 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Representations for Teacher-Guided Compositional Visual Reasoning
Oct 24, 2023
Neural Module Networks (NMN) are a compelling method for visual question answering, enabling the translation of a question into a program consisting of a series of reasoning sub-tasks that are sequentially executed on the image to produce an answer. NMNs provide enhanced explainability compared to integrated models, allowing for a better understanding of the underlying reasoning process. To improve the effectiveness of NMNs we propose to exploit features obtained by a large-scale cross-modal encoder. Also, the current training approach of NMNs relies on the propagation of module outputs to subsequent modules, leading to the accumulation of prediction errors and the generation of false answers. To mitigate this, we introduce an NMN learning strategy involving scheduled teacher guidance. Initially, the model is fully guided by the ground-truth intermediate outputs, but gradually transitions to an autonomous behavior as training progresses. This reduces error accumulation, thus improving training efficiency and final performance.We demonstrate that by incorporating cross-modal features and employing more effective training techniques for NMN, we achieve a favorable balance between performance and transparency in the reasoning process.
Unpaired MRI Super Resolution with Self-Supervised Contrastive Learning
Oct 24, 2023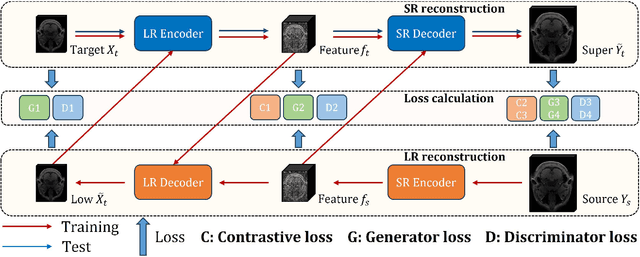
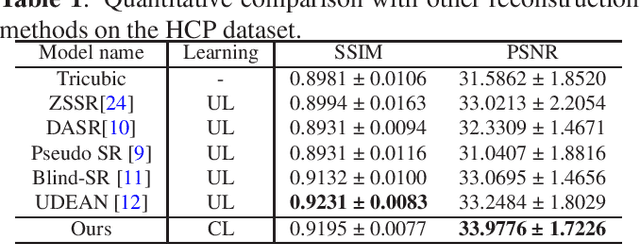
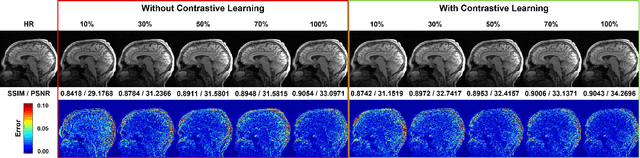
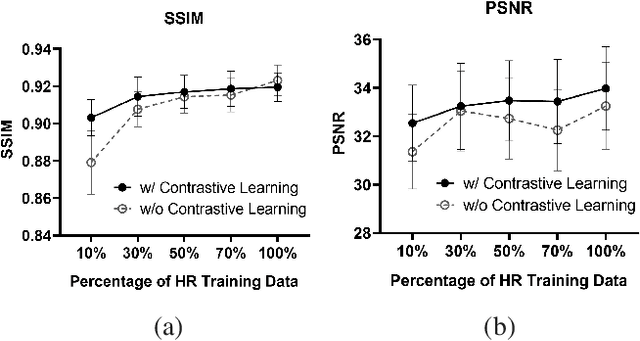
High-resolution (HR) magnetic resonance imaging (MRI) is crucial for enhancing diagnostic accuracy in clinical settings. Nonetheless, the inherent limitation of MRI resolution restricts its widespread applicability. Deep learning-based image super-resolution (SR) methods exhibit promise in improving MRI resolution without additional cost. However, these methods frequently require a substantial number of HR MRI images for training, which can be challenging to acquire. In this paper, we propose an unpaired MRI SR approach that employs self-supervised contrastive learning to enhance SR performance with limited training data. Our approach leverages both authentic HR images and synthetically generated SR images to construct positive and negative sample pairs, thus facilitating the learning of discriminative features. Empirical results presented in this study underscore significant enhancements in the peak signal-to-noise ratio and structural similarity index, even when a paucity of HR images is available. These findings accentuate the potential of our approach in addressing the challenge of limited training data, thereby contributing to the advancement of high-resolution MRI in clinical applications.
DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
Oct 26, 2023We present DreamCraft3D, a hierarchical 3D content generation method that produces high-fidelity and coherent 3D objects. We tackle the problem by leveraging a 2D reference image to guide the stages of geometry sculpting and texture boosting. A central focus of this work is to address the consistency issue that existing works encounter. To sculpt geometries that render coherently, we perform score distillation sampling via a view-dependent diffusion model. This 3D prior, alongside several training strategies, prioritizes the geometry consistency but compromises the texture fidelity. We further propose Bootstrapped Score Distillation to specifically boost the texture. We train a personalized diffusion model, Dreambooth, on the augmented renderings of the scene, imbuing it with 3D knowledge of the scene being optimized. The score distillation from this 3D-aware diffusion prior provides view-consistent guidance for the scene. Notably, through an alternating optimization of the diffusion prior and 3D scene representation, we achieve mutually reinforcing improvements: the optimized 3D scene aids in training the scene-specific diffusion model, which offers increasingly view-consistent guidance for 3D optimization. The optimization is thus bootstrapped and leads to substantial texture boosting. With tailored 3D priors throughout the hierarchical generation, DreamCraft3D generates coherent 3D objects with photorealistic renderings, advancing the state-of-the-art in 3D content generation. Code available at https://github.com/deepseek-ai/DreamCraft3D.
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023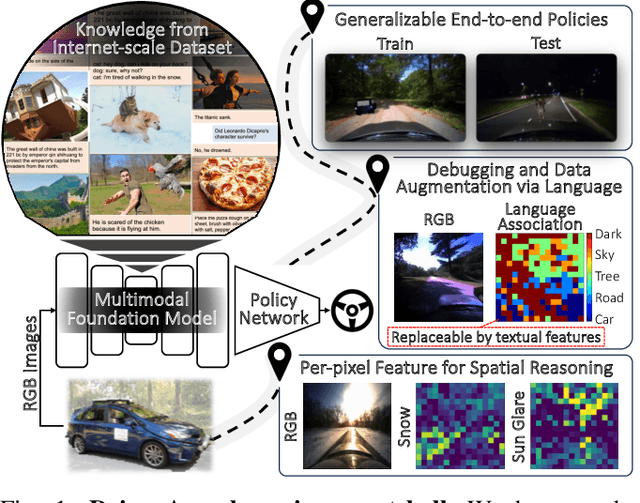
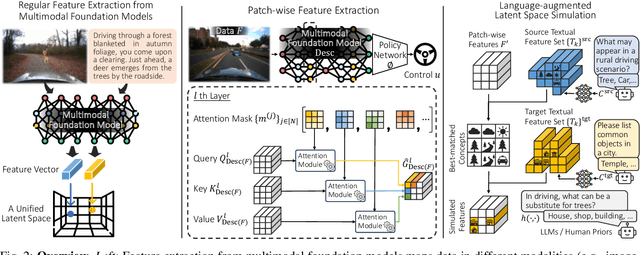
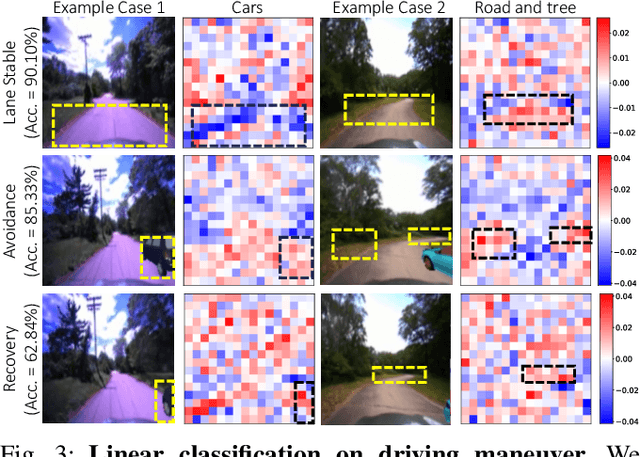
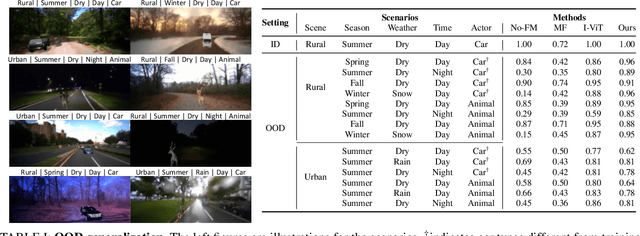
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
Generation and Recombination for Multifocus Image Fusion with Free Number of Inputs
Sep 09, 2023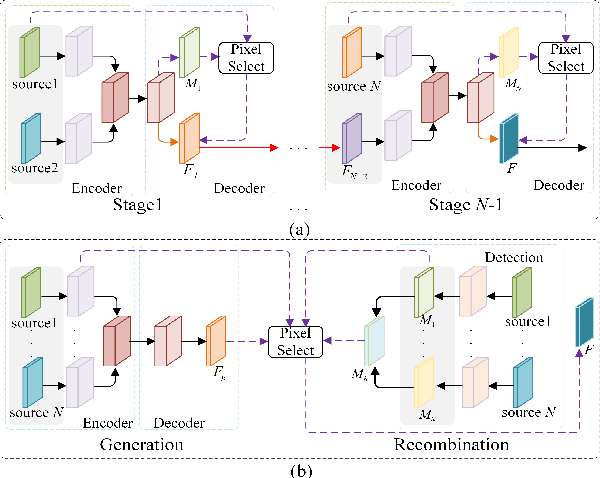



Multifocus image fusion is an effective way to overcome the limitation of optical lenses. Many existing methods obtain fused results by generating decision maps. However, such methods often assume that the focused areas of the two source images are complementary, making it impossible to achieve simultaneous fusion of multiple images. Additionally, the existing methods ignore the impact of hard pixels on fusion performance, limiting the visual quality improvement of fusion image. To address these issues, a combining generation and recombination model, termed as GRFusion, is proposed. In GRFusion, focus property detection of each source image can be implemented independently, enabling simultaneous fusion of multiple source images and avoiding information loss caused by alternating fusion. This makes GRFusion free from the number of inputs. To distinguish the hard pixels from the source images, we achieve the determination of hard pixels by considering the inconsistency among the detection results of focus areas in source images. Furthermore, a multi-directional gradient embedding method for generating full focus images is proposed. Subsequently, a hard-pixel-guided recombination mechanism for constructing fused result is devised, effectively integrating the complementary advantages of feature reconstruction-based method and focused pixel recombination-based method. Extensive experimental results demonstrate the effectiveness and the superiority of the proposed method.The source code will be released on https://github.com/xxx/xxx.
New Advances in Body Composition Assessment with ShapedNet: A Single Image Deep Regression Approach
Oct 15, 2023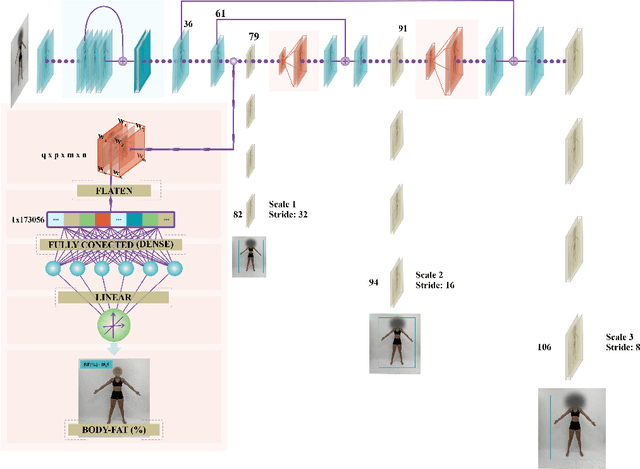
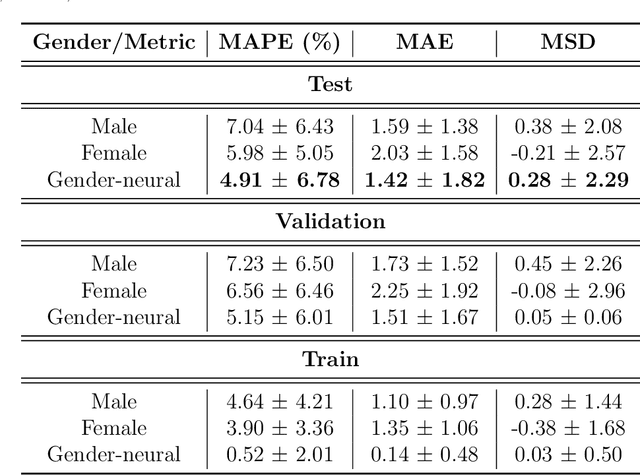
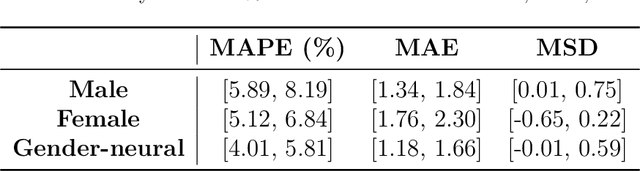
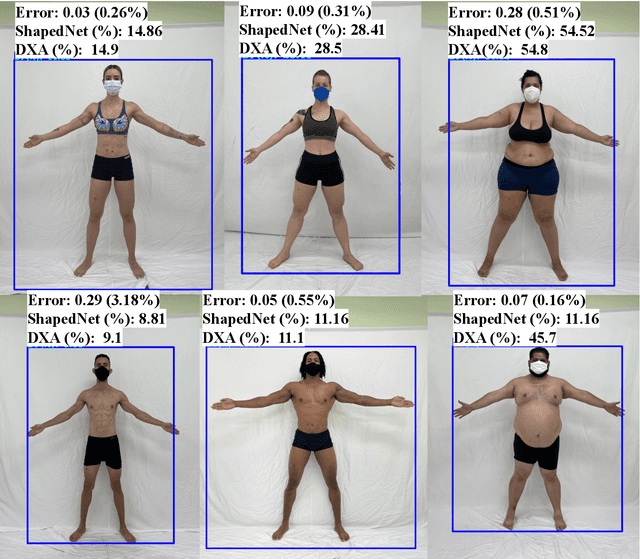
We introduce a novel technique called ShapedNet to enhance body composition assessment. This method employs a deep neural network capable of estimating Body Fat Percentage (BFP), performing individual identification, and enabling localization using a single photograph. The accuracy of ShapedNet is validated through comprehensive comparisons against the gold standard method, Dual-Energy X-ray Absorptiometry (DXA), utilizing 1273 healthy adults spanning various ages, sexes, and BFP levels. The results demonstrate that ShapedNet outperforms in 19.5% state of the art computer vision-based approaches for body fat estimation, achieving a Mean Absolute Percentage Error (MAPE) of 4.91% and Mean Absolute Error (MAE) of 1.42. The study evaluates both gender-based and Gender-neutral approaches, with the latter showcasing superior performance. The method estimates BFP with 95% confidence within an error margin of 4.01% to 5.81%. This research advances multi-task learning and body composition assessment theory through ShapedNet.
DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
Sep 22, 2023
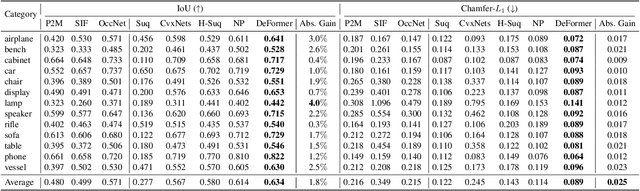
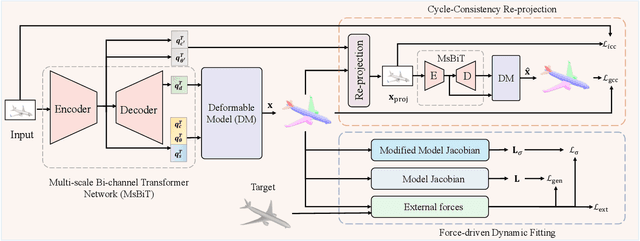
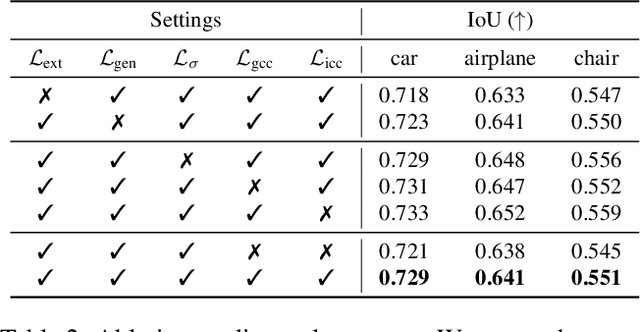
Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
Semi-Supervised Panoptic Narrative Grounding
Oct 27, 2023Despite considerable progress, the advancement of Panoptic Narrative Grounding (PNG) remains hindered by costly annotations. In this paper, we introduce a novel Semi-Supervised Panoptic Narrative Grounding (SS-PNG) learning scheme, capitalizing on a smaller set of labeled image-text pairs and a larger set of unlabeled pairs to achieve competitive performance. Unlike visual segmentation tasks, PNG involves one pixel belonging to multiple open-ended nouns. As a result, existing multi-class based semi-supervised segmentation frameworks cannot be directly applied to this task. To address this challenge, we first develop a novel SS-PNG Network (SS-PNG-NW) tailored to the SS-PNG setting. We thoroughly investigate strategies such as Burn-In and data augmentation to determine the optimal generic configuration for the SS-PNG-NW. Additionally, to tackle the issue of imbalanced pseudo-label quality, we propose a Quality-Based Loss Adjustment (QLA) approach to adjust the semi-supervised objective, resulting in an enhanced SS-PNG-NW+. Employing our proposed QLA, we improve BCE Loss and Dice loss at pixel and mask levels, respectively. We conduct extensive experiments on PNG datasets, with our SS-PNG-NW+ demonstrating promising results comparable to fully-supervised models across all data ratios. Remarkably, our SS-PNG-NW+ outperforms fully-supervised models with only 30% and 50% supervision data, exceeding their performance by 0.8% and 1.1% respectively. This highlights the effectiveness of our proposed SS-PNG-NW+ in overcoming the challenges posed by limited annotations and enhancing the applicability of PNG tasks. The source code is available at https://github.com/nini0919/SSPNG.
ViTs are Everywhere: A Comprehensive Study Showcasing Vision Transformers in Different Domain
Oct 13, 2023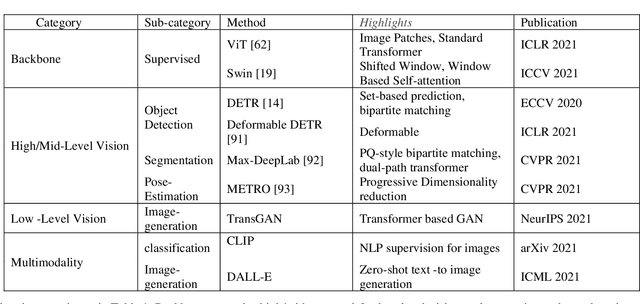
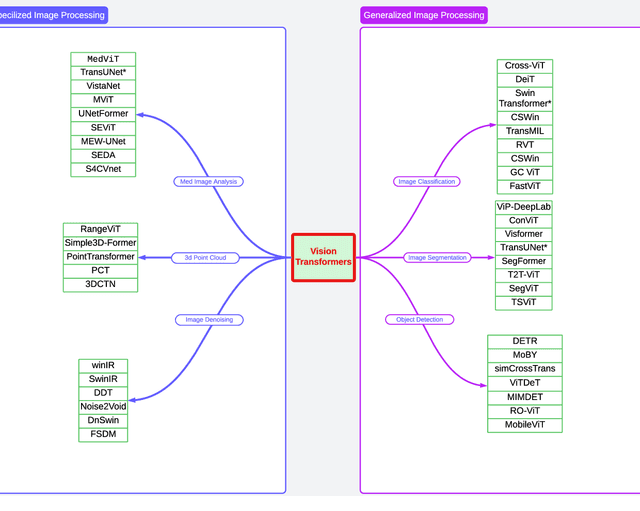
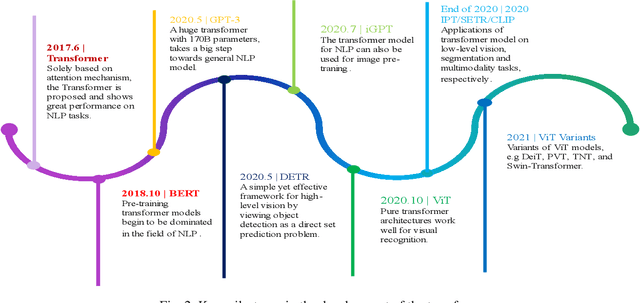
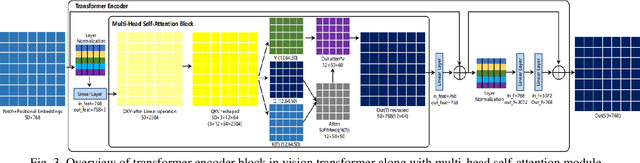
Transformer design is the de facto standard for natural language processing tasks. The success of the transformer design in natural language processing has lately piqued the interest of researchers in the domain of computer vision. When compared to Convolutional Neural Networks (CNNs), Vision Transformers (ViTs) are becoming more popular and dominant solutions for many vision problems. Transformer-based models outperform other types of networks, such as convolutional and recurrent neural networks, in a range of visual benchmarks. We evaluate various vision transformer models in this work by dividing them into distinct jobs and examining their benefits and drawbacks. ViTs can overcome several possible difficulties with convolutional neural networks (CNNs). The goal of this survey is to show the first use of ViTs in CV. In the first phase, we categorize various CV applications where ViTs are appropriate. Image classification, object identification, image segmentation, video transformer, image denoising, and NAS are all CV applications. Our next step will be to analyze the state-of-the-art in each area and identify the models that are currently available. In addition, we outline numerous open research difficulties as well as prospective research possibilities.
ADASR: An Adversarial Auto-Augmentation Framework for Hyperspectral and Multispectral Data Fusion
Oct 11, 2023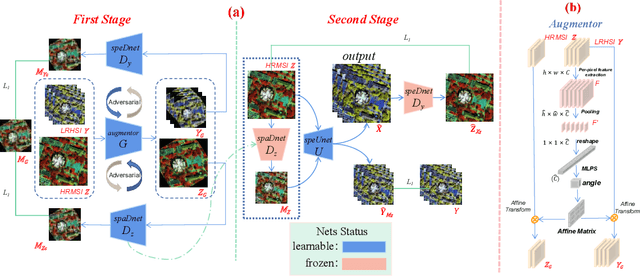
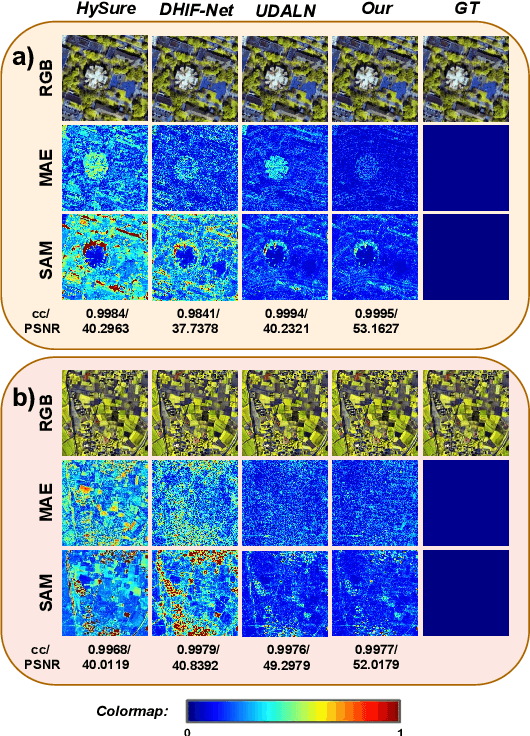
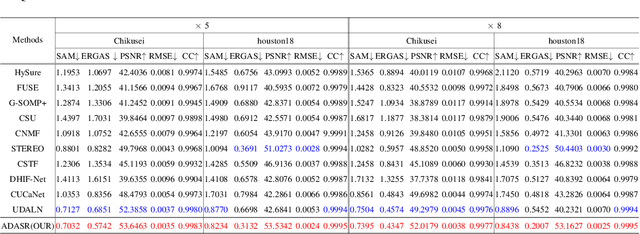
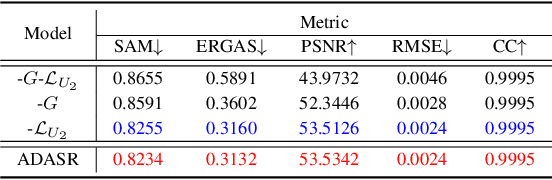
Deep learning-based hyperspectral image (HSI) super-resolution, which aims to generate high spatial resolution HSI (HR-HSI) by fusing hyperspectral image (HSI) and multispectral image (MSI) with deep neural networks (DNNs), has attracted lots of attention. However, neural networks require large amounts of training data, hindering their application in real-world scenarios. In this letter, we propose a novel adversarial automatic data augmentation framework ADASR that automatically optimizes and augments HSI-MSI sample pairs to enrich data diversity for HSI-MSI fusion. Our framework is sample-aware and optimizes an augmentor network and two downsampling networks jointly by adversarial learning so that we can learn more robust downsampling networks for training the upsampling network. Extensive experiments on two public classical hyperspectral datasets demonstrate the effectiveness of our ADASR compared to the state-of-the-art methods.