 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Med-DANet V2: A Flexible Dynamic Architecture for Efficient Medical Volumetric Segmentation
Oct 28, 2023
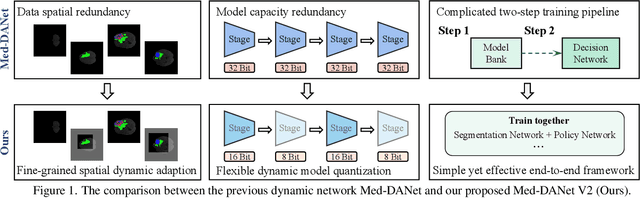
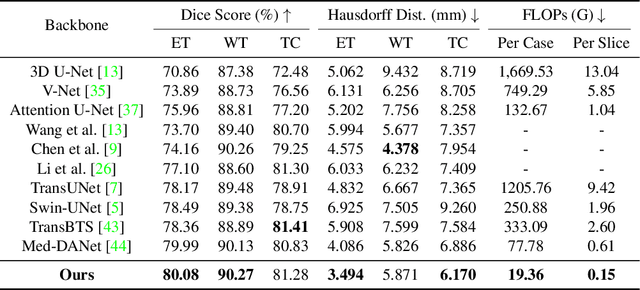
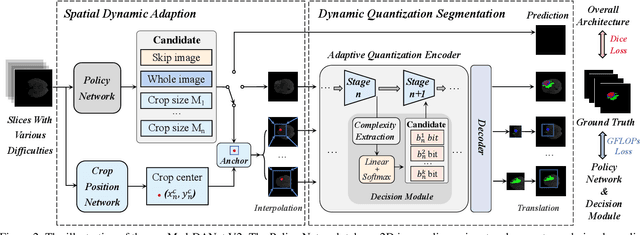
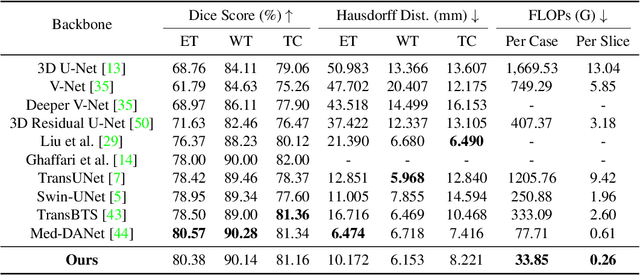
Recent works have shown that the computational efficiency of 3D medical image (e.g. CT and MRI) segmentation can be impressively improved by dynamic inference based on slice-wise complexity. As a pioneering work, a dynamic architecture network for medical volumetric segmentation (i.e. Med-DANet) has achieved a favorable accuracy and efficiency trade-off by dynamically selecting a suitable 2D candidate model from the pre-defined model bank for different slices. However, the issues of incomplete data analysis, high training costs, and the two-stage pipeline in Med-DANet require further improvement. To this end, this paper further explores a unified formulation of the dynamic inference framework from the perspective of both the data itself and the model structure. For each slice of the input volume, our proposed method dynamically selects an important foreground region for segmentation based on the policy generated by our Decision Network and Crop Position Network. Besides, we propose to insert a stage-wise quantization selector to the employed segmentation model (e.g. U-Net) for dynamic architecture adapting. Extensive experiments on BraTS 2019 and 2020 show that our method achieves comparable or better performance than previous state-of-the-art methods with much less model complexity. Compared with previous methods Med-DANet and TransBTS with dynamic and static architecture respectively, our framework improves the model efficiency by up to nearly 4.1 and 17.3 times with comparable segmentation results on BraTS 2019.
Electrical Impedance Tomography: A Fair Comparative Study on Deep Learning and Analytic-based Approaches
Oct 28, 2023Electrical Impedance Tomography (EIT) is a powerful imaging technique with diverse applications, e.g., medical diagnosis, industrial monitoring, and environmental studies. The EIT inverse problem is about inferring the internal conductivity distribution of an object from measurements taken on its boundary. It is severely ill-posed, necessitating advanced computational methods for accurate image reconstructions. Recent years have witnessed significant progress, driven by innovations in analytic-based approaches and deep learning. This review explores techniques for solving the EIT inverse problem, focusing on the interplay between contemporary deep learning-based strategies and classical analytic-based methods. Four state-of-the-art deep learning algorithms are rigorously examined, harnessing the representational capabilities of deep neural networks to reconstruct intricate conductivity distributions. In parallel, two analytic-based methods, rooted in mathematical formulations and regularisation techniques, are dissected for their strengths and limitations. These methodologies are evaluated through various numerical experiments, encompassing diverse scenarios that reflect real-world complexities. A suite of performance metrics is employed to assess the efficacy of these methods. These metrics collectively provide a nuanced understanding of the methods' ability to capture essential features and delineate complex conductivity patterns. One novel feature of the study is the incorporation of variable conductivity scenarios, introducing a level of heterogeneity that mimics textured inclusions. This departure from uniform conductivity assumptions mimics realistic scenarios where tissues or materials exhibit spatially varying electrical properties. Exploring how each method responds to such variable conductivity scenarios opens avenues for understanding their robustness and adaptability.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
Bellybutton: Accessible and Customizable Deep-Learning Image Segmentation
Aug 31, 2023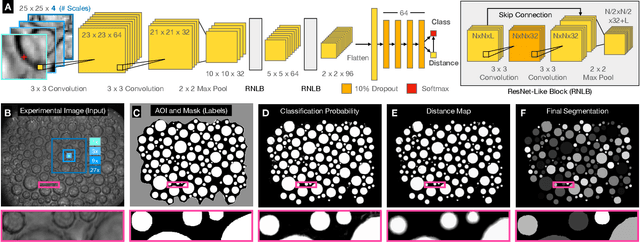


The conversion of raw images into quantifiable data can be a major hurdle in experimental research, and typically involves identifying region(s) of interest, a process known as segmentation. Machine learning tools for image segmentation are often specific to a set of tasks, such as tracking cells, or require substantial compute or coding knowledge to train and use. Here we introduce an easy-to-use (no coding required), image segmentation method, using a 15-layer convolutional neural network that can be trained on a laptop: Bellybutton. The algorithm trains on user-provided segmentation of example images, but, as we show, just one or even a portion of one training image can be sufficient in some cases. We detail the machine learning method and give three use cases where Bellybutton correctly segments images despite substantial lighting, shape, size, focus, and/or structure variation across the regions(s) of interest. Instructions for easy download and use, with further details and the datasets used in this paper are available at pypi.org/project/Bellybuttonseg.
A Generic Fundus Image Enhancement Network Boosted by Frequency Self-supervised Representation Learning
Sep 02, 2023



Fundus photography is prone to suffer from image quality degradation that impacts clinical examination performed by ophthalmologists or intelligent systems. Though enhancement algorithms have been developed to promote fundus observation on degraded images, high data demands and limited applicability hinder their clinical deployment. To circumvent this bottleneck, a generic fundus image enhancement network (GFE-Net) is developed in this study to robustly correct unknown fundus images without supervised or extra data. Levering image frequency information, self-supervised representation learning is conducted to learn robust structure-aware representations from degraded images. Then with a seamless architecture that couples representation learning and image enhancement, GFE-Net can accurately correct fundus images and meanwhile preserve retinal structures. Comprehensive experiments are implemented to demonstrate the effectiveness and advantages of GFE-Net. Compared with state-of-the-art algorithms, GFE-Net achieves superior performance in data dependency, enhancement performance, deployment efficiency, and scale generalizability. Follow-up fundus image analysis is also facilitated by GFE-Net, whose modules are respectively verified to be effective for image enhancement.
Advanced Underwater Image Restoration in Complex Illumination Conditions
Sep 05, 2023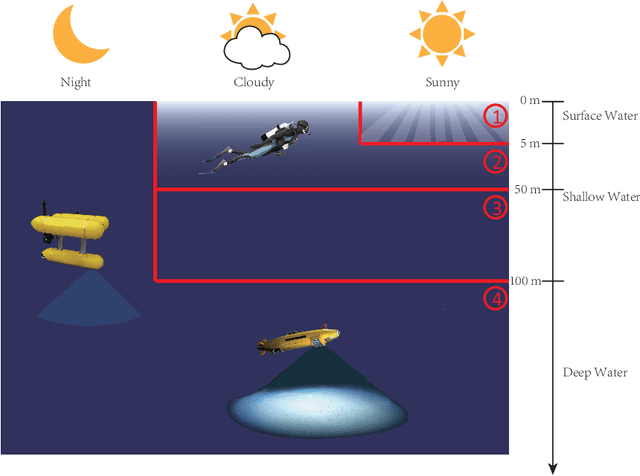

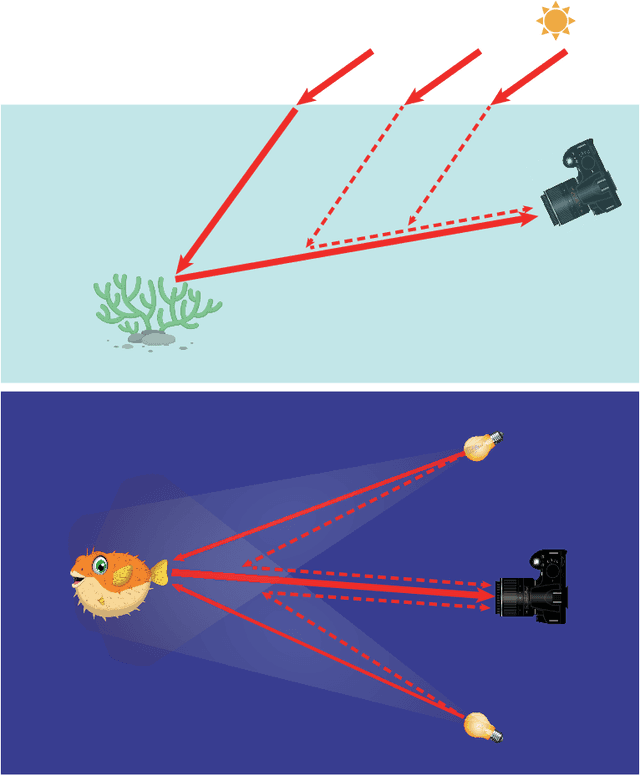
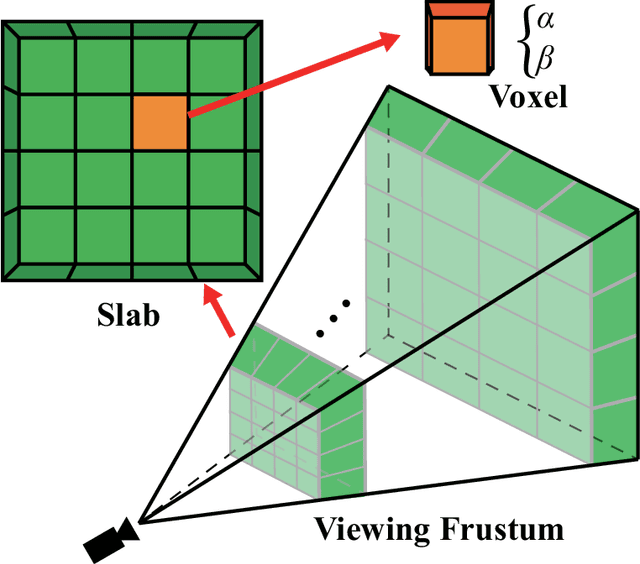
Underwater image restoration has been a challenging problem for decades since the advent of underwater photography. Most solutions focus on shallow water scenarios, where the scene is uniformly illuminated by the sunlight. However, the vast majority of uncharted underwater terrain is located beyond 200 meters depth where natural light is scarce and artificial illumination is needed. In such cases, light sources co-moving with the camera, dynamically change the scene appearance, which make shallow water restoration methods inadequate. In particular for multi-light source systems (composed of dozens of LEDs nowadays), calibrating each light is time-consuming, error-prone and tedious, and we observe that only the integrated illumination within the viewing volume of the camera is critical, rather than the individual light sources. The key idea of this paper is therefore to exploit the appearance changes of objects or the seafloor, when traversing the viewing frustum of the camera. Through new constraints assuming Lambertian surfaces, corresponding image pixels constrain the light field in front of the camera, and for each voxel a signal factor and a backscatter value are stored in a volumetric grid that can be used for very efficient image restoration of camera-light platforms, which facilitates consistently texturing large 3D models and maps that would otherwise be dominated by lighting and medium artifacts. To validate the effectiveness of our approach, we conducted extensive experiments on simulated and real-world datasets. The results of these experiments demonstrate the robustness of our approach in restoring the true albedo of objects, while mitigating the influence of lighting and medium effects. Furthermore, we demonstrate our approach can be readily extended to other scenarios, including in-air imaging with artificial illumination or other similar cases.
Myriad: Large Multimodal Model by Applying Vision Experts for Industrial Anomaly Detection
Oct 29, 2023Existing industrial anomaly detection (IAD) methods predict anomaly scores for both anomaly detection and localization. However, they struggle to perform a multi-turn dialog and detailed descriptions for anomaly regions, e.g., color, shape, and categories of industrial anomalies. Recently, large multimodal (i.e., vision and language) models (LMMs) have shown eminent perception abilities on multiple vision tasks such as image captioning, visual understanding, visual reasoning, etc., making it a competitive potential choice for more comprehensible anomaly detection. However, the knowledge about anomaly detection is absent in existing general LMMs, while training a specific LMM for anomaly detection requires a tremendous amount of annotated data and massive computation resources. In this paper, we propose a novel large multi-modal model by applying vision experts for industrial anomaly detection (dubbed Myriad), which leads to definite anomaly detection and high-quality anomaly description. Specifically, we adopt MiniGPT-4 as the base LMM and design an Expert Perception module to embed the prior knowledge from vision experts as tokens which are intelligible to Large Language Models (LLMs). To compensate for the errors and confusions of vision experts, we introduce a domain adapter to bridge the visual representation gaps between generic and industrial images. Furthermore, we propose a Vision Expert Instructor, which enables the Q-Former to generate IAD domain vision-language tokens according to vision expert prior. Extensive experiments on MVTec-AD and VisA benchmarks demonstrate that our proposed method not only performs favorably against state-of-the-art methods under the 1-class and few-shot settings, but also provide definite anomaly prediction along with detailed descriptions in IAD domain.
Multi-scale Diffusion Denoised Smoothing
Oct 26, 2023Along with recent diffusion models, randomized smoothing has become one of a few tangible approaches that offers adversarial robustness to models at scale, e.g., those of large pre-trained models. Specifically, one can perform randomized smoothing on any classifier via a simple "denoise-and-classify" pipeline, so-called denoised smoothing, given that an accurate denoiser is available - such as diffusion model. In this paper, we present scalable methods to address the current trade-off between certified robustness and accuracy in denoised smoothing. Our key idea is to "selectively" apply smoothing among multiple noise scales, coined multi-scale smoothing, which can be efficiently implemented with a single diffusion model. This approach also suggests a new objective to compare the collective robustness of multi-scale smoothed classifiers, and questions which representation of diffusion model would maximize the objective. To address this, we propose to further fine-tune diffusion model (a) to perform consistent denoising whenever the original image is recoverable, but (b) to generate rather diverse outputs otherwise. Our experiments show that the proposed multi-scale smoothing scheme combined with diffusion fine-tuning enables strong certified robustness available with high noise level while maintaining its accuracy closer to non-smoothed classifiers.
DiffS2UT: A Semantic Preserving Diffusion Model for Textless Direct Speech-to-Speech Translation
Oct 26, 2023While Diffusion Generative Models have achieved great success on image generation tasks, how to efficiently and effectively incorporate them into speech generation especially translation tasks remains a non-trivial problem. Specifically, due to the low information density of speech data, the transformed discrete speech unit sequence is much longer than the corresponding text transcription, posing significant challenges to existing auto-regressive models. Furthermore, it is not optimal to brutally apply discrete diffusion on the speech unit sequence while disregarding the continuous space structure, which will degrade the generation performance significantly. In this paper, we propose a novel diffusion model by applying the diffusion forward process in the \textit{continuous} speech representation space, while employing the diffusion backward process in the \textit{discrete} speech unit space. In this way, we preserve the semantic structure of the continuous speech representation space in the diffusion process and integrate the continuous and discrete diffusion models. We conduct extensive experiments on the textless direct speech-to-speech translation task, where the proposed method achieves comparable results to the computationally intensive auto-regressive baselines (500 steps on average) with significantly fewer decoding steps (50 steps).
Sign Languague Recognition without frame-sequencing constraints: A proof of concept on the Argentinian Sign Language
Oct 26, 2023Automatic sign language recognition (SLR) is an important topic within the areas of human-computer interaction and machine learning. On the one hand, it poses a complex challenge that requires the intervention of various knowledge areas, such as video processing, image processing, intelligent systems and linguistics. On the other hand, robust recognition of sign language could assist in the translation process and the integration of hearing-impaired people, as well as the teaching of sign language for the hearing population. SLR systems usually employ Hidden Markov Models, Dynamic Time Warping or similar models to recognize signs. Such techniques exploit the sequential ordering of frames to reduce the number of hypothesis. This paper presents a general probabilistic model for sign classification that combines sub-classifiers based on different types of features such as position, movement and handshape. The model employs a bag-of-words approach in all classification steps, to explore the hypothesis that ordering is not essential for recognition. The proposed model achieved an accuracy rate of 97% on an Argentinian Sign Language dataset containing 64 classes of signs and 3200 samples, providing some evidence that indeed recognition without ordering is possible.