 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PAC Prediction Sets Under Label Shift
Oct 19, 2023
Prediction sets capture uncertainty by predicting sets of labels rather than individual labels, enabling downstream decisions to conservatively account for all plausible outcomes. Conformal inference algorithms construct prediction sets guaranteed to contain the true label with high probability. These guarantees fail to hold in the face of distribution shift, which is precisely when reliable uncertainty quantification can be most useful. We propose a novel algorithm for constructing prediction sets with PAC guarantees in the label shift setting. This method estimates the predicted probabilities of the classes in a target domain, as well as the confusion matrix, then propagates uncertainty in these estimates through a Gaussian elimination algorithm to compute confidence intervals for importance weights. Finally, it uses these intervals to construct prediction sets. We evaluate our approach on five datasets: the CIFAR-10, ChestX-Ray and Entity-13 image datasets, the tabular CDC Heart dataset, and the AGNews text dataset. Our algorithm satisfies the PAC guarantee while producing smaller, more informative, prediction sets compared to several baselines.
Semantic-Aware Adversarial Training for Reliable Deep Hashing Retrieval
Oct 23, 2023Deep hashing has been intensively studied and successfully applied in large-scale image retrieval systems due to its efficiency and effectiveness. Recent studies have recognized that the existence of adversarial examples poses a security threat to deep hashing models, that is, adversarial vulnerability. Notably, it is challenging to efficiently distill reliable semantic representatives for deep hashing to guide adversarial learning, and thereby it hinders the enhancement of adversarial robustness of deep hashing-based retrieval models. Moreover, current researches on adversarial training for deep hashing are hard to be formalized into a unified minimax structure. In this paper, we explore Semantic-Aware Adversarial Training (SAAT) for improving the adversarial robustness of deep hashing models. Specifically, we conceive a discriminative mainstay features learning (DMFL) scheme to construct semantic representatives for guiding adversarial learning in deep hashing. Particularly, our DMFL with the strict theoretical guarantee is adaptively optimized in a discriminative learning manner, where both discriminative and semantic properties are jointly considered. Moreover, adversarial examples are fabricated by maximizing the Hamming distance between the hash codes of adversarial samples and mainstay features, the efficacy of which is validated in the adversarial attack trials. Further, we, for the first time, formulate the formalized adversarial training of deep hashing into a unified minimax optimization under the guidance of the generated mainstay codes. Extensive experiments on benchmark datasets show superb attack performance against the state-of-the-art algorithms, meanwhile, the proposed adversarial training can effectively eliminate adversarial perturbations for trustworthy deep hashing-based retrieval. Our code is available at https://github.com/xandery-geek/SAAT.
Visual Data-Type Understanding does not emerge from Scaling Vision-Language Models
Oct 16, 2023Recent advances in the development of vision-language models (VLMs) are yielding remarkable success in recognizing visual semantic content, including impressive instances of compositional image understanding. Here, we introduce the novel task of Visual Data-Type Identification, a basic perceptual skill with implications for data curation (e.g., noisy data-removal from large datasets, domain-specific retrieval) and autonomous vision (e.g., distinguishing changing weather conditions from camera lens staining). We develop two datasets consisting of animal images altered across a diverse set of 27 visual data-types, spanning four broad categories. An extensive zero-shot evaluation of 39 VLMs, ranging from 100M to 80B parameters, shows a nuanced performance landscape. While VLMs are reasonably good at identifying certain stylistic \textit{data-types}, such as cartoons and sketches, they struggle with simpler data-types arising from basic manipulations like image rotations or additive noise. Our findings reveal that (i) model scaling alone yields marginal gains for contrastively-trained models like CLIP, and (ii) there is a pronounced drop in performance for the largest auto-regressively trained VLMs like OpenFlamingo. This finding points to a blind spot in current frontier VLMs: they excel in recognizing semantic content but fail to acquire an understanding of visual data-types through scaling. By analyzing the pre-training distributions of these models and incorporating data-type information into the captions during fine-tuning, we achieve a significant enhancement in performance. By exploring this previously uncharted task, we aim to set the stage for further advancing VLMs to equip them with visual data-type understanding. Code and datasets are released at https://github.com/bethgelab/DataTypeIdentification.
Detecting Abnormal Health Conditions in Smart Home Using a Drone
Oct 18, 2023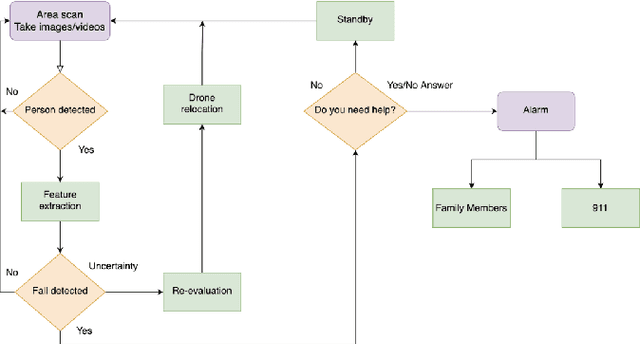


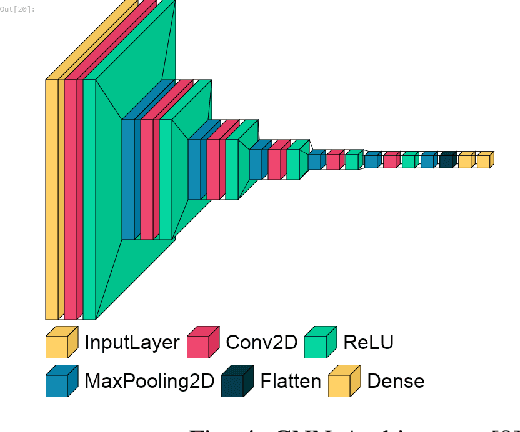
Nowadays, detecting aberrant health issues is a difficult process. Falling, especially among the elderly, is a severe concern worldwide. Falls can result in deadly consequences, including unconsciousness, internal bleeding, and often times, death. A practical and optimal, smart approach of detecting falling is currently a concern. The use of vision-based fall monitoring is becoming more common among scientists as it enables senior citizens and those with other health conditions to live independently. For tracking, surveillance, and rescue, unmanned aerial vehicles use video or image segmentation and object detection methods. The Tello drone is equipped with a camera and with this device we determined normal and abnormal behaviors among our participants. The autonomous falling objects are classified using a convolutional neural network (CNN) classifier. The results demonstrate that the systems can identify falling objects with a precision of 0.9948.
Chinese Painting Style Transfer Using Deep Generative Models
Oct 17, 2023Artistic style transfer aims to modify the style of the image while preserving its content. Style transfer using deep learning models has been widely studied since 2015, and most of the applications are focused on specific artists like Van Gogh, Monet, Cezanne. There are few researches and applications on traditional Chinese painting style transfer. In this paper, we will study and leverage different state-of-the-art deep generative models for Chinese painting style transfer and evaluate the performance both qualitatively and quantitatively. In addition, we propose our own algorithm that combines several style transfer models for our task. Specifically, we will transfer two main types of traditional Chinese painting style, known as "Gong-bi" and "Shui-mo" (to modern images like nature objects, portraits and landscapes.
Unsupervised Learning of Object-Centric Embeddings for Cell Instance Segmentation in Microscopy Images
Oct 12, 2023Segmentation of objects in microscopy images is required for many biomedical applications. We introduce object-centric embeddings (OCEs), which embed image patches such that the spatial offsets between patches cropped from the same object are preserved. Those learnt embeddings can be used to delineate individual objects and thus obtain instance segmentations. Here, we show theoretically that, under assumptions commonly found in microscopy images, OCEs can be learnt through a self-supervised task that predicts the spatial offset between image patches. Together, this forms an unsupervised cell instance segmentation method which we evaluate on nine diverse large-scale microscopy datasets. Segmentations obtained with our method lead to substantially improved results, compared to state-of-the-art baselines on six out of nine datasets, and perform on par on the remaining three datasets. If ground-truth annotations are available, our method serves as an excellent starting point for supervised training, reducing the required amount of ground-truth needed by one order of magnitude, thus substantially increasing the practical applicability of our method. Source code is available at https://github.com/funkelab/cellulus.
Revisiting Data Augmentation for Rotational Invariance in Convolutional Neural Networks
Oct 12, 2023Convolutional Neural Networks (CNN) offer state of the art performance in various computer vision tasks. Many of those tasks require different subtypes of affine invariances (scale, rotational, translational) to image transformations. Convolutional layers are translation equivariant by design, but in their basic form lack invariances. In this work we investigate how best to include rotational invariance in a CNN for image classification. Our experiments show that networks trained with data augmentation alone can classify rotated images nearly as well as in the normal unrotated case; this increase in representational power comes only at the cost of training time. We also compare data augmentation versus two modified CNN models for achieving rotational invariance or equivariance, Spatial Transformer Networks and Group Equivariant CNNs, finding no significant accuracy increase with these specialized methods. In the case of data augmented networks, we also analyze which layers help the network to encode the rotational invariance, which is important for understanding its limitations and how to best retrain a network with data augmentation to achieve invariance to rotation.
Deep supervised hashing for fast retrieval of radio image cubes
Sep 02, 2023The shear number of sources that will be detected by next-generation radio surveys will be astronomical, which will result in serendipitous discoveries. Data-dependent deep hashing algorithms have been shown to be efficient at image retrieval tasks in the fields of computer vision and multimedia. However, there are limited applications of these methodologies in the field of astronomy. In this work, we utilize deep hashing to rapidly search for similar images in a large database. The experiment uses a balanced dataset of 2708 samples consisting of four classes: Compact, FRI, FRII, and Bent. The performance of the method was evaluated using the mean average precision (mAP) metric where a precision of 88.5\% was achieved. The experimental results demonstrate the capability to search and retrieve similar radio images efficiently and at scale. The retrieval is based on the Hamming distance between the binary hash of the query image and those of the reference images in the database.
WAIT: Feature Warping for Animation to Illustration video Translation using GANs
Oct 07, 2023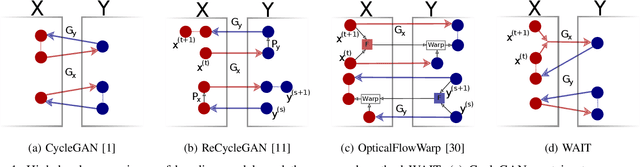
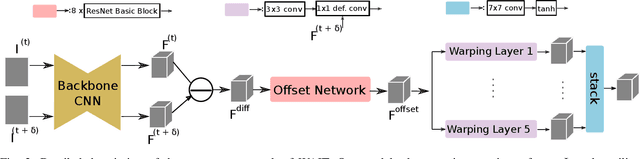


In this paper, we explore a new domain for video-to-video translation. Motivated by the availability of animation movies that are adopted from illustrated books for children, we aim to stylize these videos with the style of the original illustrations. Current state-of-the-art video-to-video translation models rely on having a video sequence or a single style image to stylize an input video. We introduce a new problem for video stylizing where an unordered set of images are used. This is a challenging task for two reasons: i) we do not have the advantage of temporal consistency as in video sequences; ii) it is more difficult to obtain consistent styles for video frames from a set of unordered images compared to using a single image. Most of the video-to-video translation methods are built on an image-to-image translation model, and integrate additional networks such as optical flow, or temporal predictors to capture temporal relations. These additional networks make the model training and inference complicated and slow down the process. To ensure temporal coherency in video-to-video style transfer, we propose a new generator network with feature warping layers which overcomes the limitations of the previous methods. We show the effectiveness of our method on three datasets both qualitatively and quantitatively. Code and pretrained models are available at https://github.com/giddyyupp/wait.
Transformer-based Multimodal Change Detection with Multitask Consistency Constraints
Oct 21, 2023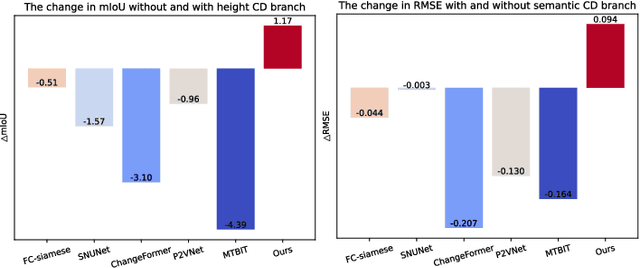
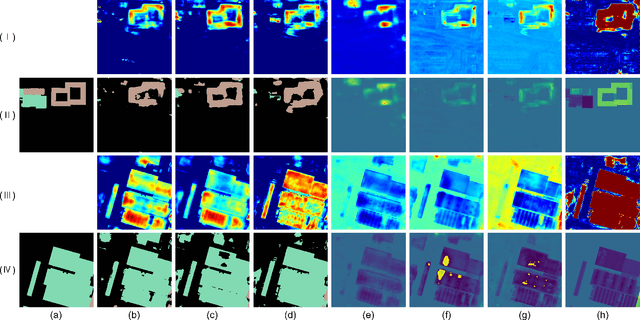
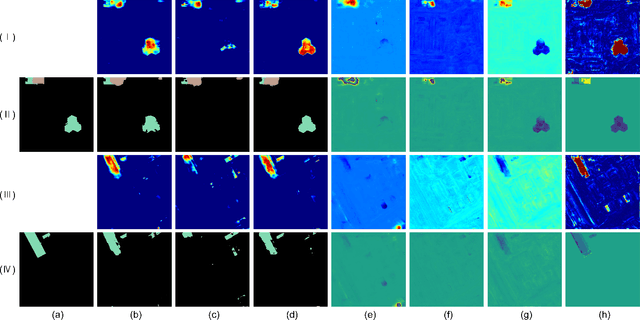

Change detection plays a fundamental role in Earth observation for analyzing temporal iterations over time. However, recent studies have largely neglected the utilization of multimodal data that presents significant practical and technical advantages compared to single-modal approaches. This research focuses on leveraging digital surface model (DSM) data and aerial images captured at different times for detecting change beyond 2D. We observe that the current change detection methods struggle with the multitask conflicts between semantic and height change detection tasks. To address this challenge, we propose an efficient Transformer-based network that learns shared representation between cross-dimensional inputs through cross-attention. It adopts a consistency constraint to establish the multimodal relationship, which involves obtaining pseudo change through height change thresholding and minimizing the difference between semantic and pseudo change within their overlapping regions. A DSM-to-image multimodal dataset encompassing three cities in the Netherlands was constructed. It lays a new foundation for beyond-2D change detection from cross-dimensional inputs. Compared to five state-of-the-art change detection methods, our model demonstrates consistent multitask superiority in terms of semantic and height change detection. Furthermore, the consistency strategy can be seamlessly adapted to the other methods, yielding promising improvements.