 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Model-driven Engineering for Machine Learning Components: A Systematic Literature Review
Nov 01, 2023
Context: Machine Learning (ML) has become widely adopted as a component in many modern software applications. Due to the large volumes of data available, organizations want to increasingly leverage their data to extract meaningful insights and enhance business profitability. ML components enable predictive capabilities, anomaly detection, recommendation, accurate image and text processing, and informed decision-making. However, developing systems with ML components is not trivial; it requires time, effort, knowledge, and expertise in ML, data processing, and software engineering. There have been several studies on the use of model-driven engineering (MDE) techniques to address these challenges when developing traditional software and cyber-physical systems. Recently, there has been a growing interest in applying MDE for systems with ML components. Objective: The goal of this study is to further explore the promising intersection of MDE with ML (MDE4ML) through a systematic literature review (SLR). Through this SLR, we wanted to analyze existing studies, including their motivations, MDE solutions, evaluation techniques, key benefits and limitations. Results: We analyzed selected studies with respect to several areas of interest and identified the following: 1) the key motivations behind using MDE4ML; 2) a variety of MDE solutions applied, such as modeling languages, model transformations, tool support, targeted ML aspects, contributions and more; 3) the evaluation techniques and metrics used; and 4) the limitations and directions for future work. We also discuss the gaps in existing literature and provide recommendations for future research. Conclusion: This SLR highlights current trends, gaps and future research directions in the field of MDE4ML, benefiting both researchers and practitioners
Tailoring Adversarial Attacks on Deep Neural Networks for Targeted Class Manipulation Using DeepFool Algorithm
Oct 18, 2023Deep neural networks (DNNs) have significantly advanced various domains, but their vulnerability to adversarial attacks poses serious concerns. Understanding these vulnerabilities and developing effective defense mechanisms is crucial. DeepFool, an algorithm proposed by Moosavi-Dezfooli et al. (2016), finds minimal perturbations to misclassify input images. However, DeepFool lacks a targeted approach, making it less effective in specific attack scenarios. Also, in previous related works, researchers primarily focus on success, not considering how much an image is getting distorted; the integrity of the image quality, and the confidence level to misclassifying. So, in this paper, we propose Targeted DeepFool, an augmented version of DeepFool that allows targeting specific classes for misclassification. We also introduce a minimum confidence score requirement hyperparameter to enhance flexibility. Our experiments demonstrate the effectiveness and efficiency of the proposed method across different deep neural network architectures while preserving image integrity as much as possible. Results show that one of the deep convolutional neural network architectures, AlexNet, and one of the state-of-the-art model Vision Transformer exhibit high robustness to getting fooled. Our code will be made public when publishing the paper.
Towards Universal Image Embeddings: A Large-Scale Dataset and Challenge for Generic Image Representations
Sep 04, 2023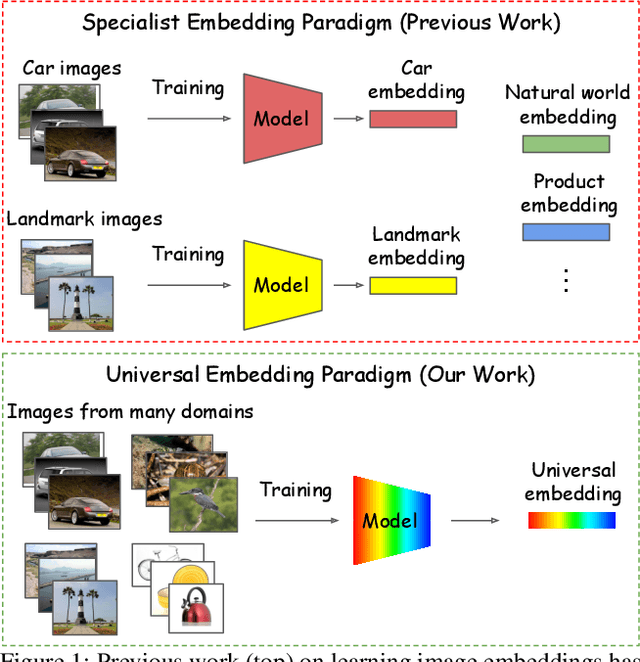
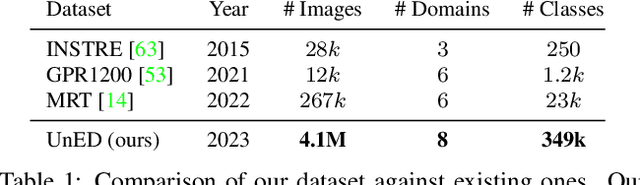
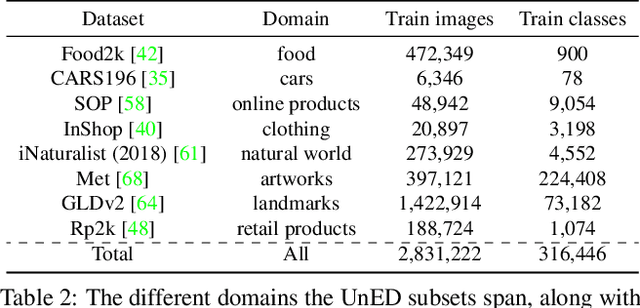
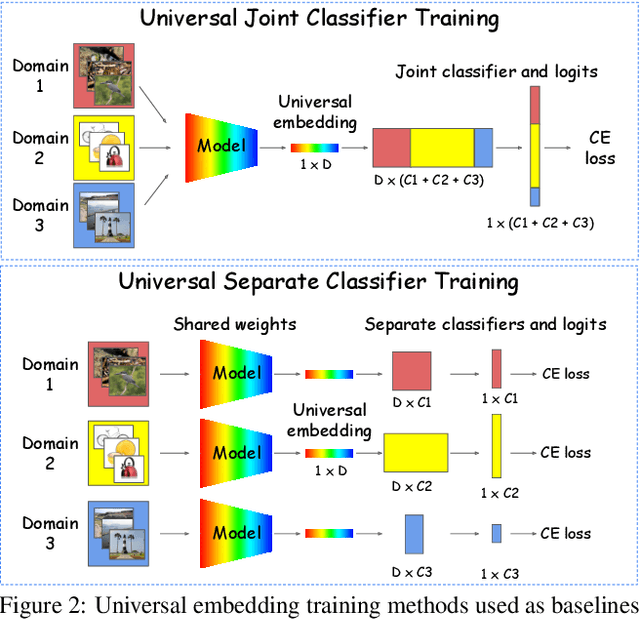
Fine-grained and instance-level recognition methods are commonly trained and evaluated on specific domains, in a model per domain scenario. Such an approach, however, is impractical in real large-scale applications. In this work, we address the problem of universal image embedding, where a single universal model is trained and used in multiple domains. First, we leverage existing domain-specific datasets to carefully construct a new large-scale public benchmark for the evaluation of universal image embeddings, with 241k query images, 1.4M index images and 2.8M training images across 8 different domains and 349k classes. We define suitable metrics, training and evaluation protocols to foster future research in this area. Second, we provide a comprehensive experimental evaluation on the new dataset, demonstrating that existing approaches and simplistic extensions lead to worse performance than an assembly of models trained for each domain separately. Finally, we conducted a public research competition on this topic, leveraging industrial datasets, which attracted the participation of more than 1k teams worldwide. This exercise generated many interesting research ideas and findings which we present in detail. Project webpage: https://cmp.felk.cvut.cz/univ_emb/
Harvest Video Foundation Models via Efficient Post-Pretraining
Oct 30, 2023Building video-language foundation models is costly and difficult due to the redundant nature of video data and the lack of high-quality video-language datasets. In this paper, we propose an efficient framework to harvest video foundation models from image ones. Our method is intuitively simple by randomly dropping input video patches and masking out input text during the post-pretraining procedure. The patch dropping boosts the training efficiency significantly and text masking enforces the learning of cross-modal fusion. We conduct extensive experiments to validate the effectiveness of our method on a wide range of video-language downstream tasks including various zero-shot tasks, video question answering, and video-text retrieval. Despite its simplicity, our method achieves state-of-the-art performances, which are comparable to some heavily pretrained video foundation models. Our method is extremely efficient and can be trained in less than one day on 8 GPUs, requiring only WebVid-10M as pretraining data. We hope our method can serve as a simple yet strong counterpart for prevalent video foundation models, provide useful insights when building them, and make large pretrained models more accessible and sustainable. This is part of the InternVideo project \url{https://github.com/OpenGVLab/InternVideo}.
Emotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
Oct 30, 2023The emotional theory of mind problem in images is an emotion recognition task, specifically asking "How does the person in the bounding box feel?" Facial expressions, body pose, contextual information and implicit commonsense knowledge all contribute to the difficulty of the task, making this task currently one of the hardest problems in affective computing. The goal of this work is to evaluate the emotional commonsense knowledge embedded in recent large vision language models (CLIP, LLaVA) and large language models (GPT-3.5) on the Emotions in Context (EMOTIC) dataset. In order to evaluate a purely text-based language model on images, we construct "narrative captions" relevant to emotion perception, using a set of 872 physical social signal descriptions related to 26 emotional categories, along with 224 labels for emotionally salient environmental contexts, sourced from writer's guides for character expressions and settings. We evaluate the use of the resulting captions in an image-to-language-to-emotion task. Experiments using zero-shot vision-language models on EMOTIC show that combining "fast" and "slow" reasoning is a promising way forward to improve emotion recognition systems. Nevertheless, a gap remains in the zero-shot emotional theory of mind task compared to prior work trained on the EMOTIC dataset.
A Dataset of Relighted 3D Interacting Hands
Oct 26, 2023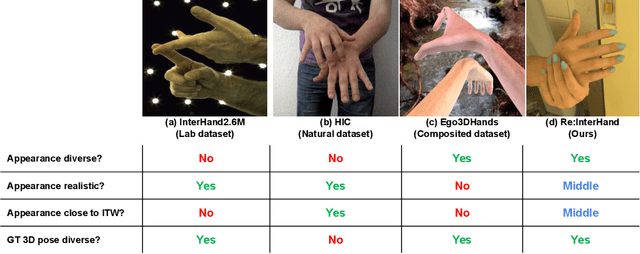
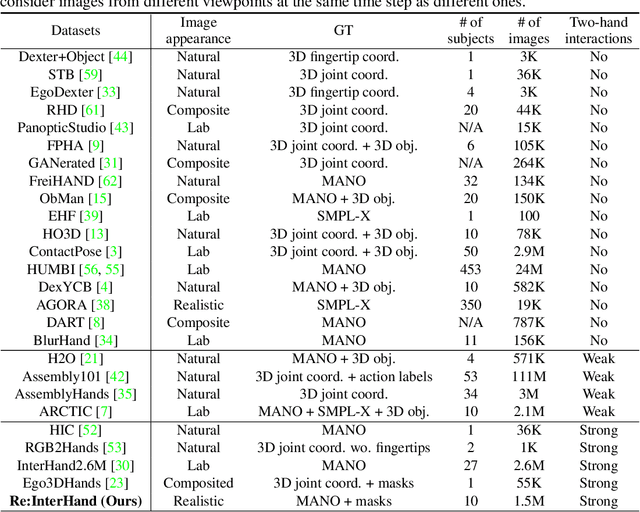
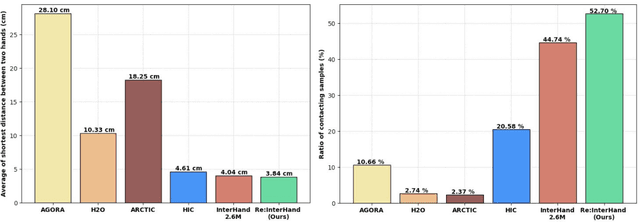
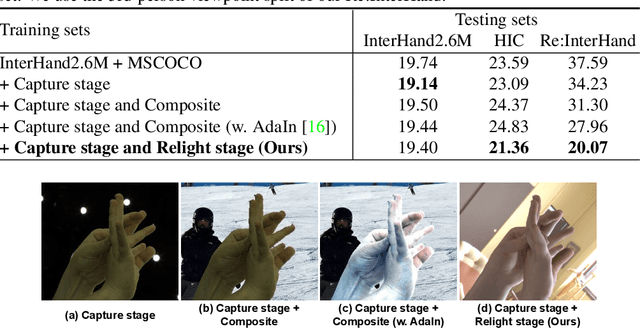
The two-hand interaction is one of the most challenging signals to analyze due to the self-similarity, complicated articulations, and occlusions of hands. Although several datasets have been proposed for the two-hand interaction analysis, all of them do not achieve 1) diverse and realistic image appearances and 2) diverse and large-scale groundtruth (GT) 3D poses at the same time. In this work, we propose Re:InterHand, a dataset of relighted 3D interacting hands that achieve the two goals. To this end, we employ a state-of-the-art hand relighting network with our accurately tracked two-hand 3D poses. We compare our Re:InterHand with existing 3D interacting hands datasets and show the benefit of it. Our Re:InterHand is available in https://mks0601.github.io/ReInterHand/.
Mutual-Guided Dynamic Network for Image Fusion
Sep 01, 2023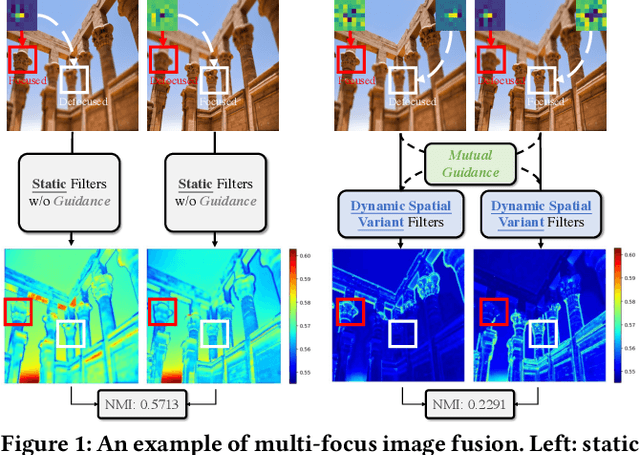

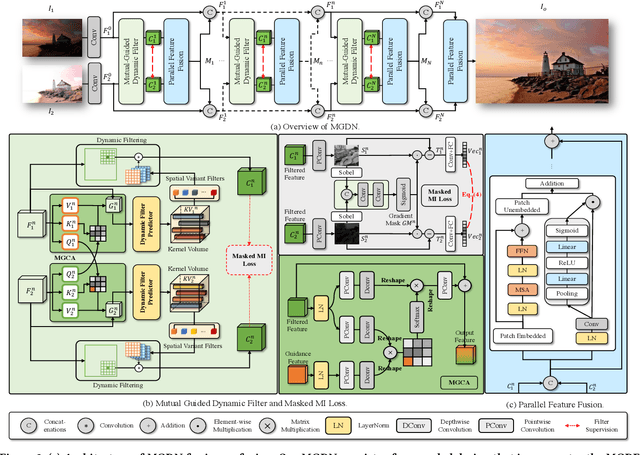
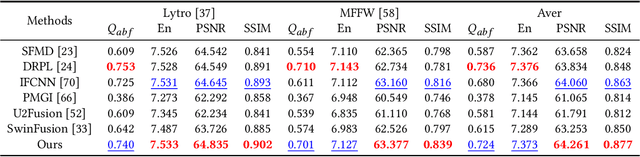
Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
Competitive Ensembling Teacher-Student Framework for Semi-Supervised Left Atrium MRI Segmentation
Oct 21, 2023Semi-supervised learning has greatly advanced medical image segmentation since it effectively alleviates the need of acquiring abundant annotations from experts and utilizes unlabeled data which is much easier to acquire. Among existing perturbed consistency learning methods, mean-teacher model serves as a standard baseline for semi-supervised medical image segmentation. In this paper, we present a simple yet efficient competitive ensembling teacher student framework for semi-supervised for left atrium segmentation from 3D MR images, in which two student models with different task-level disturbances are introduced to learn mutually, while a competitive ensembling strategy is performed to ensemble more reliable information to teacher model. Different from the one-way transfer between teacher and student models, our framework facilitates the collaborative learning procedure of different student models with the guidance of teacher model and motivates different training networks for a competitive learning and ensembling procedure to achieve better performance. We evaluate our proposed method on the public Left Atrium (LA) dataset and it obtains impressive performance gains by exploiting the unlabeled data effectively and outperforms several existing semi-supervised methods.
End-to-End (Instance)-Image Goal Navigation through Correspondence as an Emergent Phenomenon
Sep 28, 2023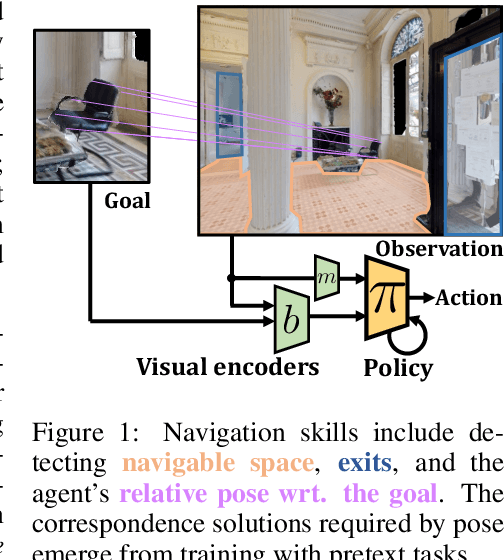


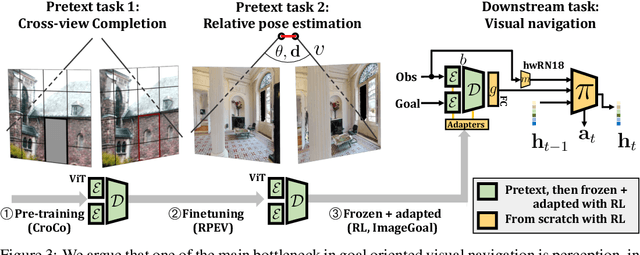
Most recent work in goal oriented visual navigation resorts to large-scale machine learning in simulated environments. The main challenge lies in learning compact representations generalizable to unseen environments and in learning high-capacity perception modules capable of reasoning on high-dimensional input. The latter is particularly difficult when the goal is not given as a category ("ObjectNav") but as an exemplar image ("ImageNav"), as the perception module needs to learn a comparison strategy requiring to solve an underlying visual correspondence problem. This has been shown to be difficult from reward alone or with standard auxiliary tasks. We address this problem through a sequence of two pretext tasks, which serve as a prior for what we argue is one of the main bottleneck in perception, extremely wide-baseline relative pose estimation and visibility prediction in complex scenes. The first pretext task, cross-view completion is a proxy for the underlying visual correspondence problem, while the second task addresses goal detection and finding directly. We propose a new dual encoder with a large-capacity binocular ViT model and show that correspondence solutions naturally emerge from the training signals. Experiments show significant improvements and SOTA performance on the two benchmarks, ImageNav and the Instance-ImageNav variant, where camera intrinsics and height differ between observation and goal.
Beyond Generation: Harnessing Text to Image Models for Object Detection and Segmentation
Sep 12, 2023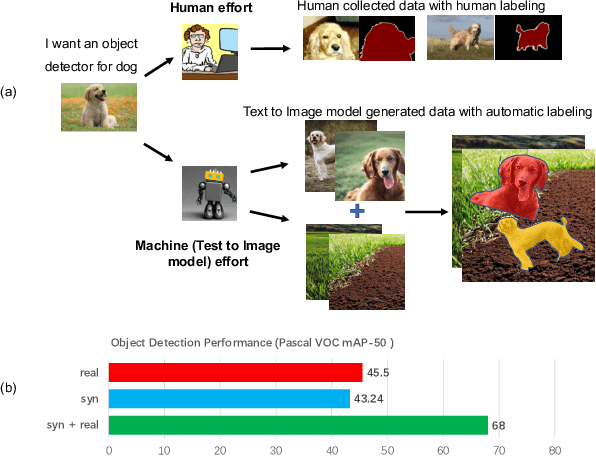

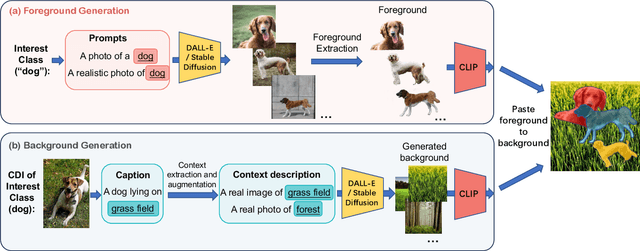

We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-to-image synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach1 decouples training data generation into foreground object generation, and contextually coherent background generation. To generate foreground objects, we employ a straightforward textual template, incorporating the object class name as input prompts. This is fed into a text-to-image synthesis framework, producing various foreground images set against isolated backgrounds. A foreground-background segmentation algorithm is then used to generate foreground object masks. To generate context images, we begin by creating language descriptions of the context. This is achieved by applying an image captioning method to a small set of images representing the desired context. These textual descriptions are then transformed into a diverse array of context images via a text-to-image synthesis framework. Subsequently, we composite these with the foreground object masks produced in the initial step, utilizing a cut-and-paste method, to formulate the training data. We demonstrate the advantages of our approach on five object detection and segmentation datasets, including Pascal VOC and COCO. We found that detectors trained solely on synthetic data produced by our method achieve performance comparable to those trained on real data (Fig. 1). Moreover, a combination of real and synthetic data yields even much better results. Further analysis indicates that the synthetic data distribution complements the real data distribution effectively. Additionally, we emphasize the compositional nature of our data generation approach in out-of-distribution and zero-shot data generation scenarios. We open-source our code at https://github.com/gyhandy/Text2Image-for-Detection