 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Portable Ultrasound Imaging Pipeline Implementation with GPU Acceleration on Nvidia CLARA AGX
Oct 31, 2023
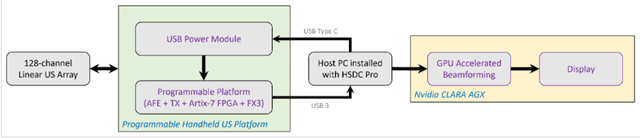
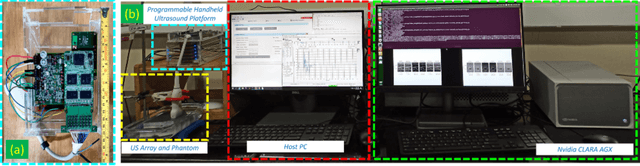
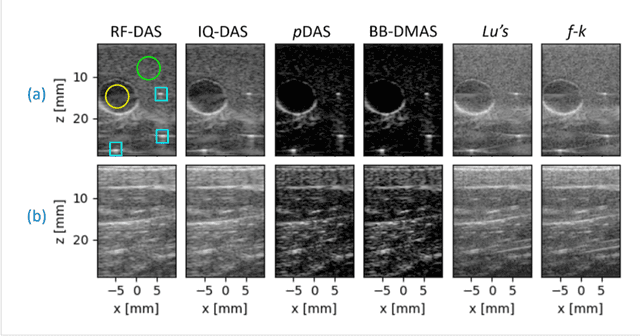
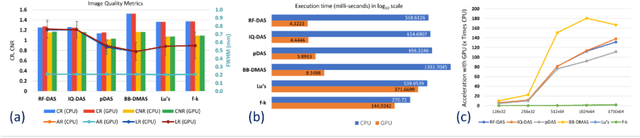
In this paper, we present a GPU-accelerated prototype implementation of a portable ultrasound imaging pipeline on an Nvidia CLARA AGX development kit. The raw data is acquired with nonsteered plane wave transmit using a programmable handheld open platform that supports 128-channel transmit and 64-channel receive. The received signals are transferred to the Nvidia CLARA AGX developer platform through a host system for accelerated imaging. GPU-accelerated implementation of the conventional delay and sum (DAS) beamformer along with two adaptive nonlinear beamformers and two Fourier-based techniques was performed. The feasibility of the complete pipeline and its imaging performance was evaluated with in-vitro phantom imaging experiments and the efficacy is demonstrated with preliminary in-vivo scans. The image quality quantified by the standard contrast and resolution metrics was comparable with that of the CPU implementation. The execution speed of the implemented beamformers was also investigated for different sizes of imaging grids and a significant speedup as high as 180 times that of the CPU implementation was observed. Since the proposed pipeline involves Nvidia CLARA AGX, there is always the potential for easy incorporation of online/active learning approaches.
Dynamic Batch Norm Statistics Update for Natural Robustness
Oct 31, 2023DNNs trained on natural clean samples have been shown to perform poorly on corrupted samples, such as noisy or blurry images. Various data augmentation methods have been recently proposed to improve DNN's robustness against common corruptions. Despite their success, they require computationally expensive training and cannot be applied to off-the-shelf trained models. Recently, it has been shown that updating BatchNorm (BN) statistics of an off-the-shelf model on a single corruption improves its accuracy on that corruption significantly. However, adopting the idea at inference time when the type of corruption is unknown and changing decreases the effectiveness of this method. In this paper, we harness the Fourier domain to detect the corruption type, a challenging task in the image domain. We propose a unified framework consisting of a corruption-detection model and BN statistics update that improves the corruption accuracy of any off-the-shelf trained model. We benchmark our framework on different models and datasets. Our results demonstrate about 8% and 4% accuracy improvement on CIFAR10-C and ImageNet-C, respectively. Furthermore, our framework can further improve the accuracy of state-of-the-art robust models, such as AugMix and DeepAug.
Scanning phase imaging without accurate positioning system
Oct 31, 2023Ptychography, a high-resolution phase imaging technique using precise in-plane translation information, has been widely applied in modern synchrotron radiation sources across the globe. A key requirement for successful ptychographic reconstruction is the precise knowledge of the scanning positions, which are typically obtained by a physical interferometric positioning system. Whereas high-throughput positioning poses a challenge in engineering, especially in nano or even smaller scale. In this work, we propose a novel scanning imaging framework that does not require any prior position information from the positioning system. Specifically, our scheme utilizes the wavefront modulation mechanism to reconstruct the object functions at each scan position and the shared illumination function, simultaneously. The scanning trajectory information is extracted by our subpixel image registration algorithm from the overlap region of reconstructed object functions. Then, a completed object function can be obtained by assembling each part of the reconstructed sample functions. High-quality imaging of biological sample and position recovery with sub-pixel accuracy are demonstrated in proof-of-concept experiment. Based on current results, we find it may have great potential applications in high-resolution and high throughput phase imaging.
Lookup Table meets Local Laplacian Filter: Pyramid Reconstruction Network for Tone Mapping
Oct 26, 2023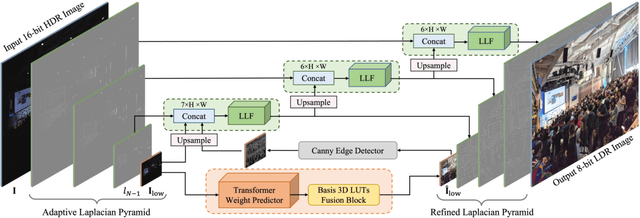
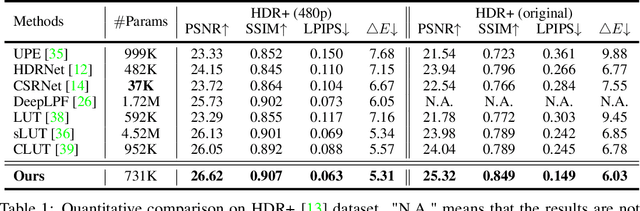
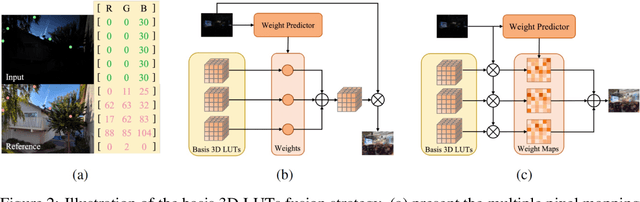
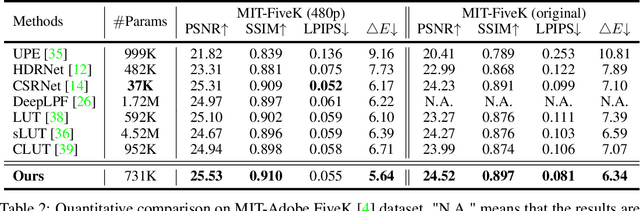
Tone mapping aims to convert high dynamic range (HDR) images to low dynamic range (LDR) representations, a critical task in the camera imaging pipeline. In recent years, 3-Dimensional LookUp Table (3D LUT) based methods have gained attention due to their ability to strike a favorable balance between enhancement performance and computational efficiency. However, these methods often fail to deliver satisfactory results in local areas since the look-up table is a global operator for tone mapping, which works based on pixel values and fails to incorporate crucial local information. To this end, this paper aims to address this issue by exploring a novel strategy that integrates global and local operators by utilizing closed-form Laplacian pyramid decomposition and reconstruction. Specifically, we employ image-adaptive 3D LUTs to manipulate the tone in the low-frequency image by leveraging the specific characteristics of the frequency information. Furthermore, we utilize local Laplacian filters to refine the edge details in the high-frequency components in an adaptive manner. Local Laplacian filters are widely used to preserve edge details in photographs, but their conventional usage involves manual tuning and fixed implementation within camera imaging pipelines or photo editing tools. We propose to learn parameter value maps progressively for local Laplacian filters from annotated data using a lightweight network. Our model achieves simultaneous global tone manipulation and local edge detail preservation in an end-to-end manner. Extensive experimental results on two benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art methods.
From LAION-5B to LAION-EO: Filtering Billions of Images Using Anchor Datasets for Satellite Image Extraction
Sep 27, 2023Large datasets, such as LAION-5B, contain a diverse distribution of images shared online. However, extraction of domain-specific subsets of large image corpora is challenging. The extraction approach based on an anchor dataset, combined with further filtering, is proposed here and demonstrated for the domain of satellite imagery. This results in the release of LAION-EO, a dataset sourced from the web containing pairs of text and satellite images in high (pixel-wise) resolution. The paper outlines the acquisition procedure as well as some of the features of the dataset.
SAMPLING: Scene-adaptive Hierarchical Multiplane Images Representation for Novel View Synthesis from a Single Image
Sep 13, 2023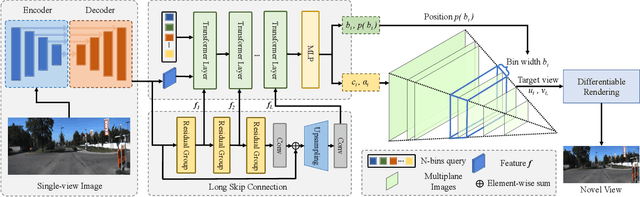
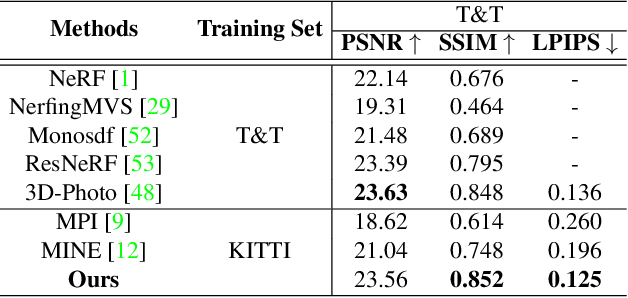
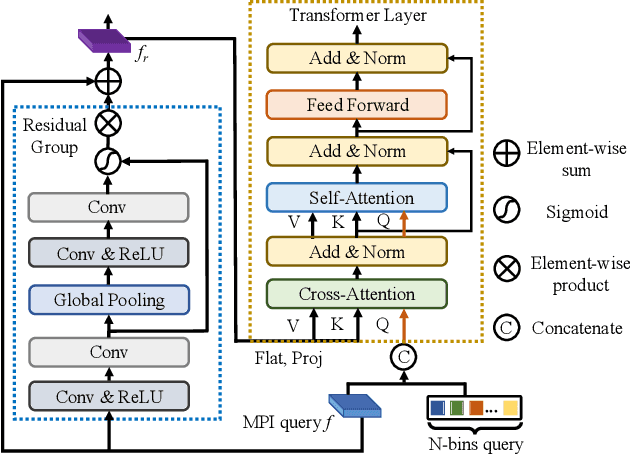
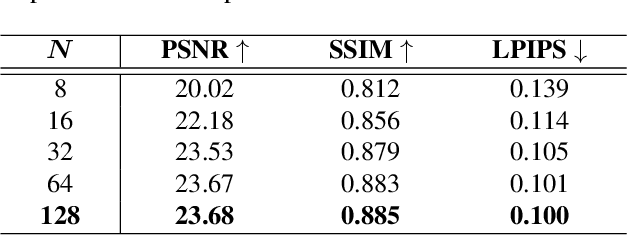
Recent novel view synthesis methods obtain promising results for relatively small scenes, e.g., indoor environments and scenes with a few objects, but tend to fail for unbounded outdoor scenes with a single image as input. In this paper, we introduce SAMPLING, a Scene-adaptive Hierarchical Multiplane Images Representation for Novel View Synthesis from a Single Image based on improved multiplane images (MPI). Observing that depth distribution varies significantly for unbounded outdoor scenes, we employ an adaptive-bins strategy for MPI to arrange planes in accordance with each scene image. To represent intricate geometry and multi-scale details, we further introduce a hierarchical refinement branch, which results in high-quality synthesized novel views. Our method demonstrates considerable performance gains in synthesizing large-scale unbounded outdoor scenes using a single image on the KITTI dataset and generalizes well to the unseen Tanks and Temples dataset.The code and models will soon be made available.
Learning In-between Imagery Dynamics via Physical Latent Spaces
Oct 14, 2023
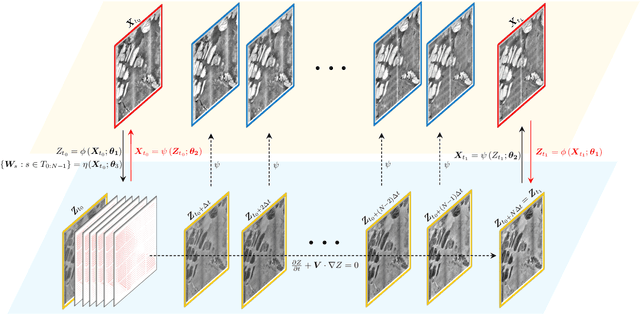

We present a framework designed to learn the underlying dynamics between two images observed at consecutive time steps. The complex nature of image data and the lack of temporal information pose significant challenges in capturing the unique evolving patterns. Our proposed method focuses on estimating the intermediary stages of image evolution, allowing for interpretability through latent dynamics while preserving spatial correlations with the image. By incorporating a latent variable that follows a physical model expressed in partial differential equations (PDEs), our approach ensures the interpretability of the learned model and provides insight into corresponding image dynamics. We demonstrate the robustness and effectiveness of our learning framework through a series of numerical tests using geoscientific imagery data.
AdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
GUPNet++: Geometry Uncertainty Propagation Network for Monocular 3D Object Detection
Oct 24, 2023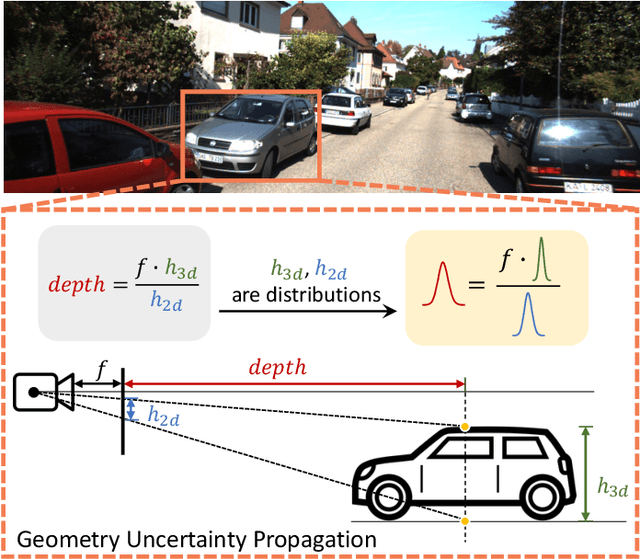
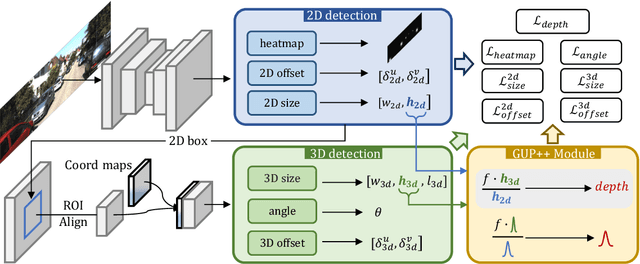
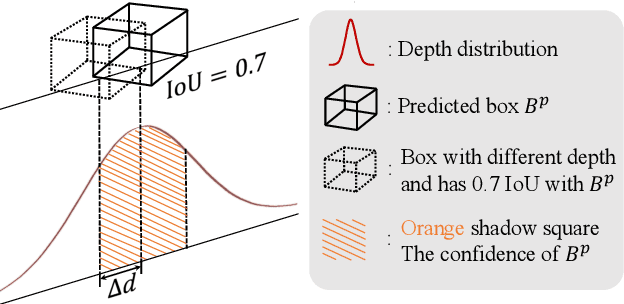
Geometry plays a significant role in monocular 3D object detection. It can be used to estimate object depth by using the perspective projection between object's physical size and 2D projection in the image plane, which can introduce mathematical priors into deep models. However, this projection process also introduces error amplification, where the error of the estimated height is amplified and reflected into the projected depth. It leads to unreliable depth inferences and also impairs training stability. To tackle this problem, we propose a novel Geometry Uncertainty Propagation Network (GUPNet++) by modeling geometry projection in a probabilistic manner. This ensures depth predictions are well-bounded and associated with a reasonable uncertainty. The significance of introducing such geometric uncertainty is two-fold: (1). It models the uncertainty propagation relationship of the geometry projection during training, improving the stability and efficiency of the end-to-end model learning. (2). It can be derived to a highly reliable confidence to indicate the quality of the 3D detection result, enabling more reliable detection inference. Experiments show that the proposed approach not only obtains (state-of-the-art) SOTA performance in image-based monocular 3D detection but also demonstrates superiority in efficacy with a simplified framework.
DeformUX-Net: Exploring a 3D Foundation Backbone for Medical Image Segmentation with Depthwise Deformable Convolution
Oct 04, 2023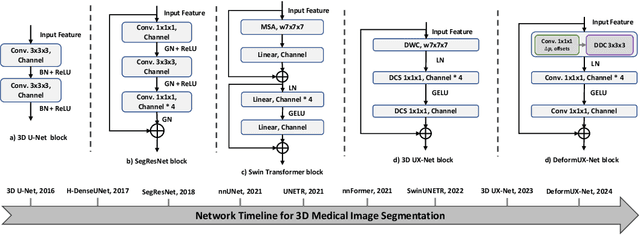
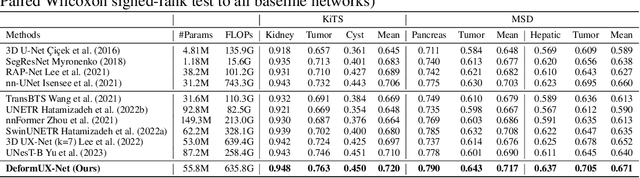
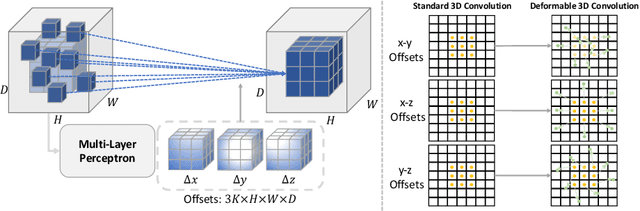
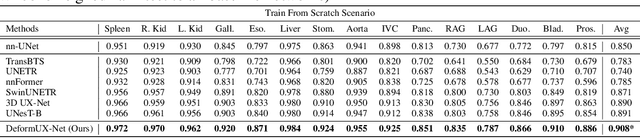
The application of 3D ViTs to medical image segmentation has seen remarkable strides, somewhat overshadowing the budding advancements in Convolutional Neural Network (CNN)-based models. Large kernel depthwise convolution has emerged as a promising technique, showcasing capabilities akin to hierarchical transformers and facilitating an expansive effective receptive field (ERF) vital for dense predictions. Despite this, existing core operators, ranging from global-local attention to large kernel convolution, exhibit inherent trade-offs and limitations (e.g., global-local range trade-off, aggregating attentional features). We hypothesize that deformable convolution can be an exploratory alternative to combine all advantages from the previous operators, providing long-range dependency, adaptive spatial aggregation and computational efficiency as a foundation backbone. In this work, we introduce 3D DeformUX-Net, a pioneering volumetric CNN model that adeptly navigates the shortcomings traditionally associated with ViTs and large kernel convolution. Specifically, we revisit volumetric deformable convolution in depth-wise setting to adapt long-range dependency with computational efficiency. Inspired by the concepts of structural re-parameterization for convolution kernel weights, we further generate the deformable tri-planar offsets by adapting a parallel branch (starting from $1\times1\times1$ convolution), providing adaptive spatial aggregation across all channels. Our empirical evaluations reveal that the 3D DeformUX-Net consistently outperforms existing state-of-the-art ViTs and large kernel convolution models across four challenging public datasets, spanning various scales from organs (KiTS: 0.680 to 0.720, MSD Pancreas: 0.676 to 0.717, AMOS: 0.871 to 0.902) to vessels (e.g., MSD hepatic vessels: 0.635 to 0.671) in mean Dice.