 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Model with Clustering-based Conditioning for Food Image Generation
Sep 01, 2023
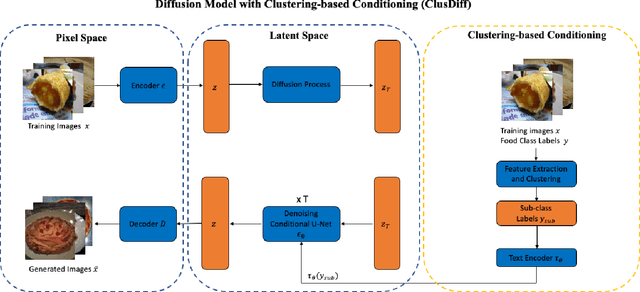

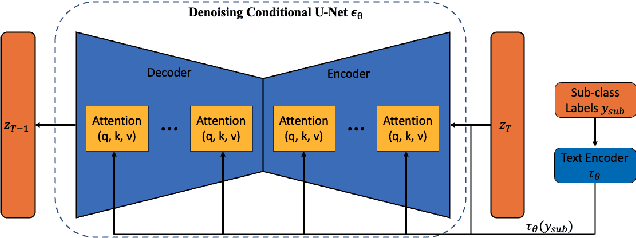
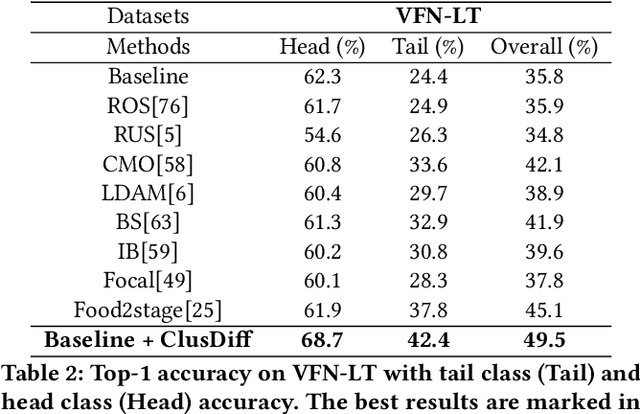
Image-based dietary assessment serves as an efficient and accurate solution for recording and analyzing nutrition intake using eating occasion images as input. Deep learning-based techniques are commonly used to perform image analysis such as food classification, segmentation, and portion size estimation, which rely on large amounts of food images with annotations for training. However, such data dependency poses significant barriers to real-world applications, because acquiring a substantial, diverse, and balanced set of food images can be challenging. One potential solution is to use synthetic food images for data augmentation. Although existing work has explored the use of generative adversarial networks (GAN) based structures for generation, the quality of synthetic food images still remains subpar. In addition, while diffusion-based generative models have shown promising results for general image generation tasks, the generation of food images can be challenging due to the substantial intra-class variance. In this paper, we investigate the generation of synthetic food images based on the conditional diffusion model and propose an effective clustering-based training framework, named ClusDiff, for generating high-quality and representative food images. The proposed method is evaluated on the Food-101 dataset and shows improved performance when compared with existing image generation works. We also demonstrate that the synthetic food images generated by ClusDiff can help address the severe class imbalance issue in long-tailed food classification using the VFN-LT dataset.
TransCC: Transformer Network for Coronary Artery CCTA Segmentation
Oct 07, 2023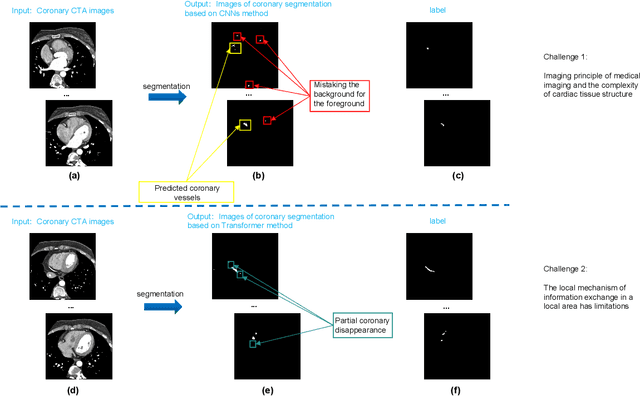
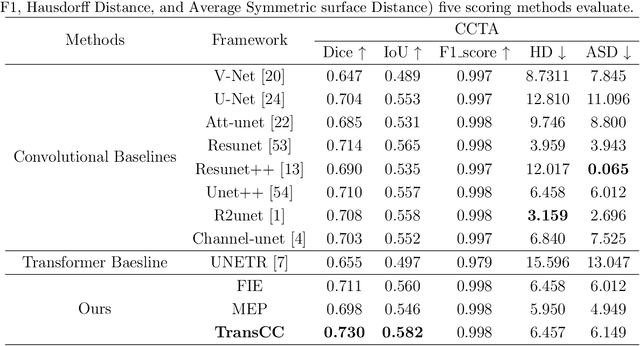
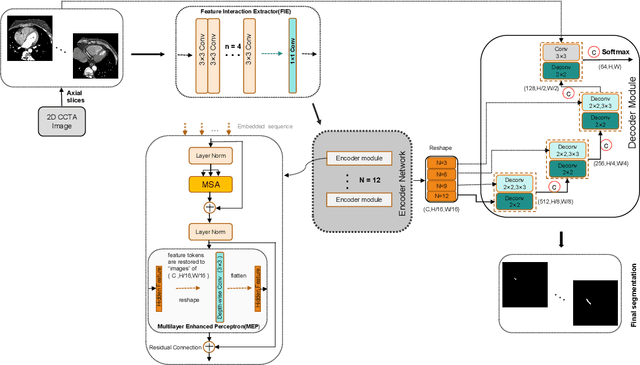
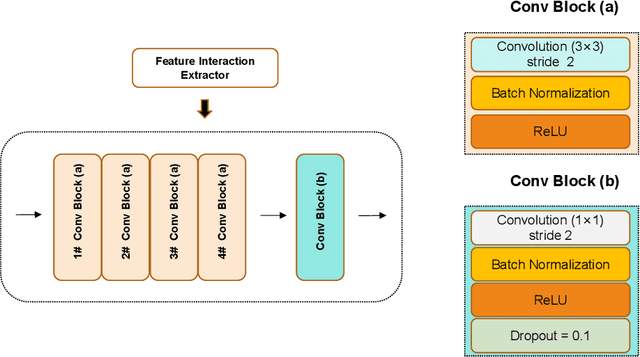
The accurate segmentation of Coronary Computed Tomography Angiography (CCTA) images holds substantial clinical value for the early detection and treatment of Coronary Heart Disease (CHD). The Transformer, utilizing a self-attention mechanism, has demonstrated commendable performance in the realm of medical image processing. However, challenges persist in coronary segmentation tasks due to (1) the damage to target local structures caused by fixed-size image patch embedding, and (2) the critical role of both global and local features in medical image segmentation tasks.To address these challenges, we propose a deep learning framework, TransCC, that effectively amalgamates the Transformer and convolutional neural networks for CCTA segmentation. Firstly, we introduce a Feature Interaction Extraction (FIE) module designed to capture the characteristics of image patches, thereby circumventing the loss of semantic information inherent in the original method. Secondly, we devise a Multilayer Enhanced Perceptron (MEP) to augment attention to local information within spatial dimensions, serving as a complement to the self-attention mechanism. Experimental results indicate that TransCC outperforms existing methods in segmentation performance, boasting an average Dice coefficient of 0.730 and an average Intersection over Union (IoU) of 0.582. These results underscore the effectiveness of TransCC in CCTA image segmentation.
Multi-dimensional Fusion and Consistency for Semi-supervised Medical Image Segmentation
Sep 12, 2023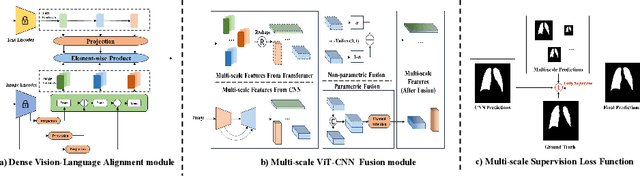
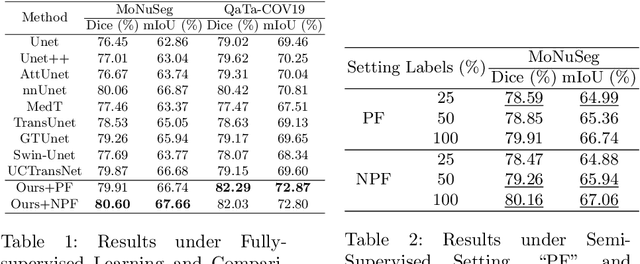
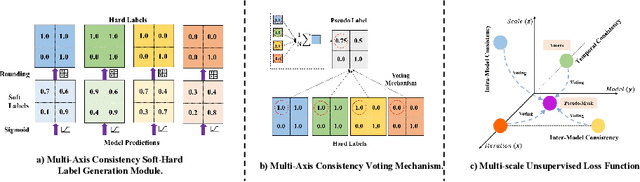
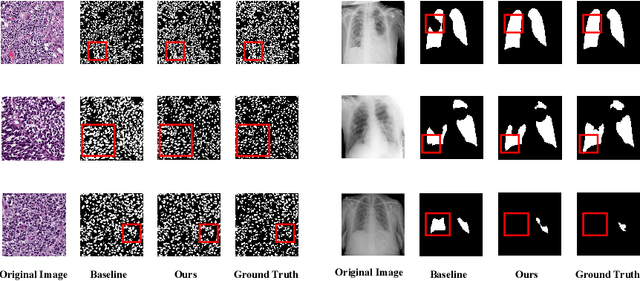
In this paper, we introduce a novel semi-supervised learning framework tailored for medical image segmentation. Central to our approach is the innovative Multi-scale Text-aware ViT-CNN Fusion scheme. This scheme adeptly combines the strengths of both ViTs and CNNs, capitalizing on the unique advantages of both architectures as well as the complementary information in vision-language modalities. Further enriching our framework, we propose the Multi-Axis Consistency framework for generating robust pseudo labels, thereby enhancing the semi-supervised learning process. Our extensive experiments on several widely-used datasets unequivocally demonstrate the efficacy of our approach.
Wide Flat Minimum Watermarking for Robust Ownership Verification of GANs
Oct 25, 2023We propose a novel multi-bit box-free watermarking method for the protection of Intellectual Property Rights (IPR) of GANs with improved robustness against white-box attacks like fine-tuning, pruning, quantization, and surrogate model attacks. The watermark is embedded by adding an extra watermarking loss term during GAN training, ensuring that the images generated by the GAN contain an invisible watermark that can be retrieved by a pre-trained watermark decoder. In order to improve the robustness against white-box model-level attacks, we make sure that the model converges to a wide flat minimum of the watermarking loss term, in such a way that any modification of the model parameters does not erase the watermark. To do so, we add random noise vectors to the parameters of the generator and require that the watermarking loss term is as invariant as possible with respect to the presence of noise. This procedure forces the generator to converge to a wide flat minimum of the watermarking loss. The proposed method is architectureand dataset-agnostic, thus being applicable to many different generation tasks and models, as well as to CNN-based image processing architectures. We present the results of extensive experiments showing that the presence of the watermark has a negligible impact on the quality of the generated images, and proving the superior robustness of the watermark against model modification and surrogate model attacks.
Dual Defense: Adversarial, Traceable, and Invisible Robust Watermarking against Face Swapping
Oct 25, 2023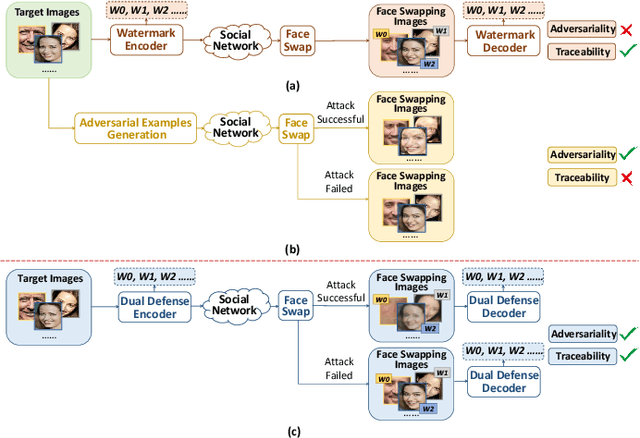
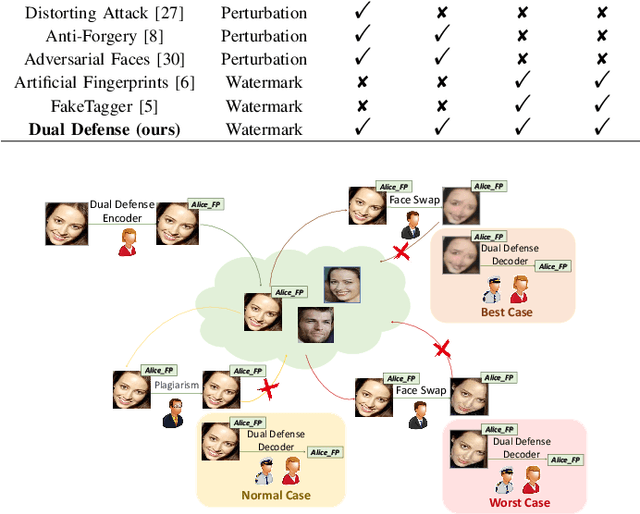
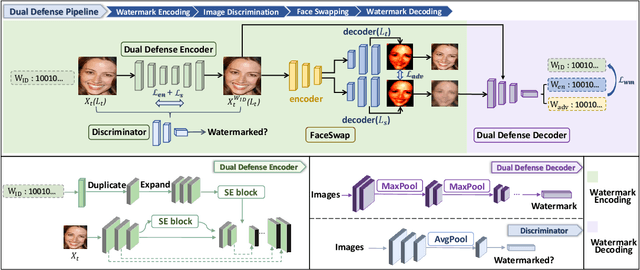
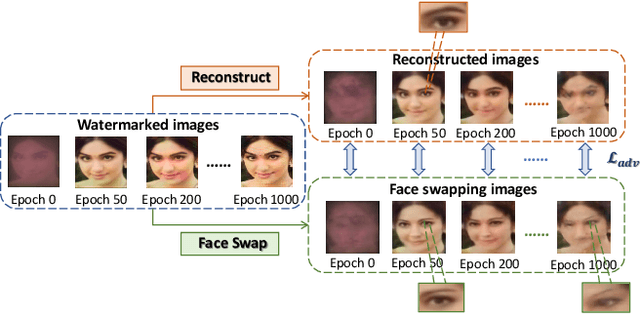
The malicious applications of deep forgery, represented by face swapping, have introduced security threats such as misinformation dissemination and identity fraud. While some research has proposed the use of robust watermarking methods to trace the copyright of facial images for post-event traceability, these methods cannot effectively prevent the generation of forgeries at the source and curb their dissemination. To address this problem, we propose a novel comprehensive active defense mechanism that combines traceability and adversariality, called Dual Defense. Dual Defense invisibly embeds a single robust watermark within the target face to actively respond to sudden cases of malicious face swapping. It disrupts the output of the face swapping model while maintaining the integrity of watermark information throughout the entire dissemination process. This allows for watermark extraction at any stage of image tracking for traceability. Specifically, we introduce a watermark embedding network based on original-domain feature impersonation attack. This network learns robust adversarial features of target facial images and embeds watermarks, seeking a well-balanced trade-off between watermark invisibility, adversariality, and traceability through perceptual adversarial encoding strategies. Extensive experiments demonstrate that Dual Defense achieves optimal overall defense success rates and exhibits promising universality in anti-face swapping tasks and dataset generalization ability. It maintains impressive adversariality and traceability in both original and robust settings, surpassing current forgery defense methods that possess only one of these capabilities, including CMUA-Watermark, Anti-Forgery, FakeTagger, or PGD methods.
Nighttime Driver Behavior Prediction Using Taillight Signal Recognition via CNN-SVM Classifier
Oct 25, 2023

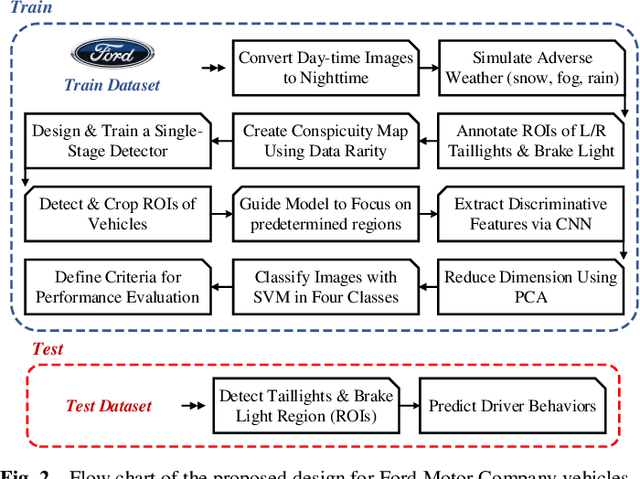

This paper aims to enhance the ability to predict nighttime driving behavior by identifying taillights of both human-driven and autonomous vehicles. The proposed model incorporates a customized detector designed to accurately detect front-vehicle taillights on the road. At the beginning of the detector, a learnable pre-processing block is implemented, which extracts deep features from input images and calculates the data rarity for each feature. In the next step, drawing inspiration from soft attention, a weighted binary mask is designed that guides the model to focus more on predetermined regions. This research utilizes Convolutional Neural Networks (CNNs) to extract distinguishing characteristics from these areas, then reduces dimensions using Principal Component Analysis (PCA). Finally, the Support Vector Machine (SVM) is used to predict the behavior of the vehicles. To train and evaluate the model, a large-scale dataset is collected from two types of dash-cams and Insta360 cameras from the rear view of Ford Motor Company vehicles. This dataset includes over 12k frames captured during both daytime and nighttime hours. To address the limited nighttime data, a unique pixel-wise image processing technique is implemented to convert daytime images into realistic night images. The findings from the experiments demonstrate that the proposed methodology can accurately categorize vehicle behavior with 92.14% accuracy, 97.38% specificity, 92.09% sensitivity, 92.10% F1-measure, and 0.895 Cohen's Kappa Statistic. Further details are available at https://github.com/DeepCar/Taillight_Recognition.
Spiral-Elliptical automated galaxy morphology classification from telescope images
Oct 10, 2023
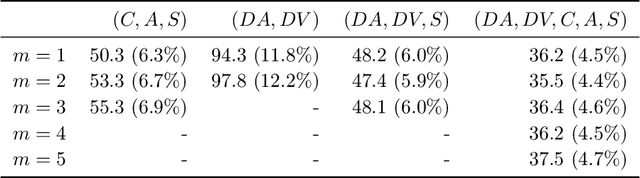
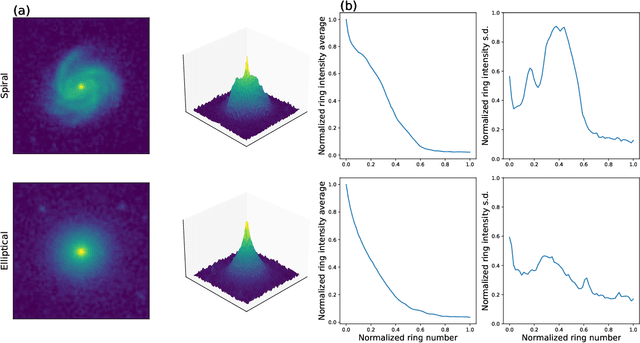

The classification of galaxy morphologies is an important step in the investigation of theories of hierarchical structure formation. While human expert visual classification remains quite effective and accurate, it cannot keep up with the massive influx of data from emerging sky surveys. A variety of approaches have been proposed to classify large numbers of galaxies; these approaches include crowdsourced visual classification, and automated and computational methods, such as machine learning methods based on designed morphology statistics and deep learning. In this work, we develop two novel galaxy morphology statistics, descent average and descent variance, which can be efficiently extracted from telescope galaxy images. We further propose simplified versions of the existing image statistics concentration, asymmetry, and clumpiness, which have been widely used in the literature of galaxy morphologies. We utilize the galaxy image data from the Sloan Digital Sky Survey to demonstrate the effective performance of our proposed image statistics at accurately detecting spiral and elliptical galaxies when used as features of a random forest classifier.
Runner re-identification from single-view video in the open-world setting
Oct 18, 2023In many sports, player re-identification is crucial for automatic video processing and analysis. However, most of the current studies on player re-identification in multi- or single-view sports videos focus on re-identification in the closed-world setting using labeled image dataset, and player re-identification in the open-world setting for automatic video analysis is not well developed. In this paper, we propose a runner re-identification system that directly processes single-view video to address the open-world setting. In the open-world setting, we cannot use labeled dataset and have to process video directly. The proposed system automatically processes raw video as input to identify runners, and it can identify runners even when they are framed out multiple times. For the automatic processing, we first detect the runners in the video using the pre-trained YOLOv8 and the fine-tuned EfficientNet. We then track the runners using ByteTrack and detect their shoes with the fine-tuned YOLOv8. Finally, we extract the image features of the runners using an unsupervised method using the gated recurrent unit autoencoder model. To improve the accuracy of runner re-identification, we use dynamic features of running sequence images. We evaluated the system on a running practice video dataset and showed that the proposed method identified runners with higher accuracy than one of the state-of-the-art models in unsupervised re-identification. We also showed that our unsupervised running dynamic feature extractor was effective for runner re-identification. Our runner re-identification system can be useful for the automatic analysis of running videos.
Universal Domain Adaptation for Robust Handling of Distributional Shifts in NLP
Oct 23, 2023When deploying machine learning systems to the wild, it is highly desirable for them to effectively leverage prior knowledge to the unfamiliar domain while also firing alarms to anomalous inputs. In order to address these requirements, Universal Domain Adaptation (UniDA) has emerged as a novel research area in computer vision, focusing on achieving both adaptation ability and robustness (i.e., the ability to detect out-of-distribution samples). While UniDA has led significant progress in computer vision, its application on language input still needs to be explored despite its feasibility. In this paper, we propose a comprehensive benchmark for natural language that offers thorough viewpoints of the model's generalizability and robustness. Our benchmark encompasses multiple datasets with varying difficulty levels and characteristics, including temporal shifts and diverse domains. On top of our testbed, we validate existing UniDA methods from computer vision and state-of-the-art domain adaptation techniques from NLP literature, yielding valuable findings: We observe that UniDA methods originally designed for image input can be effectively transferred to the natural language domain while also underscoring the effect of adaptation difficulty in determining the model's performance.
Delayed Memory Unit: Modelling Temporal Dependency Through Delay Gate
Oct 23, 2023Recurrent Neural Networks (RNNs) are renowned for their adeptness in modeling temporal dependencies, a trait that has driven their widespread adoption for sequential data processing. Nevertheless, vanilla RNNs are confronted with the well-known issue of gradient vanishing and exploding, posing a significant challenge for learning and establishing long-range dependencies. Additionally, gated RNNs tend to be over-parameterized, resulting in poor network generalization. To address these challenges, we propose a novel Delayed Memory Unit (DMU) in this paper, wherein a delay line structure, coupled with delay gates, is introduced to facilitate temporal interaction and temporal credit assignment, so as to enhance the temporal modeling capabilities of vanilla RNNs. Particularly, the DMU is designed to directly distribute the input information to the optimal time instant in the future, rather than aggregating and redistributing it over time through intricate network dynamics. Our proposed DMU demonstrates superior temporal modeling capabilities across a broad range of sequential modeling tasks, utilizing considerably fewer parameters than other state-of-the-art gated RNN models in applications such as speech recognition, radar gesture recognition, ECG waveform segmentation, and permuted sequential image classification.