 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Flooding Regularization for Stable Training of Generative Adversarial Networks
Nov 01, 2023
Generative Adversarial Networks (GANs) have shown remarkable performance in image generation. However, GAN training suffers from the problem of instability. One of the main approaches to address this problem is to modify the loss function, often using regularization terms in addition to changing the type of adversarial losses. This paper focuses on directly regularizing the adversarial loss function. We propose a method that applies flooding, an overfitting suppression method in supervised learning, to GANs to directly prevent the discriminator's loss from becoming excessively low. Flooding requires tuning the flood level, but when applied to GANs, we propose that the appropriate range of flood level settings is determined by the adversarial loss function, supported by theoretical analysis of GANs using the binary cross entropy loss. We experimentally verify that flooding stabilizes GAN training and can be combined with other stabilization techniques. We also reveal that by restricting the discriminator's loss to be no greater than flood level, the training proceeds stably even when the flood level is somewhat high.
The Development of LLMs for Embodied Navigation
Nov 01, 2023In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN
Learning from Rich Semantics and Coarse Locations for Long-tailed Object Detection
Oct 18, 2023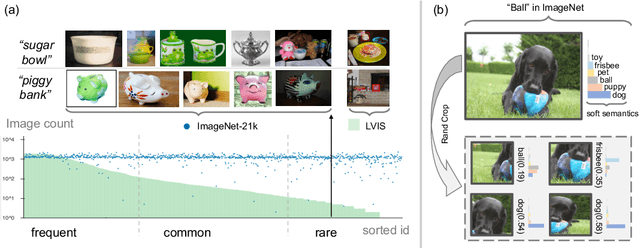
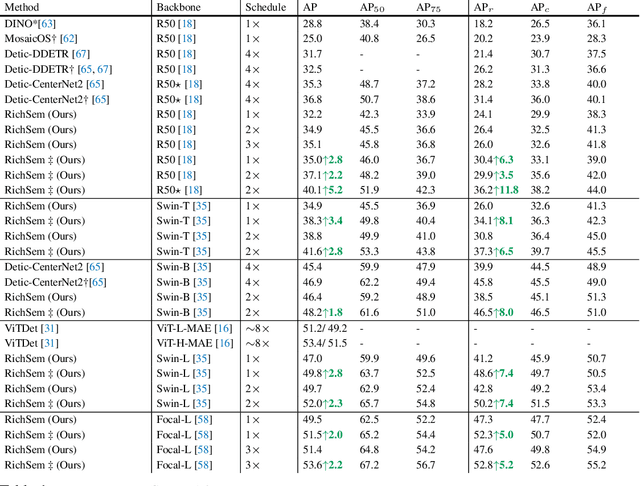
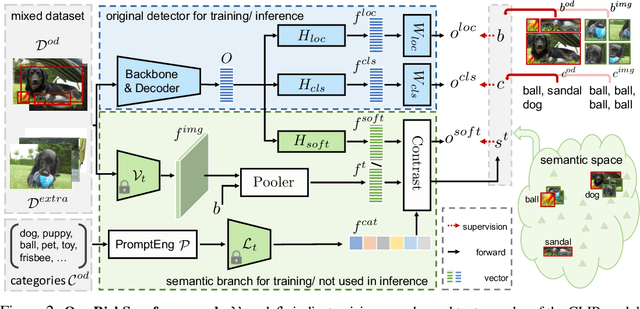
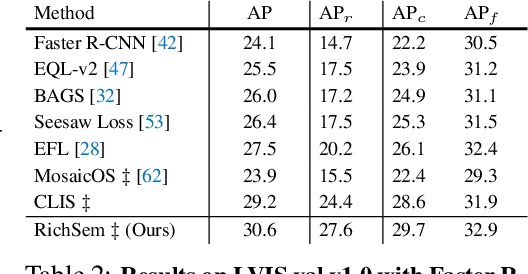
Long-tailed object detection (LTOD) aims to handle the extreme data imbalance in real-world datasets, where many tail classes have scarce instances. One popular strategy is to explore extra data with image-level labels, yet it produces limited results due to (1) semantic ambiguity -- an image-level label only captures a salient part of the image, ignoring the remaining rich semantics within the image; and (2) location sensitivity -- the label highly depends on the locations and crops of the original image, which may change after data transformations like random cropping. To remedy this, we propose RichSem, a simple but effective method, which is robust to learn rich semantics from coarse locations without the need of accurate bounding boxes. RichSem leverages rich semantics from images, which are then served as additional soft supervision for training detectors. Specifically, we add a semantic branch to our detector to learn these soft semantics and enhance feature representations for long-tailed object detection. The semantic branch is only used for training and is removed during inference. RichSem achieves consistent improvements on both overall and rare-category of LVIS under different backbones and detectors. Our method achieves state-of-the-art performance without requiring complex training and testing procedures. Moreover, we show the effectiveness of our method on other long-tailed datasets with additional experiments. Code is available at \url{https://github.com/MengLcool/RichSem}.
Cross-modal Active Complementary Learning with Self-refining Correspondence
Oct 26, 2023Recently, image-text matching has attracted more and more attention from academia and industry, which is fundamental to understanding the latent correspondence across visual and textual modalities. However, most existing methods implicitly assume the training pairs are well-aligned while ignoring the ubiquitous annotation noise, a.k.a noisy correspondence (NC), thereby inevitably leading to a performance drop. Although some methods attempt to address such noise, they still face two challenging problems: excessive memorizing/overfitting and unreliable correction for NC, especially under high noise. To address the two problems, we propose a generalized Cross-modal Robust Complementary Learning framework (CRCL), which benefits from a novel Active Complementary Loss (ACL) and an efficient Self-refining Correspondence Correction (SCC) to improve the robustness of existing methods. Specifically, ACL exploits active and complementary learning losses to reduce the risk of providing erroneous supervision, leading to theoretically and experimentally demonstrated robustness against NC. SCC utilizes multiple self-refining processes with momentum correction to enlarge the receptive field for correcting correspondences, thereby alleviating error accumulation and achieving accurate and stable corrections. We carry out extensive experiments on three image-text benchmarks, i.e., Flickr30K, MS-COCO, and CC152K, to verify the superior robustness of our CRCL against synthetic and real-world noisy correspondences.
Entity Embeddings : Perspectives Towards an Omni-Modality Era for Large Language Models
Oct 27, 2023Large Language Models (LLMs) are evolving to integrate multiple modalities, such as text, image, and audio into a unified linguistic space. We envision a future direction based on this framework where conceptual entities defined in sequences of text can also be imagined as modalities. Such a formulation has the potential to overcome the cognitive and computational limitations of current models. Several illustrative examples of such potential implicit modalities are given. Along with vast promises of the hypothesized structure, expected challenges are discussed as well.
DiffTalker: Co-driven audio-image diffusion for talking faces via intermediate landmarks
Sep 14, 2023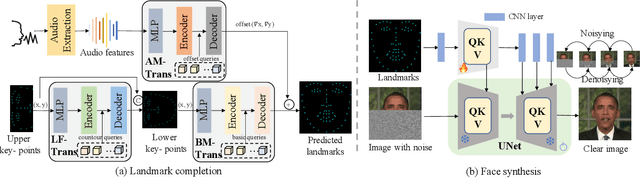
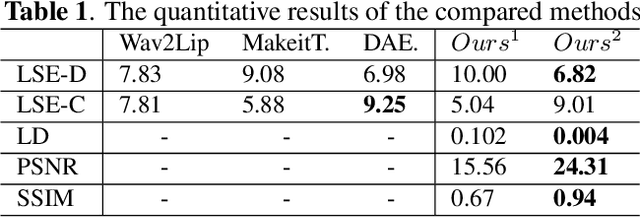
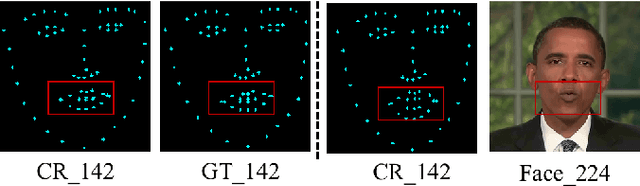

Generating realistic talking faces is a complex and widely discussed task with numerous applications. In this paper, we present DiffTalker, a novel model designed to generate lifelike talking faces through audio and landmark co-driving. DiffTalker addresses the challenges associated with directly applying diffusion models to audio control, which are traditionally trained on text-image pairs. DiffTalker consists of two agent networks: a transformer-based landmarks completion network for geometric accuracy and a diffusion-based face generation network for texture details. Landmarks play a pivotal role in establishing a seamless connection between the audio and image domains, facilitating the incorporation of knowledge from pre-trained diffusion models. This innovative approach efficiently produces articulate-speaking faces. Experimental results showcase DiffTalker's superior performance in producing clear and geometrically accurate talking faces, all without the need for additional alignment between audio and image features.
Group Testing for Accurate and Efficient Range-Based Near Neighbor Search : An Adaptive Binary Splitting Approach
Nov 05, 2023This work presents an adaptive group testing framework for the range-based high dimensional near neighbor search problem. The proposed method detects high-similarity vectors from an extensive collection of high dimensional vectors, where each vector represents an image descriptor. Our method efficiently marks each item in the collection as neighbor or non-neighbor on the basis of a cosine distance threshold without exhaustive search. Like other methods in the domain of large scale retrieval, our approach exploits the assumption that most of the items in the collection are unrelated to the query. Unlike other methods, it does not assume a large difference between the cosine similarity of the query vector with the least related neighbor and that with the least unrelated non-neighbor. Following the procedure of binary splitting, a multi-stage adaptive group testing algorithm, we split the set of items to be searched into half at each step, and perform dot product tests on smaller and smaller subsets, many of which we are able to prune away. We experimentally show that our method achieves a speed-up over exhaustive search by a factor of more than ten with an accuracy same as that of exhaustive search, on a variety of large datasets. We present a theoretical analysis of the expected number of distance computations per query and the probability that a pool with a certain number of members will be pruned. In this way, our method exploits very useful and practical distributional properties unlike other methods. In our method, all required data structures are created purely offline. Moreover, our method does not impose any strong assumptions on the number of true near neighbors, is adaptible to streaming settings where new vectors are dynamically added to the database, and does not require any parameter tuning.
Handwritten image augmentation
Aug 26, 2023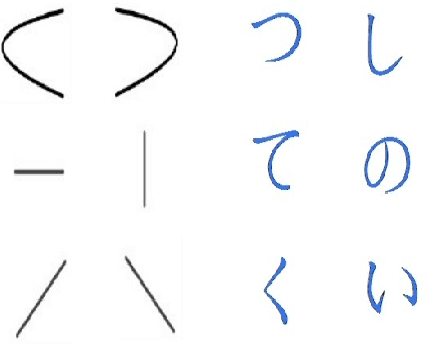
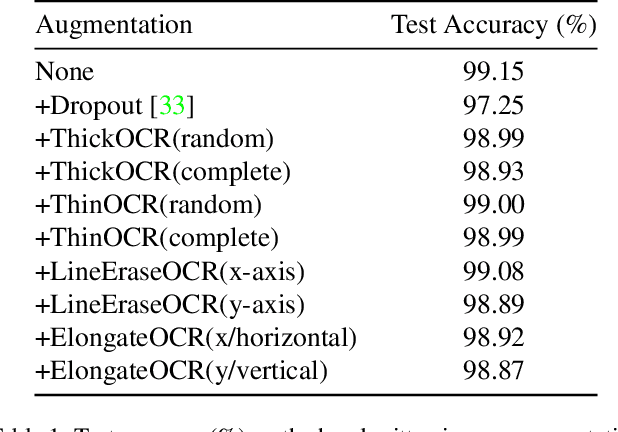
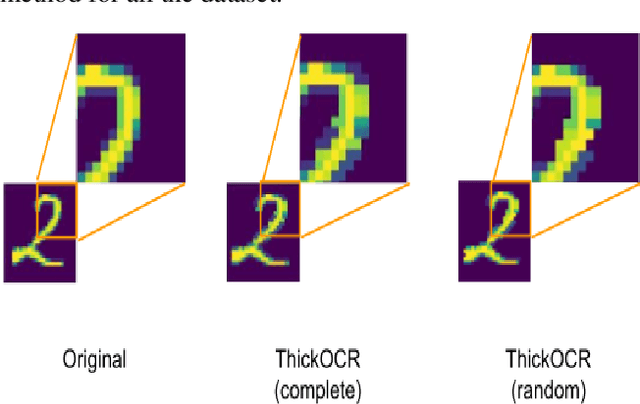
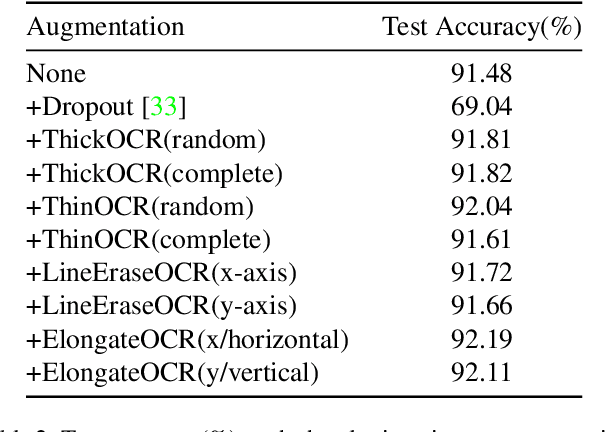
In this paper, we introduce Handwritten augmentation, a new data augmentation for handwritten character images. This method focuses on augmenting handwritten image data by altering the shape of input characters in training. The proposed handwritten augmentation is similar to position augmentation, color augmentation for images but a deeper focus on handwritten characters. Handwritten augmentation is data-driven, easy to implement, and can be integrated with CNN-based optical character recognition models. Handwritten augmentation can be implemented along with commonly used data augmentation techniques such as cropping, rotating, and yields better performance of models for handwritten image datasets developed using optical character recognition methods.
ContextRef: Evaluating Referenceless Metrics For Image Description Generation
Sep 21, 2023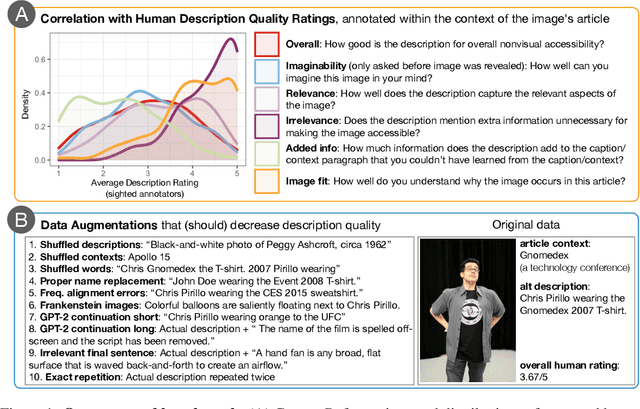
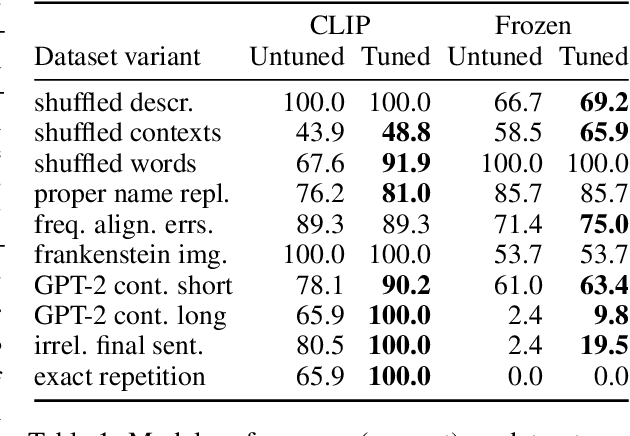
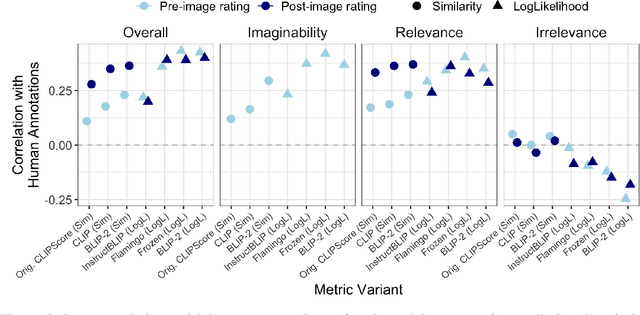
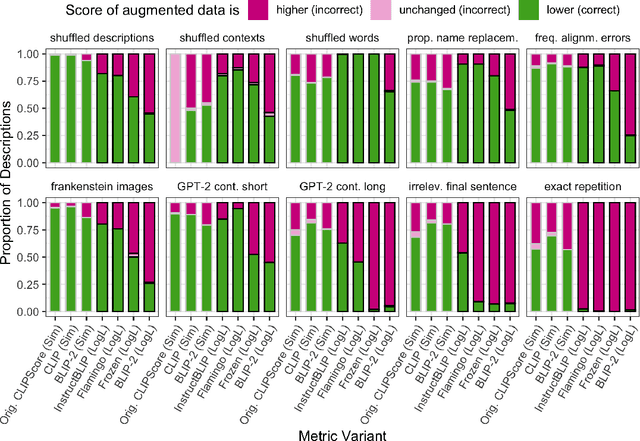
Referenceless metrics (e.g., CLIPScore) use pretrained vision--language models to assess image descriptions directly without costly ground-truth reference texts. Such methods can facilitate rapid progress, but only if they truly align with human preference judgments. In this paper, we introduce ContextRef, a benchmark for assessing referenceless metrics for such alignment. ContextRef has two components: human ratings along a variety of established quality dimensions, and ten diverse robustness checks designed to uncover fundamental weaknesses. A crucial aspect of ContextRef is that images and descriptions are presented in context, reflecting prior work showing that context is important for description quality. Using ContextRef, we assess a variety of pretrained models, scoring functions, and techniques for incorporating context. None of the methods is successful with ContextRef, but we show that careful fine-tuning yields substantial improvements. ContextRef remains a challenging benchmark though, in large part due to the challenge of context dependence.
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 31, 2023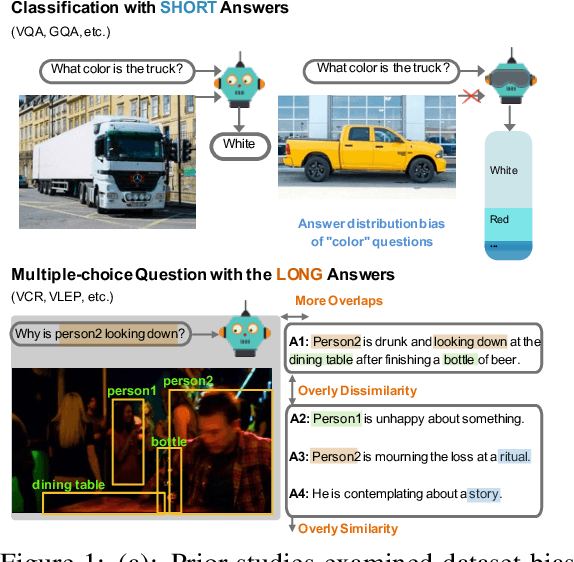
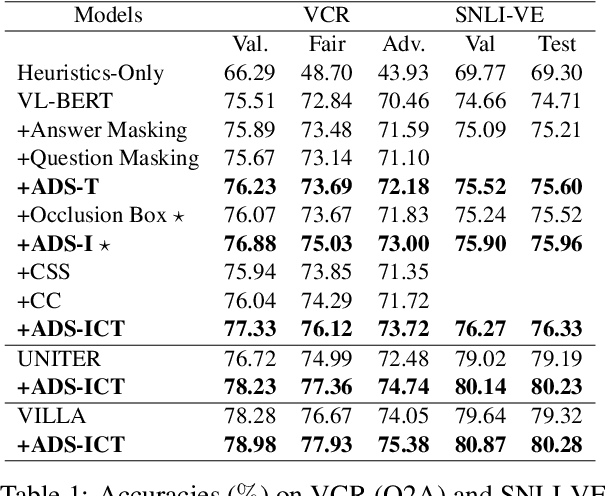
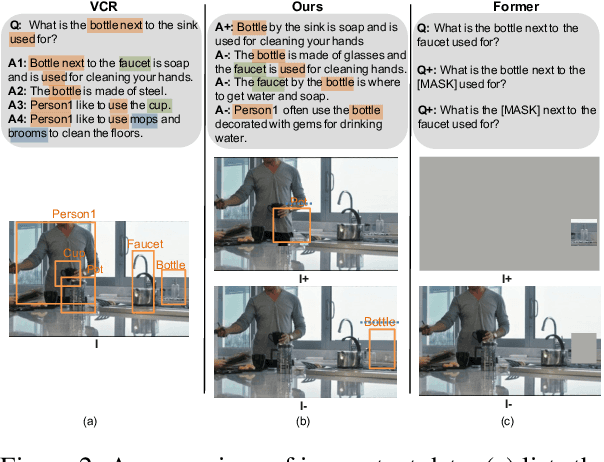
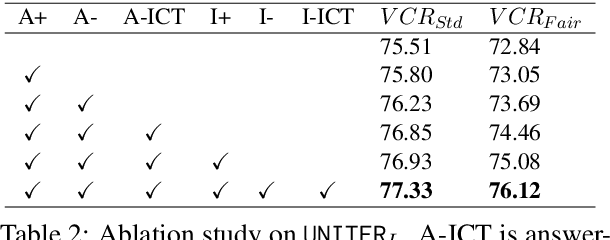
Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023