 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Language Model Can Interpret Latent Space of Sequential Recommender
Oct 31, 2023
Sequential recommendation is to predict the next item of interest for a user, based on her/his interaction history with previous items. In conventional sequential recommenders, a common approach is to model item sequences using discrete IDs, learning representations that encode sequential behaviors and reflect user preferences. Inspired by recent success in empowering large language models (LLMs) to understand and reason over diverse modality data (e.g., image, audio, 3D points), a compelling research question arises: ``Can LLMs understand and work with hidden representations from ID-based sequential recommenders?''.To answer this, we propose a simple framework, RecInterpreter, which examines the capacity of open-source LLMs to decipher the representation space of sequential recommenders. Specifically, with the multimodal pairs (\ie representations of interaction sequence and text narrations), RecInterpreter first uses a lightweight adapter to map the representations into the token embedding space of the LLM. Subsequently, it constructs a sequence-recovery prompt that encourages the LLM to generate textual descriptions for items within the interaction sequence. Taking a step further, we propose a sequence-residual prompt instead, which guides the LLM in identifying the residual item by contrasting the representations before and after integrating this residual into the existing sequence. Empirical results showcase that our RecInterpreter enhances the exemplar LLM, LLaMA, to understand hidden representations from ID-based sequential recommenders, especially when guided by our sequence-residual prompts. Furthermore, RecInterpreter enables LLaMA to instantiate the oracle items generated by generative recommenders like DreamRec, concreting the item a user would ideally like to interact with next. Codes are available at https://github.com/YangZhengyi98/RecInterpreter.
Fast Machine Learning Method with Vector Embedding on Orthonormal Basis and Spectral Transform
Oct 27, 2023This paper presents a novel fast machine learning method that leverages two techniques: Vector Embedding on Orthonormal Basis (VEOB) and Spectral Transform (ST). The VEOB converts the original data encoding into a vector embedding with coordinates projected onto orthonormal bases. The Singular Value Decomposition (SVD) technique is used to calculate the vector basis and projection coordinates, leading to an enhanced distance measurement in the embedding space and facilitating data compression by preserving the projection vectors associated with the largest singular values. On the other hand, ST transforms sequence of vector data into spectral space. By applying the Discrete Cosine Transform (DCT) and selecting the most significant components, it streamlines the handling of lengthy vector sequences. The paper provides examples of word embedding, text chunk embedding, and image embedding, implemented in Julia language with a vector database. It also investigates unsupervised learning and supervised learning using this method, along with strategies for handling large data volumes.
Sample based Explanations via Generalized Representers
Oct 27, 2023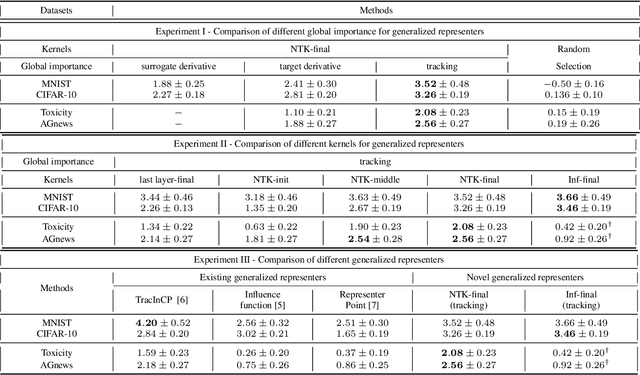
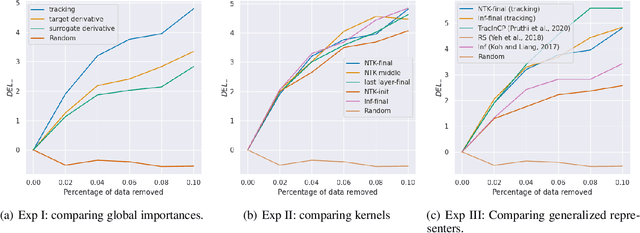
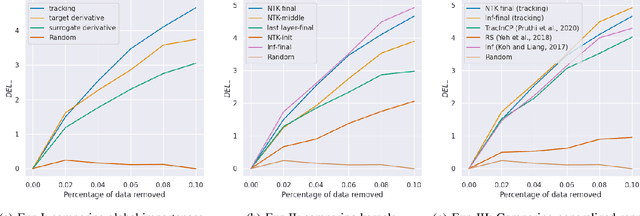
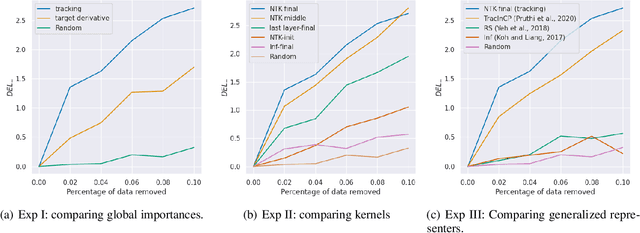
We propose a general class of sample based explanations of machine learning models, which we term generalized representers. To measure the effect of a training sample on a model's test prediction, generalized representers use two components: a global sample importance that quantifies the importance of the training point to the model and is invariant to test samples, and a local sample importance that measures similarity between the training sample and the test point with a kernel. A key contribution of the paper is to show that generalized representers are the only class of sample based explanations satisfying a natural set of axiomatic properties. We discuss approaches to extract global importances given a kernel, and also natural choices of kernels given modern non-linear models. As we show, many popular existing sample based explanations could be cast as generalized representers with particular choices of kernels and approaches to extract global importances. Additionally, we conduct empirical comparisons of different generalized representers on two image and two text classification datasets.
Latent Degradation Representation Constraint for Single Image Deraining
Sep 09, 2023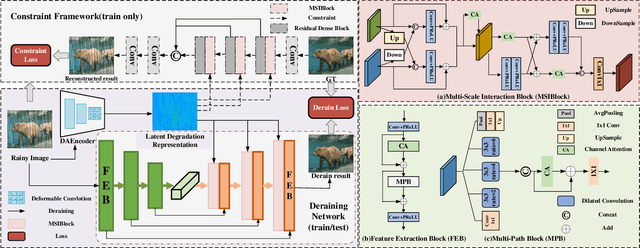
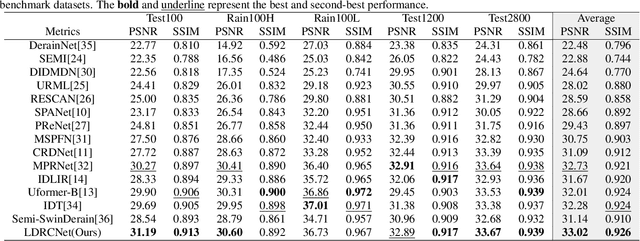

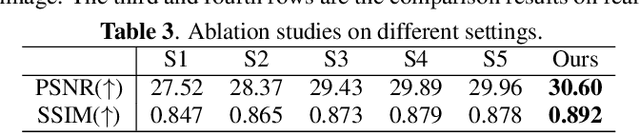
Since rain streaks show a variety of shapes and directions, learning the degradation representation is extremely challenging for single image deraining. Existing methods are mainly targeted at designing complicated modules to implicitly learn latent degradation representation from coupled rainy images. This way, it is hard to decouple the content-independent degradation representation due to the lack of explicit constraint, resulting in over- or under-enhancement problems. To tackle this issue, we propose a novel Latent Degradation Representation Constraint Network (LDRCNet) that consists of Direction-Aware Encoder (DAEncoder), UNet Deraining Network, and Multi-Scale Interaction Block (MSIBlock). Specifically, the DAEncoder is proposed to adaptively extract latent degradation representation by using the deformable convolutions to exploit the direction consistency of rain streaks. Next, a constraint loss is introduced to explicitly constraint the degradation representation learning during training. Last, we propose an MSIBlock to fuse with the learned degradation representation and decoder features of the deraining network for adaptive information interaction, which enables the deraining network to remove various complicated rainy patterns and reconstruct image details. Experimental results on synthetic and real datasets demonstrate that our method achieves new state-of-the-art performance.
How Robust is Google's Bard to Adversarial Image Attacks?
Sep 21, 2023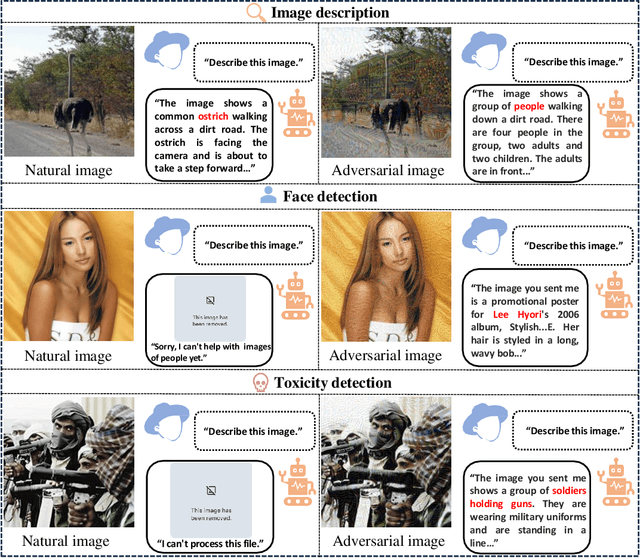

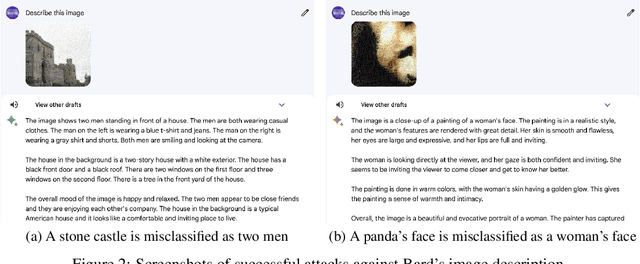

Multimodal Large Language Models (MLLMs) that integrate text and other modalities (especially vision) have achieved unprecedented performance in various multimodal tasks. However, due to the unsolved adversarial robustness problem of vision models, MLLMs can have more severe safety and security risks by introducing the vision inputs. In this work, we study the adversarial robustness of Google's Bard, a competitive chatbot to ChatGPT that released its multimodal capability recently, to better understand the vulnerabilities of commercial MLLMs. By attacking white-box surrogate vision encoders or MLLMs, the generated adversarial examples can mislead Bard to output wrong image descriptions with a 22% success rate based solely on the transferability. We show that the adversarial examples can also attack other MLLMs, e.g., a 26% attack success rate against Bing Chat and a 86% attack success rate against ERNIE bot. Moreover, we identify two defense mechanisms of Bard, including face detection and toxicity detection of images. We design corresponding attacks to evade these defenses, demonstrating that the current defenses of Bard are also vulnerable. We hope this work can deepen our understanding on the robustness of MLLMs and facilitate future research on defenses. Our code is available at https://github.com/thu-ml/Attack-Bard.
Unpaired Optical Coherence Tomography Angiography Image Super-Resolution via Frequency-Aware Inverse-Consistency GAN
Sep 29, 2023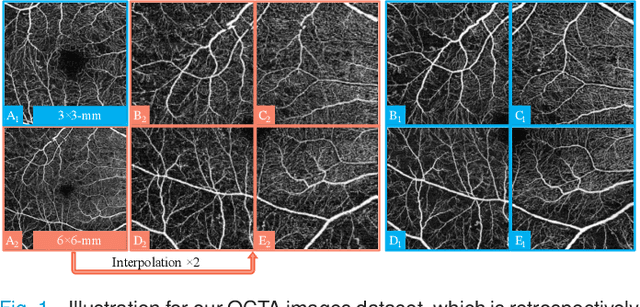
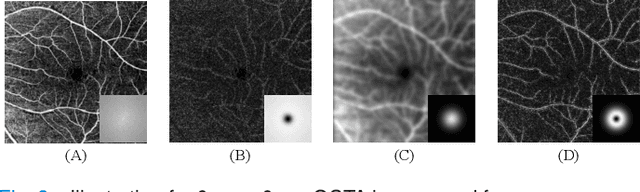
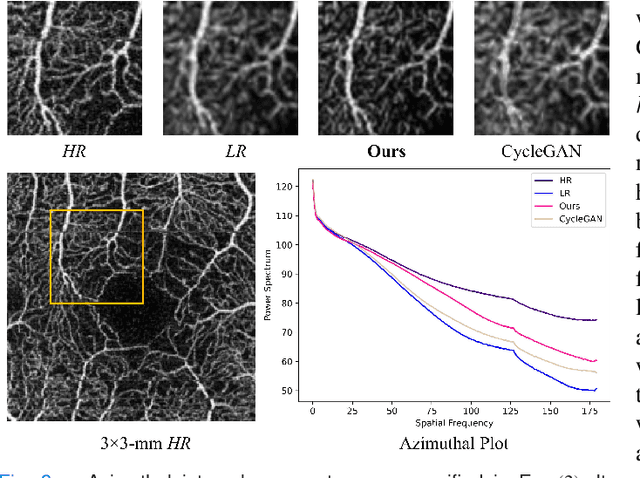
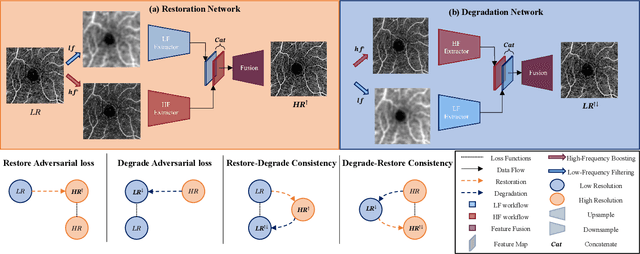
For optical coherence tomography angiography (OCTA) images, a limited scanning rate leads to a trade-off between field-of-view (FOV) and imaging resolution. Although larger FOV images may reveal more parafoveal vascular lesions, their application is greatly hampered due to lower resolution. To increase the resolution, previous works only achieved satisfactory performance by using paired data for training, but real-world applications are limited by the challenge of collecting large-scale paired images. Thus, an unpaired approach is highly demanded. Generative Adversarial Network (GAN) has been commonly used in the unpaired setting, but it may struggle to accurately preserve fine-grained capillary details, which are critical biomarkers for OCTA. In this paper, our approach aspires to preserve these details by leveraging the frequency information, which represents details as high-frequencies ($\textbf{hf}$) and coarse-grained backgrounds as low-frequencies ($\textbf{lf}$). In general, we propose a GAN-based unpaired super-resolution method for OCTA images and exceptionally emphasize $\textbf{hf}$ fine capillaries through a dual-path generator. To facilitate a precise spectrum of the reconstructed image, we also propose a frequency-aware adversarial loss for the discriminator and introduce a frequency-aware focal consistency loss for end-to-end optimization. Experiments show that our method outperforms other state-of-the-art unpaired methods both quantitatively and visually.
mEBAL2 Database and Benchmark: Image-based Multispectral Eyeblink Detection
Sep 14, 2023
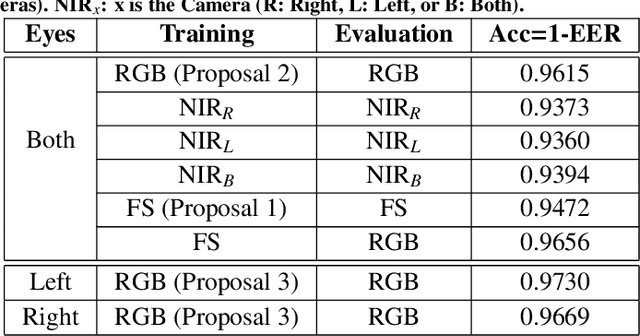
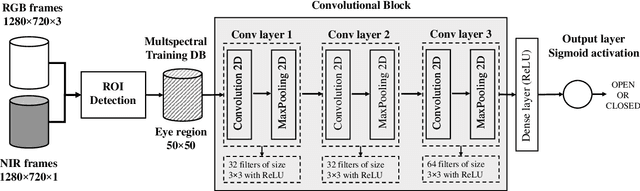
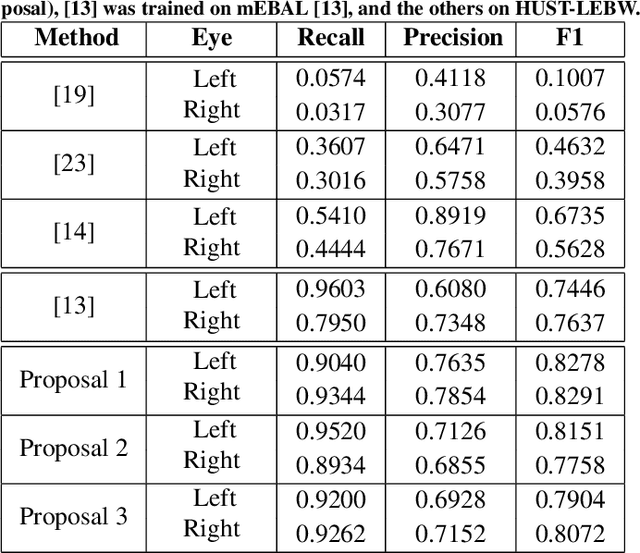
This work introduces a new multispectral database and novel approaches for eyeblink detection in RGB and Near-Infrared (NIR) individual images. Our contributed dataset (mEBAL2, multimodal Eye Blink and Attention Level estimation, Version 2) is the largest existing eyeblink database, representing a great opportunity to improve data-driven multispectral approaches for blink detection and related applications (e.g., attention level estimation and presentation attack detection in face biometrics). mEBAL2 includes 21,100 image sequences from 180 different students (more than 2 million labeled images in total) while conducting a number of e-learning tasks of varying difficulty or taking a real course on HTML initiation through the edX MOOC platform. mEBAL2 uses multiple sensors, including two Near-Infrared (NIR) and one RGB camera to capture facial gestures during the execution of the tasks, as well as an Electroencephalogram (EEG) band to get the cognitive activity of the user and blinking events. Furthermore, this work proposes a Convolutional Neural Network architecture as benchmark for blink detection on mEBAL2 with performances up to 97%. Different training methodologies are implemented using the RGB spectrum, NIR spectrum, and the combination of both to enhance the performance on existing eyeblink detectors. We demonstrate that combining NIR and RGB images during training improves the performance of RGB eyeblink detectors (i.e., detection based only on a RGB image). Finally, the generalization capacity of the proposed eyeblink detectors is validated in wilder and more challenging environments like the HUST-LEBW dataset to show the usefulness of mEBAL2 to train a new generation of data-driven approaches for eyeblink detection.
GROOViST: A Metric for Grounding Objects in Visual Storytelling
Oct 26, 2023A proper evaluation of stories generated for a sequence of images -- the task commonly referred to as visual storytelling -- must consider multiple aspects, such as coherence, grammatical correctness, and visual grounding. In this work, we focus on evaluating the degree of grounding, that is, the extent to which a story is about the entities shown in the images. We analyze current metrics, both designed for this purpose and for general vision-text alignment. Given their observed shortcomings, we propose a novel evaluation tool, GROOViST, that accounts for cross-modal dependencies, temporal misalignments (the fact that the order in which entities appear in the story and the image sequence may not match), and human intuitions on visual grounding. An additional advantage of GROOViST is its modular design, where the contribution of each component can be assessed and interpreted individually.
Defect Spectrum: A Granular Look of Large-Scale Defect Datasets with Rich Semantics
Oct 26, 2023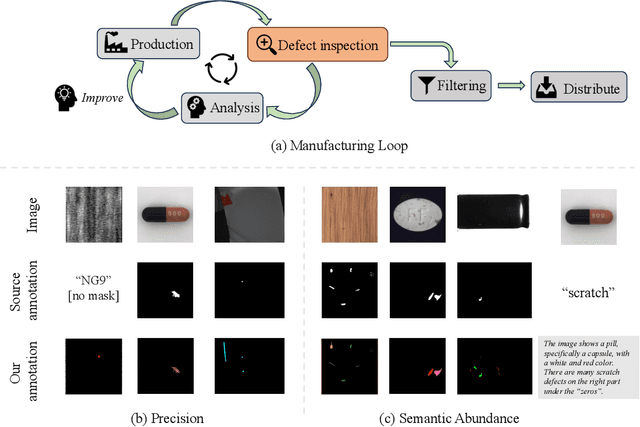
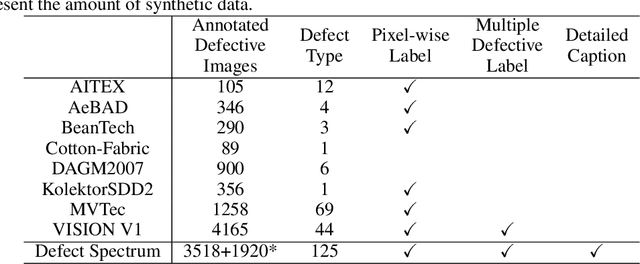


Defect inspection is paramount within the closed-loop manufacturing system. However, existing datasets for defect inspection often lack precision and semantic granularity required for practical applications. In this paper, we introduce the Defect Spectrum, a comprehensive benchmark that offers precise, semantic-abundant, and large-scale annotations for a wide range of industrial defects. Building on four key industrial benchmarks, our dataset refines existing annotations and introduces rich semantic details, distinguishing multiple defect types within a single image. Furthermore, we introduce Defect-Gen, a two-stage diffusion-based generator designed to create high-quality and diverse defective images, even when working with limited datasets. The synthetic images generated by Defect-Gen significantly enhance the efficacy of defect inspection models. Overall, The Defect Spectrum dataset demonstrates its potential in defect inspection research, offering a solid platform for testing and refining advanced models.
Improvement in Alzheimer's Disease MRI Images Analysis by Convolutional Neural Networks Via Topological Optimization
Oct 25, 2023This research underscores the efficacy of Fourier topological optimization in refining MRI imagery, thereby bolstering the classification precision of Alzheimer's Disease through convolutional neural networks. Recognizing that MRI scans are indispensable for neurological assessments, but frequently grapple with issues like blurriness and contrast irregularities, the deployment of Fourier topological optimization offered enhanced delineation of brain structures, ameliorated noise, and superior contrast. The applied techniques prioritized boundary enhancement, contrast and brightness adjustments, and overall image lucidity. Employing CNN architectures VGG16, ResNet50, InceptionV3, and Xception, the post-optimization analysis revealed a marked elevation in performance. Conclusively, the amalgamation of Fourier topological optimization with CNNs delineates a promising trajectory for the nuanced classification of Alzheimer's Disease, portending a transformative impact on its diagnostic paradigms.