 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LLP-Bench: A Large Scale Tabular Benchmark for Learning from Label Proportions
Oct 16, 2023
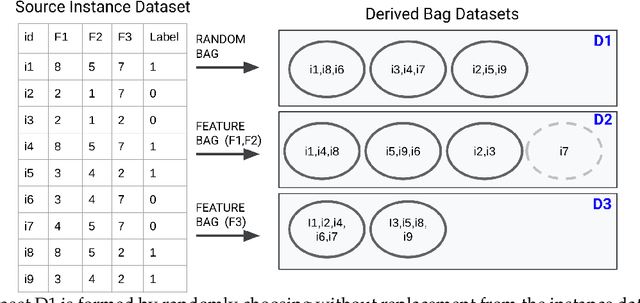
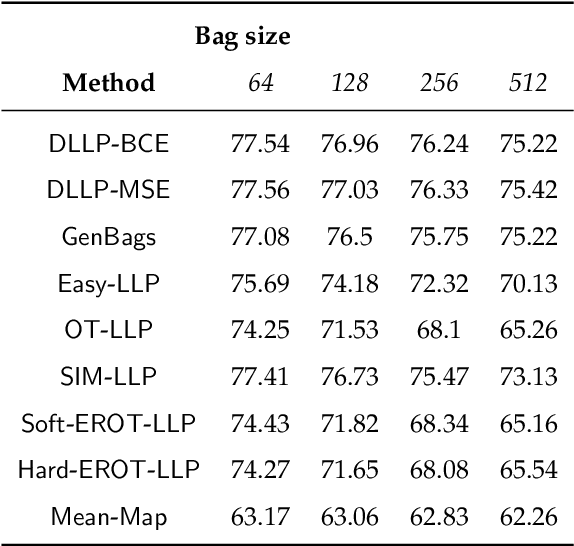
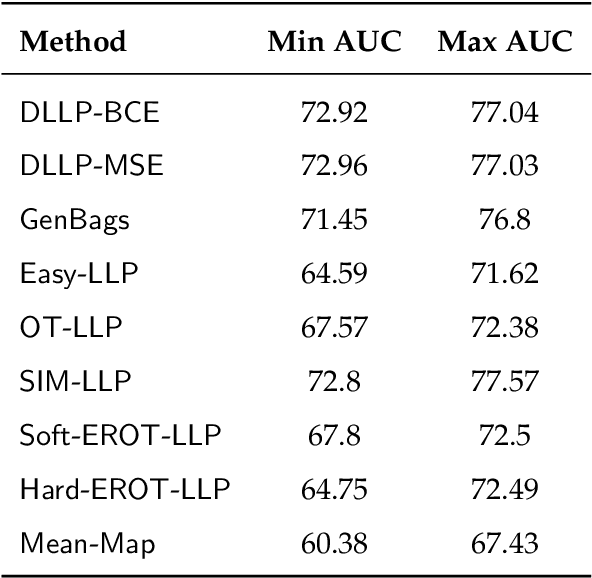
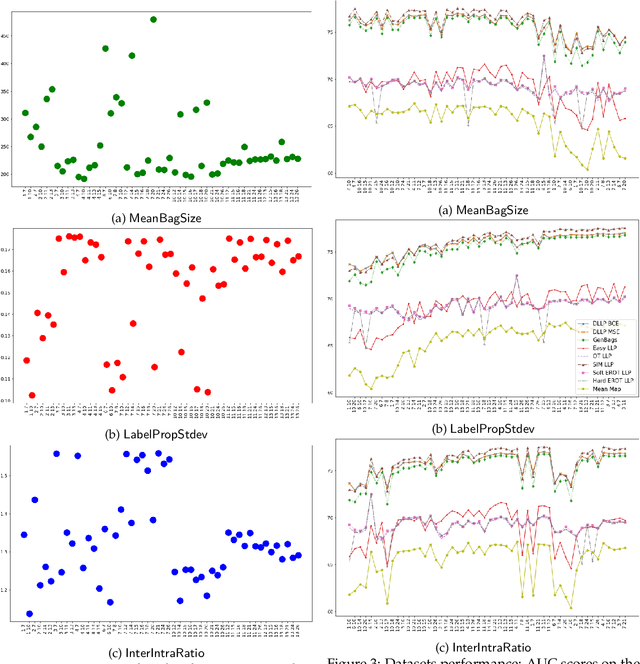
In the task of Learning from Label Proportions (LLP), a model is trained on groups (a.k.a bags) of instances and their corresponding label proportions to predict labels for individual instances. LLP has been applied pre-dominantly on two types of datasets - image and tabular. In image LLP, bags of fixed size are created by randomly sampling instances from an underlying dataset. Bags created via this methodology are called random bags. Experimentation on Image LLP has been mostly on random bags on CIFAR-* and MNIST datasets. Despite being a very crucial task in privacy sensitive applications, tabular LLP does not yet have a open, large scale LLP benchmark. One of the unique properties of tabular LLP is the ability to create feature bags where all the instances in a bag have the same value for a given feature. It has been shown in prior research that feature bags are very common in practical, real world applications [Chen et. al '23, Saket et. al. '22]. In this paper, we address the lack of a open, large scale tabular benchmark. First we propose LLP-Bench, a suite of 56 LLP datasets (52 feature bag and 4 random bag datasets) created from the Criteo CTR prediction dataset consisting of 45 million instances. The 56 datasets represent diverse ways in which bags can be constructed from underlying tabular data. To the best of our knowledge, LLP-Bench is the first large scale tabular LLP benchmark with an extensive diversity in constituent datasets. Second, we propose four metrics that characterize and quantify the hardness of a LLP dataset. Using these four metrics we present deep analysis of the 56 datasets in LLP-Bench. Finally we present the performance of 9 SOTA and popular tabular LLP techniques on all the 56 datasets. To the best of our knowledge, our study consisting of more than 2500 experiments is the most extensive study of popular tabular LLP techniques in literature.
Dense Text-to-Image Generation with Attention Modulation
Aug 24, 2023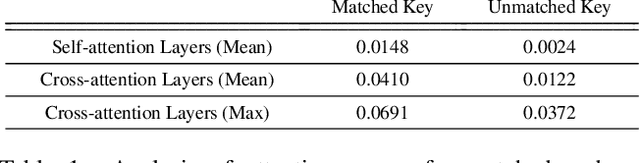
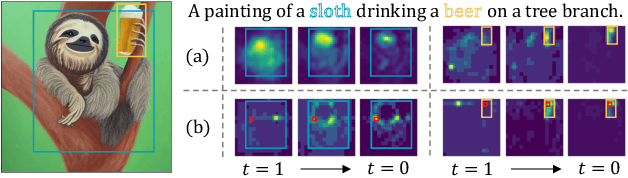
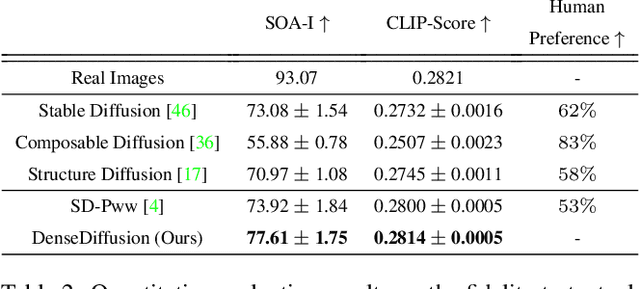
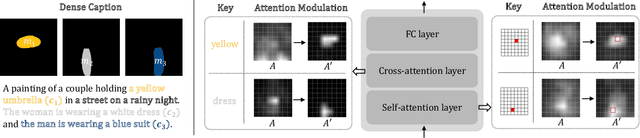
Existing text-to-image diffusion models struggle to synthesize realistic images given dense captions, where each text prompt provides a detailed description for a specific image region. To address this, we propose DenseDiffusion, a training-free method that adapts a pre-trained text-to-image model to handle such dense captions while offering control over the scene layout. We first analyze the relationship between generated images' layouts and the pre-trained model's intermediate attention maps. Next, we develop an attention modulation method that guides objects to appear in specific regions according to layout guidance. Without requiring additional fine-tuning or datasets, we improve image generation performance given dense captions regarding both automatic and human evaluation scores. In addition, we achieve similar-quality visual results with models specifically trained with layout conditions.
Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned Data
Oct 10, 2023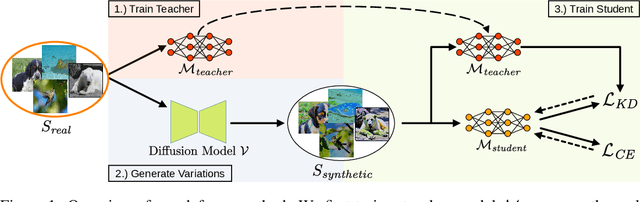
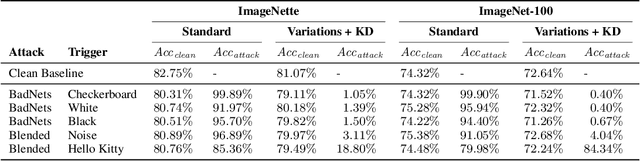

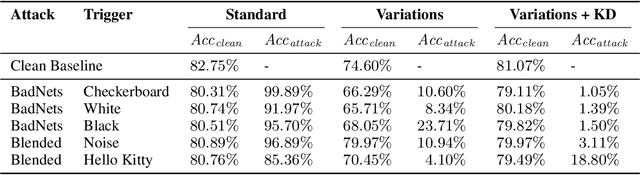
Backdoor attacks pose a serious security threat for training neural networks as they surreptitiously introduce hidden functionalities into a model. Such backdoors remain silent during inference on clean inputs, evading detection due to inconspicuous behavior. However, once a specific trigger pattern appears in the input data, the backdoor activates, causing the model to execute its concealed function. Detecting such poisoned samples within vast datasets is virtually impossible through manual inspection. To address this challenge, we propose a novel approach that enables model training on potentially poisoned datasets by utilizing the power of recent diffusion models. Specifically, we create synthetic variations of all training samples, leveraging the inherent resilience of diffusion models to potential trigger patterns in the data. By combining this generative approach with knowledge distillation, we produce student models that maintain their general performance on the task while exhibiting robust resistance to backdoor triggers.
Contrastive Grouping with Transformer for Referring Image Segmentation
Sep 02, 2023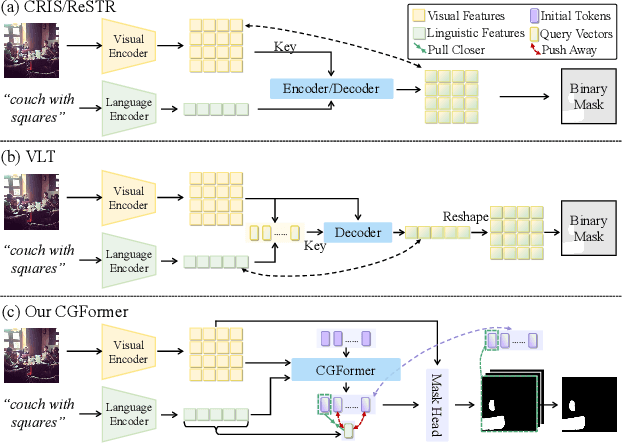
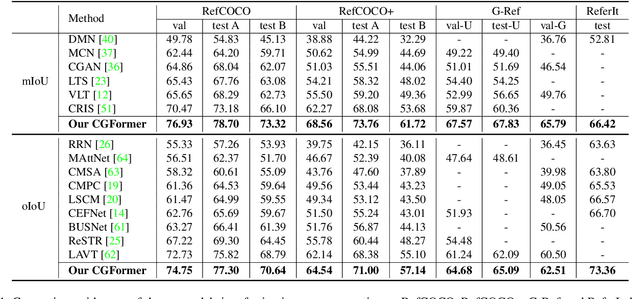
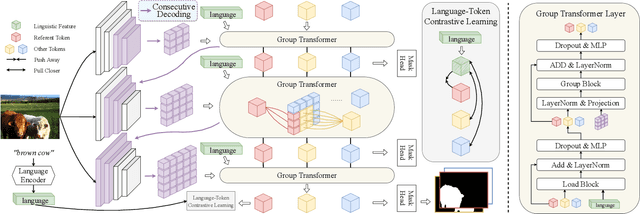
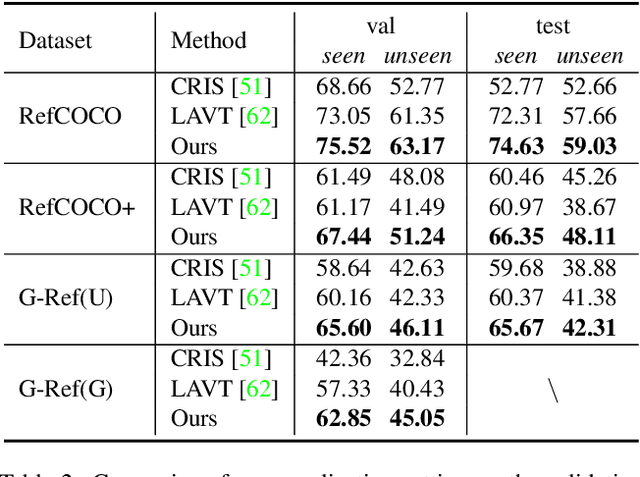
Referring image segmentation aims to segment the target referent in an image conditioning on a natural language expression. Existing one-stage methods employ per-pixel classification frameworks, which attempt straightforwardly to align vision and language at the pixel level, thus failing to capture critical object-level information. In this paper, we propose a mask classification framework, Contrastive Grouping with Transformer network (CGFormer), which explicitly captures object-level information via token-based querying and grouping strategy. Specifically, CGFormer first introduces learnable query tokens to represent objects and then alternately queries linguistic features and groups visual features into the query tokens for object-aware cross-modal reasoning. In addition, CGFormer achieves cross-level interaction by jointly updating the query tokens and decoding masks in every two consecutive layers. Finally, CGFormer cooperates contrastive learning to the grouping strategy to identify the token and its mask corresponding to the referent. Experimental results demonstrate that CGFormer outperforms state-of-the-art methods in both segmentation and generalization settings consistently and significantly.
Top-K Pooling with Patch Contrastive Learning for Weakly-Supervised Semantic Segmentation
Oct 15, 2023Weakly Supervised Semantic Segmentation (WSSS) using only image-level labels has gained significant attention due to cost-effectiveness. Recently, Vision Transformer (ViT) based methods without class activation map (CAM) have shown greater capability in generating reliable pseudo labels than previous methods using CAM. However, the current ViT-based methods utilize max pooling to select the patch with the highest prediction score to map the patch-level classification to the image-level one, which may affect the quality of pseudo labels due to the inaccurate classification of the patches. In this paper, we introduce a novel ViT-based WSSS method named top-K pooling with patch contrastive learning (TKP-PCL), which employs a top-K pooling layer to alleviate the limitations of previous max pooling selection. A patch contrastive error (PCE) is also proposed to enhance the patch embeddings to further improve the final results. The experimental results show that our approach is very efficient and outperforms other state-of-the-art WSSS methods on the PASCAL VOC 2012 dataset.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
Oct 17, 2023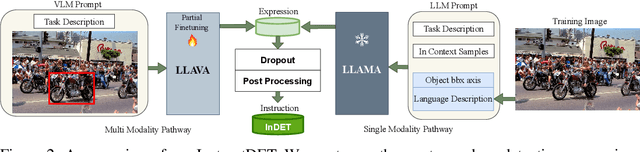

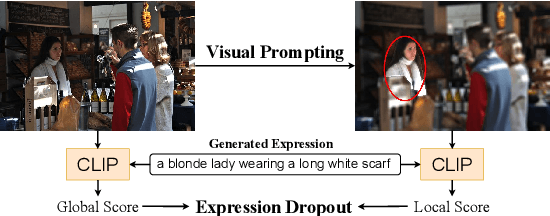
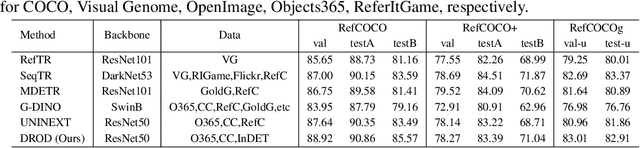
We propose InstructDET, a data-centric method for referring object detection (ROD) that localizes target objects based on user instructions. While deriving from referring expressions (REC), the instructions we leverage are greatly diversified to encompass common user intentions related to object detection. For one image, we produce tremendous instructions that refer to every single object and different combinations of multiple objects. Each instruction and its corresponding object bounding boxes (bbxs) constitute one training data pair. In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e.g., describing object property, category, and relationship). We name our constructed dataset as InDET. It contains images, bbxs and generalized instructions that are from foundation models. Our InDET is developed from existing REC datasets and object detection datasets, with the expanding potential that any image with object bbxs can be incorporated through using our InstructDET method. By using our InDET dataset, we show that a conventional ROD model surpasses existing methods on standard REC datasets and our InDET test set. Our data-centric method InstructDET, with automatic data expansion by leveraging foundation models, directs a promising field that ROD can be greatly diversified to execute common object detection instructions.
CongNaMul: A Dataset for Advanced Image Processing of Soybean Sprouts
Aug 31, 2023We present 'CongNaMul', a comprehensive dataset designed for various tasks in soybean sprouts image analysis. The CongNaMul dataset is curated to facilitate tasks such as image classification, semantic segmentation, decomposition, and measurement of length and weight. The classification task provides four classes to determine the quality of soybean sprouts: normal, broken, spotted, and broken and spotted, for the development of AI-aided automatic quality inspection technology. For semantic segmentation, images with varying complexity, from single sprout images to images with multiple sprouts, along with human-labelled mask images, are included. The label has 4 different classes: background, head, body, tail. The dataset also provides images and masks for the image decomposition task, including two separate sprout images and their combined form. Lastly, 5 physical features of sprouts (head length, body length, body thickness, tail length, weight) are provided for image-based measurement tasks. This dataset is expected to be a valuable resource for a wide range of research and applications in the advanced analysis of images of soybean sprouts. Also, we hope that this dataset can assist researchers studying classification, semantic segmentation, decomposition, and physical feature measurement in other industrial fields, in evaluating their models. The dataset is available at the authors' repository. (https://bhban.kr/data)
Dual Defense: Adversarial, Traceable, and Invisible Robust Watermarking against Face Swapping
Oct 25, 2023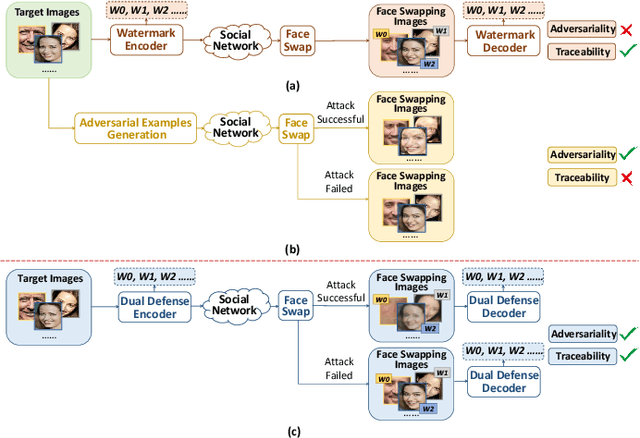
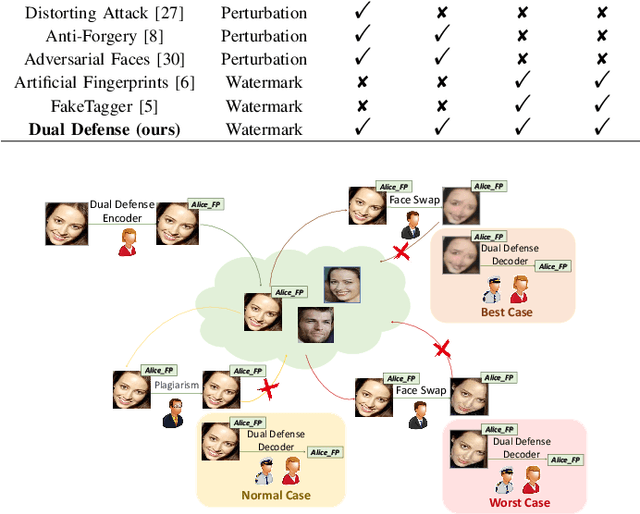
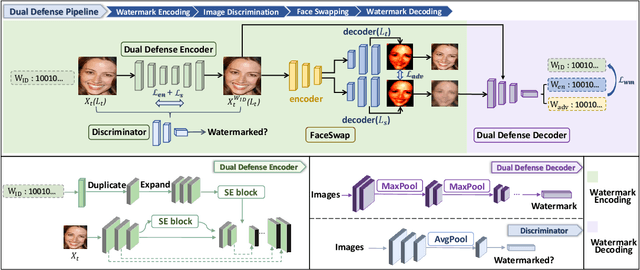
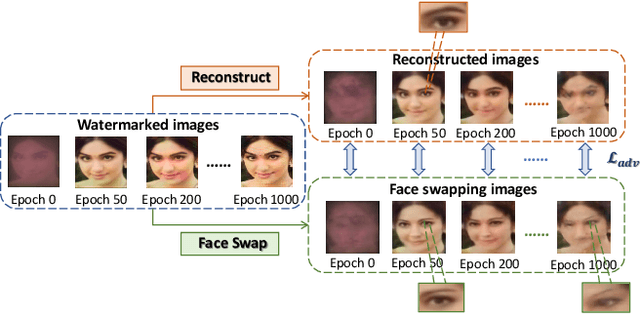
The malicious applications of deep forgery, represented by face swapping, have introduced security threats such as misinformation dissemination and identity fraud. While some research has proposed the use of robust watermarking methods to trace the copyright of facial images for post-event traceability, these methods cannot effectively prevent the generation of forgeries at the source and curb their dissemination. To address this problem, we propose a novel comprehensive active defense mechanism that combines traceability and adversariality, called Dual Defense. Dual Defense invisibly embeds a single robust watermark within the target face to actively respond to sudden cases of malicious face swapping. It disrupts the output of the face swapping model while maintaining the integrity of watermark information throughout the entire dissemination process. This allows for watermark extraction at any stage of image tracking for traceability. Specifically, we introduce a watermark embedding network based on original-domain feature impersonation attack. This network learns robust adversarial features of target facial images and embeds watermarks, seeking a well-balanced trade-off between watermark invisibility, adversariality, and traceability through perceptual adversarial encoding strategies. Extensive experiments demonstrate that Dual Defense achieves optimal overall defense success rates and exhibits promising universality in anti-face swapping tasks and dataset generalization ability. It maintains impressive adversariality and traceability in both original and robust settings, surpassing current forgery defense methods that possess only one of these capabilities, including CMUA-Watermark, Anti-Forgery, FakeTagger, or PGD methods.
Nighttime Driver Behavior Prediction Using Taillight Signal Recognition via CNN-SVM Classifier
Oct 25, 2023

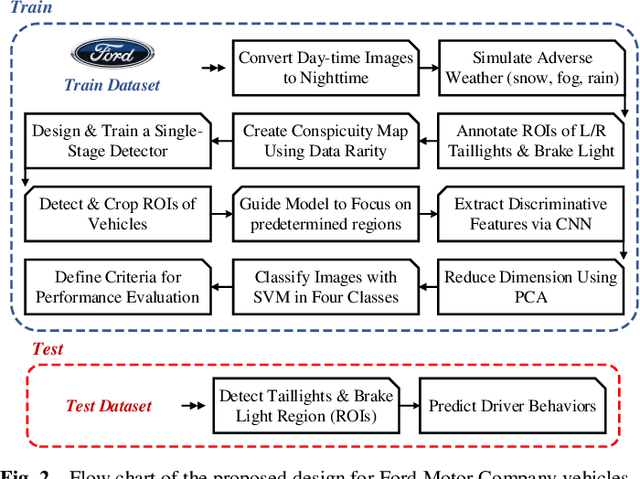

This paper aims to enhance the ability to predict nighttime driving behavior by identifying taillights of both human-driven and autonomous vehicles. The proposed model incorporates a customized detector designed to accurately detect front-vehicle taillights on the road. At the beginning of the detector, a learnable pre-processing block is implemented, which extracts deep features from input images and calculates the data rarity for each feature. In the next step, drawing inspiration from soft attention, a weighted binary mask is designed that guides the model to focus more on predetermined regions. This research utilizes Convolutional Neural Networks (CNNs) to extract distinguishing characteristics from these areas, then reduces dimensions using Principal Component Analysis (PCA). Finally, the Support Vector Machine (SVM) is used to predict the behavior of the vehicles. To train and evaluate the model, a large-scale dataset is collected from two types of dash-cams and Insta360 cameras from the rear view of Ford Motor Company vehicles. This dataset includes over 12k frames captured during both daytime and nighttime hours. To address the limited nighttime data, a unique pixel-wise image processing technique is implemented to convert daytime images into realistic night images. The findings from the experiments demonstrate that the proposed methodology can accurately categorize vehicle behavior with 92.14% accuracy, 97.38% specificity, 92.09% sensitivity, 92.10% F1-measure, and 0.895 Cohen's Kappa Statistic. Further details are available at https://github.com/DeepCar/Taillight_Recognition.
Wide Flat Minimum Watermarking for Robust Ownership Verification of GANs
Oct 25, 2023We propose a novel multi-bit box-free watermarking method for the protection of Intellectual Property Rights (IPR) of GANs with improved robustness against white-box attacks like fine-tuning, pruning, quantization, and surrogate model attacks. The watermark is embedded by adding an extra watermarking loss term during GAN training, ensuring that the images generated by the GAN contain an invisible watermark that can be retrieved by a pre-trained watermark decoder. In order to improve the robustness against white-box model-level attacks, we make sure that the model converges to a wide flat minimum of the watermarking loss term, in such a way that any modification of the model parameters does not erase the watermark. To do so, we add random noise vectors to the parameters of the generator and require that the watermarking loss term is as invariant as possible with respect to the presence of noise. This procedure forces the generator to converge to a wide flat minimum of the watermarking loss. The proposed method is architectureand dataset-agnostic, thus being applicable to many different generation tasks and models, as well as to CNN-based image processing architectures. We present the results of extensive experiments showing that the presence of the watermark has a negligible impact on the quality of the generated images, and proving the superior robustness of the watermark against model modification and surrogate model attacks.