 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Similar Data Points Identification with LLM: A Human-in-the-loop Strategy Using Summarization and Hidden State Insights
Apr 03, 2024
This study introduces a simple yet effective method for identifying similar data points across non-free text domains, such as tabular and image data, using Large Language Models (LLMs). Our two-step approach involves data point summarization and hidden state extraction. Initially, data is condensed via summarization using an LLM, reducing complexity and highlighting essential information in sentences. Subsequently, the summarization sentences are fed through another LLM to extract hidden states, serving as compact, feature-rich representations. This approach leverages the advanced comprehension and generative capabilities of LLMs, offering a scalable and efficient strategy for similarity identification across diverse datasets. We demonstrate the effectiveness of our method in identifying similar data points on multiple datasets. Additionally, our approach enables non-technical domain experts, such as fraud investigators or marketing operators, to quickly identify similar data points tailored to specific scenarios, demonstrating its utility in practical applications. In general, our results open new avenues for leveraging LLMs in data analysis across various domains.
Optical Text Recognition in Nepali and Bengali: A Transformer-based Approach
Apr 03, 2024Efforts on the research and development of OCR systems for Low-Resource Languages are relatively new. Low-resource languages have little training data available for training Machine Translation systems or other systems. Even though a vast amount of text has been digitized and made available on the internet the text is still in PDF and Image format, which are not instantly accessible. This paper discusses text recognition for two scripts: Bengali and Nepali; there are about 300 and 40 million Bengali and Nepali speakers respectively. In this study, using encoder-decoder transformers, a model was developed, and its efficacy was assessed using a collection of optical text images, both handwritten and printed. The results signify that the suggested technique corresponds with current approaches and achieves high precision in recognizing text in Bengali and Nepali. This study can pave the way for the advanced and accessible study of linguistics in South East Asia.
BCAmirs at SemEval-2024 Task 4: Beyond Words: A Multimodal and Multilingual Exploration of Persuasion in Memes
Apr 03, 2024Memes, combining text and images, frequently use metaphors to convey persuasive messages, shaping public opinion. Motivated by this, our team engaged in SemEval-2024 Task 4, a hierarchical multi-label classification task designed to identify rhetorical and psychological persuasion techniques embedded within memes. To tackle this problem, we introduced a caption generation step to assess the modality gap and the impact of additional semantic information from images, which improved our result. Our best model utilizes GPT-4 generated captions alongside meme text to fine-tune RoBERTa as the text encoder and CLIP as the image encoder. It outperforms the baseline by a large margin in all 12 subtasks. In particular, it ranked in top-3 across all languages in Subtask 2a, and top-4 in Subtask 2b, demonstrating quantitatively strong performance. The improvement achieved by the introduced intermediate step is likely attributable to the metaphorical essence of images that challenges visual encoders. This highlights the potential for improving abstract visual semantics encoding.
MatAtlas: Text-driven Consistent Geometry Texturing and Material Assignment
Apr 03, 2024We present MatAtlas, a method for consistent text-guided 3D model texturing. Following recent progress we leverage a large scale text-to-image generation model (e.g., Stable Diffusion) as a prior to texture a 3D model. We carefully design an RGB texturing pipeline that leverages a grid pattern diffusion, driven by depth and edges. By proposing a multi-step texture refinement process, we significantly improve the quality and 3D consistency of the texturing output. To further address the problem of baked-in lighting, we move beyond RGB colors and pursue assigning parametric materials to the assets. Given the high-quality initial RGB texture, we propose a novel material retrieval method capitalized on Large Language Models (LLM), enabling editabiliy and relightability. We evaluate our method on a wide variety of geometries and show that our method significantly outperform prior arts. We also analyze the role of each component through a detailed ablation study.
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
Apr 03, 2024Recent progress in visual generative models enables the generation of high-quality images. To prevent the misuse of generated images, it is important to identify the origin model that generates them. In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed. The goal is to check if a given image is generated by the source model. We first formulate this problem as a few-shot one-class classification task. To solve the task, we propose OCC-CLIP, a CLIP-based framework for few-shot one-class classification, enabling the identification of an image's source model, even among multiple candidates. Extensive experiments corresponding to various generative models verify the effectiveness of our OCC-CLIP framework. Furthermore, an experiment based on the recently released DALL-E 3 API verifies the real-world applicability of our solution.
A Recommender System for NFT Collectibles with Item Feature
Apr 03, 2024Recommender systems have been actively studied and applied in various domains to deal with information overload. Although there are numerous studies on recommender systems for movies, music, and e-commerce, comparatively less attention has been paid to the recommender system for NFTs despite the continuous growth of the NFT market. This paper presents a recommender system for NFTs that utilizes a variety of data sources, from NFT transaction records to external item features, to generate precise recommendations that cater to individual preferences. We develop a data-efficient graph-based recommender system to efficiently capture the complex relationship between each item and users and generate node(item) embeddings which incorporate both node feature information and graph structure. Furthermore, we exploit inputs beyond user-item interactions, such as image feature, text feature, and price feature. Numerical experiments verify the performance of the graph-based recommender system improves significantly after utilizing all types of item features as side information, thereby outperforming all other baselines.
LASPA: Latent Spatial Alignment for Fast Training-free Single Image Editing
Mar 19, 2024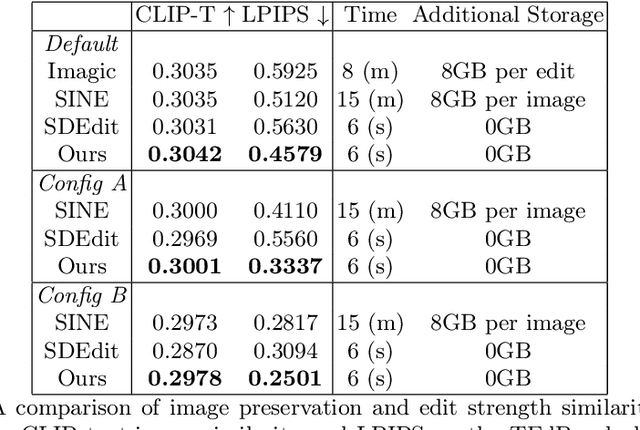
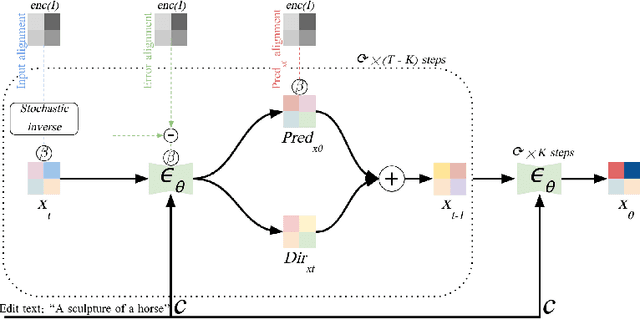
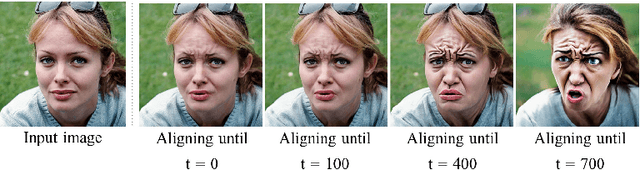

We present a novel, training-free approach for textual editing of real images using diffusion models. Unlike prior methods that rely on computationally expensive finetuning, our approach leverages LAtent SPatial Alignment (LASPA) to efficiently preserve image details. We demonstrate how the diffusion process is amenable to spatial guidance using a reference image, leading to semantically coherent edits. This eliminates the need for complex optimization and costly model finetuning, resulting in significantly faster editing compared to previous methods. Additionally, our method avoids the storage requirements associated with large finetuned models. These advantages make our approach particularly well-suited for editing on mobile devices and applications demanding rapid response times. While simple and fast, our method achieves 62-71\% preference in a user-study and significantly better model-based editing strength and image preservation scores.
The Devil is in the Edges: Monocular Depth Estimation with Edge-aware Consistency Fusion
Mar 30, 2024This paper presents a novel monocular depth estimation method, named ECFNet, for estimating high-quality monocular depth with clear edges and valid overall structure from a single RGB image. We make a thorough inquiry about the key factor that affects the edge depth estimation of the MDE networks, and come to a ratiocination that the edge information itself plays a critical role in predicting depth details. Driven by this analysis, we propose to explicitly employ the image edges as input for ECFNet and fuse the initial depths from different sources to produce the final depth. Specifically, ECFNet first uses a hybrid edge detection strategy to get the edge map and edge-highlighted image from the input image, and then leverages a pre-trained MDE network to infer the initial depths of the aforementioned three images. After that, ECFNet utilizes a layered fusion module (LFM) to fuse the initial depth, which will be further updated by a depth consistency module (DCM) to form the final estimation. Extensive experimental results on public datasets and ablation studies indicate that our method achieves state-of-the-art performance. Project page: https://zrealli.github.io/edgedepth.
Semantic Prompting with Image-Token for Continual Learning
Mar 18, 2024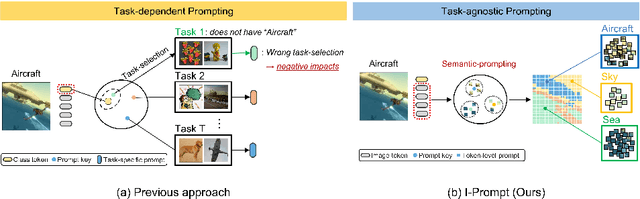
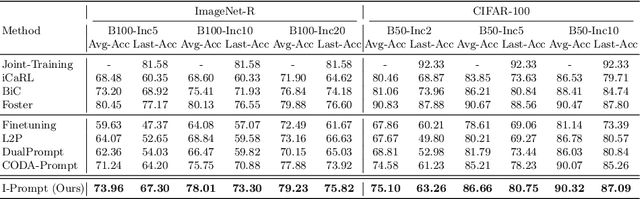
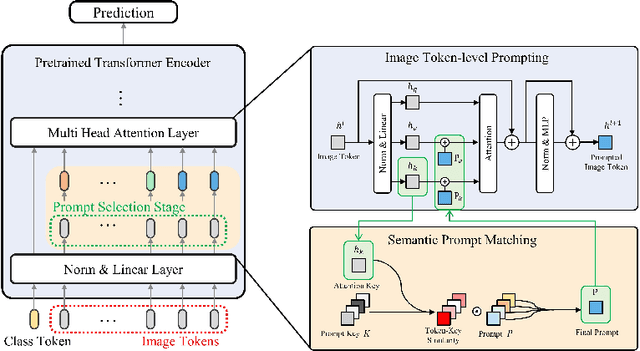
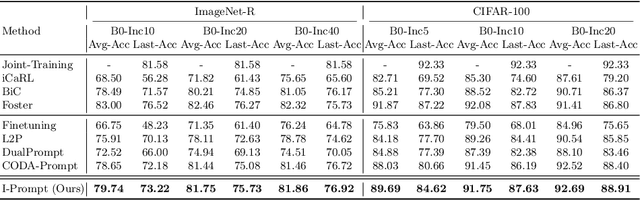
Continual learning aims to refine model parameters for new tasks while retaining knowledge from previous tasks. Recently, prompt-based learning has emerged to leverage pre-trained models to be prompted to learn subsequent tasks without the reliance on the rehearsal buffer. Although this approach has demonstrated outstanding results, existing methods depend on preceding task-selection process to choose appropriate prompts. However, imperfectness in task-selection may lead to negative impacts on the performance particularly in the scenarios where the number of tasks is large or task distributions are imbalanced. To address this issue, we introduce I-Prompt, a task-agnostic approach focuses on the visual semantic information of image tokens to eliminate task prediction. Our method consists of semantic prompt matching, which determines prompts based on similarities between tokens, and image token-level prompting, which applies prompts directly to image tokens in the intermediate layers. Consequently, our method achieves competitive performance on four benchmarks while significantly reducing training time compared to state-of-the-art methods. Moreover, we demonstrate the superiority of our method across various scenarios through extensive experiments.
Task-Customized Mixture of Adapters for General Image Fusion
Mar 19, 2024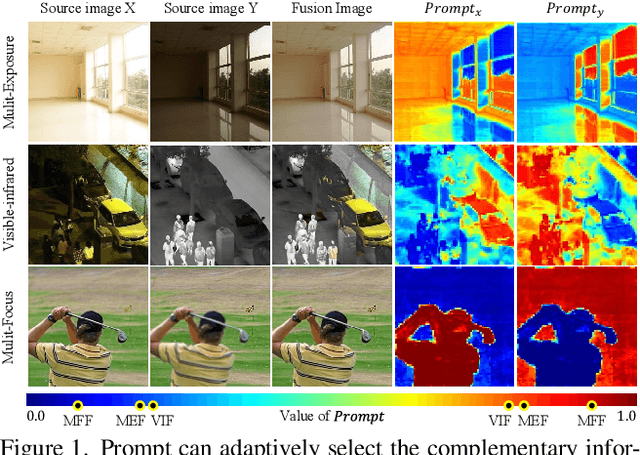
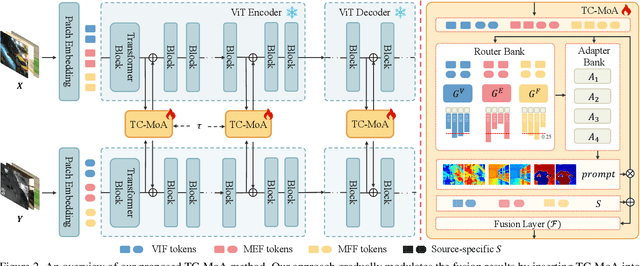
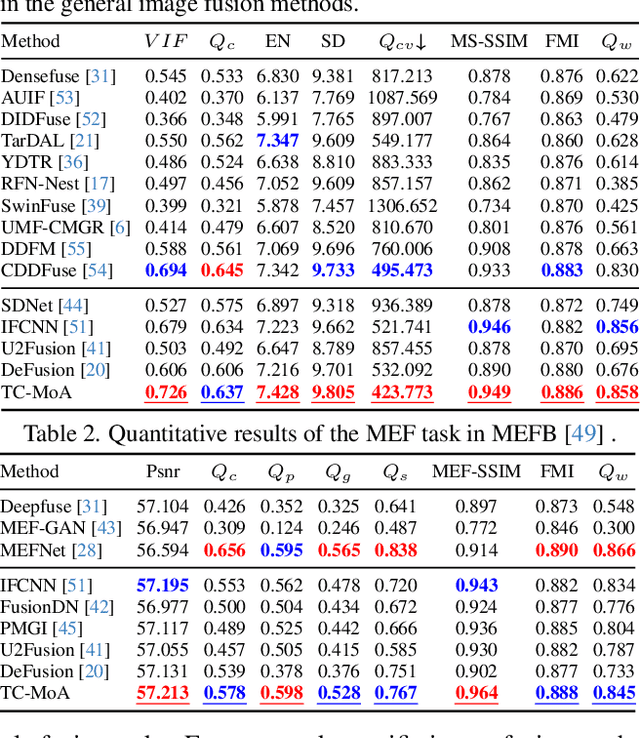

General image fusion aims at integrating important information from multi-source images. However, due to the significant cross-task gap, the respective fusion mechanism varies considerably in practice, resulting in limited performance across subtasks. To handle this problem, we propose a novel task-customized mixture of adapters (TC-MoA) for general image fusion, adaptively prompting various fusion tasks in a unified model. We borrow the insight from the mixture of experts (MoE), taking the experts as efficient tuning adapters to prompt a pre-trained foundation model. These adapters are shared across different tasks and constrained by mutual information regularization, ensuring compatibility with different tasks while complementarity for multi-source images. The task-specific routing networks customize these adapters to extract task-specific information from different sources with dynamic dominant intensity, performing adaptive visual feature prompt fusion. Notably, our TC-MoA controls the dominant intensity bias for different fusion tasks, successfully unifying multiple fusion tasks in a single model. Extensive experiments show that TC-MoA outperforms the competing approaches in learning commonalities while retaining compatibility for general image fusion (multi-modal, multi-exposure, and multi-focus), and also demonstrating striking controllability on more generalization experiments. The code is available at https://github.com/YangSun22/TC-MoA .