 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
You'll Never Walk Alone: A Sketch and Text Duet for Fine-Grained Image Retrieval
Mar 20, 2024
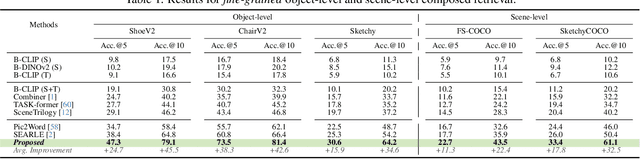
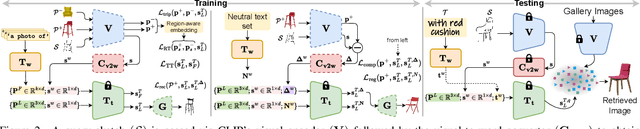

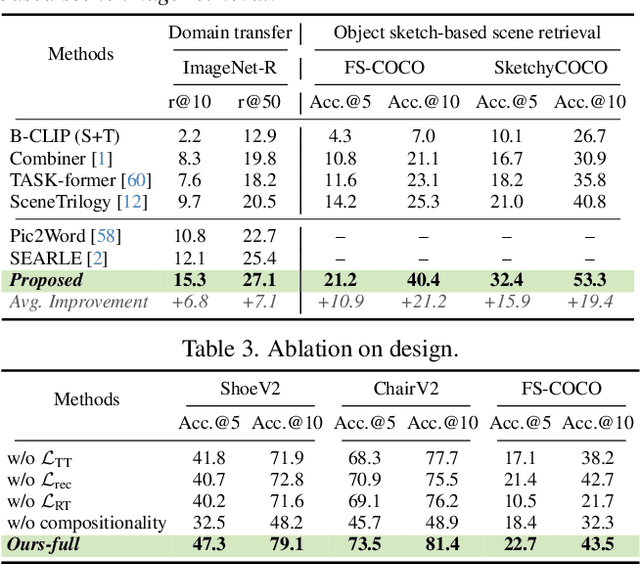
Two primary input modalities prevail in image retrieval: sketch and text. While text is widely used for inter-category retrieval tasks, sketches have been established as the sole preferred modality for fine-grained image retrieval due to their ability to capture intricate visual details. In this paper, we question the reliance on sketches alone for fine-grained image retrieval by simultaneously exploring the fine-grained representation capabilities of both sketch and text, orchestrating a duet between the two. The end result enables precise retrievals previously unattainable, allowing users to pose ever-finer queries and incorporate attributes like colour and contextual cues from text. For this purpose, we introduce a novel compositionality framework, effectively combining sketches and text using pre-trained CLIP models, while eliminating the need for extensive fine-grained textual descriptions. Last but not least, our system extends to novel applications in composed image retrieval, domain attribute transfer, and fine-grained generation, providing solutions for various real-world scenarios.
TraveLER: A Multi-LMM Agent Framework for Video Question-Answering
Apr 01, 2024Recently, Large Multimodal Models (LMMs) have made significant progress in video question-answering using a frame-wise approach by leveraging large-scale, image-based pretraining in a zero-shot manner. While image-based methods for videos have shown impressive performance, a current limitation is that they often overlook how key timestamps are selected and cannot adjust when incorrect timestamps are identified. Moreover, they are unable to extract details relevant to the question, instead providing general descriptions of the frame. To overcome this, we design a multi-LMM agent framework that travels along the video, iteratively collecting relevant information from keyframes through interactive question-asking until there is sufficient information to answer the question. Specifically, we propose TraveLER, a model that can create a plan to "Traverse" through the video, ask questions about individual frames to "Locate" and store key information, and then "Evaluate" if there is enough information to answer the question. Finally, if there is not enough information, our method is able to "Replan" based on its collected knowledge. Through extensive experiments, we find that the proposed TraveLER approach improves performance on several video question-answering benchmarks, such as NExT-QA, STAR, and Perception Test, without the need to fine-tune on specific datasets.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
Apr 01, 2024
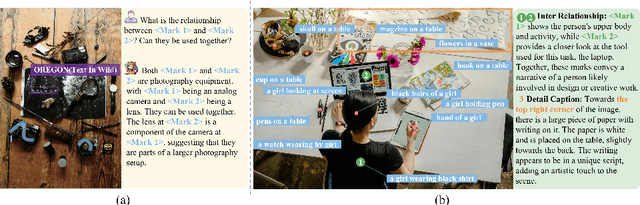
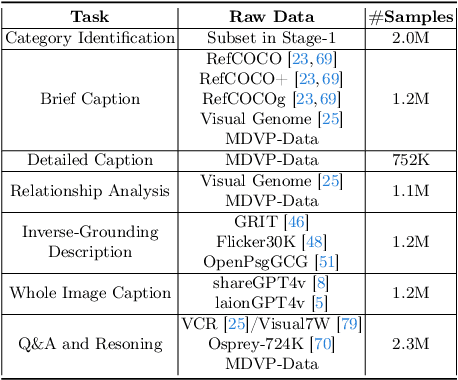
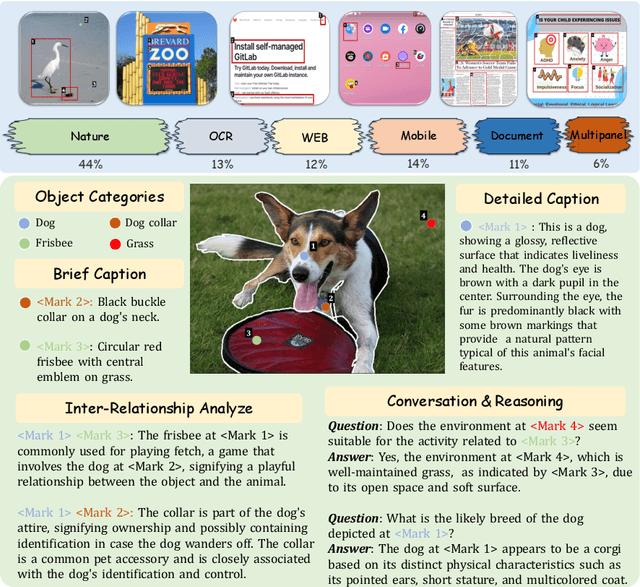
The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
FairRAG: Fair Human Generation via Fair Retrieval Augmentation
Mar 29, 2024
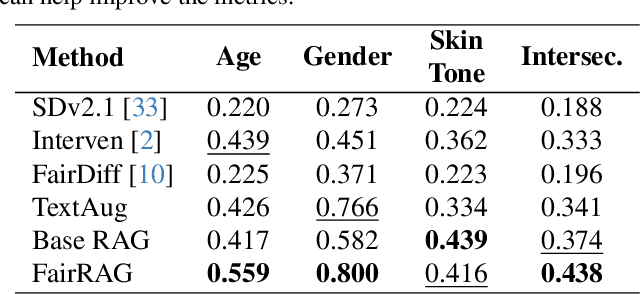
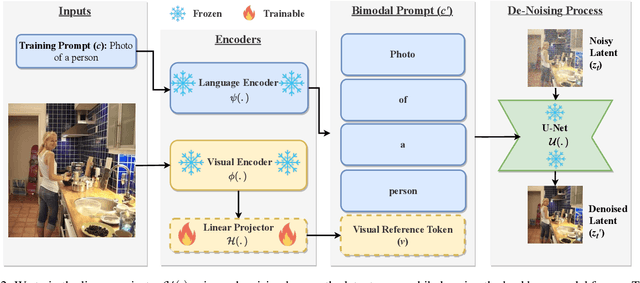
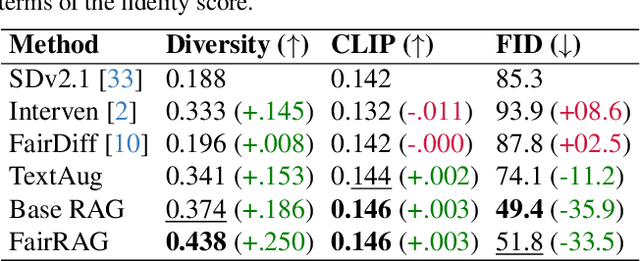
Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.
Relational Representation Learning Network for Cross-Spectral Image Patch Matching
Mar 18, 2024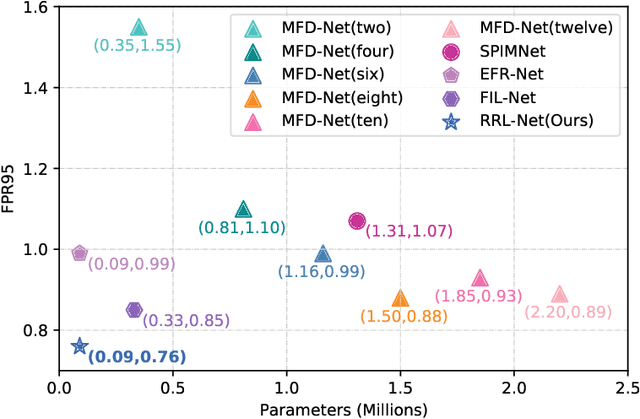
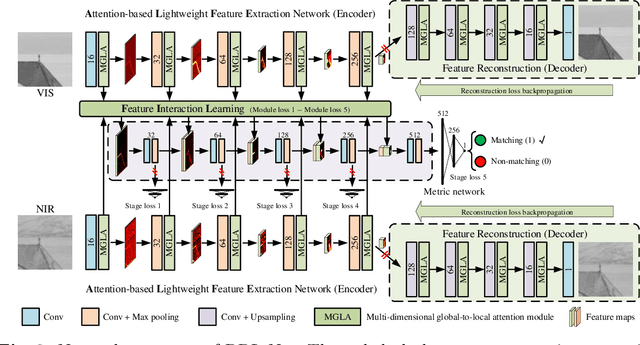
Recently, feature relation learning has drawn widespread attention in cross-spectral image patch matching. However, existing related research focuses on extracting diverse relations between image patch features and ignores sufficient intrinsic feature representations of individual image patches. Therefore, an innovative relational representation learning idea is proposed for the first time, which simultaneously focuses on sufficiently mining the intrinsic features of individual image patches and the relations between image patch features. Based on this, we construct a lightweight Relational Representation Learning Network (RRL-Net). Specifically, we innovatively construct an autoencoder to fully characterize the individual intrinsic features, and introduce a Feature Interaction Learning (FIL) module to extract deep-level feature relations. To further fully mine individual intrinsic features, a lightweight Multi-dimensional Global-to-Local Attention (MGLA) module is constructed to enhance the global feature extraction of individual image patches and capture local dependencies within global features. By combining the MGLA module, we further explore the feature extraction network and construct an Attention-based Lightweight Feature Extraction (ALFE) network. In addition, we propose a Multi-Loss Post-Pruning (MLPP) optimization strategy, which greatly promotes network optimization while avoiding increases in parameters and inference time. Extensive experiments demonstrate that our RRL-Net achieves state-of-the-art (SOTA) performance on multiple public datasets. Our code will be made public later.
ImageNot: A contrast with ImageNet preserves model rankings
Apr 02, 2024We introduce ImageNot, a dataset designed to match the scale of ImageNet while differing drastically in other aspects. We show that key model architectures developed for ImageNet over the years rank identically when trained and evaluated on ImageNot to how they rank on ImageNet. This is true when training models from scratch or fine-tuning them. Moreover, the relative improvements of each model over earlier models strongly correlate in both datasets. We further give evidence that ImageNot has a similar utility as ImageNet for transfer learning purposes. Our work demonstrates a surprising degree of external validity in the relative performance of image classification models. This stands in contrast with absolute accuracy numbers that typically drop sharply even under small changes to a dataset.
Quantifying Noise of Dynamic Vision Sensor
Apr 02, 2024Dynamic visual sensors (DVS) are characterized by a large amount of background activity (BA) noise, which it is mixed with the original (cleaned) sensor signal. The dynamic nature of the signal and the absence in practical application of the ground truth, it clearly makes difficult to distinguish between noise and the cleaned sensor signals using standard image processing techniques. In this letter, a new technique is presented to characterise BA noise derived from the Detrended Fluctuation Analysis (DFA). The proposed technique can be used to address an existing DVS issues, which is how to quantitatively characterised noise and signal without ground truth, and how to derive an optimal denoising filter parameters. The solution of the latter problem is demonstrated for the popular real moving-car dataset.
Constrained Robotic Navigation on Preferred Terrains Using LLMs and Speech Instruction: Exploiting the Power of Adverbs
Apr 02, 2024This paper explores leveraging large language models for map-free off-road navigation using generative AI, reducing the need for traditional data collection and annotation. We propose a method where a robot receives verbal instructions, converted to text through Whisper, and a large language model (LLM) model extracts landmarks, preferred terrains, and crucial adverbs translated into speed settings for constrained navigation. A language-driven semantic segmentation model generates text-based masks for identifying landmarks and terrain types in images. By translating 2D image points to the vehicle's motion plane using camera parameters, an MPC controller can guides the vehicle towards the desired terrain. This approach enhances adaptation to diverse environments and facilitates the use of high-level instructions for navigating complex and challenging terrains.
MotionChain: Conversational Motion Controllers via Multimodal Prompts
Apr 03, 2024Recent advancements in language models have demonstrated their adeptness in conducting multi-turn dialogues and retaining conversational context. However, this proficiency remains largely unexplored in other multimodal generative models, particularly in human motion models. By integrating multi-turn conversations in controlling continuous virtual human movements, generative human motion models can achieve an intuitive and step-by-step process of human task execution for humanoid robotics, game agents, or other embodied systems. In this work, we present MotionChain, a conversational human motion controller to generate continuous and long-term human motion through multimodal prompts. Specifically, MotionChain consists of multi-modal tokenizers that transform various data types such as text, image, and motion, into discrete tokens, coupled with a Vision-Motion-aware Language model. By leveraging large-scale language, vision-language, and vision-motion data to assist motion-related generation tasks, MotionChain thus comprehends each instruction in multi-turn conversation and generates human motions followed by these prompts. Extensive experiments validate the efficacy of MotionChain, demonstrating state-of-the-art performance in conversational motion generation, as well as more intuitive manners of controlling and interacting with virtual humans.
SalFoM: Dynamic Saliency Prediction with Video Foundation Models
Apr 03, 2024Recent advancements in video saliency prediction (VSP) have shown promising performance compared to the human visual system, whose emulation is the primary goal of VSP. However, current state-of-the-art models employ spatio-temporal transformers trained on limited amounts of data, hindering generalizability adaptation to downstream tasks. The benefits of vision foundation models present a potential solution to improve the VSP process. However, adapting image foundation models to the video domain presents significant challenges in modeling scene dynamics and capturing temporal information. To address these challenges, and as the first initiative to design a VSP model based on video foundation models, we introduce SalFoM, a novel encoder-decoder video transformer architecture. Our model employs UnMasked Teacher (UMT) as feature extractor and presents a heterogeneous decoder which features a locality-aware spatio-temporal transformer and integrates local and global spatio-temporal information from various perspectives to produce the final saliency map. Our qualitative and quantitative experiments on the challenging VSP benchmark datasets of DHF1K, Hollywood-2 and UCF-Sports demonstrate the superiority of our proposed model in comparison with the state-of-the-art methods.