 NFEs. We achieve FIDs of 12.21 (5 NFE), 2.51 (10 NFE) on unconditional CIFAR10, and MSE of 0.55 (5 NFE, 7.5 guidance scale) on Stable Diffusion, bringing a speed-up of 15\%$\sim$30\% compared to previous state-of-the-art training-free methods. Code is available at \url{https://github.com/thu-ml/DPM-Solver-v3}.
Accelerated sparse Kernel Spectral Clustering for large scale data clustering problems
Oct 20, 2023An improved version of the sparse multiway kernel spectral clustering (KSC) is presented in this brief. The original algorithm is derived from weighted kernel principal component (KPCA) analysis formulated within the primal-dual least-squares support vector machine (LS-SVM) framework. Sparsity is achieved then by the combination of the incomplete Cholesky decomposition (ICD) based low rank approximation of the kernel matrix with the so called reduced set method. The original ICD based sparse KSC algorithm was reported to be computationally far too demanding, especially when applied on large scale data clustering problems that actually it was designed for, which has prevented to gain more than simply theoretical relevance so far. This is altered by the modifications reported in this brief that drastically improve the computational characteristics. Solving the alternative, symmetrized version of the computationally most demanding core eigenvalue problem eliminates the necessity of forming and SVD of large matrices during the model construction. This results in solving clustering problems now within seconds that were reported to require hours without altering the results. Furthermore, sparsity is also improved significantly, leading to more compact model representation, increasing further not only the computational efficiency but also the descriptive power. These transform the original, only theoretically relevant ICD based sparse KSC algorithm applicable for large scale practical clustering problems. Theoretical results and improvements are demonstrated by computational experiments on carefully selected synthetic data as well as on real life problems such as image segmentation.
Longer-range Contextualized Masked Autoencoder
Oct 20, 2023Masked image modeling (MIM) has emerged as a promising self-supervised learning (SSL) strategy. The MIM pre-training facilitates learning powerful representations using an encoder-decoder framework by randomly masking some input pixels and reconstructing the masked pixels from the remaining ones. However, as the encoder is trained with partial pixels, the MIM pre-training can suffer from a low capability of understanding long-range dependency. This limitation may hinder its capability to fully understand multiple-range dependencies, resulting in narrow highlighted regions in the attention map that may incur accuracy drops. To mitigate the limitation, We propose a self-supervised learning framework, named Longer-range Contextualized Masked Autoencoder (LC-MAE). LC-MAE effectively leverages a global context understanding of visual representations while simultaneously reducing the spatial redundancy of input at the same time. Our method steers the encoder to learn from entire pixels in multiple views while also learning local representation from sparse pixels. As a result, LC-MAE learns more discriminative representations, leading to a performance improvement of achieving 84.2% top-1 accuracy with ViT-B on ImageNet-1K with 0.6%p gain. We attribute the success to the enhanced pre-training method, as evidenced by the singular value spectrum and attention analyses. Finally, LC-MAE achieves significant performance gains at the downstream semantic segmentation and fine-grained visual classification tasks; and on diverse robust evaluation metrics. Our code will be publicly available.
Ranking-aware Uncertainty for Text-guided Image Retrieval
Aug 16, 2023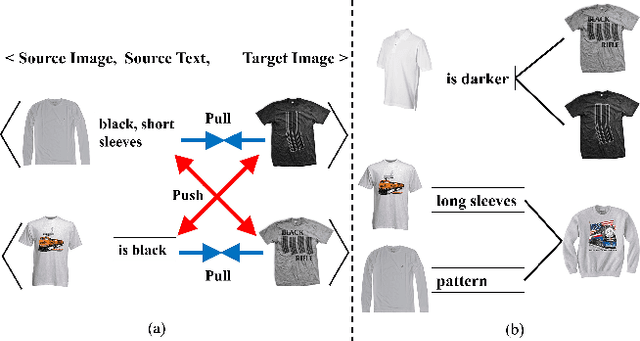
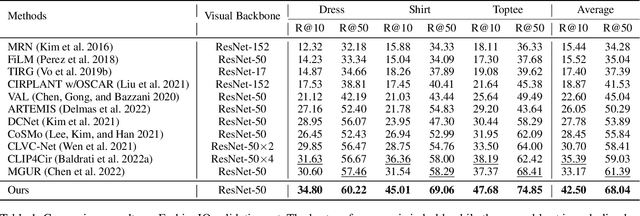
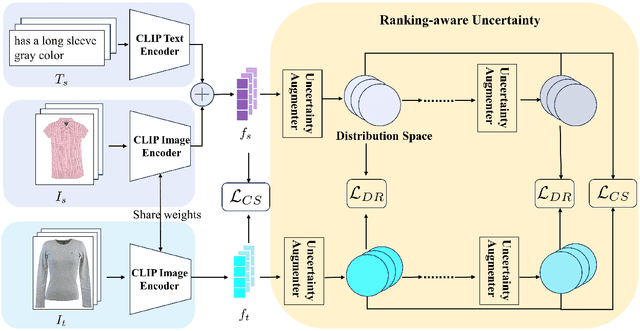
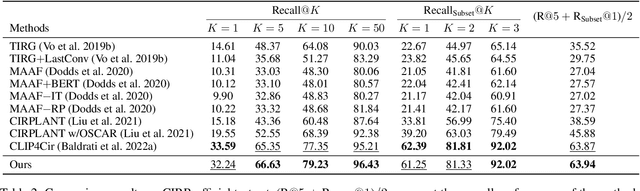
Text-guided image retrieval is to incorporate conditional text to better capture users' intent. Traditionally, the existing methods focus on minimizing the embedding distances between the source inputs and the targeted image, using the provided triplets $\langle$source image, source text, target image$\rangle$. However, such triplet optimization may limit the learned retrieval model to capture more detailed ranking information, e.g., the triplets are one-to-one correspondences and they fail to account for many-to-many correspondences arising from semantic diversity in feedback languages and images. To capture more ranking information, we propose a novel ranking-aware uncertainty approach to model many-to-many correspondences by only using the provided triplets. We introduce uncertainty learning to learn the stochastic ranking list of features. Specifically, our approach mainly comprises three components: (1) In-sample uncertainty, which aims to capture semantic diversity using a Gaussian distribution derived from both combined and target features; (2) Cross-sample uncertainty, which further mines the ranking information from other samples' distributions; and (3) Distribution regularization, which aligns the distributional representations of source inputs and targeted image. Compared to the existing state-of-the-art methods, our proposed method achieves significant results on two public datasets for composed image retrieval.