 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WaveAttack: Asymmetric Frequency Obfuscation-based Backdoor Attacks Against Deep Neural Networks
Oct 19, 2023
Due to the popularity of Artificial Intelligence (AI) technology, numerous backdoor attacks are designed by adversaries to mislead deep neural network predictions by manipulating training samples and training processes. Although backdoor attacks are effective in various real scenarios, they still suffer from the problems of both low fidelity of poisoned samples and non-negligible transfer in latent space, which make them easily detectable by existing backdoor detection algorithms. To overcome the weakness, this paper proposes a novel frequency-based backdoor attack method named WaveAttack, which obtains image high-frequency features through Discrete Wavelet Transform (DWT) to generate backdoor triggers. Furthermore, we introduce an asymmetric frequency obfuscation method, which can add an adaptive residual in the training and inference stage to improve the impact of triggers and further enhance the effectiveness of WaveAttack. Comprehensive experimental results show that WaveAttack not only achieves higher stealthiness and effectiveness, but also outperforms state-of-the-art (SOTA) backdoor attack methods in the fidelity of images by up to 28.27\% improvement in PSNR, 1.61\% improvement in SSIM, and 70.59\% reduction in IS.
FUSC: Fetal Ultrasound Semantic Clustering of Second Trimester Scans Using Deep Self-supervised Learning
Oct 19, 2023Ultrasound is the primary imaging modality in clinical practice during pregnancy. More than 140M fetuses are born yearly, resulting in numerous scans. The availability of a large volume of fetal ultrasound scans presents the opportunity to train robust machine learning models. However, the abundance of scans also has its challenges, as manual labeling of each image is needed for supervised methods. Labeling is typically labor-intensive and requires expertise to annotate the images accurately. This study presents an unsupervised approach for automatically clustering ultrasound images into a large range of fetal views, reducing or eliminating the need for manual labeling. Our Fetal Ultrasound Semantic Clustering (FUSC) method is developed using a large dataset of 88,063 images and further evaluated on an additional unseen dataset of 8,187 images achieving over 92% clustering purity. The result of our investigation hold the potential to significantly impact the field of fetal ultrasound imaging and pave the way for more advanced automated labeling solutions. Finally, we make the code and the experimental setup publicly available to help advance the field.
To token or not to token: A Comparative Study of Text Representations for Cross-Lingual Transfer
Oct 12, 2023Choosing an appropriate tokenization scheme is often a bottleneck in low-resource cross-lingual transfer. To understand the downstream implications of text representation choices, we perform a comparative analysis on language models having diverse text representation modalities including 2 segmentation-based models (\texttt{BERT}, \texttt{mBERT}), 1 image-based model (\texttt{PIXEL}), and 1 character-level model (\texttt{CANINE}). First, we propose a scoring Language Quotient (LQ) metric capable of providing a weighted representation of both zero-shot and few-shot evaluation combined. Utilizing this metric, we perform experiments comprising 19 source languages and 133 target languages on three tasks (POS tagging, Dependency parsing, and NER). Our analysis reveals that image-based models excel in cross-lingual transfer when languages are closely related and share visually similar scripts. However, for tasks biased toward word meaning (POS, NER), segmentation-based models prove to be superior. Furthermore, in dependency parsing tasks where word relationships play a crucial role, models with their character-level focus, outperform others. Finally, we propose a recommendation scheme based on our findings to guide model selection according to task and language requirements.
Interpretable Diffusion via Information Decomposition
Oct 12, 2023


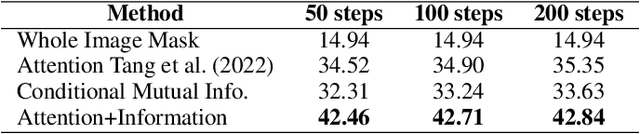
Denoising diffusion models enable conditional generation and density modeling of complex relationships like images and text. However, the nature of the learned relationships is opaque making it difficult to understand precisely what relationships between words and parts of an image are captured, or to predict the effect of an intervention. We illuminate the fine-grained relationships learned by diffusion models by noticing a precise relationship between diffusion and information decomposition. Exact expressions for mutual information and conditional mutual information can be written in terms of the denoising model. Furthermore, pointwise estimates can be easily estimated as well, allowing us to ask questions about the relationships between specific images and captions. Decomposing information even further to understand which variables in a high-dimensional space carry information is a long-standing problem. For diffusion models, we show that a natural non-negative decomposition of mutual information emerges, allowing us to quantify informative relationships between words and pixels in an image. We exploit these new relations to measure the compositional understanding of diffusion models, to do unsupervised localization of objects in images, and to measure effects when selectively editing images through prompt interventions.
Finite Scalar Quantization: VQ-VAE Made Simple
Oct 12, 2023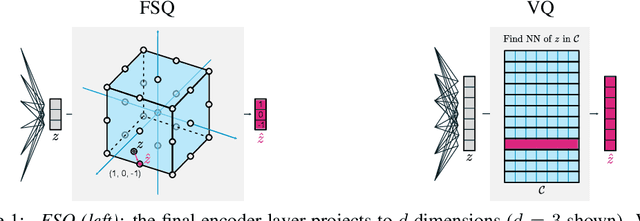


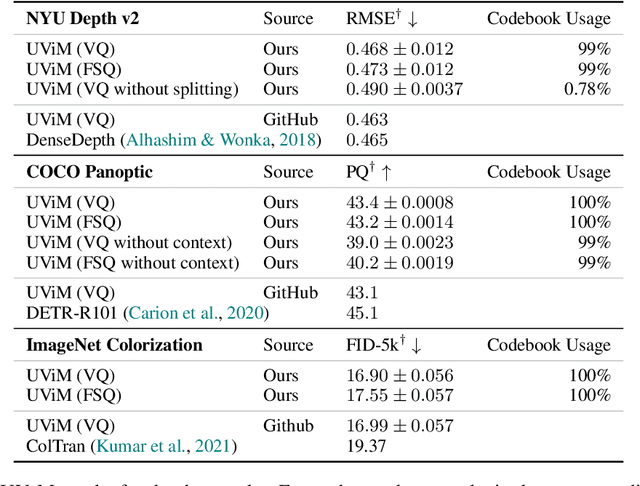
We propose to replace vector quantization (VQ) in the latent representation of VQ-VAEs with a simple scheme termed finite scalar quantization (FSQ), where we project the VAE representation down to a few dimensions (typically less than 10). Each dimension is quantized to a small set of fixed values, leading to an (implicit) codebook given by the product of these sets. By appropriately choosing the number of dimensions and values each dimension can take, we obtain the same codebook size as in VQ. On top of such discrete representations, we can train the same models that have been trained on VQ-VAE representations. For example, autoregressive and masked transformer models for image generation, multimodal generation, and dense prediction computer vision tasks. Concretely, we employ FSQ with MaskGIT for image generation, and with UViM for depth estimation, colorization, and panoptic segmentation. Despite the much simpler design of FSQ, we obtain competitive performance in all these tasks. We emphasize that FSQ does not suffer from codebook collapse and does not need the complex machinery employed in VQ (commitment losses, codebook reseeding, code splitting, entropy penalties, etc.) to learn expressive discrete representations.
Learning Efficient Representations for Image-Based Patent Retrieval
Aug 26, 2023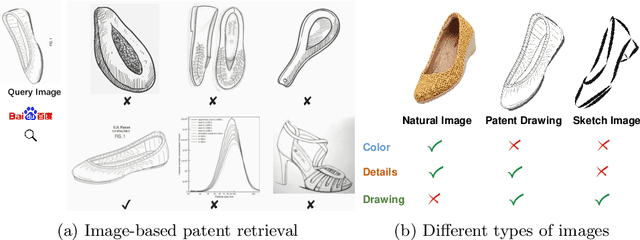
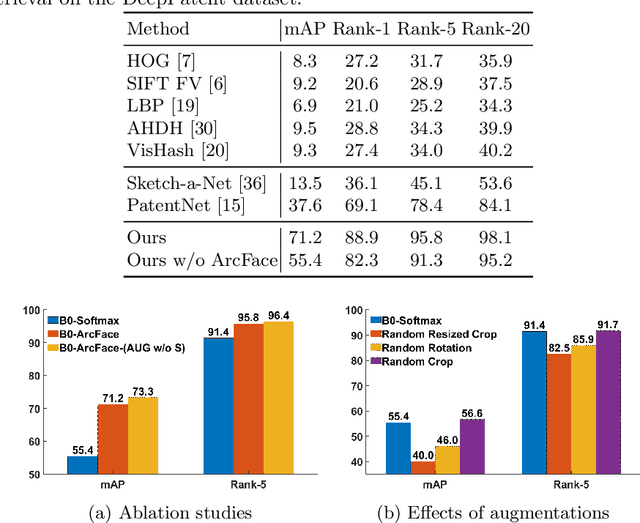
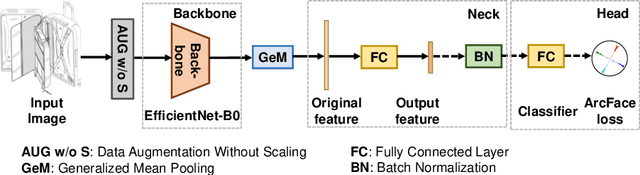
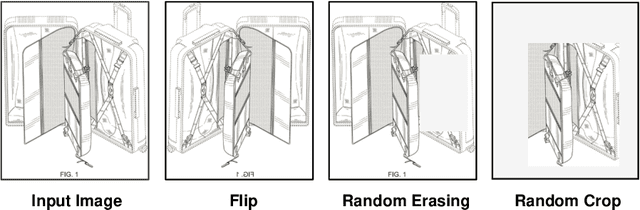
Patent retrieval has been attracting tremendous interest from researchers in intellectual property and information retrieval communities in the past decades. However, most existing approaches rely on textual and metadata information of the patent, and content-based image-based patent retrieval is rarely investigated. Based on traits of patent drawing images, we present a simple and lightweight model for this task. Without bells and whistles, this approach significantly outperforms other counterparts on a large-scale benchmark and noticeably improves the state-of-the-art by 33.5% with the mean average precision (mAP) score. Further experiments reveal that this model can be elaborately scaled up to achieve a surprisingly high mAP of 93.5%. Our method ranks first in the ECCV 2022 Patent Diagram Image Retrieval Challenge.
FIVA: Facial Image and Video Anonymization and Anonymization Defense
Sep 08, 2023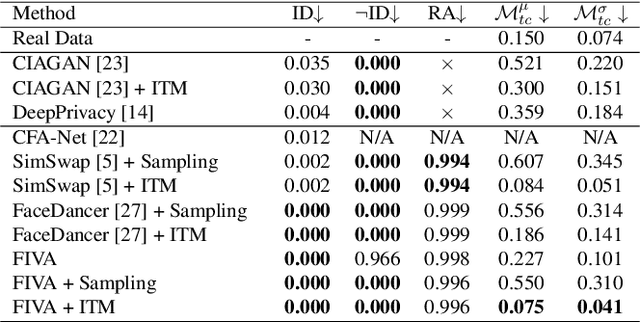
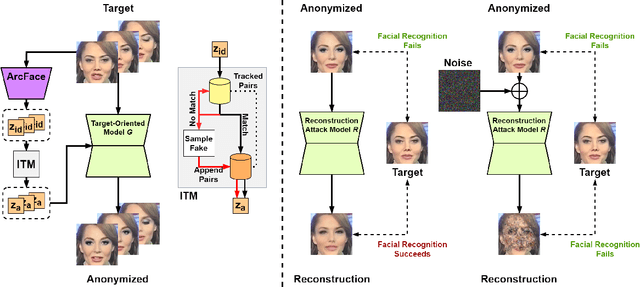
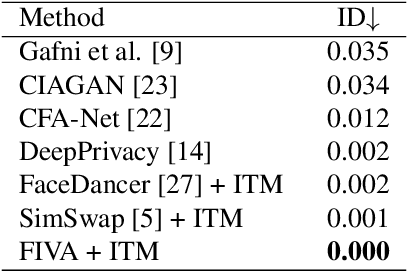
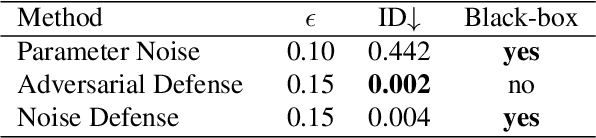
In this paper, we present a new approach for facial anonymization in images and videos, abbreviated as FIVA. Our proposed method is able to maintain the same face anonymization consistently over frames with our suggested identity-tracking and guarantees a strong difference from the original face. FIVA allows for 0 true positives for a false acceptance rate of 0.001. Our work considers the important security issue of reconstruction attacks and investigates adversarial noise, uniform noise, and parameter noise to disrupt reconstruction attacks. In this regard, we apply different defense and protection methods against these privacy threats to demonstrate the scalability of FIVA. On top of this, we also show that reconstruction attack models can be used for detection of deep fakes. Last but not least, we provide experimental results showing how FIVA can even enable face swapping, which is purely trained on a single target image.
Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model
Aug 25, 2023
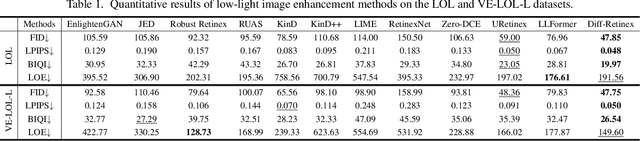
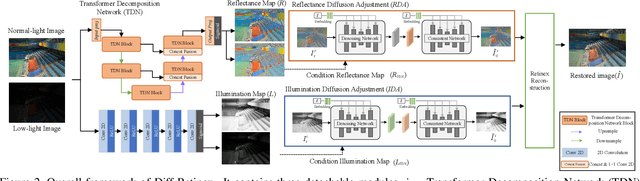
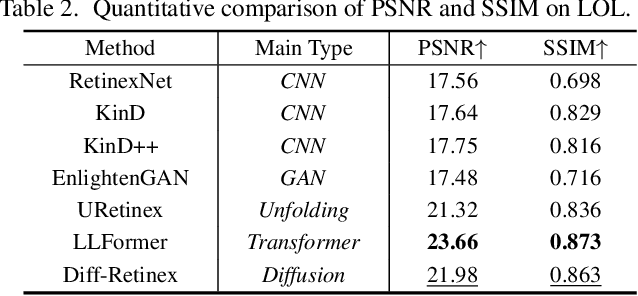
In this paper, we rethink the low-light image enhancement task and propose a physically explainable and generative diffusion model for low-light image enhancement, termed as Diff-Retinex. We aim to integrate the advantages of the physical model and the generative network. Furthermore, we hope to supplement and even deduce the information missing in the low-light image through the generative network. Therefore, Diff-Retinex formulates the low-light image enhancement problem into Retinex decomposition and conditional image generation. In the Retinex decomposition, we integrate the superiority of attention in Transformer and meticulously design a Retinex Transformer decomposition network (TDN) to decompose the image into illumination and reflectance maps. Then, we design multi-path generative diffusion networks to reconstruct the normal-light Retinex probability distribution and solve the various degradations in these components respectively, including dark illumination, noise, color deviation, loss of scene contents, etc. Owing to generative diffusion model, Diff-Retinex puts the restoration of low-light subtle detail into practice. Extensive experiments conducted on real-world low-light datasets qualitatively and quantitatively demonstrate the effectiveness, superiority, and generalization of the proposed method.
Score-Based Generative Models for PET Image Reconstruction
Aug 27, 2023Score-based generative models have demonstrated highly promising results for medical image reconstruction tasks in magnetic resonance imaging or computed tomography. However, their application to Positron Emission Tomography (PET) is still largely unexplored. PET image reconstruction involves a variety of challenges, including Poisson noise with high variance and a wide dynamic range. To address these challenges, we propose several PET-specific adaptations of score-based generative models. The proposed framework is developed for both 2D and 3D PET. In addition, we provide an extension to guided reconstruction using magnetic resonance images. We validate the approach through extensive 2D and 3D $\textit{in-silico}$ experiments with a model trained on patient-realistic data without lesions, and evaluate on data without lesions as well as out-of-distribution data with lesions. This demonstrates the proposed method's robustness and significant potential for improved PET reconstruction.
Geometry-Guided Ray Augmentation for Neural Surface Reconstruction with Sparse Views
Oct 18, 2023
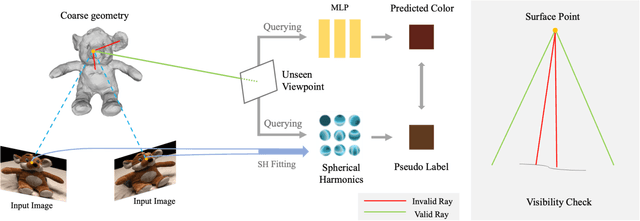
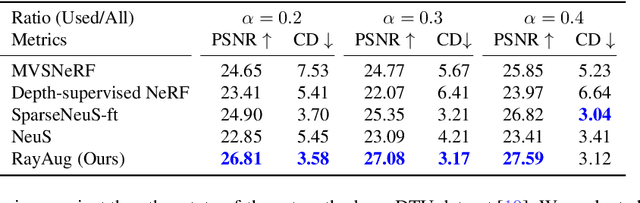

In this paper, we propose a novel method for 3D scene and object reconstruction from sparse multi-view images. Different from previous methods that leverage extra information such as depth or generalizable features across scenes, our approach leverages the scene properties embedded in the multi-view inputs to create precise pseudo-labels for optimization without any prior training. Specifically, we introduce a geometry-guided approach that improves surface reconstruction accuracy from sparse views by leveraging spherical harmonics to predict the novel radiance while holistically considering all color observations for a point in the scene. Also, our pipeline exploits proxy geometry and correctly handles the occlusion in generating the pseudo-labels of radiance, which previous image-warping methods fail to avoid. Our method, dubbed Ray Augmentation (RayAug), achieves superior results on DTU and Blender datasets without requiring prior training, demonstrating its effectiveness in addressing the problem of sparse view reconstruction. Our pipeline is flexible and can be integrated into other implicit neural reconstruction methods for sparse views.