 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shatter and Gather: Learning Referring Image Segmentation with Text Supervision
Aug 29, 2023
Referring image segmentation, the task of segmenting any arbitrary entities described in free-form texts, opens up a variety of vision applications. However, manual labeling of training data for this task is prohibitively costly, leading to lack of labeled data for training. We address this issue by a weakly supervised learning approach using text descriptions of training images as the only source of supervision. To this end, we first present a new model that discovers semantic entities in input image and then combines such entities relevant to text query to predict the mask of the referent. We also present a new loss function that allows the model to be trained without any further supervision. Our method was evaluated on four public benchmarks for referring image segmentation, where it clearly outperformed the existing method for the same task and recent open-vocabulary segmentation models on all the benchmarks.
ViTs are Everywhere: A Comprehensive Study Showcasing Vision Transformers in Different Domain
Oct 09, 2023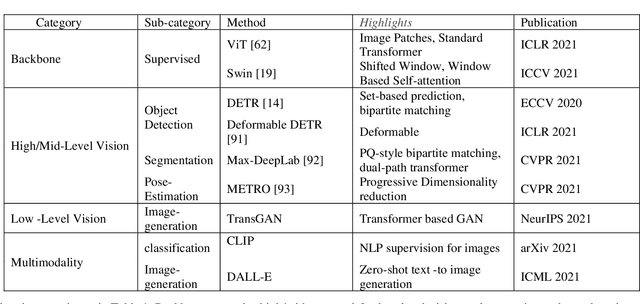
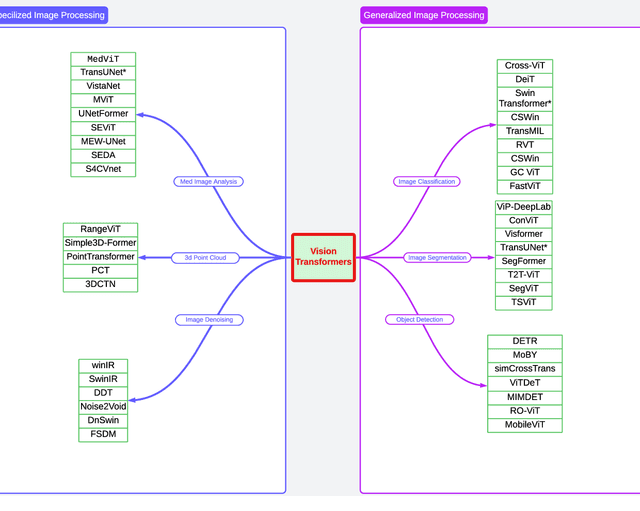
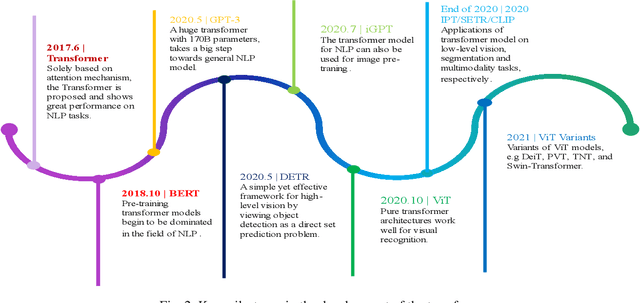
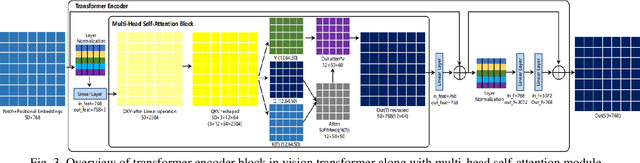
Transformer design is the de facto standard for natural language processing tasks. The success of the transformer design in natural language processing has lately piqued the interest of researchers in the domain of computer vision. When compared to Convolutional Neural Networks (CNNs), Vision Transformers (ViTs) are becoming more popular and dominant solutions for many vision problems. Transformer-based models outperform other types of networks, such as convolutional and recurrent neural networks, in a range of visual benchmarks. We evaluate various vision transformer models in this work by dividing them into distinct jobs and examining their benefits and drawbacks. ViTs can overcome several possible difficulties with convolutional neural networks (CNNs). The goal of this survey is to show the first use of ViTs in CV. In the first phase, we categorize various CV applications where ViTs are appropriate. Image classification, object identification, image segmentation, video transformer, image denoising, and NAS are all CV applications. Our next step will be to analyze the state-of-the-art in each area and identify the models that are currently available. In addition, we outline numerous open research difficulties as well as prospective research possibilities.
Semantic-Aware Adversarial Training for Reliable Deep Hashing Retrieval
Oct 23, 2023Deep hashing has been intensively studied and successfully applied in large-scale image retrieval systems due to its efficiency and effectiveness. Recent studies have recognized that the existence of adversarial examples poses a security threat to deep hashing models, that is, adversarial vulnerability. Notably, it is challenging to efficiently distill reliable semantic representatives for deep hashing to guide adversarial learning, and thereby it hinders the enhancement of adversarial robustness of deep hashing-based retrieval models. Moreover, current researches on adversarial training for deep hashing are hard to be formalized into a unified minimax structure. In this paper, we explore Semantic-Aware Adversarial Training (SAAT) for improving the adversarial robustness of deep hashing models. Specifically, we conceive a discriminative mainstay features learning (DMFL) scheme to construct semantic representatives for guiding adversarial learning in deep hashing. Particularly, our DMFL with the strict theoretical guarantee is adaptively optimized in a discriminative learning manner, where both discriminative and semantic properties are jointly considered. Moreover, adversarial examples are fabricated by maximizing the Hamming distance between the hash codes of adversarial samples and mainstay features, the efficacy of which is validated in the adversarial attack trials. Further, we, for the first time, formulate the formalized adversarial training of deep hashing into a unified minimax optimization under the guidance of the generated mainstay codes. Extensive experiments on benchmark datasets show superb attack performance against the state-of-the-art algorithms, meanwhile, the proposed adversarial training can effectively eliminate adversarial perturbations for trustworthy deep hashing-based retrieval. Our code is available at https://github.com/xandery-geek/SAAT.
RevColV2: Exploring Disentangled Representations in Masked Image Modeling
Sep 02, 2023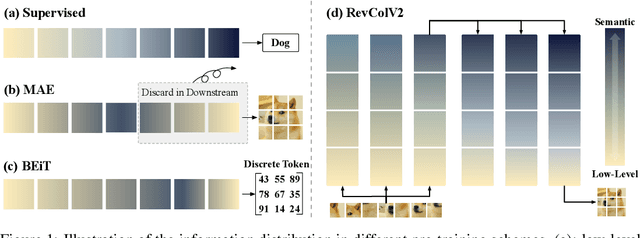

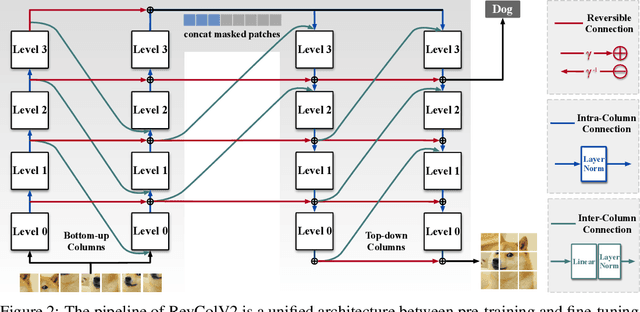
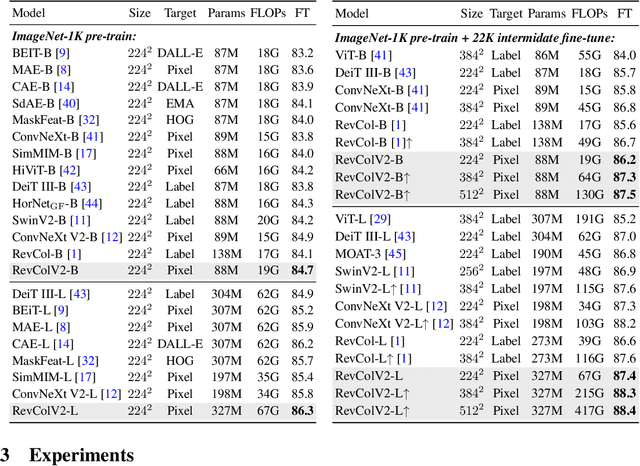
Masked image modeling (MIM) has become a prevalent pre-training setup for vision foundation models and attains promising performance. Despite its success, existing MIM methods discard the decoder network during downstream applications, resulting in inconsistent representations between pre-training and fine-tuning and can hamper downstream task performance. In this paper, we propose a new architecture, RevColV2, which tackles this issue by keeping the entire autoencoder architecture during both pre-training and fine-tuning. The main body of RevColV2 contains bottom-up columns and top-down columns, between which information is reversibly propagated and gradually disentangled. Such design enables our architecture with the nice property: maintaining disentangled low-level and semantic information at the end of the network in MIM pre-training. Our experimental results suggest that a foundation model with decoupled features can achieve competitive performance across multiple downstream vision tasks such as image classification, semantic segmentation and object detection. For example, after intermediate fine-tuning on ImageNet-22K dataset, RevColV2-L attains 88.4% top-1 accuracy on ImageNet-1K classification and 58.6 mIoU on ADE20K semantic segmentation. With extra teacher and large scale dataset, RevColv2-L achieves 62.1 box AP on COCO detection and 60.4 mIoU on ADE20K semantic segmentation. Code and models are released at https://github.com/megvii-research/RevCol
PAC Prediction Sets Under Label Shift
Oct 19, 2023Prediction sets capture uncertainty by predicting sets of labels rather than individual labels, enabling downstream decisions to conservatively account for all plausible outcomes. Conformal inference algorithms construct prediction sets guaranteed to contain the true label with high probability. These guarantees fail to hold in the face of distribution shift, which is precisely when reliable uncertainty quantification can be most useful. We propose a novel algorithm for constructing prediction sets with PAC guarantees in the label shift setting. This method estimates the predicted probabilities of the classes in a target domain, as well as the confusion matrix, then propagates uncertainty in these estimates through a Gaussian elimination algorithm to compute confidence intervals for importance weights. Finally, it uses these intervals to construct prediction sets. We evaluate our approach on five datasets: the CIFAR-10, ChestX-Ray and Entity-13 image datasets, the tabular CDC Heart dataset, and the AGNews text dataset. Our algorithm satisfies the PAC guarantee while producing smaller, more informative, prediction sets compared to several baselines.
Incremental Object Detection with CLIP
Oct 13, 2023In the incremental detection task, unlike the incremental classification task, data ambiguity exists due to the possibility of an image having different labeled bounding boxes in multiple continuous learning stages. This phenomenon often impairs the model's ability to learn new classes. However, the forward compatibility of the model is less considered in existing work, which hinders the model's suitability for incremental learning. To overcome this obstacle, we propose to use a language-visual model such as CLIP to generate text feature embeddings for different class sets, which enhances the feature space globally. We then employ the broad classes to replace the unavailable novel classes in the early learning stage to simulate the actual incremental scenario. Finally, we use the CLIP image encoder to identify potential objects in the proposals, which are classified into the background by the model. We modify the background labels of those proposals to known classes and add the boxes to the training set to alleviate the problem of data ambiguity. We evaluate our approach on various incremental learning settings on the PASCAL VOC 2007 dataset, and our approach outperforms state-of-the-art methods, particularly for the new classes.
Tumor-Centered Patching for Enhanced Medical Image Segmentation
Aug 23, 2023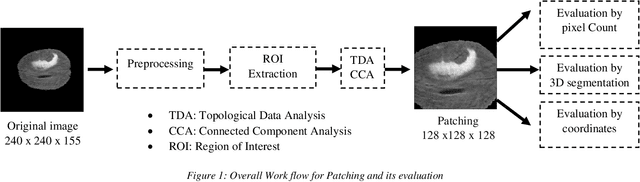
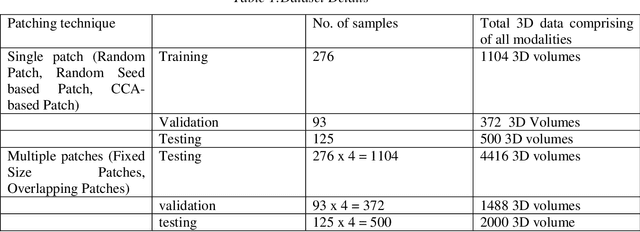
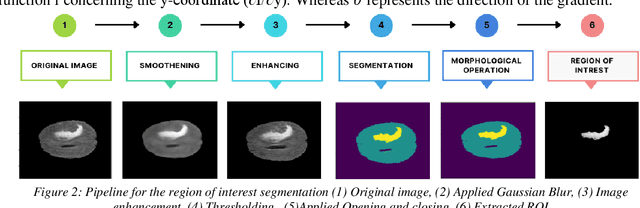
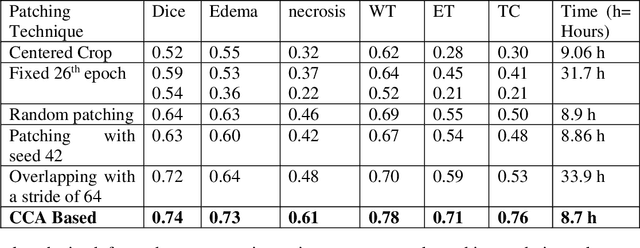
The realm of medical image diagnosis has advanced significantly with the integration of computer-aided diagnosis and surgical systems. However, challenges persist, particularly in achieving precise image segmentation. While deep learning techniques show potential, obstacles like limited resources, slow convergence, and class imbalance impede their effectiveness. Traditional patch-based methods, though common, struggle to capture intricate tumor boundaries and often lead to redundant samples, compromising computational efficiency and feature quality. To tackle these issues, this research introduces an innovative approach centered on the tumor itself for patch-based image analysis. This novel tumor-centered patching method aims to address the class imbalance and boundary deficiencies, enabling focused and accurate tumor segmentation. By aligning patches with the tumor's anatomical context, this technique enhances feature extraction accuracy and reduces computational load. Experimental results demonstrate improved class imbalance, with segmentation scores of 0.78, 0.76, and 0.71 for whole, core, and enhancing tumors, respectively using a lightweight simple U-Net. This approach shows potential for enhancing medical image segmentation and improving computer-aided diagnosis systems.
Enhanced Residual SwinV2 Transformer for Learned Image Compression
Aug 23, 2023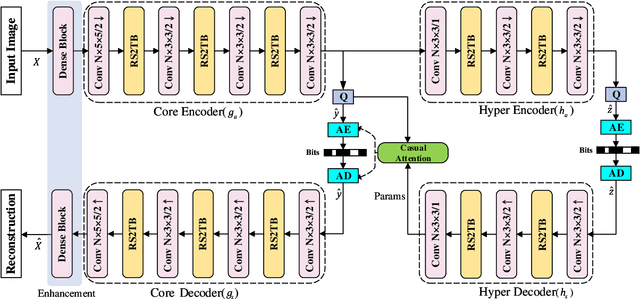
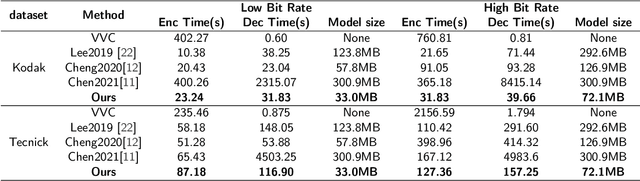
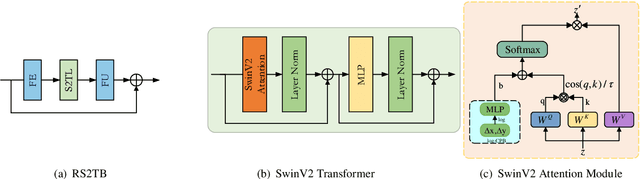

Recently, the deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. However, a challenge of many learning-based approaches is that they often achieve better performance via sacrificing complexity, which making practical deployment difficult. To alleviate this issue, in this paper, we propose an effective and efficient learned image compression framework based on an enhanced residual Swinv2 transformer. To enhance the nonlinear representation of images in our framework, we use a feature enhancement module that consists of three consecutive convolutional layers. In the subsequent coding and hyper coding steps, we utilize a SwinV2 transformer-based attention mechanism to process the input image. The SwinV2 model can help to reduce model complexity while maintaining high performance. Experimental results show that the proposed method achieves comparable performance compared to some recent learned image compression methods on Kodak and Tecnick datasets, and outperforms some traditional codecs including VVC. In particular, our method achieves comparable results while reducing model complexity by 56% compared to these recent methods.
Visual Data-Type Understanding does not emerge from Scaling Vision-Language Models
Oct 16, 2023Recent advances in the development of vision-language models (VLMs) are yielding remarkable success in recognizing visual semantic content, including impressive instances of compositional image understanding. Here, we introduce the novel task of Visual Data-Type Identification, a basic perceptual skill with implications for data curation (e.g., noisy data-removal from large datasets, domain-specific retrieval) and autonomous vision (e.g., distinguishing changing weather conditions from camera lens staining). We develop two datasets consisting of animal images altered across a diverse set of 27 visual data-types, spanning four broad categories. An extensive zero-shot evaluation of 39 VLMs, ranging from 100M to 80B parameters, shows a nuanced performance landscape. While VLMs are reasonably good at identifying certain stylistic \textit{data-types}, such as cartoons and sketches, they struggle with simpler data-types arising from basic manipulations like image rotations or additive noise. Our findings reveal that (i) model scaling alone yields marginal gains for contrastively-trained models like CLIP, and (ii) there is a pronounced drop in performance for the largest auto-regressively trained VLMs like OpenFlamingo. This finding points to a blind spot in current frontier VLMs: they excel in recognizing semantic content but fail to acquire an understanding of visual data-types through scaling. By analyzing the pre-training distributions of these models and incorporating data-type information into the captions during fine-tuning, we achieve a significant enhancement in performance. By exploring this previously uncharted task, we aim to set the stage for further advancing VLMs to equip them with visual data-type understanding. Code and datasets are released at https://github.com/bethgelab/DataTypeIdentification.
Compositional Representation Learning for Brain Tumour Segmentation
Oct 10, 2023For brain tumour segmentation, deep learning models can achieve human expert-level performance given a large amount of data and pixel-level annotations. However, the expensive exercise of obtaining pixel-level annotations for large amounts of data is not always feasible, and performance is often heavily reduced in a low-annotated data regime. To tackle this challenge, we adapt a mixed supervision framework, vMFNet, to learn robust compositional representations using unsupervised learning and weak supervision alongside non-exhaustive pixel-level pathology labels. In particular, we use the BraTS dataset to simulate a collection of 2-point expert pathology annotations indicating the top and bottom slice of the tumour (or tumour sub-regions: peritumoural edema, GD-enhancing tumour, and the necrotic / non-enhancing tumour) in each MRI volume, from which weak image-level labels that indicate the presence or absence of the tumour (or the tumour sub-regions) in the image are constructed. Then, vMFNet models the encoded image features with von-Mises-Fisher (vMF) distributions, via learnable and compositional vMF kernels which capture information about structures in the images. We show that good tumour segmentation performance can be achieved with a large amount of weakly labelled data but only a small amount of fully-annotated data. Interestingly, emergent learning of anatomical structures occurs in the compositional representation even given only supervision relating to pathology (tumour).