 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-pixel imaging based on deep learning
Oct 25, 2023
Since the advent of single-pixel imaging and machine learning, both fields have flourished, but followed parallel tracks. Until recently, machine learning, especially deep learning, has demonstrated effectiveness in delivering high-quality solutions across various application domains of single-pixel imaging. This article comprehensively reviews the research of single-pixel imaging technology based on deep learning. From the basic principles of single-pixel imaging and deep learning, the principles and implementation methods of single-pixel imaging based on deep learning are described in detail. Then, the research status and development trend of single-pixel imaging based on deep learning in various domains are analyzed, including super-resolution single-pixel imaging, single-pixel imaging through scattering media, photon-level single-pixel imaging, optical encryption based on single-pixel imaging, color single-pixel imaging, and image-free sensing. Finally, this review explores the limitations in the ongoing research, while offers the delivering insights into prospective avenues for future research.
The Teenager's Problem: Efficient Garment Decluttering With Grasp Optimization
Oct 25, 2023This paper addresses the ''Teenager's Problem'': efficiently removing scattered garments from a planar surface. As grasping and transporting individual garments is highly inefficient, we propose analytical policies to select grasp locations for multiple garments using an overhead camera. Two classes of methods are considered: depth-based, which use overhead depth data to find efficient grasps, and segment-based, which use segmentation on the RGB overhead image (without requiring any depth data); grasp efficiency is measured by Objects per Transport, which denotes the average number of objects removed per trip to the laundry basket. Experiments suggest that both depth- and segment-based methods easily reduce Objects per Transport (OpT) by $20\%$; furthermore, these approaches complement each other, with combined hybrid methods yielding improvements of $34\%$. Finally, a method employing consolidation (with segmentation) is considered, which manipulates the garments on the work surface to increase OpT; this yields an improvement of $67\%$ over the baseline, though at a cost of additional physical actions.
Learning to Explain: A Model-Agnostic Framework for Explaining Black Box Models
Oct 25, 2023We present Learning to Explain (LTX), a model-agnostic framework designed for providing post-hoc explanations for vision models. The LTX framework introduces an "explainer" model that generates explanation maps, highlighting the crucial regions that justify the predictions made by the model being explained. To train the explainer, we employ a two-stage process consisting of initial pretraining followed by per-instance finetuning. During both stages of training, we utilize a unique configuration where we compare the explained model's prediction for a masked input with its original prediction for the unmasked input. This approach enables the use of a novel counterfactual objective, which aims to anticipate the model's output using masked versions of the input image. Importantly, the LTX framework is not restricted to a specific model architecture and can provide explanations for both Transformer-based and convolutional models. Through our evaluations, we demonstrate that LTX significantly outperforms the current state-of-the-art in explainability across various metrics.
CrossEAI: Using Explainable AI to generate better bounding boxes for Chest X-ray images
Oct 29, 2023Explainability is critical for deep learning applications in healthcare which are mandated to provide interpretations to both patients and doctors according to legal regulations and responsibilities. Explainable AI methods, such as feature importance using integrated gradients, model approximation using LIME, or neuron activation and layer conductance to provide interpretations for certain health risk predictions. In medical imaging diagnosis, disease classification usually achieves high accuracy, but generated bounding boxes have much lower Intersection over Union (IoU). Different methods with self-supervised or semi-supervised learning strategies have been proposed, but few improvements have been identified for bounding box generation. Previous work shows that bounding boxes generated by these methods are usually larger than ground truth and contain major non-disease area. This paper utilizes the advantages of post-hoc AI explainable methods to generate bounding boxes for chest x-ray image diagnosis. In this work, we propose CrossEAI which combines heatmap and gradient map to generate more targeted bounding boxes. By using weighted average of Guided Backpropagation and Grad-CAM++, we are able to generate bounding boxes which are closer to the ground truth. We evaluate our model on a chest x-ray dataset. The performance has significant improvement over the state of the art model with the same setting, with $9\%$ improvement in average of all diseases over all IoU. Moreover, as a model that does not use any ground truth bounding box information for training, we achieve same performance in general as the model that uses $80\%$ of the ground truth bounding box information for training
Learning Continuous Exposure Value Representations for Single-Image HDR Reconstruction
Sep 07, 2023Deep learning is commonly used to reconstruct HDR images from LDR images. LDR stack-based methods are used for single-image HDR reconstruction, generating an HDR image from a deep learning-generated LDR stack. However, current methods generate the stack with predetermined exposure values (EVs), which may limit the quality of HDR reconstruction. To address this, we propose the continuous exposure value representation (CEVR), which uses an implicit function to generate LDR images with arbitrary EVs, including those unseen during training. Our approach generates a continuous stack with more images containing diverse EVs, significantly improving HDR reconstruction. We use a cycle training strategy to supervise the model in generating continuous EV LDR images without corresponding ground truths. Our CEVR model outperforms existing methods, as demonstrated by experimental results.
OV-VG: A Benchmark for Open-Vocabulary Visual Grounding
Oct 22, 2023



Open-vocabulary learning has emerged as a cutting-edge research area, particularly in light of the widespread adoption of vision-based foundational models. Its primary objective is to comprehend novel concepts that are not encompassed within a predefined vocabulary. One key facet of this endeavor is Visual Grounding, which entails locating a specific region within an image based on a corresponding language description. While current foundational models excel at various visual language tasks, there's a noticeable absence of models specifically tailored for open-vocabulary visual grounding. This research endeavor introduces novel and challenging OV tasks, namely Open-Vocabulary Visual Grounding and Open-Vocabulary Phrase Localization. The overarching aim is to establish connections between language descriptions and the localization of novel objects. To facilitate this, we have curated a comprehensive annotated benchmark, encompassing 7,272 OV-VG images and 1,000 OV-PL images. In our pursuit of addressing these challenges, we delved into various baseline methodologies rooted in existing open-vocabulary object detection, VG, and phrase localization frameworks. Surprisingly, we discovered that state-of-the-art methods often falter in diverse scenarios. Consequently, we developed a novel framework that integrates two critical components: Text-Image Query Selection and Language-Guided Feature Attention. These modules are designed to bolster the recognition of novel categories and enhance the alignment between visual and linguistic information. Extensive experiments demonstrate the efficacy of our proposed framework, which consistently attains SOTA performance across the OV-VG task. Additionally, ablation studies provide further evidence of the effectiveness of our innovative models. Codes and datasets will be made publicly available at https://github.com/cv516Buaa/OV-VG.
Investigating the Robustness and Properties of Detection Transformers (DETR) Toward Difficult Images
Oct 12, 2023
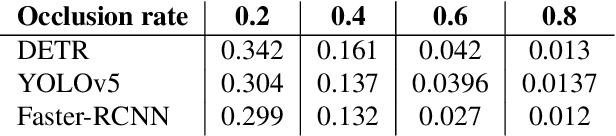
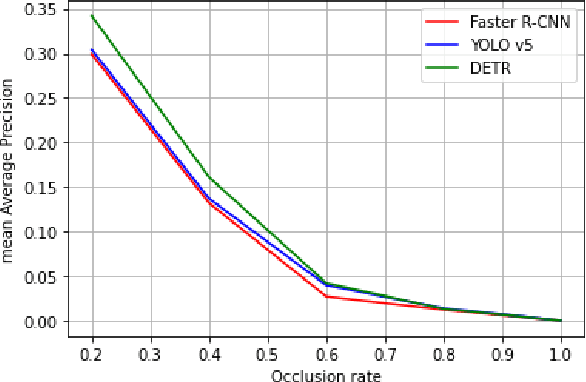
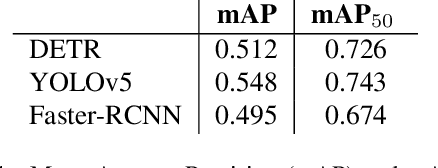
Transformer-based object detectors (DETR) have shown significant performance across machine vision tasks, ultimately in object detection. This detector is based on a self-attention mechanism along with the transformer encoder-decoder architecture to capture the global context in the image. The critical issue to be addressed is how this model architecture can handle different image nuisances, such as occlusion and adversarial perturbations. We studied this issue by measuring the performance of DETR with different experiments and benchmarking the network with convolutional neural network (CNN) based detectors like YOLO and Faster-RCNN. We found that DETR performs well when it comes to resistance to interference from information loss in occlusion images. Despite that, we found that the adversarial stickers put on the image require the network to produce a new unnecessary set of keys, queries, and values, which in most cases, results in a misdirection of the network. DETR also performed poorer than YOLOv5 in the image corruption benchmark. Furthermore, we found that DETR depends heavily on the main query when making a prediction, which leads to imbalanced contributions between queries since the main query receives most of the gradient flow.
UWB Based Static Gesture Classification
Oct 23, 2023

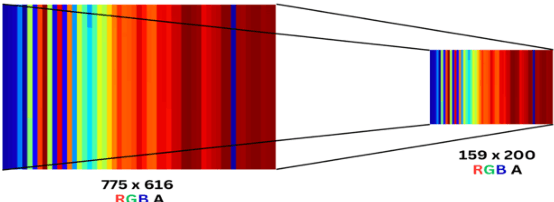
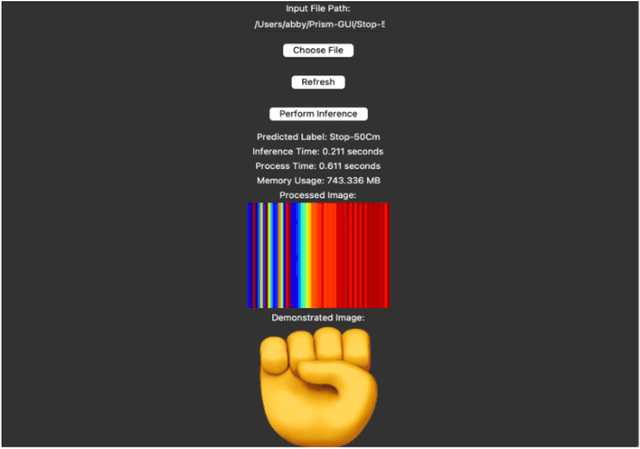
Our paper presents a robust framework for UWB-based static gesture recognition, leveraging proprietary UWB radar sensor technology. Extensive data collection efforts were undertaken to compile datasets containing five commonly used gestures. Our approach involves a comprehensive data pre-processing pipeline that encompasses outlier handling, aspect ratio-preserving resizing, and false-color image transformation. Both CNN and MobileNet models were trained on the processed images. Remarkably, our best-performing model achieved an accuracy of 96.78%. Additionally, we developed a user-friendly GUI framework to assess the model's system resource usage and processing times, which revealed low memory utilization and real-time task completion in under one second. This research marks a significant step towards enhancing static gesture recognition using UWB technology, promising practical applications in various domains.
Multi-scale, Data-driven and Anatomically Constrained Deep Learning Image Registration for Adult and Fetal Echocardiography
Sep 11, 2023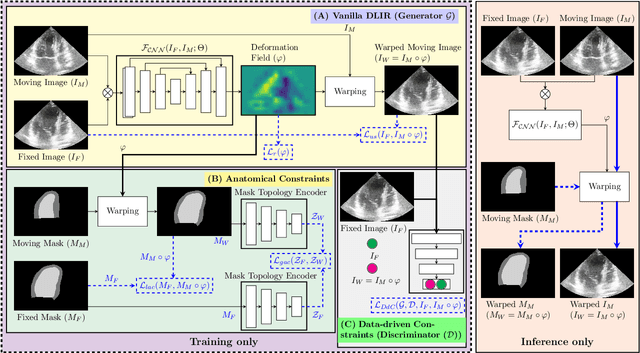

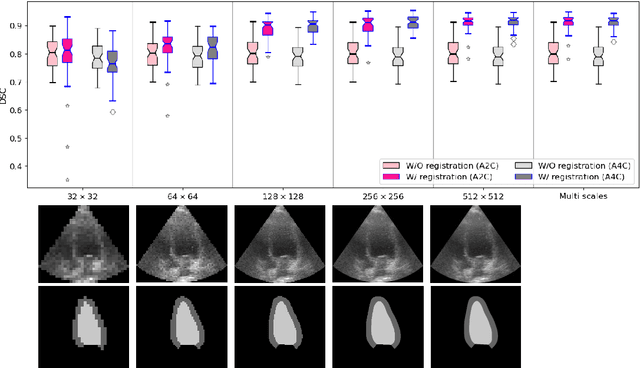
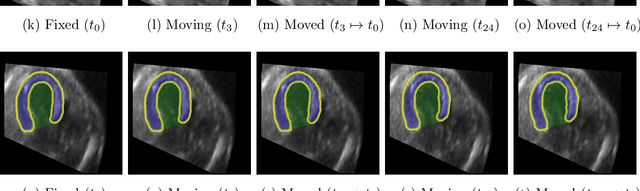
Temporal echocardiography image registration is a basis for clinical quantifications such as cardiac motion estimation, myocardial strain assessments, and stroke volume quantifications. In past studies, deep learning image registration (DLIR) has shown promising results and is consistently accurate and precise, requiring less computational time. We propose that a greater focus on the warped moving image's anatomic plausibility and image quality can support robust DLIR performance. Further, past implementations have focused on adult echocardiography, and there is an absence of DLIR implementations for fetal echocardiography. We propose a framework that combines three strategies for DLIR in both fetal and adult echo: (1) an anatomic shape-encoded loss to preserve physiological myocardial and left ventricular anatomical topologies in warped images; (2) a data-driven loss that is trained adversarially to preserve good image texture features in warped images; and (3) a multi-scale training scheme of a data-driven and anatomically constrained algorithm to improve accuracy. Our tests show that good anatomical topology and image textures are strongly linked to shape-encoded and data-driven adversarial losses. They improve different aspects of registration performance in a non-overlapping way, justifying their combination. Despite fundamental distinctions between adult and fetal echo images, we show that these strategies can provide excellent registration results in both adult and fetal echocardiography using the publicly available CAMUS adult echo dataset and our private multi-demographic fetal echo dataset. Our approach outperforms traditional non-DL gold standard registration approaches, including Optical Flow and Elastix. Registration improvements could be translated to more accurate and precise clinical quantification of cardiac ejection fraction, demonstrating a potential for translation.
Pre-Trained Masked Image Model for Mobile Robot Navigation
Oct 10, 20232D top-down maps are commonly used for the navigation and exploration of mobile robots through unknown areas. Typically, the robot builds the navigation maps incrementally from local observations using onboard sensors. Recent works have shown that predicting the structural patterns in the environment through learning-based approaches can greatly enhance task efficiency. While many such works build task-specific networks using limited datasets, we show that the existing foundational vision networks can accomplish the same without any fine-tuning. Specifically, we use Masked Autoencoders, pre-trained on street images, to present novel applications for field-of-view expansion, single-agent topological exploration, and multi-agent exploration for indoor mapping, across different input modalities. Our work motivates the use of foundational vision models for generalized structure prediction-driven applications, especially in the dearth of training data. For more qualitative results see https://raaslab.org/projects/MIM4Robots.