 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spiral-Elliptical automated galaxy morphology classification from telescope images
Oct 10, 2023
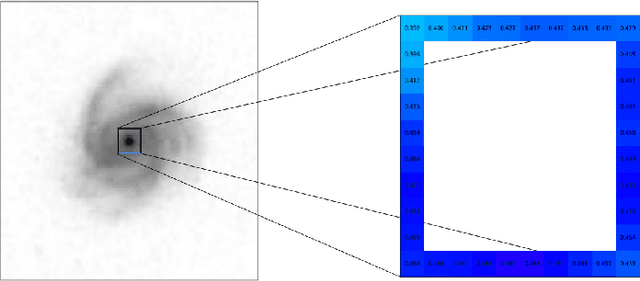
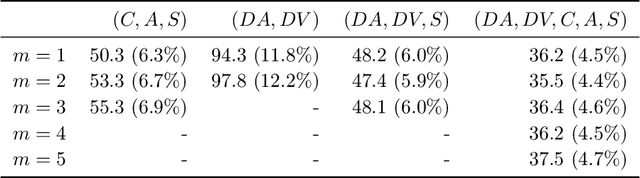
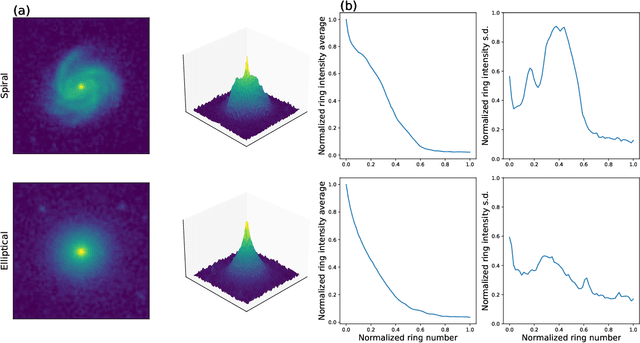

The classification of galaxy morphologies is an important step in the investigation of theories of hierarchical structure formation. While human expert visual classification remains quite effective and accurate, it cannot keep up with the massive influx of data from emerging sky surveys. A variety of approaches have been proposed to classify large numbers of galaxies; these approaches include crowdsourced visual classification, and automated and computational methods, such as machine learning methods based on designed morphology statistics and deep learning. In this work, we develop two novel galaxy morphology statistics, descent average and descent variance, which can be efficiently extracted from telescope galaxy images. We further propose simplified versions of the existing image statistics concentration, asymmetry, and clumpiness, which have been widely used in the literature of galaxy morphologies. We utilize the galaxy image data from the Sloan Digital Sky Survey to demonstrate the effective performance of our proposed image statistics at accurately detecting spiral and elliptical galaxies when used as features of a random forest classifier.
Language-Oriented Communication with Semantic Coding and Knowledge Distillation for Text-to-Image Generation
Sep 20, 2023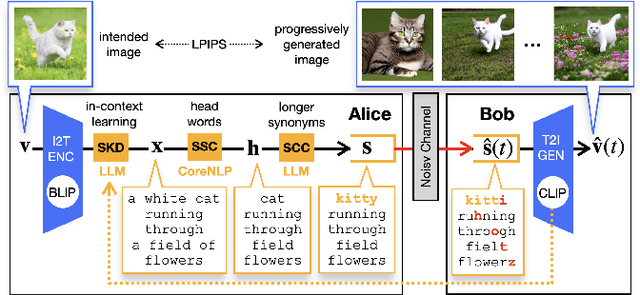


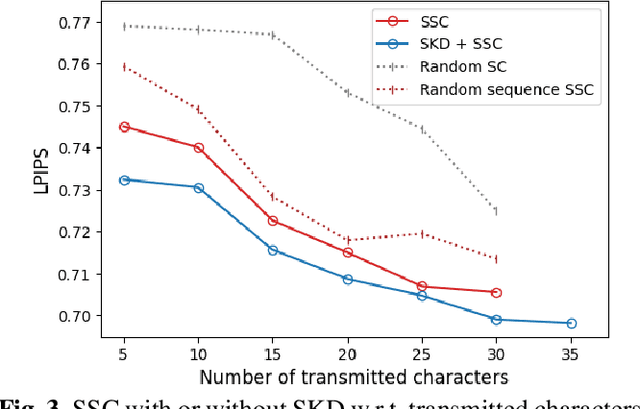
By integrating recent advances in large language models (LLMs) and generative models into the emerging semantic communication (SC) paradigm, in this article we put forward to a novel framework of language-oriented semantic communication (LSC). In LSC, machines communicate using human language messages that can be interpreted and manipulated via natural language processing (NLP) techniques for SC efficiency. To demonstrate LSC's potential, we introduce three innovative algorithms: 1) semantic source coding (SSC) which compresses a text prompt into its key head words capturing the prompt's syntactic essence while maintaining their appearance order to keep the prompt's context; 2) semantic channel coding (SCC) that improves robustness against errors by substituting head words with their lenghthier synonyms; and 3) semantic knowledge distillation (SKD) that produces listener-customized prompts via in-context learning the listener's language style. In a communication task for progressive text-to-image generation, the proposed methods achieve higher perceptual similarities with fewer transmissions while enhancing robustness in noisy communication channels.
A Survey on Video Diffusion Models
Oct 16, 2023The recent wave of AI-generated content (AIGC) has witnessed substantial success in computer vision, with the diffusion model playing a crucial role in this achievement. Due to their impressive generative capabilities, diffusion models are gradually superseding methods based on GANs and auto-regressive Transformers, demonstrating exceptional performance not only in image generation and editing, but also in the realm of video-related research. However, existing surveys mainly focus on diffusion models in the context of image generation, with few up-to-date reviews on their application in the video domain. To address this gap, this paper presents a comprehensive review of video diffusion models in the AIGC era. Specifically, we begin with a concise introduction to the fundamentals and evolution of diffusion models. Subsequently, we present an overview of research on diffusion models in the video domain, categorizing the work into three key areas: video generation, video editing, and other video understanding tasks. We conduct a thorough review of the literature in these three key areas, including further categorization and practical contributions in the field. Finally, we discuss the challenges faced by research in this domain and outline potential future developmental trends. A comprehensive list of video diffusion models studied in this survey is available at https://github.com/ChenHsing/Awesome-Video-Diffusion-Models.
ConsistNet: Enforcing 3D Consistency for Multi-view Images Diffusion
Oct 16, 2023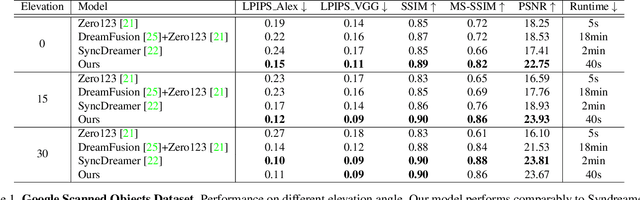
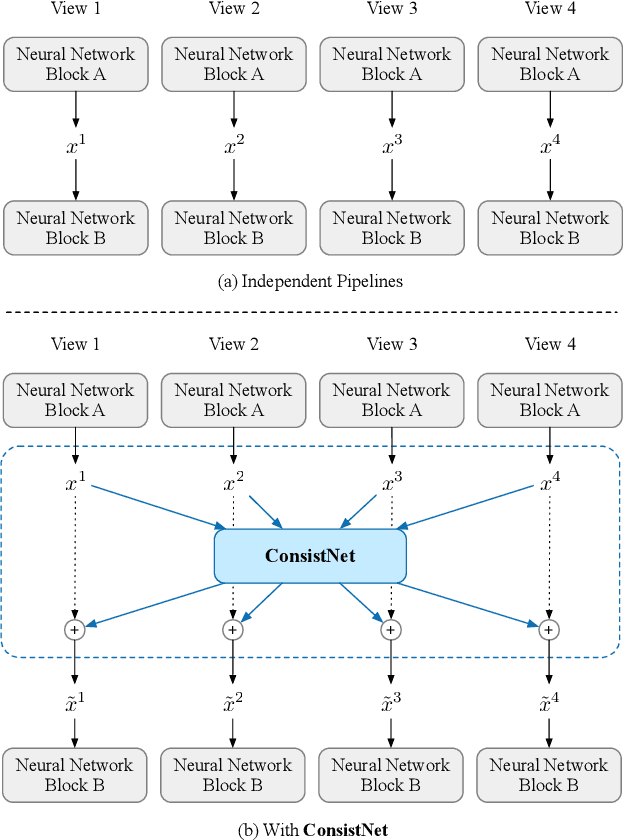
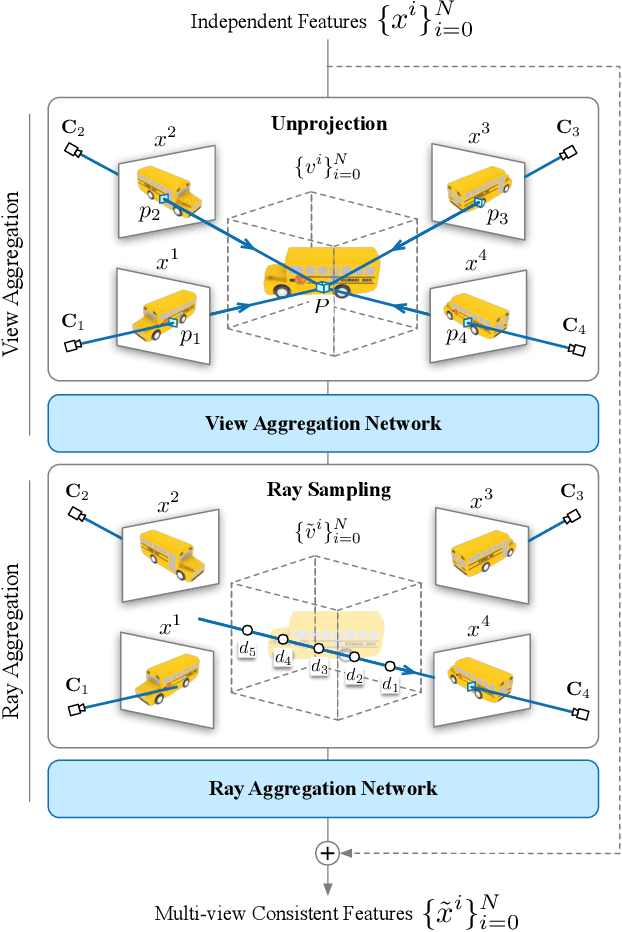
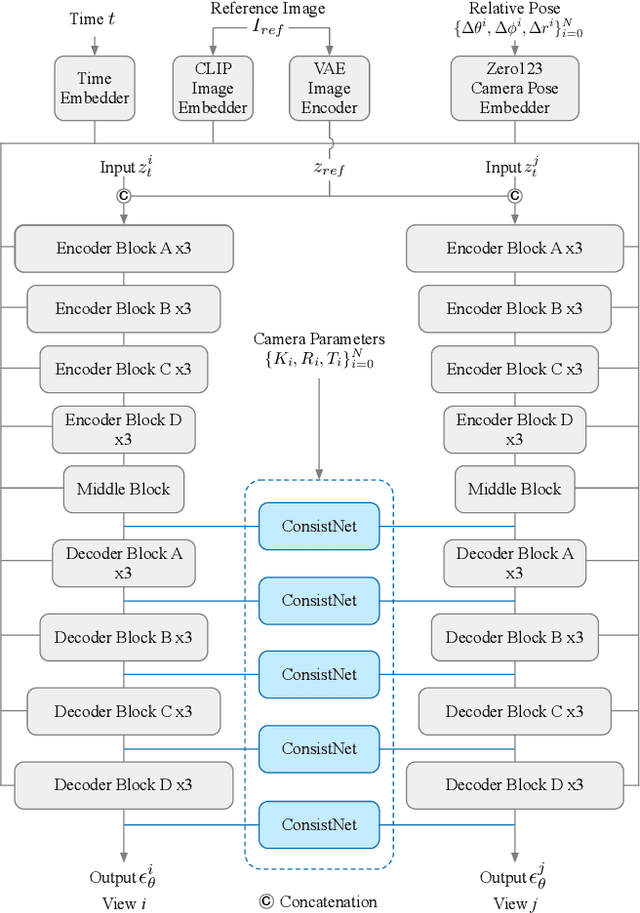
Given a single image of a 3D object, this paper proposes a novel method (named ConsistNet) that is able to generate multiple images of the same object, as if seen they are captured from different viewpoints, while the 3D (multi-view) consistencies among those multiple generated images are effectively exploited. Central to our method is a multi-view consistency block which enables information exchange across multiple single-view diffusion processes based on the underlying multi-view geometry principles. ConsistNet is an extension to the standard latent diffusion model, and consists of two sub-modules: (a) a view aggregation module that unprojects multi-view features into global 3D volumes and infer consistency, and (b) a ray aggregation module that samples and aggregate 3D consistent features back to each view to enforce consistency. Our approach departs from previous methods in multi-view image generation, in that it can be easily dropped-in pre-trained LDMs without requiring explicit pixel correspondences or depth prediction. Experiments show that our method effectively learns 3D consistency over a frozen Zero123 backbone and can generate 16 surrounding views of the object within 40 seconds on a single A100 GPU. Our code will be made available on https://github.com/JiayuYANG/ConsistNet
BiLL-VTG: Bridging Large Language Models and Lightweight Visual Tools for Video-based Texts Generation
Oct 16, 2023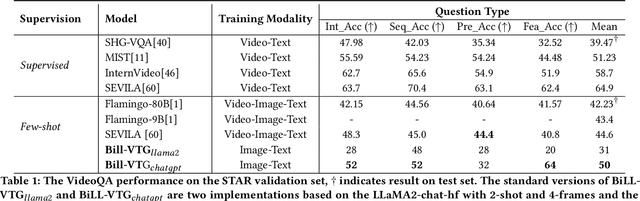
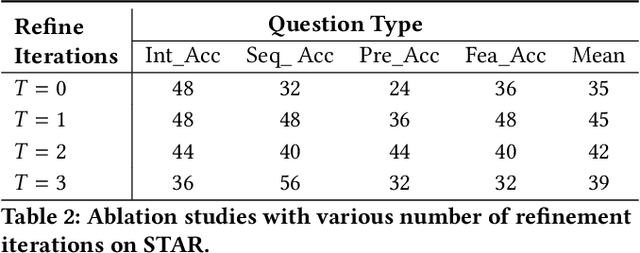
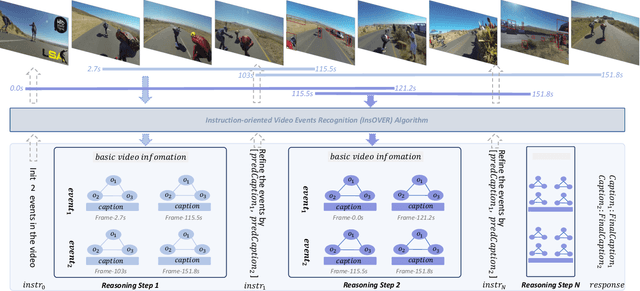
Building models that generate textual responses to user instructions for videos is a practical and challenging topic, as it requires both vision understanding and knowledge reasoning. Compared to language and image modalities, training efficiency remains a serious problem as existing studies train models on massive sparse videos aligned with brief descriptions. In this paper, we introduce BiLL-VTG, a fast adaptive framework that leverages large language models (LLMs) to reasoning on videos based on essential lightweight visual tools. Specifically, we reveal the key to response specific instructions is the concentration on relevant video events, and utilize two visual tools of structured scene graph generation and descriptive image caption generation to gather and represent the events information. Thus, a LLM equipped with world knowledge is adopted as the reasoning agent to achieve the response by performing multiple reasoning steps on specified video events.To address the difficulty of specifying events from agent, we further propose an Instruction-oriented Video Events Recognition (InsOVER) algorithm based on the efficient Hungarian matching to localize corresponding video events using linguistic instructions, enabling LLMs to interact with long videos. Extensive experiments on two typical video-based texts generations tasks show that our tuning-free framework outperforms the pre-trained models including Flamingo-80B, to achieve the state-of-the-art performance.
Impact of Data Synthesis Strategies for the Classification of Craniosynostosis
Oct 16, 2023Introduction: Photogrammetric surface scans provide a radiation-free option to assess and classify craniosynostosis. Due to the low prevalence of craniosynostosis and high patient restrictions, clinical data is rare. Synthetic data could support or even replace clinical data for the classification of craniosynostosis, but this has never been studied systematically. Methods: We test the combinations of three different synthetic data sources: a statistical shape model (SSM), a generative adversarial network (GAN), and image-based principal component analysis for a convolutional neural network (CNN)-based classification of craniosynostosis. The CNN is trained only on synthetic data, but validated and tested on clinical data. Results: The combination of a SSM and a GAN achieved an accuracy of more than 0.96 and a F1-score of more than 0.95 on the unseen test set. The difference to training on clinical data was smaller than 0.01. Including a second image modality improved classification performance for all data sources. Conclusion: Without a single clinical training sample, a CNN was able to classify head deformities as accurate as if it was trained on clinical data. Using multiple data sources was key for a good classification based on synthetic data alone. Synthetic data might play an important future role in the assessment of craniosynostosis.
CausalImages: An R Package for Causal Inference with Earth Observation, Bio-medical, and Social Science Images
Oct 03, 2023The causalimages R package enables causal inference with image and image sequence data, providing new tools for integrating novel data sources like satellite and bio-medical imagery into the study of cause and effect. One set of functions enables image-based causal inference analyses. For example, one key function decomposes treatment effect heterogeneity by images using an interpretable Bayesian framework. This allows for determining which types of images or image sequences are most responsive to interventions. A second modeling function allows researchers to control for confounding using images. The package also allows investigators to produce embeddings that serve as vector summaries of the image or video content. Finally, infrastructural functions are also provided, such as tools for writing large-scale image and image sequence data as sequentialized byte strings for more rapid image analysis. causalimages therefore opens new capabilities for causal inference in R, letting researchers use informative imagery in substantive analyses in a fast and accessible manner.
Gene-induced Multimodal Pre-training for Image-omic Classification
Sep 06, 2023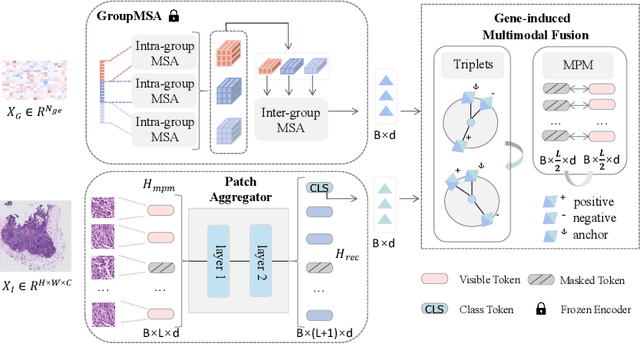
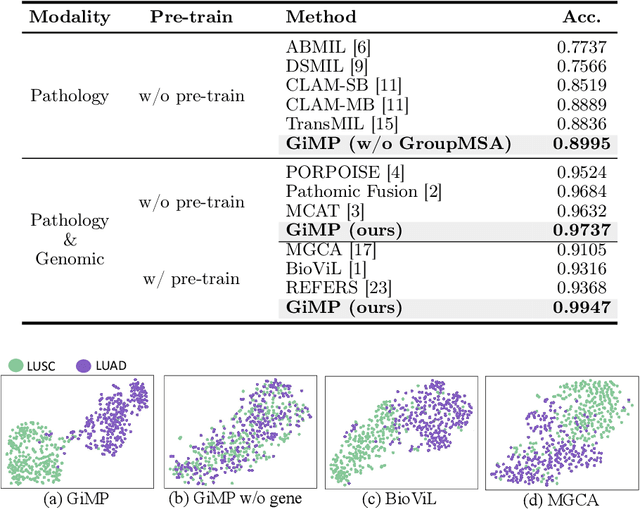
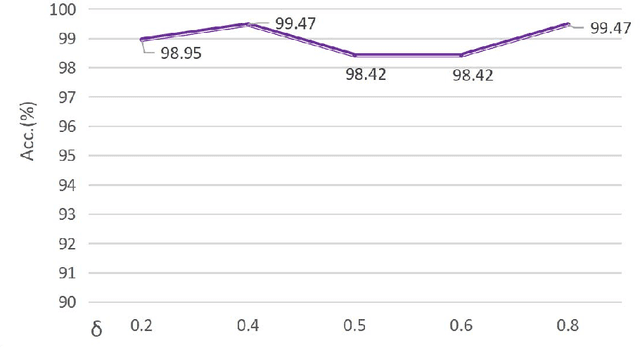
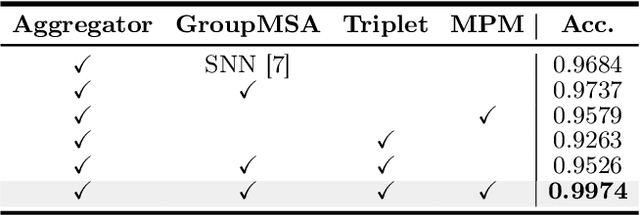
Histology analysis of the tumor micro-environment integrated with genomic assays is the gold standard for most cancers in modern medicine. This paper proposes a Gene-induced Multimodal Pre-training (GiMP) framework, which jointly incorporates genomics and Whole Slide Images (WSIs) for classification tasks. Our work aims at dealing with the main challenges of multi-modality image-omic classification w.r.t. (1) the patient-level feature extraction difficulties from gigapixel WSIs and tens of thousands of genes, and (2) effective fusion considering high-order relevance modeling. Concretely, we first propose a group multi-head self-attention gene encoder to capture global structured features in gene expression cohorts. We design a masked patch modeling paradigm (MPM) to capture the latent pathological characteristics of different tissues. The mask strategy is randomly masking a fixed-length contiguous subsequence of patch embeddings of a WSI. Finally, we combine the classification tokens of paired modalities and propose a triplet learning module to learn high-order relevance and discriminative patient-level information.After pre-training, a simple fine-tuning can be adopted to obtain the classification results. Experimental results on the TCGA dataset show the superiority of our network architectures and our pre-training framework, achieving 99.47% in accuracy for image-omic classification. The code is publicly available at https://github.com/huangwudiduan/GIMP.
Improving Deep Learning-based Defect Detection on Window Frames with Image Processing Strategies
Sep 13, 2023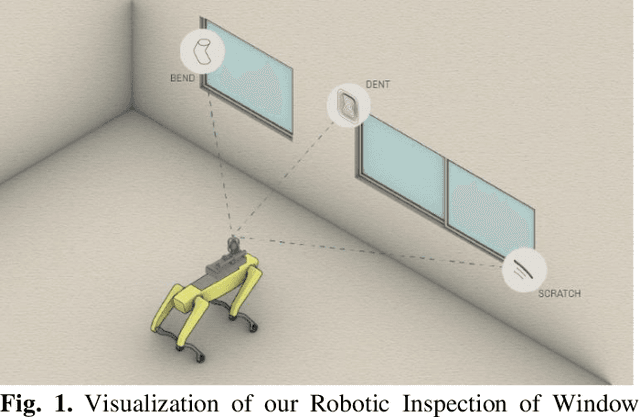



Detecting subtle defects in window frames, including dents and scratches, is vital for upholding product integrity and sustaining a positive brand perception. Conventional machine vision systems often struggle to identify these defects in challenging environments like construction sites. In contrast, modern vision systems leveraging machine and deep learning (DL) are emerging as potent tools, particularly for cosmetic inspections. However, the promise of DL is yet to be fully realized. A few manufacturers have established a clear strategy for AI integration in quality inspection, hindered mainly by issues like scarce clean datasets and environmental changes that compromise model accuracy. Addressing these challenges, our study presents an innovative approach that amplifies defect detection in DL models, even with constrained data resources. The paper proposes a new defect detection pipeline called InspectNet (IPT-enhanced UNET) that includes the best combination of image enhancement and augmentation techniques for pre-processing the dataset and a Unet model tuned for window frame defect detection and segmentation. Experiments were carried out using a Spot Robot doing window frame inspections . 16 variations of the dataset were constructed using different image augmentation settings. Results of the experiments revealed that, on average, across all proposed evaluation measures, Unet outperformed all other algorithms when IPT-enhanced augmentations were applied. In particular, when using the best dataset, the average Intersection over Union (IoU) values achieved were IPT-enhanced Unet, reaching 0.91 of mIoU.
Affine-Consistent Transformer for Multi-Class Cell Nuclei Detection
Oct 22, 2023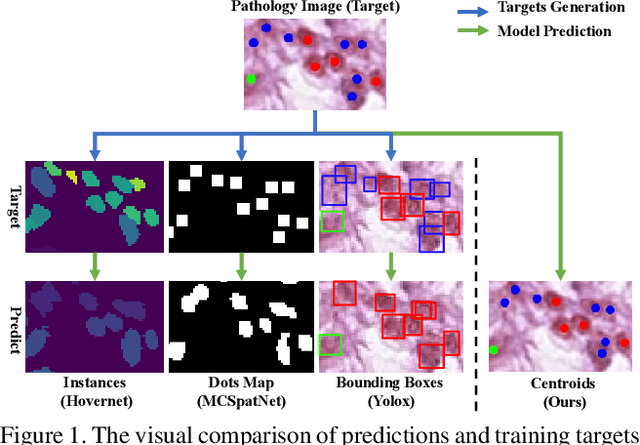
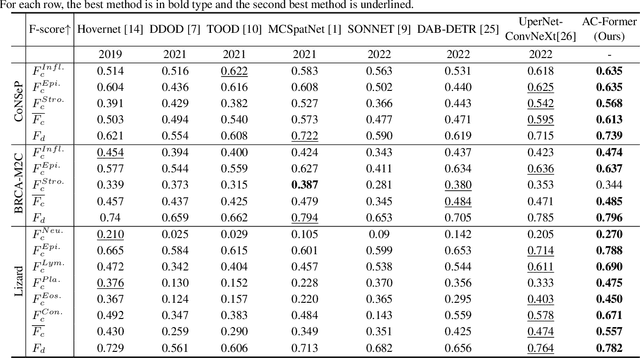
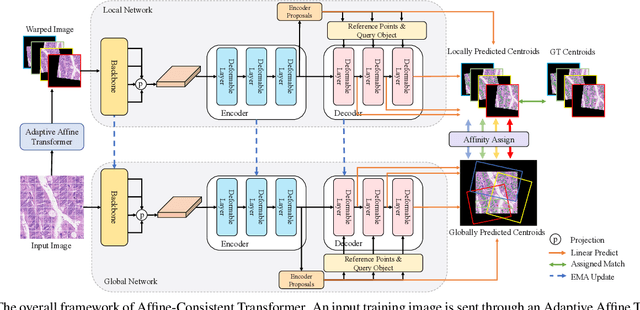
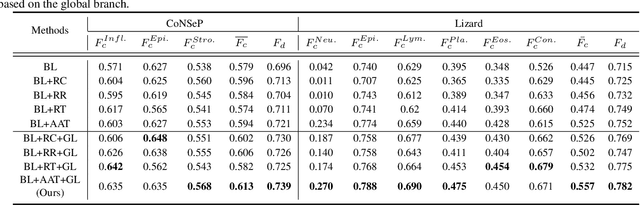
Multi-class cell nuclei detection is a fundamental prerequisite in the diagnosis of histopathology. It is critical to efficiently locate and identify cells with diverse morphology and distributions in digital pathological images. Most existing methods take complex intermediate representations as learning targets and rely on inflexible post-refinements while paying less attention to various cell density and fields of view. In this paper, we propose a novel Affine-Consistent Transformer (AC-Former), which directly yields a sequence of nucleus positions and is trained collaboratively through two sub-networks, a global and a local network. The local branch learns to infer distorted input images of smaller scales while the global network outputs the large-scale predictions as extra supervision signals. We further introduce an Adaptive Affine Transformer (AAT) module, which can automatically learn the key spatial transformations to warp original images for local network training. The AAT module works by learning to capture the transformed image regions that are more valuable for training the model. Experimental results demonstrate that the proposed method significantly outperforms existing state-of-the-art algorithms on various benchmarks.