 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TiC-CLIP: Continual Training of CLIP Models
Oct 24, 2023
Keeping large foundation models up to date on latest data is inherently expensive. To avoid the prohibitive costs of constantly retraining, it is imperative to continually train these models. This problem is exacerbated by the lack of any large scale continual learning benchmarks or baselines. We introduce the first set of web-scale Time-Continual (TiC) benchmarks for training vision-language models: TiC-DataCompt, TiC-YFCC, and TiC-RedCaps with over 12.7B timestamped image-text pairs spanning 9 years (2014--2022). We first use our benchmarks to curate various dynamic evaluations to measure temporal robustness of existing models. We show OpenAI's CLIP (trained on data up to 2020) loses $\approx 8\%$ zero-shot accuracy on our curated retrieval task from 2021--2022 compared with more recently trained models in OpenCLIP repository. We then study how to efficiently train models on time-continuous data. We demonstrate that a simple rehearsal-based approach that continues training from the last checkpoint and replays old data reduces compute by $2.5\times$ when compared to the standard practice of retraining from scratch.
Research on Image Stitching Based on Invariant Features of Reconstructed Plane
Aug 30, 2023



Generating high-quality stitched images is a challenging task in computer vision. The existing feature-based image stitching methods commonly only focus on point and line features, neglecting the crucial role of higher-level planar features in image stitching. This paper proposes an image stitching method based on invariant planar features, which uses planar features as constraints to improve the overall effect of natural image stitching. Initially, our approach expands the quantity of matched feature points and lines through straight-line procedures, advancing alignment quality and reducing artifacts in overlapping areas. Then, uncertain planes are described by known matching points and matching lines, and plane features are introduced to preserve energy items, which improves the overall appearance of stitched images while reducing distortion and guarantees a more natural stitched image. Furthermore, to demonstrate the superiority of our approach, we also propose several evaluation indexes related to planar features to quantify the detailed changes of planar features. An extensive set of experiments validates the effectiveness of our approach in stitching natural images with a larger field of view. Compared with the most advanced methods, our method retains the texture and structure of the image better, and produces less unnatural distortion. Multiple quantitative evaluations illustrate that our approach outperforms existing methods with significant improvements, further validating the effectiveness and superiority of our proposed method.
DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
Oct 26, 2023We present DreamCraft3D, a hierarchical 3D content generation method that produces high-fidelity and coherent 3D objects. We tackle the problem by leveraging a 2D reference image to guide the stages of geometry sculpting and texture boosting. A central focus of this work is to address the consistency issue that existing works encounter. To sculpt geometries that render coherently, we perform score distillation sampling via a view-dependent diffusion model. This 3D prior, alongside several training strategies, prioritizes the geometry consistency but compromises the texture fidelity. We further propose Bootstrapped Score Distillation to specifically boost the texture. We train a personalized diffusion model, Dreambooth, on the augmented renderings of the scene, imbuing it with 3D knowledge of the scene being optimized. The score distillation from this 3D-aware diffusion prior provides view-consistent guidance for the scene. Notably, through an alternating optimization of the diffusion prior and 3D scene representation, we achieve mutually reinforcing improvements: the optimized 3D scene aids in training the scene-specific diffusion model, which offers increasingly view-consistent guidance for 3D optimization. The optimization is thus bootstrapped and leads to substantial texture boosting. With tailored 3D priors throughout the hierarchical generation, DreamCraft3D generates coherent 3D objects with photorealistic renderings, advancing the state-of-the-art in 3D content generation. Code available at https://github.com/deepseek-ai/DreamCraft3D.
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023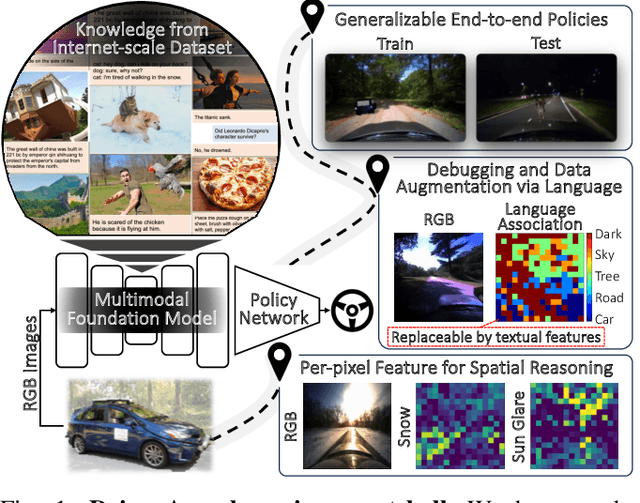
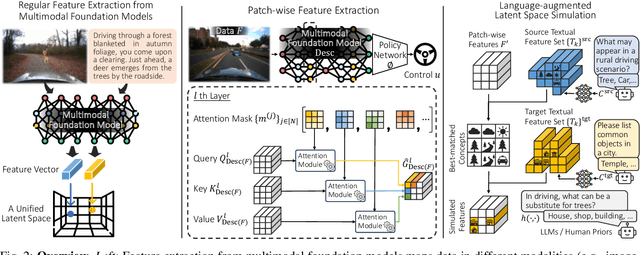
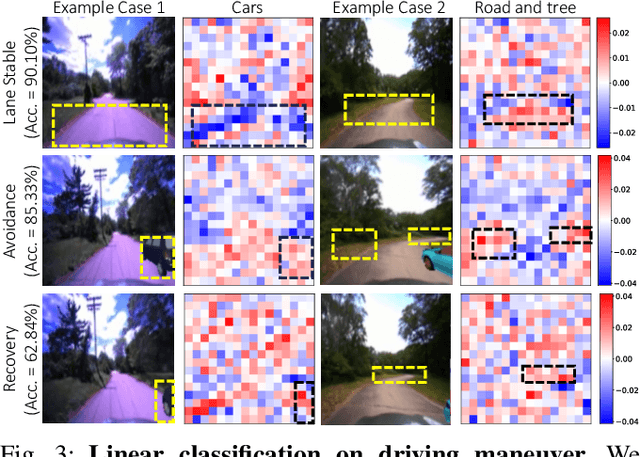
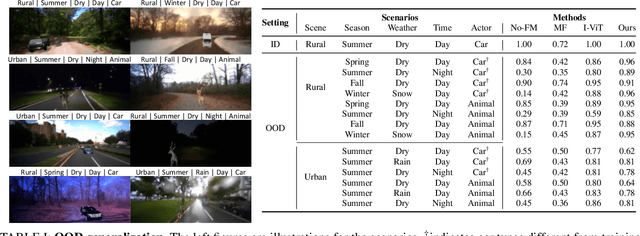
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
Human Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.
Weakly Supervised Learning for Breast Cancer Prediction on Mammograms in Realistic Settings
Oct 19, 2023Automatic methods for early detection of breast cancer on mammography can significantly decrease mortality. Broad uptake of those methods in hospitals is currently hindered because the methods have too many constraints. They assume annotations available for single images or even regions-of-interest (ROIs), and a fixed number of images per patient. Both assumptions do not hold in a general hospital setting. Relaxing those assumptions results in a weakly supervised learning setting, where labels are available per case, but not for individual images or ROIs. Not all images taken for a patient contain malignant regions and the malignant ROIs cover only a tiny part of an image, whereas most image regions represent benign tissue. In this work, we investigate a two-level multi-instance learning (MIL) approach for case-level breast cancer prediction on two public datasets (1.6k and 5k cases) and an in-house dataset of 21k cases. Observing that breast cancer is usually only present in one side, while images of both breasts are taken as a precaution, we propose a domain-specific MIL pooling variant. We show that two-level MIL can be applied in realistic clinical settings where only case labels, and a variable number of images per patient are available. Data in realistic settings scales with continuous patient intake, while manual annotation efforts do not. Hence, research should focus in particular on unsupervised ROI extraction, in order to improve breast cancer prediction for all patients.
Few-Shot Medical Image Segmentation via a Region-enhanced Prototypical Transformer
Sep 09, 2023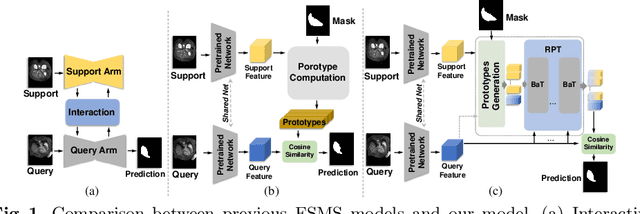
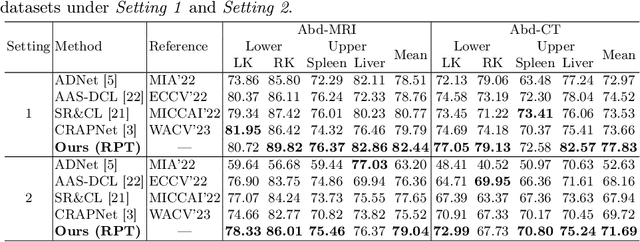

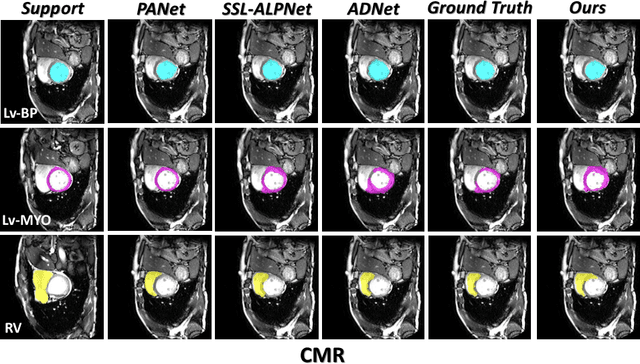
Automated segmentation of large volumes of medical images is often plagued by the limited availability of fully annotated data and the diversity of organ surface properties resulting from the use of different acquisition protocols for different patients. In this paper, we introduce a more promising few-shot learning-based method named Region-enhanced Prototypical Transformer (RPT) to mitigate the effects of large intra-class diversity/bias. First, a subdivision strategy is introduced to produce a collection of regional prototypes from the foreground of the support prototype. Second, a self-selection mechanism is proposed to incorporate into the Bias-alleviated Transformer (BaT) block to suppress or remove interferences present in the query prototype and regional support prototypes. By stacking BaT blocks, the proposed RPT can iteratively optimize the generated regional prototypes and finally produce rectified and more accurate global prototypes for Few-Shot Medical Image Segmentation (FSMS). Extensive experiments are conducted on three publicly available medical image datasets, and the obtained results show consistent improvements compared to state-of-the-art FSMS methods. The source code is available at: https://github.com/YazhouZhu19/RPT.
3D Structure-guided Network for Tooth Alignment in 2D Photograph
Oct 17, 2023Orthodontics focuses on rectifying misaligned teeth (i.e., malocclusions), affecting both masticatory function and aesthetics. However, orthodontic treatment often involves complex, lengthy procedures. As such, generating a 2D photograph depicting aligned teeth prior to orthodontic treatment is crucial for effective dentist-patient communication and, more importantly, for encouraging patients to accept orthodontic intervention. In this paper, we propose a 3D structure-guided tooth alignment network that takes 2D photographs as input (e.g., photos captured by smartphones) and aligns the teeth within the 2D image space to generate an orthodontic comparison photograph featuring aesthetically pleasing, aligned teeth. Notably, while the process operates within a 2D image space, our method employs 3D intra-oral scanning models collected in clinics to learn about orthodontic treatment, i.e., projecting the pre- and post-orthodontic 3D tooth structures onto 2D tooth contours, followed by a diffusion model to learn the mapping relationship. Ultimately, the aligned tooth contours are leveraged to guide the generation of a 2D photograph with aesthetically pleasing, aligned teeth and realistic textures. We evaluate our network on various facial photographs, demonstrating its exceptional performance and strong applicability within the orthodontic industry.
Whole-brain radiomics for clustered federated personalization in brain tumor segmentation
Oct 17, 2023Federated learning and its application to medical image segmentation have recently become a popular research topic. This training paradigm suffers from statistical heterogeneity between participating institutions' local datasets, incurring convergence slowdown as well as potential accuracy loss compared to classical training. To mitigate this effect, federated personalization emerged as the federated optimization of one model per institution. We propose a novel personalization algorithm tailored to the feature shift induced by the usage of different scanners and acquisition parameters by different institutions. This method is the first to account for both inter and intra-institution feature shift (multiple scanners used in a single institution). It is based on the computation, within each centre, of a series of radiomic features capturing the global texture of each 3D image volume, followed by a clustering analysis pooling all feature vectors transferred from the local institutions to the central server. Each computed clustered decentralized dataset (potentially including data from different institutions) then serves to finetune a global model obtained through classical federated learning. We validate our approach on the Federated Brain Tumor Segmentation 2022 Challenge dataset (FeTS2022). Our code is available at (https://github.com/MatthisManthe/radiomics_CFFL).
Memory augment is All You Need for image restoration
Sep 04, 2023
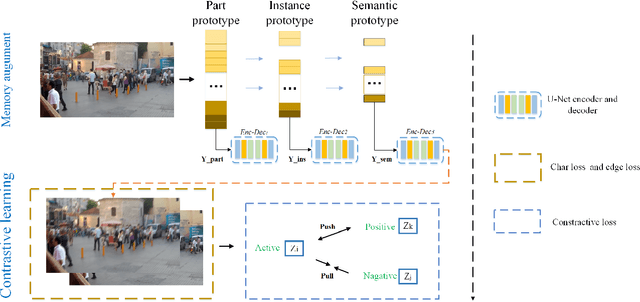
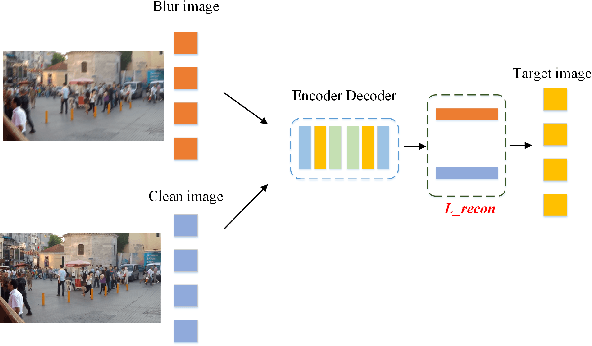

Image restoration is a low-level vision task, most CNN methods are designed as a black box, lacking transparency and internal aesthetics. Although some methods combining traditional optimization algorithms with DNNs have been proposed, they all have some limitations. In this paper, we propose a three-granularity memory layer and contrast learning named MemoryNet, specifically, dividing the samples into positive, negative, and actual three samples for contrastive learning, where the memory layer is able to preserve the deep features of the image and the contrastive learning converges the learned features to balance. Experiments on Derain/Deshadow/Deblur task demonstrate that these methods are effective in improving restoration performance. In addition, this paper's model obtains significant PSNR, SSIM gain on three datasets with different degradation types, which is a strong proof that the recovered images are perceptually realistic. The source code of MemoryNet can be obtained from https://github.com/zhangbaijin/MemoryNet