 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kosmos-G: Generating Images in Context with Multimodal Large Language Models
Oct 04, 2023
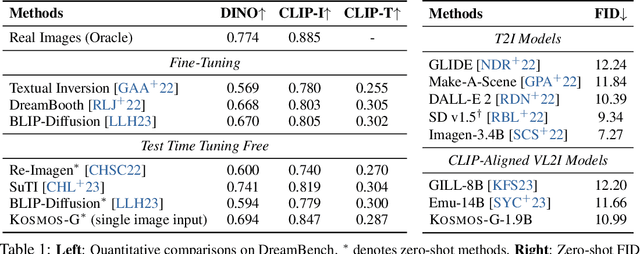
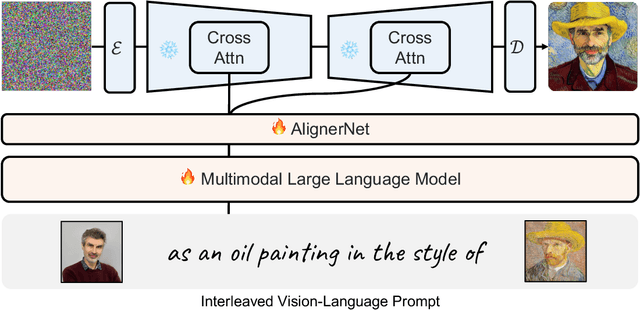
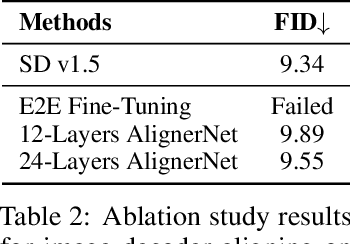
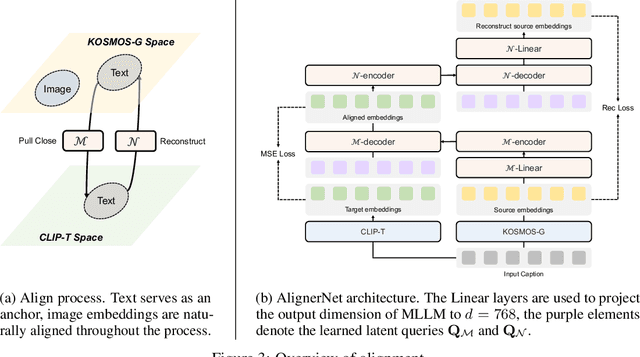
Recent advancements in text-to-image (T2I) and vision-language-to-image (VL2I) generation have made significant strides. However, the generation from generalized vision-language inputs, especially involving multiple images, remains under-explored. This paper presents Kosmos-G, a model that leverages the advanced perception capabilities of Multimodal Large Language Models (MLLMs) to tackle the aforementioned challenge. Our approach aligns the output space of MLLM with CLIP using the textual modality as an anchor and performs compositional instruction tuning on curated data. Kosmos-G demonstrates a unique capability of zero-shot multi-entity subject-driven generation. Notably, the score distillation instruction tuning requires no modifications to the image decoder. This allows for a seamless substitution of CLIP and effortless integration with a myriad of U-Net techniques ranging from fine-grained controls to personalized image decoder variants. We posit Kosmos-G as an initial attempt towards the goal of "image as a foreign language in image generation."
Heuristic Vision Pre-Training with Self-Supervised and Supervised Multi-Task Learning
Oct 11, 2023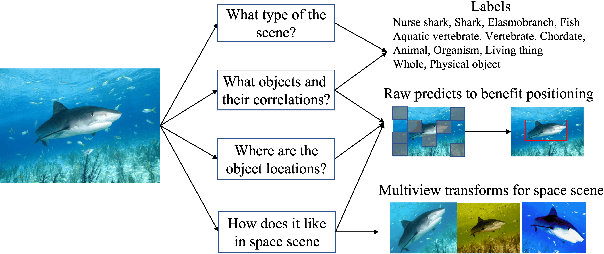
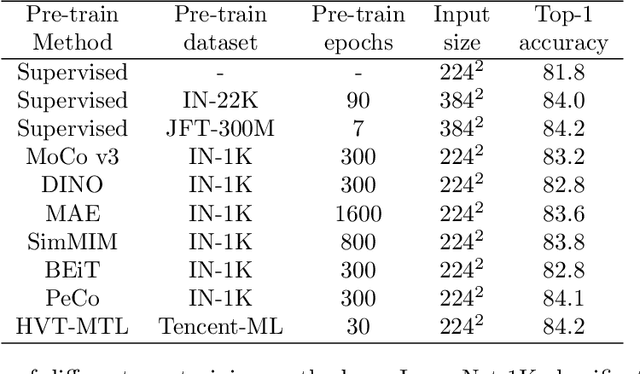
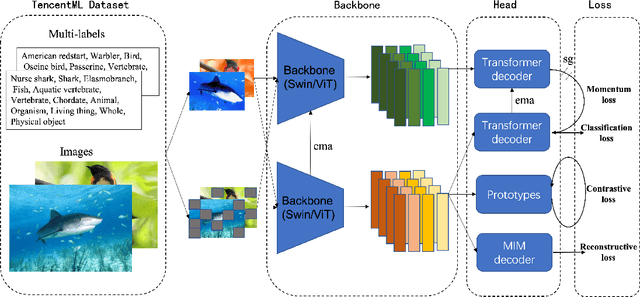
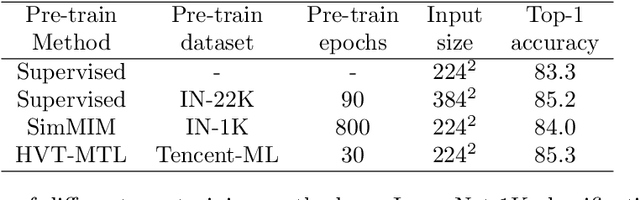
To mimic human vision with the way of recognizing the diverse and open world, foundation vision models are much critical. While recent techniques of self-supervised learning show the promising potentiality of this mission, we argue that signals from labelled data are also important for common-sense recognition, and properly chosen pre-text tasks can facilitate the efficiency of vision representation learning. To this end, we propose a novel pre-training framework by adopting both self-supervised and supervised visual pre-text tasks in a multi-task manner. Specifically, given an image, we take a heuristic way by considering its intrinsic style properties, inside objects with their locations and correlations, and how it looks like in 3D space for basic visual understanding. However, large-scale object bounding boxes and correlations are usually hard to achieve. Alternatively, we develop a hybrid method by leveraging both multi-label classification and self-supervised learning. On the one hand, under the multi-label supervision, the pre-trained model can explore the detailed information of an image, e.g., image types, objects, and part of semantic relations. On the other hand, self-supervised learning tasks, with respect to Masked Image Modeling (MIM) and contrastive learning, can help the model learn pixel details and patch correlations. Results show that our pre-trained models can deliver results on par with or better than state-of-the-art (SOTA) results on multiple visual tasks. For example, with a vanilla Swin-B backbone, we achieve 85.3\% top-1 accuracy on ImageNet-1K classification, 47.9 box AP on COCO object detection for Mask R-CNN, and 50.6 mIoU on ADE-20K semantic segmentation when using Upernet. The performance shows the ability of our vision foundation model to serve general purpose vision tasks.
RenAIssance: A Survey into AI Text-to-Image Generation in the Era of Large Model
Sep 02, 2023Text-to-image generation (TTI) refers to the usage of models that could process text input and generate high fidelity images based on text descriptions. Text-to-image generation using neural networks could be traced back to the emergence of Generative Adversial Network (GAN), followed by the autoregressive Transformer. Diffusion models are one prominent type of generative model used for the generation of images through the systematic introduction of noises with repeating steps. As an effect of the impressive results of diffusion models on image synthesis, it has been cemented as the major image decoder used by text-to-image models and brought text-to-image generation to the forefront of machine-learning (ML) research. In the era of large models, scaling up model size and the integration with large language models have further improved the performance of TTI models, resulting the generation result nearly indistinguishable from real-world images, revolutionizing the way we retrieval images. Our explorative study has incentivised us to think that there are further ways of scaling text-to-image models with the combination of innovative model architectures and prediction enhancement techniques. We have divided the work of this survey into five main sections wherein we detail the frameworks of major literature in order to delve into the different types of text-to-image generation methods. Following this we provide a detailed comparison and critique of these methods and offer possible pathways of improvement for future work. In the future work, we argue that TTI development could yield impressive productivity improvements for creation, particularly in the context of the AIGC era, and could be extended to more complex tasks such as video generation and 3D generation.
EGIC: Enhanced Low-Bit-Rate Generative Image Compression Guided by Semantic Segmentation
Sep 06, 2023We introduce EGIC, a novel generative image compression method that allows traversing the distortion-perception curve efficiently from a single model. Specifically, we propose an implicitly encoded variant of image interpolation that predicts the residual between a MSE-optimized and GAN-optimized decoder output. On the receiver side, the user can then control the impact of the residual on the GAN-based reconstruction. Together with improved GAN-based building blocks, EGIC outperforms a wide-variety of perception-oriented and distortion-oriented baselines, including HiFiC, MRIC and DIRAC, while performing almost on par with VTM-20.0 on the distortion end. EGIC is simple to implement, very lightweight (e.g. 0.18x model parameters compared to HiFiC) and provides excellent interpolation characteristics, which makes it a promising candidate for practical applications targeting the low bit range.
Mutual-Guided Dynamic Network for Image Fusion
Aug 24, 2023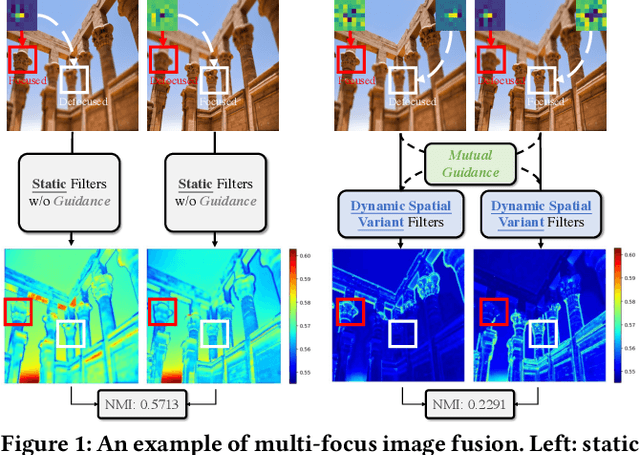

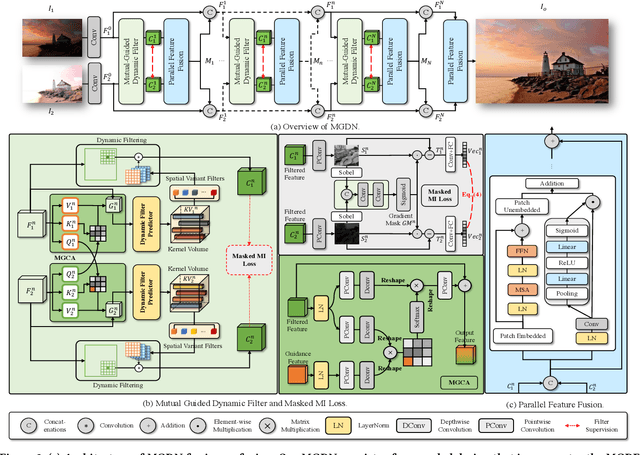
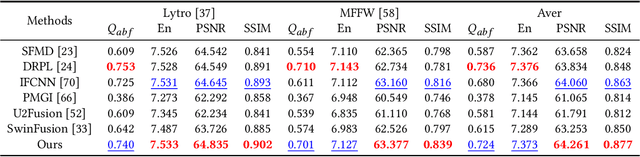
Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
CorrEmbed: Evaluating Pre-trained Model Image Similarity Efficacy with a Novel Metric
Aug 30, 2023
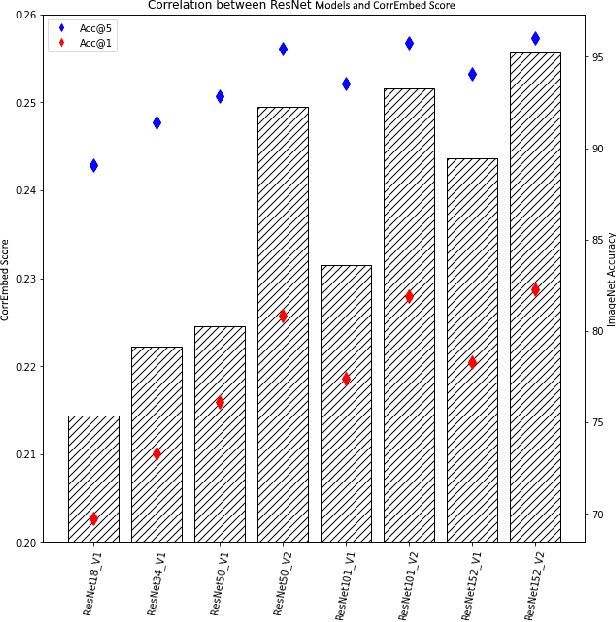
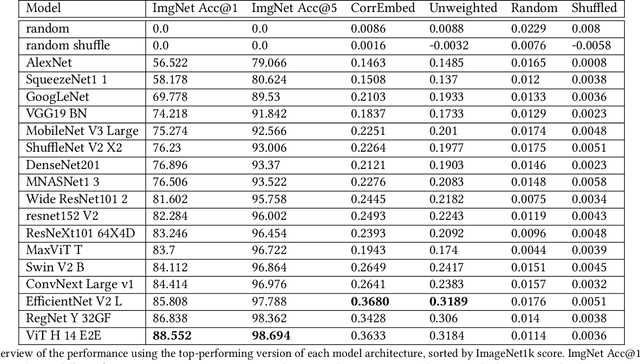
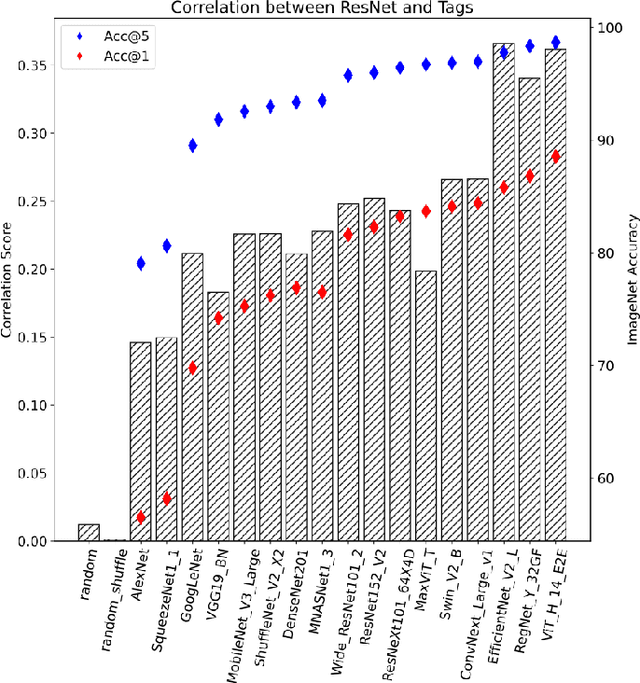
Detecting visually similar images is a particularly useful attribute to look to when calculating product recommendations. Embedding similarity, which utilizes pre-trained computer vision models to extract high-level image features, has demonstrated remarkable efficacy in identifying images with similar compositions. However, there is a lack of methods for evaluating the embeddings generated by these models, as conventional loss and performance metrics do not adequately capture their performance in image similarity search tasks. In this paper, we evaluate the viability of the image embeddings from numerous pre-trained computer vision models using a novel approach named CorrEmbed. Our approach computes the correlation between distances in image embeddings and distances in human-generated tag vectors. We extensively evaluate numerous pre-trained Torchvision models using this metric, revealing an intuitive relationship of linear scaling between ImageNet1k accuracy scores and tag-correlation scores. Importantly, our method also identifies deviations from this pattern, providing insights into how different models capture high-level image features. By offering a robust performance evaluation of these pre-trained models, CorrEmbed serves as a valuable tool for researchers and practitioners seeking to develop effective, data-driven approaches to similar item recommendations in fashion retail.
Making Multimodal Generation Easier: When Diffusion Models Meet LLMs
Oct 13, 2023We present EasyGen, an efficient model designed to enhance multimodal understanding and generation by harnessing the capabilities of diffusion models and large language models (LLMs). Unlike existing multimodal models that predominately depend on encoders like CLIP or ImageBind and need ample amounts of training data to bridge the gap between modalities, EasyGen is built upon a bidirectional conditional diffusion model named BiDiffuser, which promotes more efficient interactions between modalities. EasyGen handles image-to-text generation by integrating BiDiffuser and an LLM via a simple projection layer. Unlike most existing multimodal models that are limited to generating text responses, EasyGen can also facilitate text-to-image generation by leveraging the LLM to create textual descriptions, which can be interpreted by BiDiffuser to generate appropriate visual responses. Extensive quantitative and qualitative experiments demonstrate the effectiveness of EasyGen, whose training can be easily achieved in a lab setting. The source code is available at https://github.com/zxy556677/EasyGen.
Robust Visual Imitation Learning with Inverse Dynamics Representations
Oct 22, 2023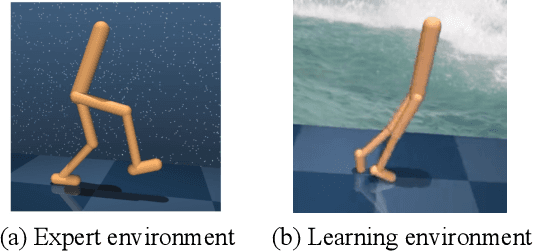
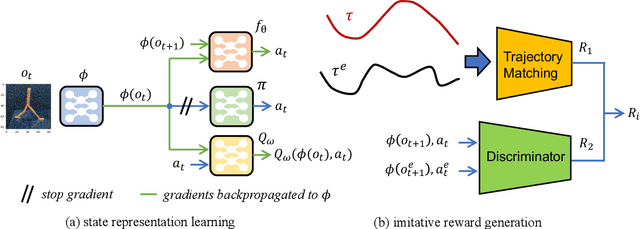
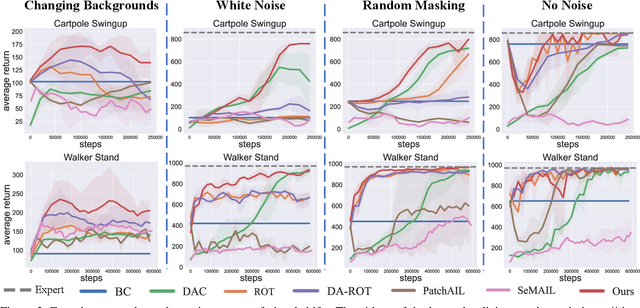
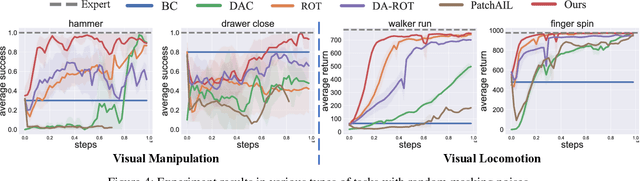
Imitation learning (IL) has achieved considerable success in solving complex sequential decision-making problems. However, current IL methods mainly assume that the environment for learning policies is the same as the environment for collecting expert datasets. Therefore, these methods may fail to work when there are slight differences between the learning and expert environments, especially for challenging problems with high-dimensional image observations. However, in real-world scenarios, it is rare to have the chance to collect expert trajectories precisely in the target learning environment. To address this challenge, we propose a novel robust imitation learning approach, where we develop an inverse dynamics state representation learning objective to align the expert environment and the learning environment. With the abstract state representation, we design an effective reward function, which thoroughly measures the similarity between behavior data and expert data not only element-wise, but also from the trajectory level. We conduct extensive experiments to evaluate the proposed approach under various visual perturbations and in diverse visual control tasks. Our approach can achieve a near-expert performance in most environments, and significantly outperforms the state-of-the-art visual IL methods and robust IL methods.
ASC: Appearance and Structure Consistency for Unsupervised Domain Adaptation in Fetal Brain MRI Segmentation
Oct 22, 2023Automatic tissue segmentation of fetal brain images is essential for the quantitative analysis of prenatal neurodevelopment. However, producing voxel-level annotations of fetal brain imaging is time-consuming and expensive. To reduce labeling costs, we propose a practical unsupervised domain adaptation (UDA) setting that adapts the segmentation labels of high-quality fetal brain atlases to unlabeled fetal brain MRI data from another domain. To address the task, we propose a new UDA framework based on Appearance and Structure Consistency, named ASC. We adapt the segmentation model to the appearances of different domains by constraining the consistency before and after a frequency-based image transformation, which is to swap the appearance between brain MRI data and atlases. Consider that even in the same domain, the fetal brain images of different gestational ages could have significant variations in the anatomical structures. To make the model adapt to the structural variations in the target domain, we further encourage prediction consistency under different structural perturbations. Extensive experiments on FeTA 2021 benchmark demonstrate the effectiveness of our ASC in comparison to registration-based, semi-supervised learning-based, and existing UDA-based methods.
Hyperspectral Image Denoising via Self-Modulating Convolutional Neural Networks
Sep 15, 2023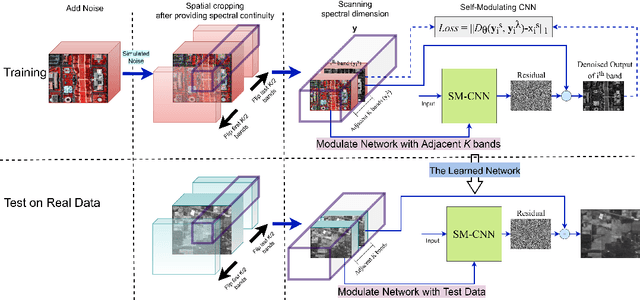
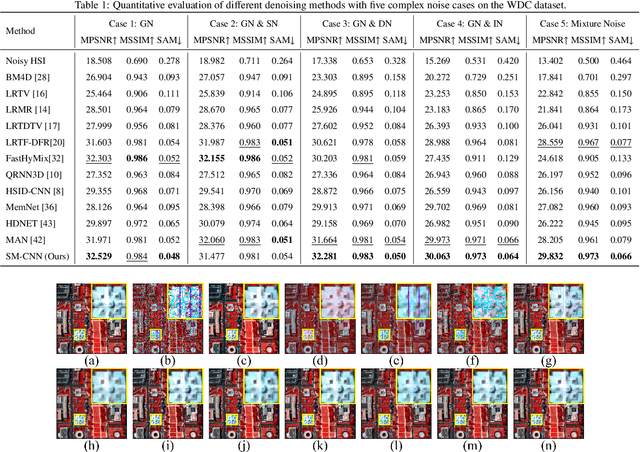
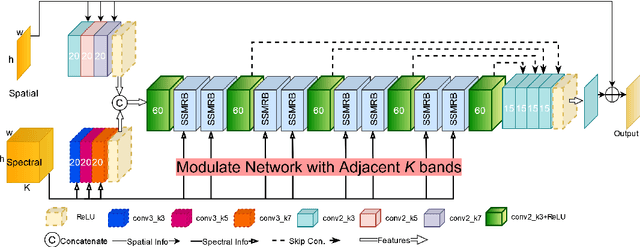
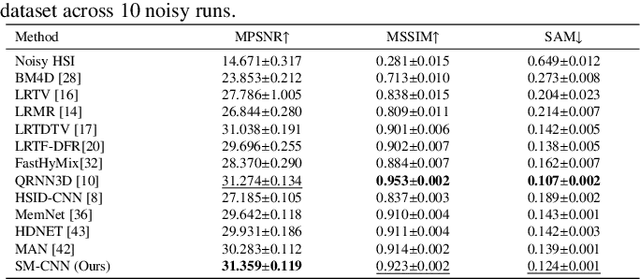
Compared to natural images, hyperspectral images (HSIs) consist of a large number of bands, with each band capturing different spectral information from a certain wavelength, even some beyond the visible spectrum. These characteristics of HSIs make them highly effective for remote sensing applications. That said, the existing hyperspectral imaging devices introduce severe degradation in HSIs. Hence, hyperspectral image denoising has attracted lots of attention by the community lately. While recent deep HSI denoising methods have provided effective solutions, their performance under real-life complex noise remains suboptimal, as they lack adaptability to new data. To overcome these limitations, in our work, we introduce a self-modulating convolutional neural network which we refer to as SM-CNN, which utilizes correlated spectral and spatial information. At the core of the model lies a novel block, which we call spectral self-modulating residual block (SSMRB), that allows the network to transform the features in an adaptive manner based on the adjacent spectral data, enhancing the network's ability to handle complex noise. In particular, the introduction of SSMRB transforms our denoising network into a dynamic network that adapts its predicted features while denoising every input HSI with respect to its spatio-spectral characteristics. Experimental analysis on both synthetic and real data shows that the proposed SM-CNN outperforms other state-of-the-art HSI denoising methods both quantitatively and qualitatively on public benchmark datasets.