 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Skip-WaveNet: A Wavelet based Multi-scale Architecture to Trace Firn Layers in Radar Echograms
Oct 30, 2023
Echograms created from airborne radar sensors capture the profile of firn layers present on top of an ice sheet. Accurate tracking of these layers is essential to calculate the snow accumulation rates, which are required to investigate the contribution of polar ice cap melt to sea level rise. However, automatically processing the radar echograms to detect the underlying firn layers is a challenging problem. In our work, we develop wavelet-based multi-scale deep learning architectures for these radar echograms to improve firn layer detection. We show that wavelet based architectures improve the optimal dataset scale (ODS) and optimal image scale (OIS) F-scores by 3.99% and 3.7%, respectively, over the non-wavelet architecture. Further, our proposed Skip-WaveNet architecture generates new wavelets in each iteration, achieves higher generalizability as compared to state-of-the-art firn layer detection networks, and estimates layer depths with a mean absolute error of 3.31 pixels and 94.3% average precision. Such a network can be used by scientists to trace firn layers, calculate the annual snow accumulation rates, estimate the resulting surface mass balance of the ice sheet, and help project global sea level rise.
RayDF: Neural Ray-surface Distance Fields with Multi-view Consistency
Oct 30, 2023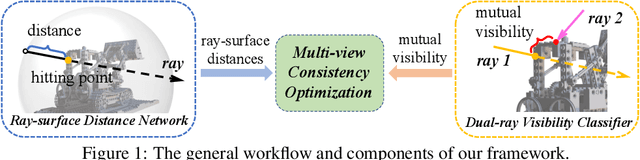
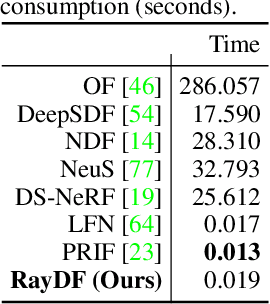
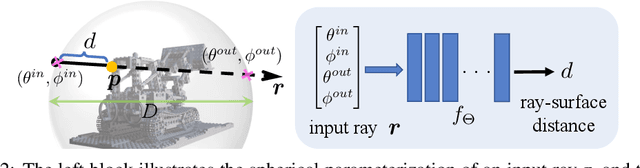
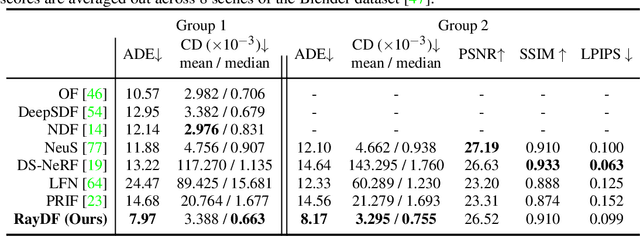
In this paper, we study the problem of continuous 3D shape representations. The majority of existing successful methods are coordinate-based implicit neural representations. However, they are inefficient to render novel views or recover explicit surface points. A few works start to formulate 3D shapes as ray-based neural functions, but the learned structures are inferior due to the lack of multi-view geometry consistency. To tackle these challenges, we propose a new framework called RayDF. It consists of three major components: 1) the simple ray-surface distance field, 2) the novel dual-ray visibility classifier, and 3) a multi-view consistency optimization module to drive the learned ray-surface distances to be multi-view geometry consistent. We extensively evaluate our method on three public datasets, demonstrating remarkable performance in 3D surface point reconstruction on both synthetic and challenging real-world 3D scenes, clearly surpassing existing coordinate-based and ray-based baselines. Most notably, our method achieves a 1000x faster speed than coordinate-based methods to render an 800x800 depth image, showing the superiority of our method for 3D shape representation. Our code and data are available at https://github.com/vLAR-group/RayDF
Conditional Unscented Autoencoders for Trajectory Prediction
Oct 30, 2023The \ac{CVAE} is one of the most widely-used models in trajectory prediction for \ac{AD}. It captures the interplay between a driving context and its ground-truth future into a probabilistic latent space and uses it to produce predictions. In this paper, we challenge key components of the CVAE. We leverage recent advances in the space of the VAE, the foundation of the CVAE, which show that a simple change in the sampling procedure can greatly benefit performance. We find that unscented sampling, which draws samples from any learned distribution in a deterministic manner, can naturally be better suited to trajectory prediction than potentially dangerous random sampling. We go further and offer additional improvements, including a more structured mixture latent space, as well as a novel, potentially more expressive way to do inference with CVAEs. We show wide applicability of our models by evaluating them on the INTERACTION prediction dataset, outperforming the state of the art, as well as at the task of image modeling on the CelebA dataset, outperforming the baseline vanilla CVAE. Code is available at https://github.com/boschresearch/cuae-prediction.
Look At Me, No Replay! SurpriseNet: Anomaly Detection Inspired Class Incremental Learning
Oct 30, 2023Continual learning aims to create artificial neural networks capable of accumulating knowledge and skills through incremental training on a sequence of tasks. The main challenge of continual learning is catastrophic interference, wherein new knowledge overrides or interferes with past knowledge, leading to forgetting. An associated issue is the problem of learning "cross-task knowledge," where models fail to acquire and retain knowledge that helps differentiate classes across task boundaries. A common solution to both problems is "replay," where a limited buffer of past instances is utilized to learn cross-task knowledge and mitigate catastrophic interference. However, a notable drawback of these methods is their tendency to overfit the limited replay buffer. In contrast, our proposed solution, SurpriseNet, addresses catastrophic interference by employing a parameter isolation method and learning cross-task knowledge using an auto-encoder inspired by anomaly detection. SurpriseNet is applicable to both structured and unstructured data, as it does not rely on image-specific inductive biases. We have conducted empirical experiments demonstrating the strengths of SurpriseNet on various traditional vision continual-learning benchmarks, as well as on structured data datasets. Source code made available at https://doi.org/10.5281/zenodo.8247906 and https://github.com/tachyonicClock/SurpriseNet-CIKM-23
SparseDFF: Sparse-View Feature Distillation for One-Shot Dexterous Manipulation
Oct 25, 2023
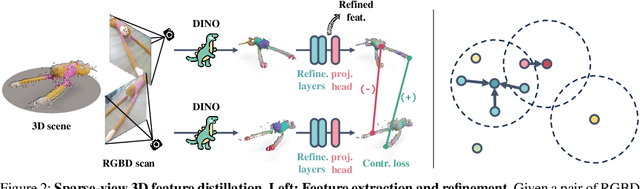


Humans excel at transferring manipulation skills across diverse object shapes, poses, and appearances due to their understanding of semantic correspondences between different instances. To endow robots with a similar high-level understanding, we develop a Distilled Feature Field (DFF) for 3D scenes, leveraging large 2D vision models to distill semantic features from multiview images. While current research demonstrates advanced performance in reconstructing DFFs from dense views, the development of learning a DFF from sparse views is relatively nascent, despite its prevalence in numerous manipulation tasks with fixed cameras. In this work, we introduce SparseDFF, a novel method for acquiring view-consistent 3D DFFs from sparse RGBD observations, enabling one-shot learning of dexterous manipulations that are transferable to novel scenes. Specifically, we map the image features to the 3D point cloud, allowing for propagation across the 3D space to establish a dense feature field. At the core of SparseDFF is a lightweight feature refinement network, optimized with a contrastive loss between pairwise views after back-projecting the image features onto the 3D point cloud. Additionally, we implement a point-pruning mechanism to augment feature continuity within each local neighborhood. By establishing coherent feature fields on both source and target scenes, we devise an energy function that facilitates the minimization of feature discrepancies w.r.t. the end-effector parameters between the demonstration and the target manipulation. We evaluate our approach using a dexterous hand, mastering real-world manipulations on both rigid and deformable objects, and showcase robust generalization in the face of object and scene-context variations.
RSAdapter: Adapting Multimodal Models for Remote Sensing Visual Question Answering
Oct 19, 2023In recent years, with the rapid advancement of transformer models, transformer-based multimodal architectures have found wide application in various downstream tasks, including but not limited to Image Captioning, Visual Question Answering (VQA), and Image-Text Generation. However, contemporary approaches to Remote Sensing (RS) VQA often involve resource-intensive techniques, such as full fine-tuning of large models or the extraction of image-text features from pre-trained multimodal models, followed by modality fusion using decoders. These approaches demand significant computational resources and time, and a considerable number of trainable parameters are introduced. To address these challenges, we introduce a novel method known as RSAdapter, which prioritizes runtime and parameter efficiency. RSAdapter comprises two key components: the Parallel Adapter and an additional linear transformation layer inserted after each fully connected (FC) layer within the Adapter. This approach not only improves adaptation to pre-trained multimodal models but also allows the parameters of the linear transformation layer to be integrated into the preceding FC layers during inference, reducing inference costs. To demonstrate the effectiveness of RSAdapter, we conduct an extensive series of experiments using three distinct RS-VQA datasets and achieve state-of-the-art results on all three datasets. The code for RSAdapter will be available online at https://github.com/Y-D-Wang/RSAdapter.
Lost in Translation: When GPT-4V(ision) Can't See Eye to Eye with Text. A Vision-Language-Consistency Analysis of VLLMs and Beyond
Oct 19, 2023Recent advancements in multimodal techniques open exciting possibilities for models excelling in diverse tasks involving text, audio, and image processing. Models like GPT-4V, blending computer vision and language modeling, excel in complex text and image tasks. Numerous prior research endeavors have diligently examined the performance of these Vision Large Language Models (VLLMs) across tasks like object detection, image captioning and others. However, these analyses often focus on evaluating the performance of each modality in isolation, lacking insights into their cross-modal interactions. Specifically, questions concerning whether these vision-language models execute vision and language tasks consistently or independently have remained unanswered. In this study, we draw inspiration from recent investigations into multilingualism and conduct a comprehensive analysis of model's cross-modal interactions. We introduce a systematic framework that quantifies the capability disparities between different modalities in the multi-modal setting and provide a set of datasets designed for these evaluations. Our findings reveal that models like GPT-4V tend to perform consistently modalities when the tasks are relatively simple. However, the trustworthiness of results derived from the vision modality diminishes as the tasks become more challenging. Expanding on our findings, we introduce "Vision Description Prompting," a method that effectively improves performance in challenging vision-related tasks.
IFT: Image Fusion Transformer for Ghost-free High Dynamic Range Imaging
Sep 26, 2023Multi-frame high dynamic range (HDR) imaging aims to reconstruct ghost-free images with photo-realistic details from content-complementary but spatially misaligned low dynamic range (LDR) images. Existing HDR algorithms are prone to producing ghosting artifacts as their methods fail to capture long-range dependencies between LDR frames with large motion in dynamic scenes. To address this issue, we propose a novel image fusion transformer, referred to as IFT, which presents a fast global patch searching (FGPS) module followed by a self-cross fusion module (SCF) for ghost-free HDR imaging. The FGPS searches the patches from supporting frames that have the closest dependency to each patch of the reference frame for long-range dependency modeling, while the SCF conducts intra-frame and inter-frame feature fusion on the patches obtained by the FGPS with linear complexity to input resolution. By matching similar patches between frames, objects with large motion ranges in dynamic scenes can be aligned, which can effectively alleviate the generation of artifacts. In addition, the proposed FGPS and SCF can be integrated into various deep HDR methods as efficient plug-in modules. Extensive experiments on multiple benchmarks show that our method achieves state-of-the-art performance both quantitatively and qualitatively.
Visual Question Generation in Bengali
Oct 12, 2023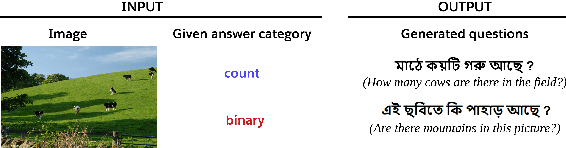
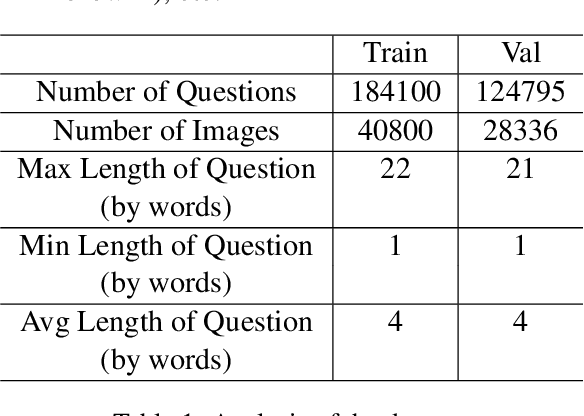
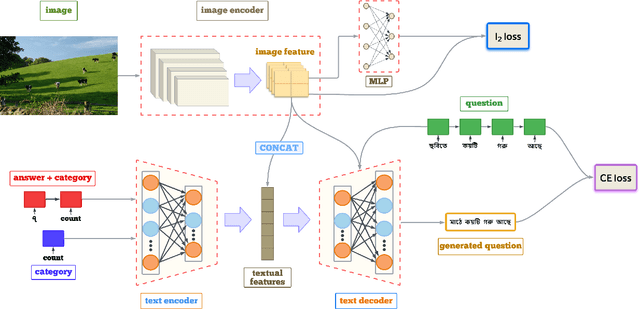
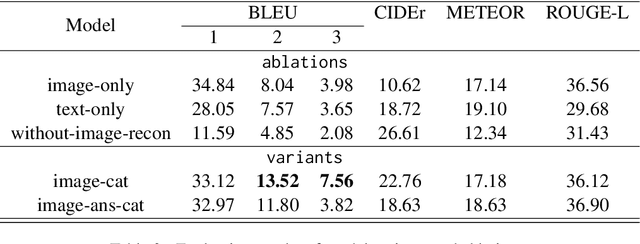
The task of Visual Question Generation (VQG) is to generate human-like questions relevant to the given image. As VQG is an emerging research field, existing works tend to focus only on resource-rich language such as English due to the availability of datasets. In this paper, we propose the first Bengali Visual Question Generation task and develop a novel transformer-based encoder-decoder architecture that generates questions in Bengali when given an image. We propose multiple variants of models - (i) image-only: baseline model of generating questions from images without additional information, (ii) image-category and image-answer-category: guided VQG where we condition the model to generate questions based on the answer and the category of expected question. These models are trained and evaluated on the translated VQAv2.0 dataset. Our quantitative and qualitative results establish the first state of the art models for VQG task in Bengali and demonstrate that our models are capable of generating grammatically correct and relevant questions. Our quantitative results show that our image-cat model achieves a BLUE-1 score of 33.12 and BLEU-3 score of 7.56 which is the highest of the other two variants. We also perform a human evaluation to assess the quality of the generation tasks. Human evaluation suggests that image-cat model is capable of generating goal-driven and attribute-specific questions and also stays relevant to the corresponding image.
* 19 pages including references, 4 figures and 3 tables. Accepted in the Proceedings of the Workshop on Multimodal, Multilingual Natural Language Generation and Multilingual WebNLG Challenge (MM-NLG 2023)
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
Sep 13, 2023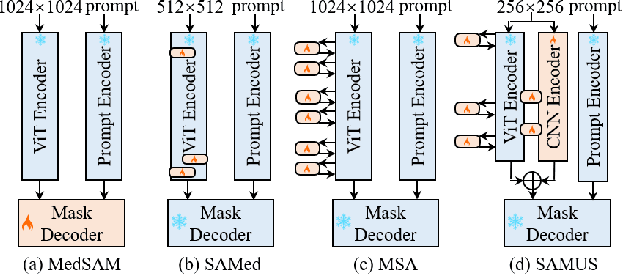
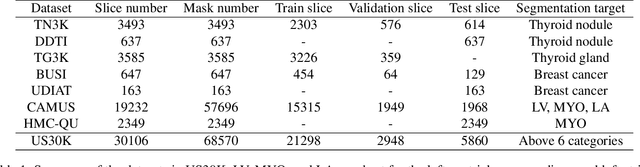
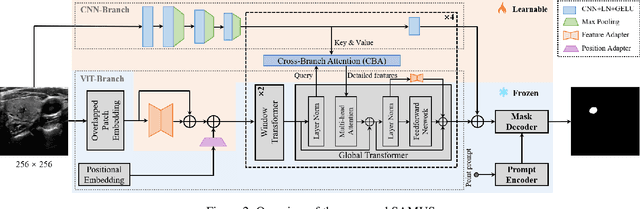
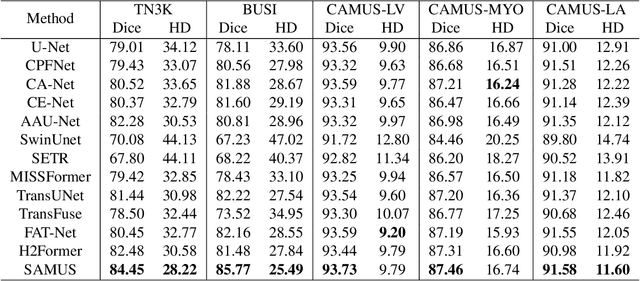
Segment anything model (SAM), an eminent universal image segmentation model, has recently gathered considerable attention within the domain of medical image segmentation. Despite the remarkable performance of SAM on natural images, it grapples with significant performance degradation and limited generalization when confronted with medical images, particularly with those involving objects of low contrast, faint boundaries, intricate shapes, and diminutive sizes. In this paper, we propose SAMUS, a universal model tailored for ultrasound image segmentation. In contrast to previous SAM-based universal models, SAMUS pursues not only better generalization but also lower deployment cost, rendering it more suitable for clinical applications. Specifically, based on SAM, a parallel CNN branch is introduced to inject local features into the ViT encoder through cross-branch attention for better medical image segmentation. Then, a position adapter and a feature adapter are developed to adapt SAM from natural to medical domains and from requiring large-size inputs (1024x1024) to small-size inputs (256x256) for more clinical-friendly deployment. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate SAMUS's superiority against the state-of-the-art task-specific models and universal foundation models under both task-specific evaluation and generalization evaluation. Moreover, SAMUS is deployable on entry-level GPUs, as it has been liberated from the constraints of long sequence encoding. The code, data, and models will be released at https://github.com/xianlin7/SAMUS.