 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation
Oct 11, 2023
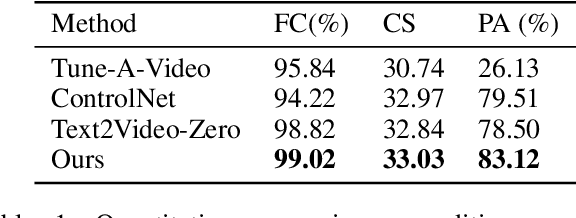
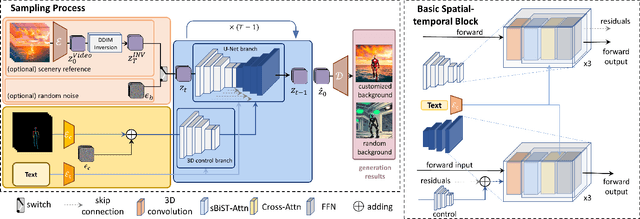
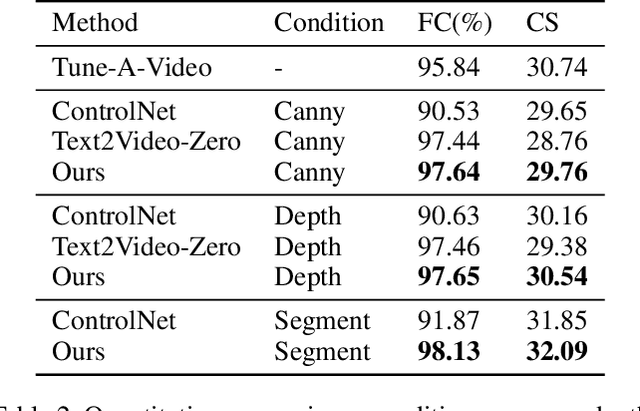
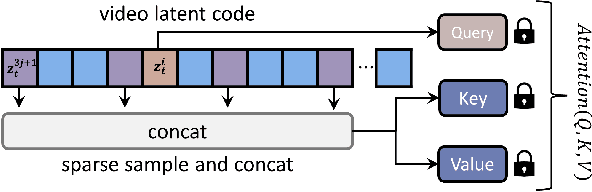
Recent works have successfully extended large-scale text-to-image models to the video domain, producing promising results but at a high computational cost and requiring a large amount of video data. In this work, we introduce ConditionVideo, a training-free approach to text-to-video generation based on the provided condition, video, and input text, by leveraging the power of off-the-shelf text-to-image generation methods (e.g., Stable Diffusion). ConditionVideo generates realistic dynamic videos from random noise or given scene videos. Our method explicitly disentangles the motion representation into condition-guided and scenery motion components. To this end, the ConditionVideo model is designed with a UNet branch and a control branch. To improve temporal coherence, we introduce sparse bi-directional spatial-temporal attention (sBiST-Attn). The 3D control network extends the conventional 2D controlnet model, aiming to strengthen conditional generation accuracy by additionally leveraging the bi-directional frames in the temporal domain. Our method exhibits superior performance in terms of frame consistency, clip score, and conditional accuracy, outperforming other compared methods.
Real-Fake: Effective Training Data Synthesis Through Distribution Matching
Oct 16, 2023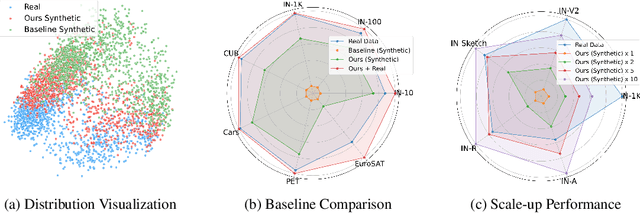
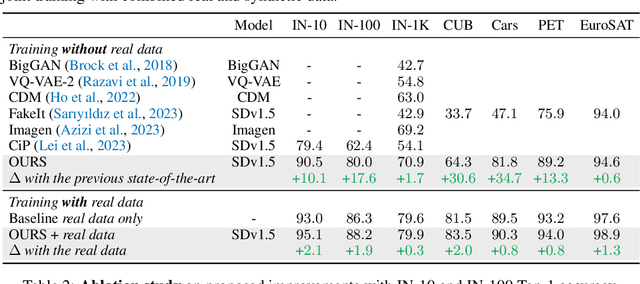
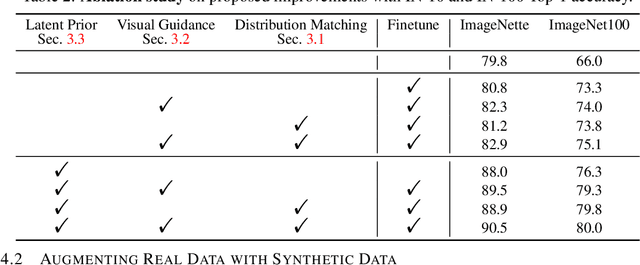
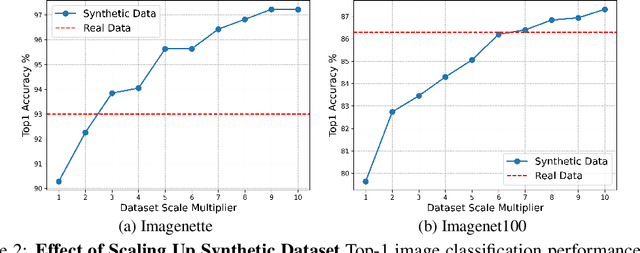
Synthetic training data has gained prominence in numerous learning tasks and scenarios, offering advantages such as dataset augmentation, generalization evaluation, and privacy preservation. Despite these benefits, the efficiency of synthetic data generated by current methodologies remains inferior when training advanced deep models exclusively, limiting its practical utility. To address this challenge, we analyze the principles underlying training data synthesis for supervised learning and elucidate a principled theoretical framework from the distribution-matching perspective that explicates the mechanisms governing synthesis efficacy. Through extensive experiments, we demonstrate the effectiveness of our synthetic data across diverse image classification tasks, both as a replacement for and augmentation to real datasets, while also benefits challenging tasks such as out-of-distribution generalization and privacy preservation.
VGDiffZero: Text-to-image Diffusion Models Can Be Zero-shot Visual Grounders
Sep 03, 2023Large-scale text-to-image diffusion models have shown impressive capabilities across various generative tasks, enabled by strong vision-language alignment obtained through pre-training. However, most vision-language discriminative tasks require extensive fine-tuning on carefully-labeled datasets to acquire such alignment, with great cost in time and computing resources. In this work, we explore directly applying a pre-trained generative diffusion model to the challenging discriminative task of visual grounding without any fine-tuning and additional training dataset. Specifically, we propose VGDiffZero, a simple yet effective zero-shot visual grounding framework based on text-to-image diffusion models. We also design a comprehensive region-scoring method considering both global and local contexts of each isolated proposal. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg show that VGDiffZero achieves strong performance on zero-shot visual grounding.
Equivariant Bootstrapping for Uncertainty Quantification in Imaging Inverse Problems
Oct 20, 2023Scientific imaging problems are often severely ill-posed, and hence have significant intrinsic uncertainty. Accurately quantifying the uncertainty in the solutions to such problems is therefore critical for the rigorous interpretation of experimental results as well as for reliably using the reconstructed images as scientific evidence. Unfortunately, existing imaging methods are unable to quantify the uncertainty in the reconstructed images in a manner that is robust to experiment replications. This paper presents a new uncertainty quantification methodology based on an equivariant formulation of the parametric bootstrap algorithm that leverages symmetries and invariance properties commonly encountered in imaging problems. Additionally, the proposed methodology is general and can be easily applied with any image reconstruction technique, including unsupervised training strategies that can be trained from observed data alone, thus enabling uncertainty quantification in situations where there is no ground truth data available. We demonstrate the proposed approach with a series of numerical experiments and through comparisons with alternative uncertainty quantification strategies from the state-of-the-art, such as Bayesian strategies involving score-based diffusion models and Langevin samplers. In all our experiments, the proposed method delivers remarkably accurate high-dimensional confidence regions and outperforms the competing approaches in terms of estimation accuracy, uncertainty quantification accuracy, and computing time.
DIG-MILP: a Deep Instance Generator for Mixed-Integer Linear Programming with Feasibility Guarantee
Oct 20, 2023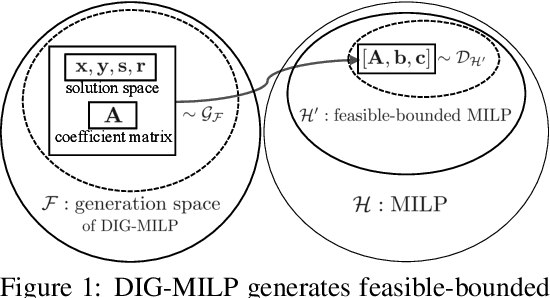

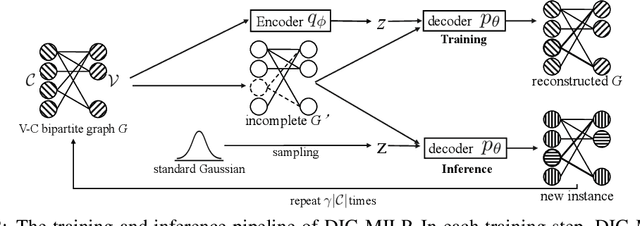

Mixed-integer linear programming (MILP) stands as a notable NP-hard problem pivotal to numerous crucial industrial applications. The development of effective algorithms, the tuning of solvers, and the training of machine learning models for MILP resolution all hinge on access to extensive, diverse, and representative data. Yet compared to the abundant naturally occurring data in image and text realms, MILP is markedly data deficient, underscoring the vital role of synthetic MILP generation. We present DIG-MILP, a deep generative framework based on variational auto-encoder (VAE), adept at extracting deep-level structural features from highly limited MILP data and producing instances that closely mirror the target data. Notably, by leveraging the MILP duality, DIG-MILP guarantees a correct and complete generation space as well as ensures the boundedness and feasibility of the generated instances. Our empirical study highlights the novelty and quality of the instances generated by DIG-MILP through two distinct downstream tasks: (S1) Data sharing, where solver solution times correlate highly positive between original and DIG-MILP-generated instances, allowing data sharing for solver tuning without publishing the original data; (S2) Data Augmentation, wherein the DIG-MILP-generated instances bolster the generalization performance of machine learning models tasked with resolving MILP problems.
nnSAM: Plug-and-play Segment Anything Model Improves nnUNet Performance
Oct 02, 2023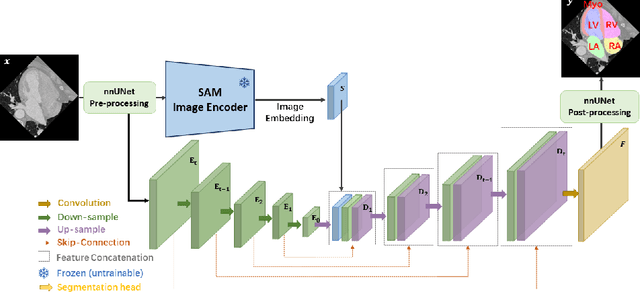
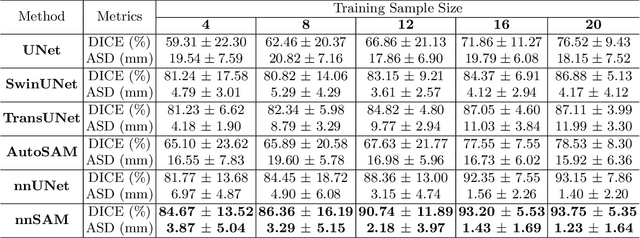
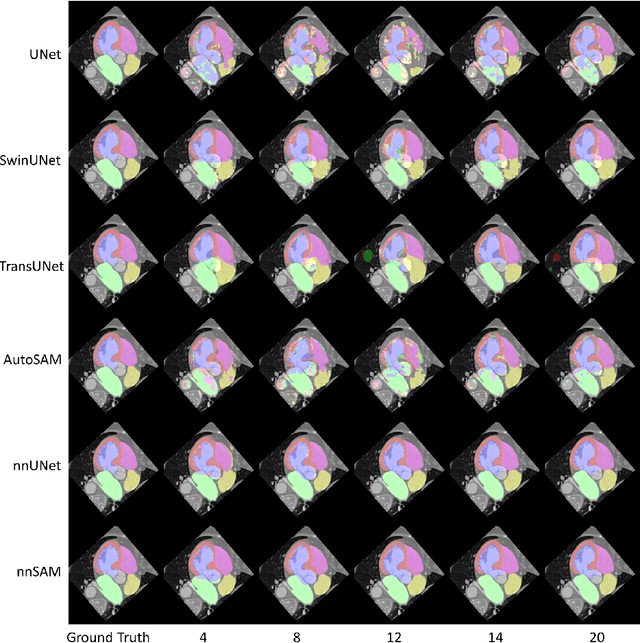
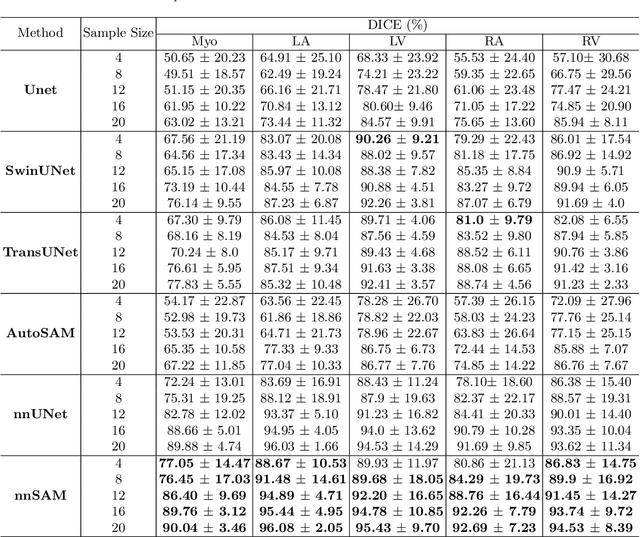
The recent developments of foundation models in computer vision, especially the Segment Anything Model (SAM), allow scalable and domain-agnostic image segmentation to serve as a general-purpose segmentation tool. In parallel, the field of medical image segmentation has benefited significantly from specialized neural networks like the nnUNet, which is trained on domain-specific datasets and can automatically configure the network to tailor to specific segmentation challenges. To combine the advantages of foundation models and domain-specific models, we present nnSAM, which synergistically integrates the SAM model with the nnUNet model to achieve more accurate and robust medical image segmentation. The nnSAM model leverages the powerful and robust feature extraction capabilities of SAM, while harnessing the automatic configuration capabilities of nnUNet to promote dataset-tailored learning. Our comprehensive evaluation of nnSAM model on different sizes of training samples shows that it allows few-shot learning, which is highly relevant for medical image segmentation where high-quality, annotated data can be scarce and costly to obtain. By melding the strengths of both its predecessors, nnSAM positions itself as a potential new benchmark in medical image segmentation, offering a tool that combines broad applicability with specialized efficiency. The code is available at https://github.com/Kent0n-Li/Medical-Image-Segmentation.
Image-free Classifier Injection for Zero-Shot Classification
Aug 21, 2023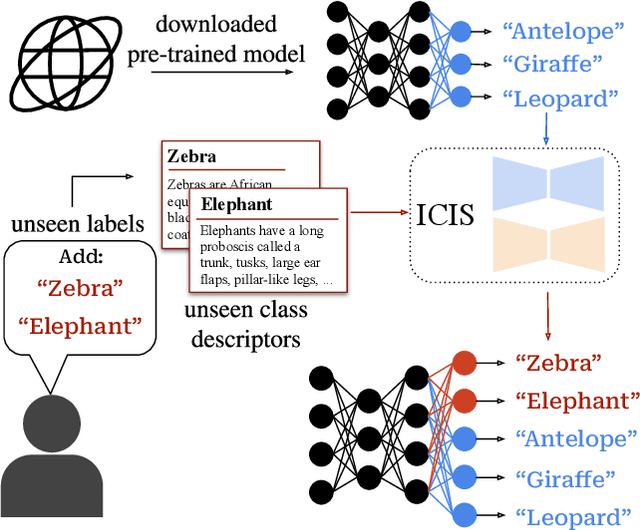
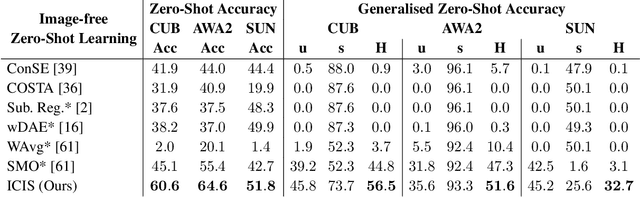
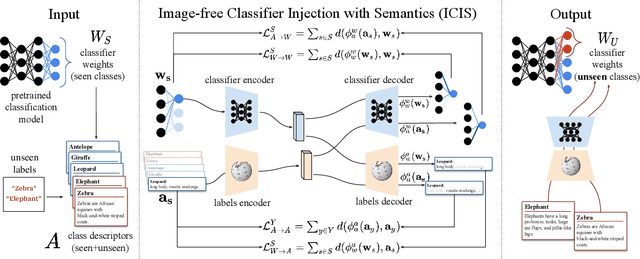
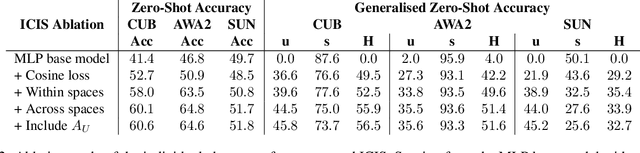
Zero-shot learning models achieve remarkable results on image classification for samples from classes that were not seen during training. However, such models must be trained from scratch with specialised methods: therefore, access to a training dataset is required when the need for zero-shot classification arises. In this paper, we aim to equip pre-trained models with zero-shot classification capabilities without the use of image data. We achieve this with our proposed Image-free Classifier Injection with Semantics (ICIS) that injects classifiers for new, unseen classes into pre-trained classification models in a post-hoc fashion without relying on image data. Instead, the existing classifier weights and simple class-wise descriptors, such as class names or attributes, are used. ICIS has two encoder-decoder networks that learn to reconstruct classifier weights from descriptors (and vice versa), exploiting (cross-)reconstruction and cosine losses to regularise the decoding process. Notably, ICIS can be cheaply trained and applied directly on top of pre-trained classification models. Experiments on benchmark ZSL datasets show that ICIS produces unseen classifier weights that achieve strong (generalised) zero-shot classification performance. Code is available at https://github.com/ExplainableML/ImageFreeZSL .
Content Bias in Deep Learning Age Approximation: A new Approach Towards more Explainability
Oct 03, 2023


In the context of temporal image forensics, it is not evident that a neural network, trained on images from different time-slots (classes), exploit solely age related features. Usually, images taken in close temporal proximity (e.g., belonging to the same age class) share some common content properties. Such content bias can be exploited by a neural network. In this work, a novel approach that evaluates the influence of image content is proposed. This approach is verified using synthetic images (where content bias can be ruled out) with an age signal embedded. Based on the proposed approach, it is shown that a `standard' neural network trained in the context of age classification is strongly dependent on image content. As a potential countermeasure, two different techniques are applied to mitigate the influence of the image content during training, and they are also evaluated by the proposed method.
Research on Key Technologies of Infrastructure Digitalization based on Multimodal Spatial Data
Oct 22, 2023Since NASA put forward the concept of the digital twin in 2010, many industries have put forward the dynamic goal of digital development, and the transportation industry is also among them. With more and more companies laying out on this virgin land, the digital twin transportation industry has grown rapidly and gradually formed a complete scientific research system. However, under the largely mature framework, there are still many loophole problems that need to be solved. In the process of constructing a road network with point cloud information, we summarize several major features of the point cloud collected by laser scanners and analyze the potential problems of constructing the network, such as misjudging the feature points as ground points and grid voids. On this basis, we reviewed relevant literature and proposed targeted solutions, such as building a point cloud pyramid modeled after the image pyramid, expanding the virtual grid, etc., applying CSF for ground-point cloud extraction, and constructing a road network model using the PTD (progressive density-based filter) algorithm. For the problem of road sign detection, we optimize the remote sensing data in the ground point cloud by enhancing the information density using edge detection, improving the data quality by removing the low intensity points, and achieving 90% accuracy of road text recognition using PaddleOCR and Densenet. As for the real-time digital twin traffic, we design the P2PRN network using the backbone of MPR-GAN for 2D feature generation and SuperGlue for 2D feature matching, rendering the viewpoints according to the matching optimization points, completing the multimodal matching task after several iterations, and successfully calculating the road camera position with 10{\deg} and 15m accuracy.
S4C: Self-Supervised Semantic Scene Completion with Neural Fields
Oct 12, 2023


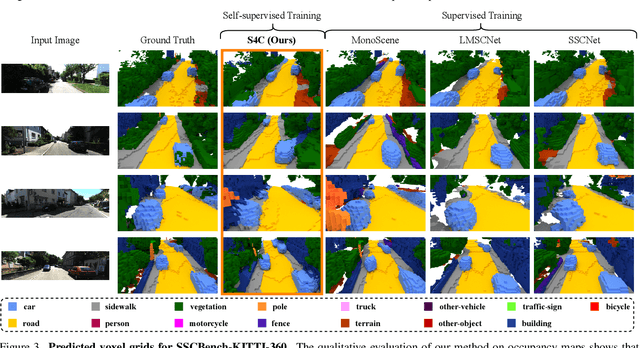
3D semantic scene understanding is a fundamental challenge in computer vision. It enables mobile agents to autonomously plan and navigate arbitrary environments. SSC formalizes this challenge as jointly estimating dense geometry and semantic information from sparse observations of a scene. Current methods for SSC are generally trained on 3D ground truth based on aggregated LiDAR scans. This process relies on special sensors and annotation by hand which are costly and do not scale well. To overcome this issue, our work presents the first self-supervised approach to SSC called S4C that does not rely on 3D ground truth data. Our proposed method can reconstruct a scene from a single image and only relies on videos and pseudo segmentation ground truth generated from off-the-shelf image segmentation network during training. Unlike existing methods, which use discrete voxel grids, we represent scenes as implicit semantic fields. This formulation allows querying any point within the camera frustum for occupancy and semantic class. Our architecture is trained through rendering-based self-supervised losses. Nonetheless, our method achieves performance close to fully supervised state-of-the-art methods. Additionally, our method demonstrates strong generalization capabilities and can synthesize accurate segmentation maps for far away viewpoints.