 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transitivity Recovering Decompositions: Interpretable and Robust Fine-Grained Relationships
Oct 24, 2023
Recent advances in fine-grained representation learning leverage local-to-global (emergent) relationships for achieving state-of-the-art results. The relational representations relied upon by such methods, however, are abstract. We aim to deconstruct this abstraction by expressing them as interpretable graphs over image views. We begin by theoretically showing that abstract relational representations are nothing but a way of recovering transitive relationships among local views. Based on this, we design Transitivity Recovering Decompositions (TRD), a graph-space search algorithm that identifies interpretable equivalents of abstract emergent relationships at both instance and class levels, and with no post-hoc computations. We additionally show that TRD is provably robust to noisy views, with empirical evidence also supporting this finding. The latter allows TRD to perform at par or even better than the state-of-the-art, while being fully interpretable. Implementation is available at https://github.com/abhrac/trd.
Learning Low-Rank Latent Spaces with Simple Deterministic Autoencoder: Theoretical and Empirical Insights
Oct 24, 2023The autoencoder is an unsupervised learning paradigm that aims to create a compact latent representation of data by minimizing the reconstruction loss. However, it tends to overlook the fact that most data (images) are embedded in a lower-dimensional space, which is crucial for effective data representation. To address this limitation, we propose a novel approach called Low-Rank Autoencoder (LoRAE). In LoRAE, we incorporated a low-rank regularizer to adaptively reconstruct a low-dimensional latent space while preserving the basic objective of an autoencoder. This helps embed the data in a lower-dimensional space while preserving important information. It is a simple autoencoder extension that learns low-rank latent space. Theoretically, we establish a tighter error bound for our model. Empirically, our model's superiority shines through various tasks such as image generation and downstream classification. Both theoretical and practical outcomes highlight the importance of acquiring low-dimensional embeddings.
AugUndo: Scaling Up Augmentations for Unsupervised Depth Completion
Oct 15, 2023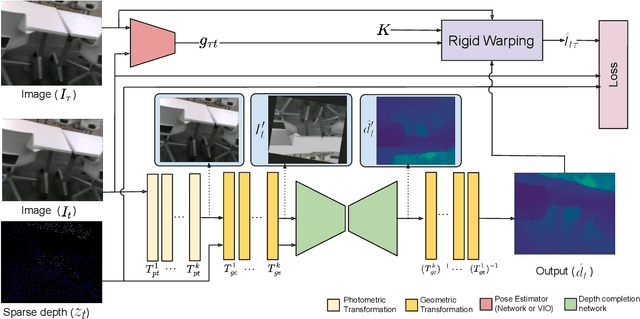
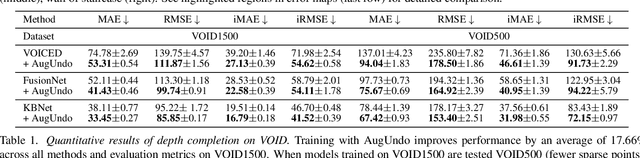
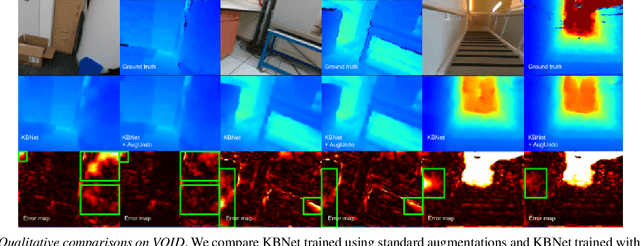
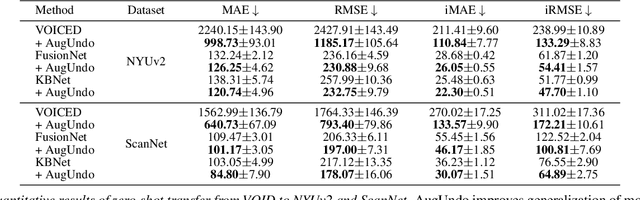
Unsupervised depth completion methods are trained by minimizing sparse depth and image reconstruction error. Block artifacts from resampling, intensity saturation, and occlusions are amongst the many undesirable by-products of common data augmentation schemes that affect image reconstruction quality, and thus the training signal. Hence, typical augmentations on images that are viewed as essential to training pipelines in other vision tasks have seen limited use beyond small image intensity changes and flipping. The sparse depth modality have seen even less as intensity transformations alter the scale of the 3D scene, and geometric transformations may decimate the sparse points during resampling. We propose a method that unlocks a wide range of previously-infeasible geometric augmentations for unsupervised depth completion. This is achieved by reversing, or "undo"-ing, geometric transformations to the coordinates of the output depth, warping the depth map back to the original reference frame. This enables computing the reconstruction losses using the original images and sparse depth maps, eliminating the pitfalls of naive loss computation on the augmented inputs. This simple yet effective strategy allows us to scale up augmentations to boost performance. We demonstrate our method on indoor (VOID) and outdoor (KITTI) datasets where we improve upon three existing methods by an average of 10.4\% across both datasets.
Multi-Concept T2I-Zero: Tweaking Only The Text Embeddings and Nothing Else
Oct 11, 2023



Recent advances in text-to-image diffusion models have enabled the photorealistic generation of images from text prompts. Despite the great progress, existing models still struggle to generate compositional multi-concept images naturally, limiting their ability to visualize human imagination. While several recent works have attempted to address this issue, they either introduce additional training or adopt guidance at inference time. In this work, we consider a more ambitious goal: natural multi-concept generation using a pre-trained diffusion model, and with almost no extra cost. To achieve this goal, we identify the limitations in the text embeddings used for the pre-trained text-to-image diffusion models. Specifically, we observe concept dominance and non-localized contribution that severely degrade multi-concept generation performance. We further design a minimal low-cost solution that overcomes the above issues by tweaking (not re-training) the text embeddings for more realistic multi-concept text-to-image generation. Our Correction by Similarities method tweaks the embedding of concepts by collecting semantic features from most similar tokens to localize the contribution. To avoid mixing features of concepts, we also apply Cross-Token Non-Maximum Suppression, which excludes the overlap of contributions from different concepts. Experiments show that our approach outperforms previous methods in text-to-image, image manipulation, and personalization tasks, despite not introducing additional training or inference costs to the diffusion steps.
C-RITNet: Set Infrared and Visible Image Fusion Free from Complementary Information Mining
Sep 13, 2023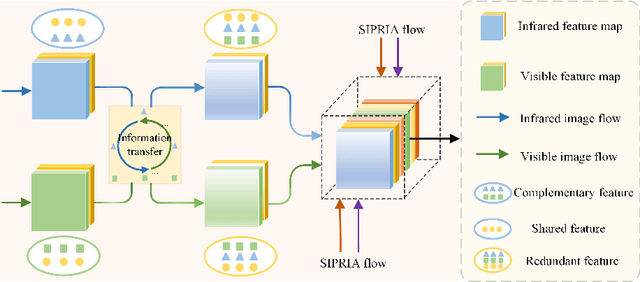

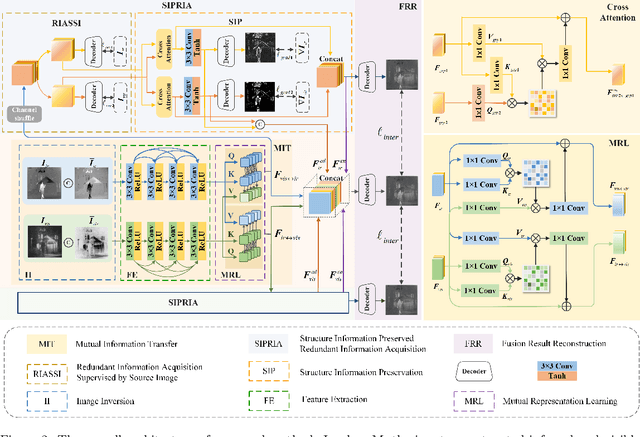
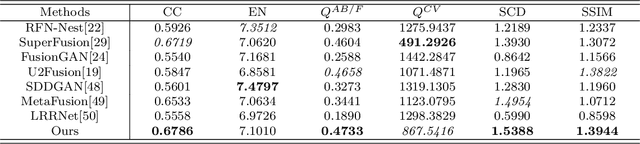
Infrared and visible image fusion (IVIF) aims to extract and integrate the complementary information in two different modalities to generate high-quality fused images with salient targets and abundant texture details. However, current image fusion methods go to great lengths to excavate complementary features, which is generally achieved through two efforts. On the one hand, the feature extraction network is expected to have excellent performance in extracting complementary information. On the other hand, complex fusion strategies are often designed to aggregate the complementary information. In other words, enabling the network to perceive and extract complementary information is extremely challenging. Complicated fusion strategies, while effective, still run the risk of losing weak edge details. To this end, this paper rethinks the IVIF outside the box, proposing a complementary-redundant information transfer network (C-RITNet). It reasonably transfers complementary information into redundant one, which integrates both the shared and complementary features from two modalities. Hence, the proposed method is able to alleviate the challenges posed by the complementary information extraction and reduce the reliance on sophisticated fusion strategies. Specifically, to skillfully sidestep aggregating complementary information in IVIF, we first design the mutual information transfer (MIT) module to mutually represent features from two modalities, roughly transferring complementary information into redundant one. Then, a redundant information acquisition supervised by source image (RIASSI) module is devised to further ensure the complementary-redundant information transfer after MIT. Meanwhile, we also propose a structure information preservation (SIP) module to guarantee that the edge structure information of the source images can be transferred to the fusion results.
Is Deep Learning Network Necessary for Image Generation?
Aug 25, 2023
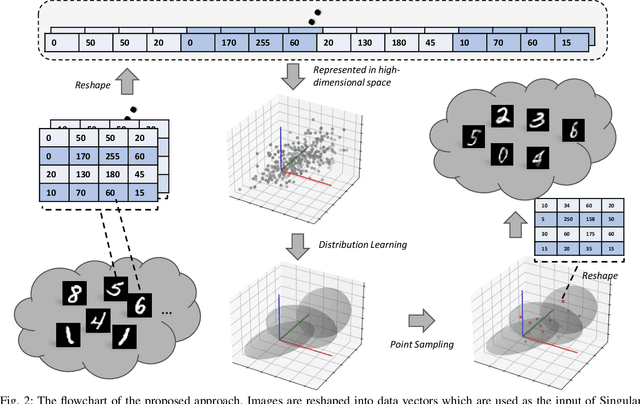


Recently, images are considered samples from a high-dimensional distribution, and deep learning has become almost synonymous with image generation. However, is a deep learning network truly necessary for image generation? In this paper, we investigate the possibility of image generation without using a deep learning network, motivated by validating the assumption that images follow a high-dimensional distribution. Since images are assumed to be samples from such a distribution, we utilize the Gaussian Mixture Model (GMM) to describe it. In particular, we employ a recent distribution learning technique named as Monte-Carlo Marginalization to capture the parameters of the GMM based on image samples. Moreover, we also use the Singular Value Decomposition (SVD) for dimensionality reduction to decrease computational complexity. During our evaluation experiment, we first attempt to model the distribution of image samples directly to verify the assumption that images truly follow a distribution. We then use the SVD for dimensionality reduction. The principal components, rather than raw image data, are used for distribution learning. Compared to methods relying on deep learning networks, our approach is more explainable, and its performance is promising. Experiments show that our images have a lower FID value compared to those generated by variational auto-encoders, demonstrating the feasibility of image generation without deep learning networks.
The GOOSE Dataset for Perception in Unstructured Environments
Oct 25, 2023The potential for deploying autonomous systems can be significantly increased by improving the perception and interpretation of the environment. However, the development of deep learning-based techniques for autonomous systems in unstructured outdoor environments poses challenges due to limited data availability for training and testing. To address this gap, we present the German Outdoor and Offroad Dataset (GOOSE), a comprehensive dataset specifically designed for unstructured outdoor environments. The GOOSE dataset incorporates 10 000 labeled pairs of images and point clouds, which are utilized to train a range of state-of-the-art segmentation models on both image and point cloud data. We open source the dataset, along with an ontology for unstructured terrain, as well as dataset standards and guidelines. This initiative aims to establish a common framework, enabling the seamless inclusion of existing datasets and a fast way to enhance the perception capabilities of various robots operating in unstructured environments. The dataset, pre-trained models for offroad perception, and additional documentation can be found at https://goose-dataset.de/.
SonoSAM -- Segment Anything on Ultrasound Images
Oct 25, 2023In this paper, we present SonoSAM - a promptable foundational model for segmenting objects of interest on ultrasound images. Fine-tuned exclusively on a rich, diverse set of objects from roughly 200k ultrasound image-mask pairs, SonoSAM demonstrates state-of-the-art performance on 8 unseen ultrasound data-sets, outperforming competing methods by a significant margin on all metrics of interest. SonoSAM achieves average dice similarity score of more than 90% on almost all test datasets within 2-6 clicks on an average, making it a valuable tool for annotating ultrasound images. We also extend SonoSAM to 3-D (2-D +t) applications and demonstrate superior performance making it a valuable tool for generating dense annotations from ultrasound cine-loops. Further, to increase practical utility of SonoSAM, we propose a two-step process of fine-tuning followed by knowledge distillation to a smaller footprint model without comprising the performance. We present detailed qualitative and quantitative comparisons of SonoSAM with state-of-the art methods showcasing efficacy of SonoSAM as one of the first reliable, generic foundational model for ultrasound.
MCUFormer: Deploying Vision Tranformers on Microcontrollers with Limited Memory
Oct 27, 2023Due to the high price and heavy energy consumption of GPUs, deploying deep models on IoT devices such as microcontrollers makes significant contributions for ecological AI. Conventional methods successfully enable convolutional neural network inference of high resolution images on microcontrollers, while the framework for vision transformers that achieve the state-of-the-art performance in many vision applications still remains unexplored. In this paper, we propose a hardware-algorithm co-optimizations method called MCUFormer to deploy vision transformers on microcontrollers with extremely limited memory, where we jointly design transformer architecture and construct the inference operator library to fit the memory resource constraint. More specifically, we generalize the one-shot network architecture search (NAS) to discover the optimal architecture with highest task performance given the memory budget from the microcontrollers, where we enlarge the existing search space of vision transformers by considering the low-rank decomposition dimensions and patch resolution for memory reduction. For the construction of the inference operator library of vision transformers, we schedule the memory buffer during inference through operator integration, patch embedding decomposition, and token overwriting, allowing the memory buffer to be fully utilized to adapt to the forward pass of the vision transformer. Experimental results demonstrate that our MCUFormer achieves 73.62\% top-1 accuracy on ImageNet for image classification with 320KB memory on STM32F746 microcontroller. Code is available at https://github.com/liangyn22/MCUFormer.
Addressing GAN Training Instabilities via Tunable Classification Losses
Oct 27, 2023Generative adversarial networks (GANs), modeled as a zero-sum game between a generator (G) and a discriminator (D), allow generating synthetic data with formal guarantees. Noting that D is a classifier, we begin by reformulating the GAN value function using class probability estimation (CPE) losses. We prove a two-way correspondence between CPE loss GANs and $f$-GANs which minimize $f$-divergences. We also show that all symmetric $f$-divergences are equivalent in convergence. In the finite sample and model capacity setting, we define and obtain bounds on estimation and generalization errors. We specialize these results to $\alpha$-GANs, defined using $\alpha$-loss, a tunable CPE loss family parametrized by $\alpha\in(0,\infty]$. We next introduce a class of dual-objective GANs to address training instabilities of GANs by modeling each player's objective using $\alpha$-loss to obtain $(\alpha_D,\alpha_G)$-GANs. We show that the resulting non-zero sum game simplifies to minimizing an $f$-divergence under appropriate conditions on $(\alpha_D,\alpha_G)$. Generalizing this dual-objective formulation using CPE losses, we define and obtain upper bounds on an appropriately defined estimation error. Finally, we highlight the value of tuning $(\alpha_D,\alpha_G)$ in alleviating training instabilities for the synthetic 2D Gaussian mixture ring as well as the large publicly available Celeb-A and LSUN Classroom image datasets.