 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Advanced Underwater Image Restoration in Complex Illumination Conditions
Sep 05, 2023
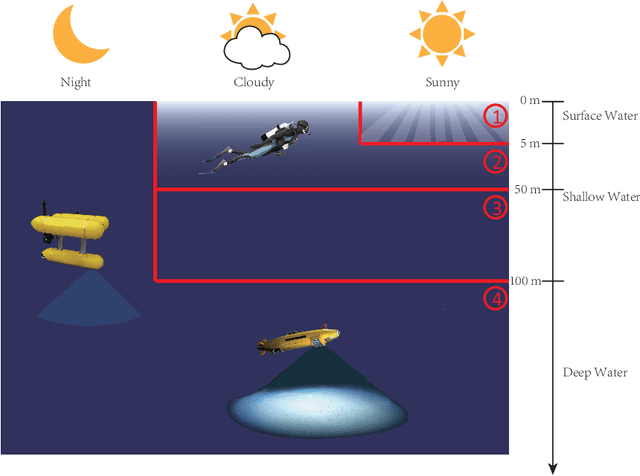

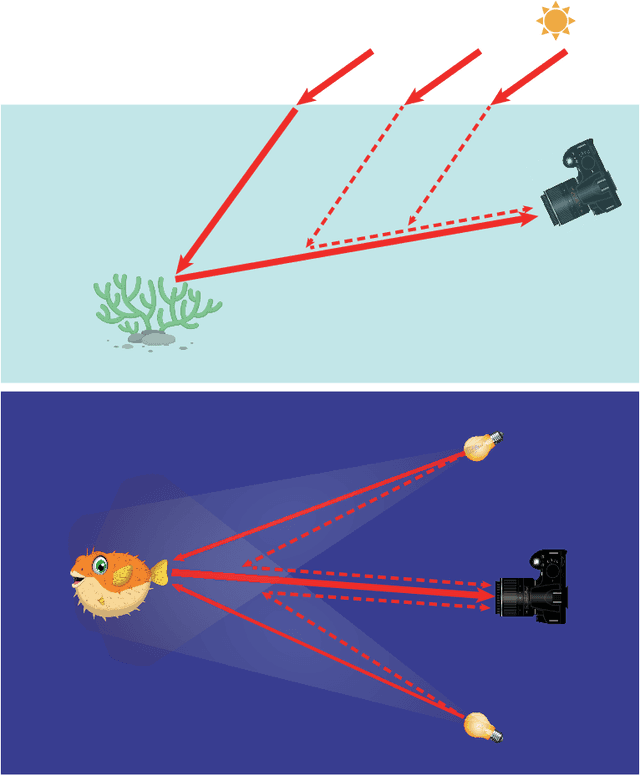
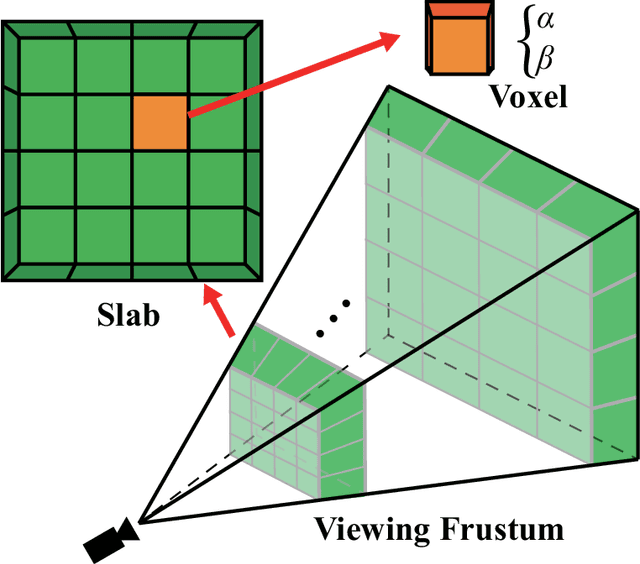
Underwater image restoration has been a challenging problem for decades since the advent of underwater photography. Most solutions focus on shallow water scenarios, where the scene is uniformly illuminated by the sunlight. However, the vast majority of uncharted underwater terrain is located beyond 200 meters depth where natural light is scarce and artificial illumination is needed. In such cases, light sources co-moving with the camera, dynamically change the scene appearance, which make shallow water restoration methods inadequate. In particular for multi-light source systems (composed of dozens of LEDs nowadays), calibrating each light is time-consuming, error-prone and tedious, and we observe that only the integrated illumination within the viewing volume of the camera is critical, rather than the individual light sources. The key idea of this paper is therefore to exploit the appearance changes of objects or the seafloor, when traversing the viewing frustum of the camera. Through new constraints assuming Lambertian surfaces, corresponding image pixels constrain the light field in front of the camera, and for each voxel a signal factor and a backscatter value are stored in a volumetric grid that can be used for very efficient image restoration of camera-light platforms, which facilitates consistently texturing large 3D models and maps that would otherwise be dominated by lighting and medium artifacts. To validate the effectiveness of our approach, we conducted extensive experiments on simulated and real-world datasets. The results of these experiments demonstrate the robustness of our approach in restoring the true albedo of objects, while mitigating the influence of lighting and medium effects. Furthermore, we demonstrate our approach can be readily extended to other scenarios, including in-air imaging with artificial illumination or other similar cases.
ScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models
Oct 11, 2023
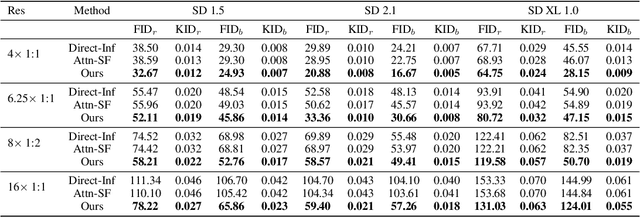


In this work, we investigate the capability of generating images from pre-trained diffusion models at much higher resolutions than the training image sizes. In addition, the generated images should have arbitrary image aspect ratios. When generating images directly at a higher resolution, 1024 x 1024, with the pre-trained Stable Diffusion using training images of resolution 512 x 512, we observe persistent problems of object repetition and unreasonable object structures. Existing works for higher-resolution generation, such as attention-based and joint-diffusion approaches, cannot well address these issues. As a new perspective, we examine the structural components of the U-Net in diffusion models and identify the crucial cause as the limited perception field of convolutional kernels. Based on this key observation, we propose a simple yet effective re-dilation that can dynamically adjust the convolutional perception field during inference. We further propose the dispersed convolution and noise-damped classifier-free guidance, which can enable ultra-high-resolution image generation (e.g., 4096 x 4096). Notably, our approach does not require any training or optimization. Extensive experiments demonstrate that our approach can address the repetition issue well and achieve state-of-the-art performance on higher-resolution image synthesis, especially in texture details. Our work also suggests that a pre-trained diffusion model trained on low-resolution images can be directly used for high-resolution visual generation without further tuning, which may provide insights for future research on ultra-high-resolution image and video synthesis.
MCUFormer: Deploying Vision Tranformers on Microcontrollers with Limited Memory
Oct 27, 2023Due to the high price and heavy energy consumption of GPUs, deploying deep models on IoT devices such as microcontrollers makes significant contributions for ecological AI. Conventional methods successfully enable convolutional neural network inference of high resolution images on microcontrollers, while the framework for vision transformers that achieve the state-of-the-art performance in many vision applications still remains unexplored. In this paper, we propose a hardware-algorithm co-optimizations method called MCUFormer to deploy vision transformers on microcontrollers with extremely limited memory, where we jointly design transformer architecture and construct the inference operator library to fit the memory resource constraint. More specifically, we generalize the one-shot network architecture search (NAS) to discover the optimal architecture with highest task performance given the memory budget from the microcontrollers, where we enlarge the existing search space of vision transformers by considering the low-rank decomposition dimensions and patch resolution for memory reduction. For the construction of the inference operator library of vision transformers, we schedule the memory buffer during inference through operator integration, patch embedding decomposition, and token overwriting, allowing the memory buffer to be fully utilized to adapt to the forward pass of the vision transformer. Experimental results demonstrate that our MCUFormer achieves 73.62\% top-1 accuracy on ImageNet for image classification with 320KB memory on STM32F746 microcontroller. Code is available at https://github.com/liangyn22/MCUFormer.
Addressing GAN Training Instabilities via Tunable Classification Losses
Oct 27, 2023Generative adversarial networks (GANs), modeled as a zero-sum game between a generator (G) and a discriminator (D), allow generating synthetic data with formal guarantees. Noting that D is a classifier, we begin by reformulating the GAN value function using class probability estimation (CPE) losses. We prove a two-way correspondence between CPE loss GANs and $f$-GANs which minimize $f$-divergences. We also show that all symmetric $f$-divergences are equivalent in convergence. In the finite sample and model capacity setting, we define and obtain bounds on estimation and generalization errors. We specialize these results to $\alpha$-GANs, defined using $\alpha$-loss, a tunable CPE loss family parametrized by $\alpha\in(0,\infty]$. We next introduce a class of dual-objective GANs to address training instabilities of GANs by modeling each player's objective using $\alpha$-loss to obtain $(\alpha_D,\alpha_G)$-GANs. We show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. Generalizing this dual-objective formulation using CPE losses, we define and obtain upper bounds on an appropriately defined estimation error. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring as well as the large publicly available Celeb-A and LSUN Classroom image datasets.
DocStormer: Revitalizing Multi-Degraded Colored Document Images to Pristine PDF
Oct 27, 2023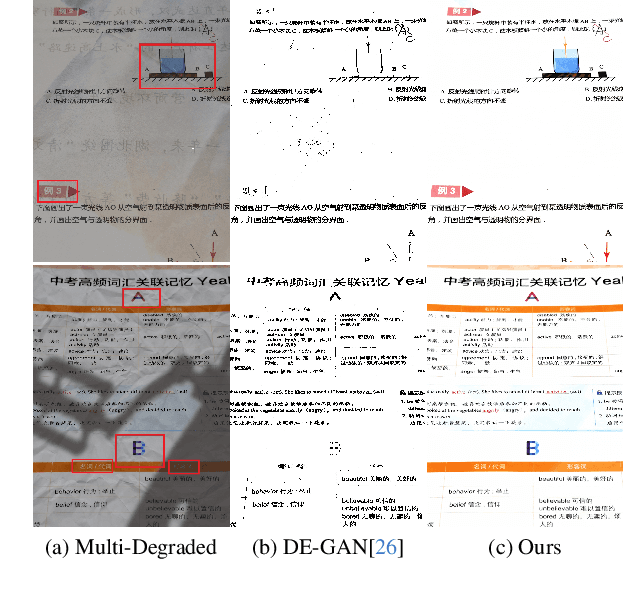

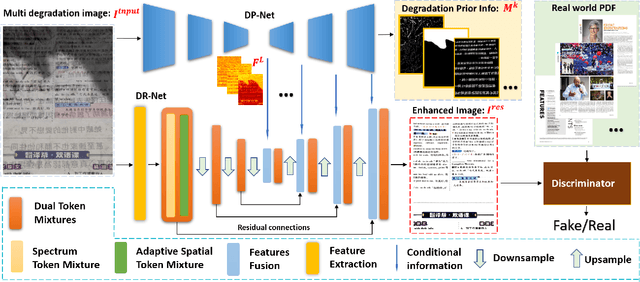
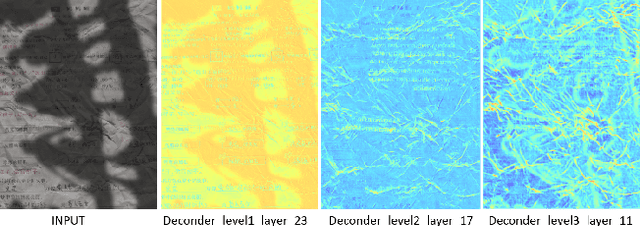
For capturing colored document images, e.g. posters and magazines, it is common that multiple degradations such as shadows, wrinkles, etc., are simultaneously introduced due to external factors. Restoring multi-degraded colored document images is a great challenge, yet overlooked, as most existing algorithms focus on enhancing color-ignored document images via binarization. Thus, we propose DocStormer, a novel algorithm designed to restore multi-degraded colored documents to their potential pristine PDF. The contributions are: firstly, we propose a "Perceive-then-Restore" paradigm with a reinforced transformer block, which more effectively encodes and utilizes the distribution of degradations. Secondly, we are the first to utilize GAN and pristine PDF magazine images to narrow the distribution gap between the enhanced results and PDF images, in pursuit of less degradation and better visual quality. Thirdly, we propose a non-parametric strategy, PFILI, which enables a smaller training scale and larger testing resolutions with acceptable detail trade-off, while saving memory and inference time. Fourthly, we are the first to propose a novel Multi-Degraded Colored Document image Enhancing dataset, named MD-CDE, for both training and evaluation. Experimental results show that the DocStormer exhibits superior performance, capable of revitalizing multi-degraded colored documents into their potential pristine digital versions, which fills the current academic gap from the perspective of method, data, and task.
Hyper-Skin: A Hyperspectral Dataset for Reconstructing Facial Skin-Spectra from RGB Images
Oct 27, 2023We introduce Hyper-Skin, a hyperspectral dataset covering wide range of wavelengths from visible (VIS) spectrum (400nm - 700nm) to near-infrared (NIR) spectrum (700nm - 1000nm), uniquely designed to facilitate research on facial skin-spectra reconstruction. By reconstructing skin spectra from RGB images, our dataset enables the study of hyperspectral skin analysis, such as melanin and hemoglobin concentrations, directly on the consumer device. Overcoming limitations of existing datasets, Hyper-Skin consists of diverse facial skin data collected with a pushbroom hyperspectral camera. With 330 hyperspectral cubes from 51 subjects, the dataset covers the facial skin from different angles and facial poses. Each hyperspectral cube has dimensions of 1024$\times$1024$\times$448, resulting in millions of spectra vectors per image. The dataset, carefully curated in adherence to ethical guidelines, includes paired hyperspectral images and synthetic RGB images generated using real camera responses. We demonstrate the efficacy of our dataset by showcasing skin spectra reconstruction using state-of-the-art models on 31 bands of hyperspectral data resampled in the VIS and NIR spectrum. This Hyper-Skin dataset would be a valuable resource to NeurIPS community, encouraging the development of novel algorithms for skin spectral reconstruction while fostering interdisciplinary collaboration in hyperspectral skin analysis related to cosmetology and skin's well-being. Instructions to request the data and the related benchmarking codes are publicly available at: \url{https://github.com/hyperspectral-skin/Hyper-Skin-2023}.
Exploring adversarial attacks in federated learning for medical imaging
Oct 10, 2023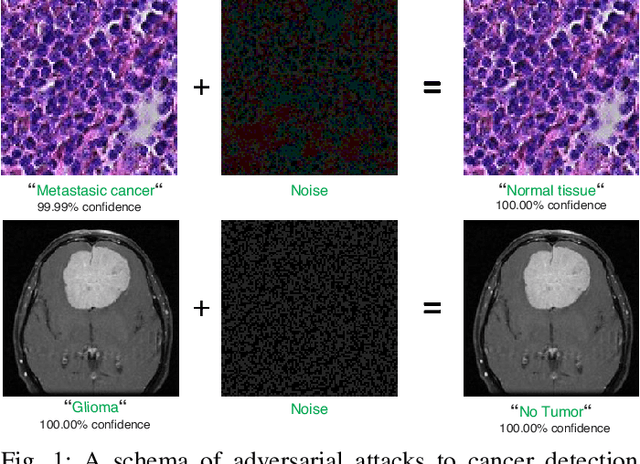
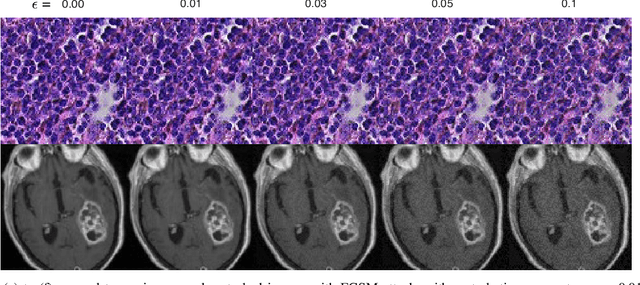
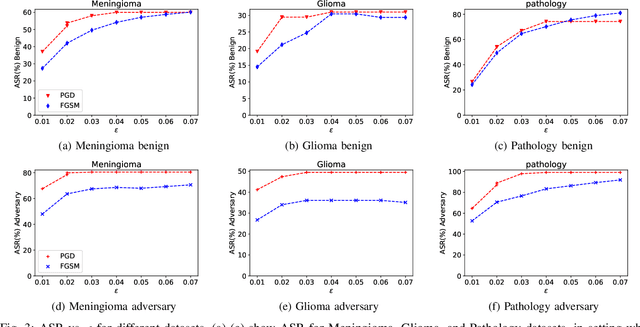
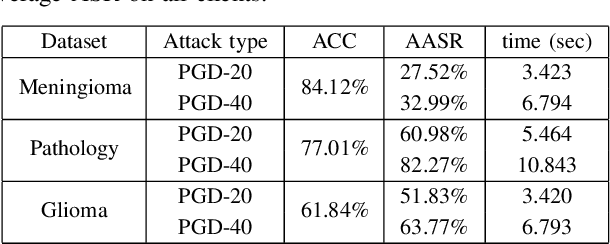
Federated learning offers a privacy-preserving framework for medical image analysis but exposes the system to adversarial attacks. This paper aims to evaluate the vulnerabilities of federated learning networks in medical image analysis against such attacks. Employing domain-specific MRI tumor and pathology imaging datasets, we assess the effectiveness of known threat scenarios in a federated learning environment. Our tests reveal that domain-specific configurations can increase the attacker's success rate significantly. The findings emphasize the urgent need for effective defense mechanisms and suggest a critical re-evaluation of current security protocols in federated medical image analysis systems.
$k$-$t$ CLAIR: Self-Consistency Guided Multi-Prior Learning for Dynamic Parallel MR Image Reconstruction
Oct 17, 2023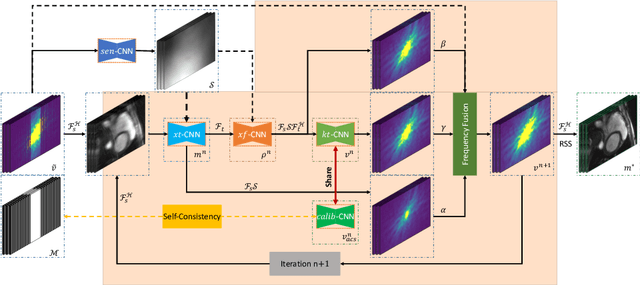
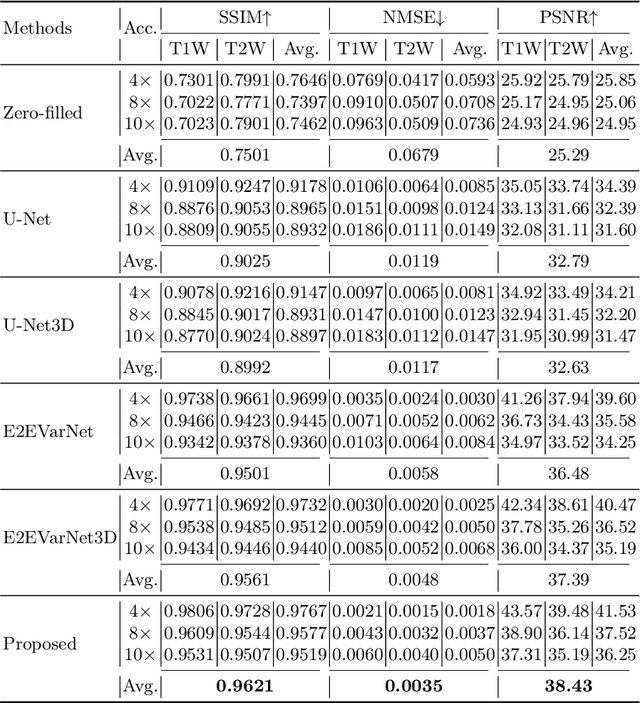
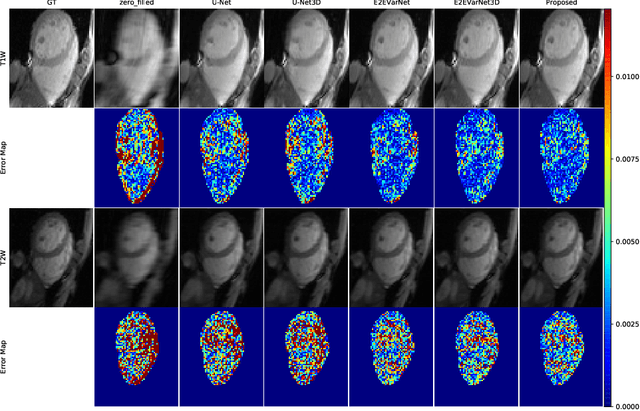
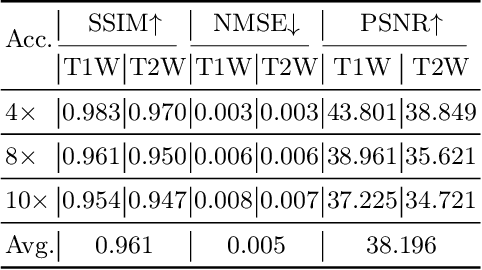
Cardiac magnetic resonance imaging (CMR) has been widely used in clinical practice for the medical diagnosis of cardiac diseases. However, the long acquisition time hinders its development in real-time applications. Here, we propose a novel self-consistency guided multi-prior learning framework named $k$-$t$ CLAIR to exploit spatiotemporal correlations from highly undersampled data for accelerated dynamic parallel MRI reconstruction. The $k$-$t$ CLAIR progressively reconstructs faithful images by leveraging multiple complementary priors learned in the $x$-$t$, $x$-$f$, and $k$-$t$ domains in an iterative fashion, as dynamic MRI exhibits high spatiotemporal redundancy. Additionally, $k$-$t$ CLAIR incorporates calibration information for prior learning, resulting in a more consistent reconstruction. Experimental results on cardiac cine and T1W/T2W images demonstrate that $k$-$t$ CLAIR achieves high-quality dynamic MR reconstruction in terms of both quantitative and qualitative performance.
CAMEL2: Enhancing weakly supervised learning for histopathology images by incorporating the significance ratio
Oct 09, 2023Histopathology image analysis plays a crucial role in cancer diagnosis. However, training a clinically applicable segmentation algorithm requires pathologists to engage in labour-intensive labelling. In contrast, weakly supervised learning methods, which only require coarse-grained labels at the image level, can significantly reduce the labeling efforts. Unfortunately, while these methods perform reasonably well in slide-level prediction, their ability to locate cancerous regions, which is essential for many clinical applications, remains unsatisfactory. Previously, we proposed CAMEL, which achieves comparable results to those of fully supervised baselines in pixel-level segmentation. However, CAMEL requires 1,280x1,280 image-level binary annotations for positive WSIs. Here, we present CAMEL2, by introducing a threshold of the cancerous ratio for positive bags, it allows us to better utilize the information, consequently enabling us to scale up the image-level setting from 1,280x1,280 to 5,120x5,120 while maintaining the accuracy. Our results with various datasets, demonstrate that CAMEL2, with the help of 5,120x5,120 image-level binary annotations, which are easy to annotate, achieves comparable performance to that of a fully supervised baseline in both instance- and slide-level classifications.
Utilizing Synthetic Data for Medical Vision-Language Pre-training: Bypassing the Need for Real Images
Oct 10, 2023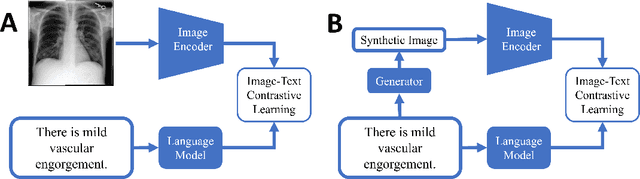
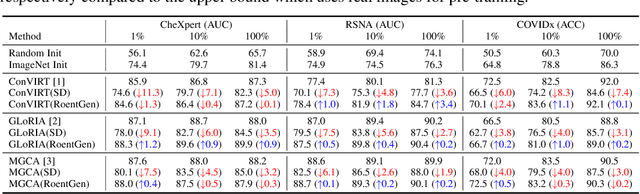
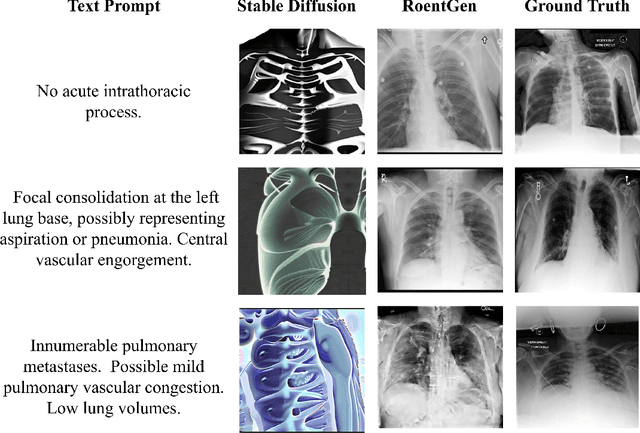
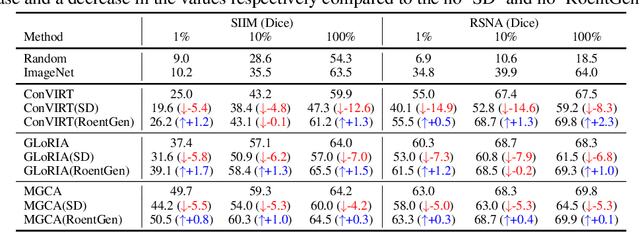
Medical Vision-Language Pre-training (VLP) learns representations jointly from medical images and paired radiology reports. It typically requires large-scale paired image-text datasets to achieve effective pre-training for both the image encoder and text encoder. The advent of text-guided generative models raises a compelling question: Can VLP be implemented solely with synthetic images generated from genuine radiology reports, thereby mitigating the need for extensively pairing and curating image-text datasets? In this work, we scrutinize this very question by examining the feasibility and effectiveness of employing synthetic images for medical VLP. We replace real medical images with their synthetic equivalents, generated from authentic medical reports. Utilizing three state-of-the-art VLP algorithms, we exclusively train on these synthetic samples. Our empirical evaluation across three subsequent tasks, namely image classification, semantic segmentation and object detection, reveals that the performance achieved through synthetic data is on par with or even exceeds that obtained with real images. As a pioneering contribution to this domain, we introduce a large-scale synthetic medical image dataset, paired with anonymized real radiology reports. This alleviates the need of sharing medical images, which are not easy to curate and share in practice. The code and the dataset will be made publicly available upon paper acceptance.