 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Content Bias in Deep Learning Age Approximation: A new Approach Towards more Explainability
Oct 03, 2023



In the context of temporal image forensics, it is not evident that a neural network, trained on images from different time-slots (classes), exploit solely age related features. Usually, images taken in close temporal proximity (e.g., belonging to the same age class) share some common content properties. Such content bias can be exploited by a neural network. In this work, a novel approach that evaluates the influence of image content is proposed. This approach is verified using synthetic images (where content bias can be ruled out) with an age signal embedded. Based on the proposed approach, it is shown that a `standard' neural network trained in the context of age classification is strongly dependent on image content. As a potential countermeasure, two different techniques are applied to mitigate the influence of the image content during training, and they are also evaluated by the proposed method.
KAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
Oct 16, 2023This paper proposes a method for hiding the least-important samples during the training of deep neural networks to increase efficiency, i.e., to reduce the cost of training. Using information about the loss and prediction confidence during training, we adaptively find samples to exclude in a given epoch based on their contribution to the overall learning process, without significantly degrading accuracy. We explore the converge properties when accounting for the reduction in the number of SGD updates. Empirical results on various large-scale datasets and models used directly in image classification and segmentation show that while the with-replacement importance sampling algorithm performs poorly on large datasets, our method can reduce total training time by up to 22% impacting accuracy only by 0.4% compared to the baseline. Code available at https://github.com/TruongThaoNguyen/kakurenbo
A Non-monotonic Smooth Activation Function
Oct 16, 2023Activation functions are crucial in deep learning models since they introduce non-linearity into the networks, allowing them to learn from errors and make adjustments, which is essential for learning complex patterns. The essential purpose of activation functions is to transform unprocessed input signals into significant output activations, promoting information transmission throughout the neural network. In this study, we propose a new activation function called Sqish, which is a non-monotonic and smooth function and an alternative to existing ones. We showed its superiority in classification, object detection, segmentation tasks, and adversarial robustness experiments. We got an 8.21% improvement over ReLU on the CIFAR100 dataset with the ShuffleNet V2 model in the FGSM adversarial attack. We also got a 5.87% improvement over ReLU on image classification on the CIFAR100 dataset with the ShuffleNet V2 model.
Rapid Non-cartesian Reconstruction Using an Implicit Representation of GROG Kernels
Oct 16, 2023MRI data is acquired in Fourier space. Data acquisition is typically performed on a Cartesian grid in this space to enable the use of a fast Fourier transform algorithm to achieve fast and efficient reconstruction. However, it has been shown that for multiple applications, non-Cartesian data acquisition can improve the performance of MR imaging by providing fast and more efficient data acquisition, and improving motion robustness. Nonetheless, the image reconstruction process of non-Cartesian data is more involved and can be time-consuming, even through the use of efficient algorithms such as non-uniform FFT (NUFFT). This work provides an efficient approach (iGROG) to transform the non-Cartesian data into Cartesian data, to achieve simpler and faster reconstruction which should help enable non-Cartesian data sampling to be performed more widely in MRI.
Conditional Diffusion Distillation
Oct 02, 2023
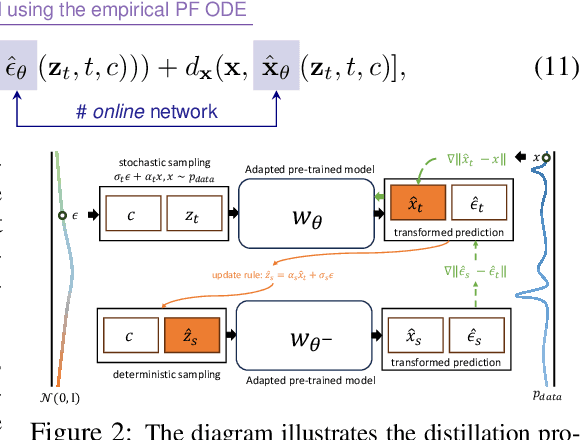

Generative diffusion models provide strong priors for text-to-image generation and thereby serve as a foundation for conditional generation tasks such as image editing, restoration, and super-resolution. However, one major limitation of diffusion models is their slow sampling time. To address this challenge, we present a novel conditional distillation method designed to supplement the diffusion priors with the help of image conditions, allowing for conditional sampling with very few steps. We directly distill the unconditional pre-training in a single stage through joint-learning, largely simplifying the previous two-stage procedures that involve both distillation and conditional finetuning separately. Furthermore, our method enables a new parameter-efficient distillation mechanism that distills each task with only a small number of additional parameters combined with the shared frozen unconditional backbone. Experiments across multiple tasks including super-resolution, image editing, and depth-to-image generation demonstrate that our method outperforms existing distillation techniques for the same sampling time. Notably, our method is the first distillation strategy that can match the performance of the much slower fine-tuned conditional diffusion models.
Developing a Novel Image Marker to Predict the Responses of Neoadjuvant Chemotherapy (NACT) for Ovarian Cancer Patients
Sep 13, 2023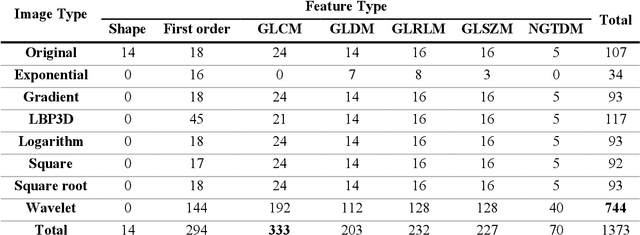
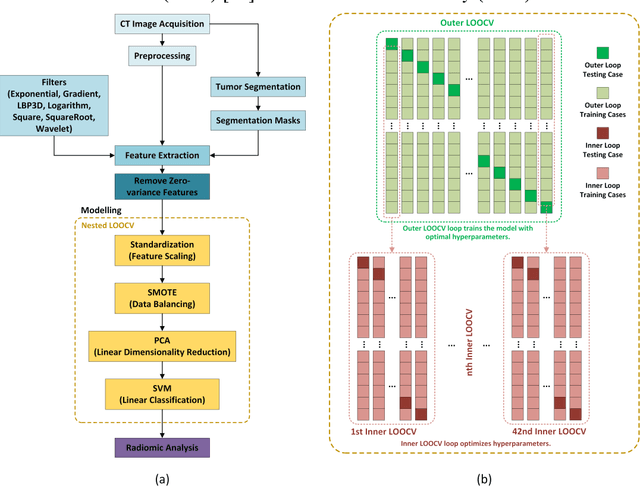
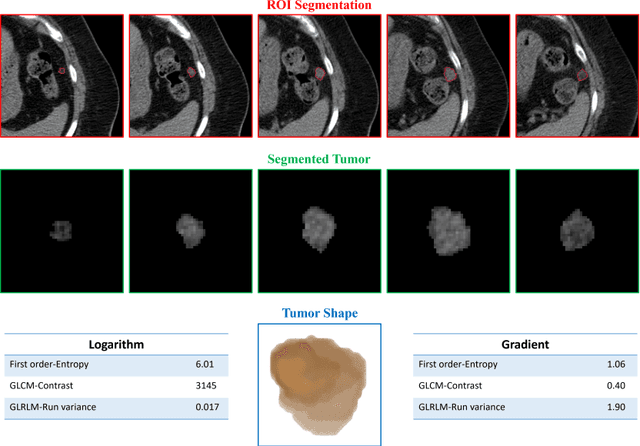
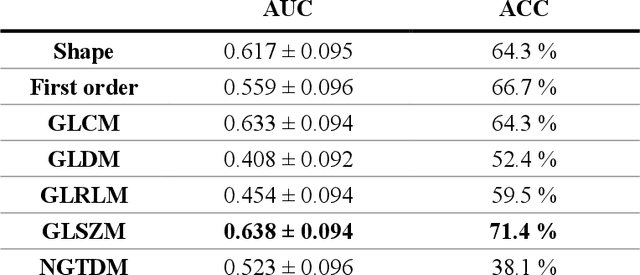
Objective: Neoadjuvant chemotherapy (NACT) is one kind of treatment for advanced stage ovarian cancer patients. However, due to the nature of tumor heterogeneity, the patients' responses to NACT varies significantly among different subgroups. To address this clinical challenge, the purpose of this study is to develop a novel image marker to achieve high accuracy response prediction of the NACT at an early stage. Methods: For this purpose, we first computed a total of 1373 radiomics features to quantify the tumor characteristics, which can be grouped into three categories: geometric, intensity, and texture features. Second, all these features were optimized by principal component analysis algorithm to generate a compact and informative feature cluster. Using this cluster as the input, an SVM based classifier was developed and optimized to create a final marker, indicating the likelihood of the patient being responsive to the NACT treatment. To validate this scheme, a total of 42 ovarian cancer patients were retrospectively collected. A nested leave-one-out cross-validation was adopted for model performance assessment. Results: The results demonstrate that the new method yielded an AUC (area under the ROC [receiver characteristic operation] curve) of 0.745. Meanwhile, the model achieved overall accuracy of 76.2%, positive predictive value of 70%, and negative predictive value of 78.1%. Conclusion: This study provides meaningful information for the development of radiomics based image markers in NACT response prediction.
From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models
Oct 13, 2023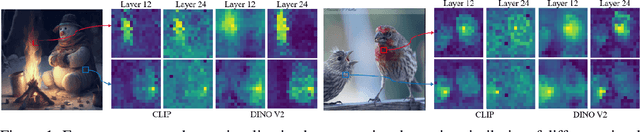
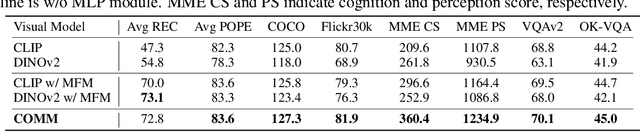
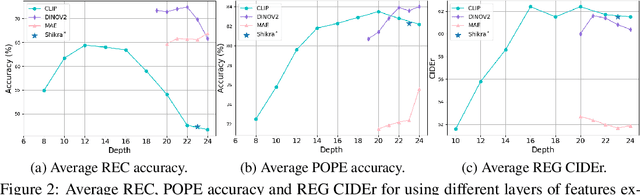
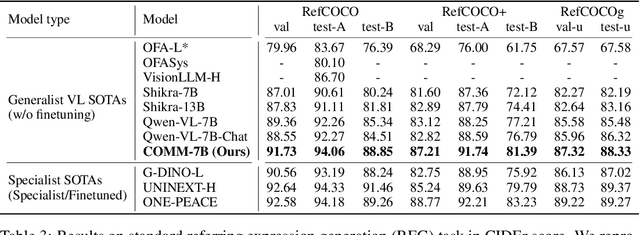
Multi-modal Large Language Models (MLLMs) have made significant strides in expanding the capabilities of Large Language Models (LLMs) through the incorporation of visual perception interfaces. Despite the emergence of exciting applications and the availability of diverse instruction tuning data, existing approaches often rely on CLIP or its variants as the visual branch, and merely extract features from the deep layers. However, these methods lack a comprehensive analysis of the visual encoders in MLLMs. In this paper, we conduct an extensive investigation into the effectiveness of different vision encoders within MLLMs. Our findings reveal that the shallow layer features of CLIP offer particular advantages for fine-grained tasks such as grounding and region understanding. Surprisingly, the vision-only model DINO, which is not pretrained with text-image alignment, demonstrates promising performance as a visual branch within MLLMs. By simply equipping it with an MLP layer for alignment, DINO surpasses CLIP in fine-grained related perception tasks. Building upon these observations, we propose a simple yet effective feature merging strategy, named COMM, that integrates CLIP and DINO with Multi-level features Merging, to enhance the visual capabilities of MLLMs. We evaluate COMM through comprehensive experiments on a wide range of benchmarks, including image captioning, visual question answering, visual grounding, and object hallucination. Experimental results demonstrate the superior performance of COMM compared to existing methods, showcasing its enhanced visual capabilities within MLLMs. Code will be made available at https://github.com/YuchenLiu98/COMM.
DT/MARS-CycleGAN: Improved Object Detection for MARS Phenotyping Robot
Oct 20, 2023Robotic crop phenotyping has emerged as a key technology to assess crops' morphological and physiological traits at scale. These phenotypical measurements are essential for developing new crop varieties with the aim of increasing productivity and dealing with environmental challenges such as climate change. However, developing and deploying crop phenotyping robots face many challenges such as complex and variable crop shapes that complicate robotic object detection, dynamic and unstructured environments that baffle robotic control, and real-time computing and managing big data that challenge robotic hardware/software. This work specifically tackles the first challenge by proposing a novel Digital-Twin(DT)MARS-CycleGAN model for image augmentation to improve our Modular Agricultural Robotic System (MARS)'s crop object detection from complex and variable backgrounds. Our core idea is that in addition to the cycle consistency losses in the CycleGAN model, we designed and enforced a new DT-MARS loss in the deep learning model to penalize the inconsistency between real crop images captured by MARS and synthesized images sensed by DT MARS. Therefore, the generated synthesized crop images closely mimic real images in terms of realism, and they are employed to fine-tune object detectors such as YOLOv8. Extensive experiments demonstrated that our new DT/MARS-CycleGAN framework significantly boosts our MARS' crop object/row detector's performance, contributing to the field of robotic crop phenotyping.
Skin Lesion Segmentation Improved by Transformer-based Networks with Inter-scale Dependency Modeling
Oct 20, 2023Melanoma, a dangerous type of skin cancer resulting from abnormal skin cell growth, can be treated if detected early. Various approaches using Fully Convolutional Networks (FCNs) have been proposed, with the U-Net architecture being prominent To aid in its diagnosis through automatic skin lesion segmentation. However, the symmetrical U-Net model's reliance on convolutional operations hinders its ability to capture long-range dependencies crucial for accurate medical image segmentation. Several Transformer-based U-Net topologies have recently been created to overcome this limitation by replacing CNN blocks with different Transformer modules to capture local and global representations. Furthermore, the U-shaped structure is hampered by semantic gaps between the encoder and decoder. This study intends to increase the network's feature re-usability by carefully building the skip connection path. Integrating an already calculated attention affinity within the skip connection path improves the typical concatenation process utilized in the conventional skip connection path. As a result, we propose a U-shaped hierarchical Transformer-based structure for skin lesion segmentation and an Inter-scale Context Fusion (ISCF) method that uses attention correlations in each stage of the encoder to adaptively combine the contexts from each stage to mitigate semantic gaps. The findings from two skin lesion segmentation benchmarks support the ISCF module's applicability and effectiveness. The code is publicly available at \url{https://github.com/saniaesk/skin-lesion-segmentation}
SYRAC: Synthesize, Rank, and Count
Oct 11, 2023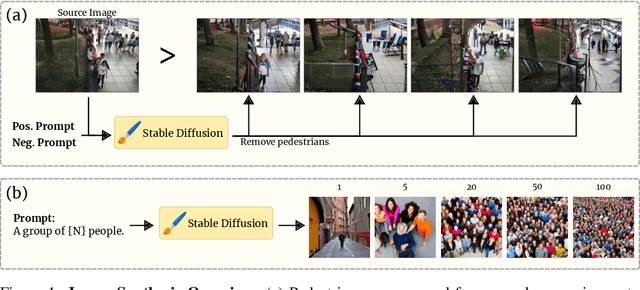
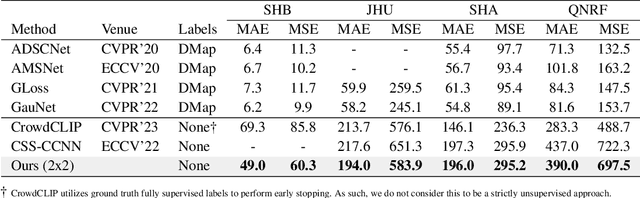


Crowd counting is a critical task in computer vision, with several important applications. However, existing counting methods rely on labor-intensive density map annotations, necessitating the manual localization of each individual pedestrian. While recent efforts have attempted to alleviate the annotation burden through weakly or semi-supervised learning, these approaches fall short of significantly reducing the workload. We propose a novel approach to eliminate the annotation burden by leveraging latent diffusion models to generate synthetic data. However, these models struggle to reliably understand object quantities, leading to noisy annotations when prompted to produce images with a specific quantity of objects. To address this, we use latent diffusion models to create two types of synthetic data: one by removing pedestrians from real images, which generates ranked image pairs with a weak but reliable object quantity signal, and the other by generating synthetic images with a predetermined number of objects, offering a strong but noisy counting signal. Our method utilizes the ranking image pairs for pre-training and then fits a linear layer to the noisy synthetic images using these crowd quantity features. We report state-of-the-art results for unsupervised crowd counting.