 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging Large-Scale Pretrained Vision Foundation Models for Label-Efficient 3D Point Cloud Segmentation
Nov 03, 2023
Recently, large-scale pre-trained models such as Segment-Anything Model (SAM) and Contrastive Language-Image Pre-training (CLIP) have demonstrated remarkable success and revolutionized the field of computer vision. These foundation vision models effectively capture knowledge from a large-scale broad data with their vast model parameters, enabling them to perform zero-shot segmentation on previously unseen data without additional training. While they showcase competence in 2D tasks, their potential for enhancing 3D scene understanding remains relatively unexplored. To this end, we present a novel framework that adapts various foundational models for the 3D point cloud segmentation task. Our approach involves making initial predictions of 2D semantic masks using different large vision models. We then project these mask predictions from various frames of RGB-D video sequences into 3D space. To generate robust 3D semantic pseudo labels, we introduce a semantic label fusion strategy that effectively combines all the results via voting. We examine diverse scenarios, like zero-shot learning and limited guidance from sparse 2D point labels, to assess the pros and cons of different vision foundation models. Our approach is experimented on ScanNet dataset for 3D indoor scenes, and the results demonstrate the effectiveness of adopting general 2D foundation models on solving 3D point cloud segmentation tasks.
Beyond U: Making Diffusion Models Faster & Lighter
Oct 31, 2023Diffusion models are a family of generative models that yield record-breaking performance in tasks such as image synthesis, video generation, and molecule design. Despite their capabilities, their efficiency, especially in the reverse denoising process, remains a challenge due to slow convergence rates and high computational costs. In this work, we introduce an approach that leverages continuous dynamical systems to design a novel denoising network for diffusion models that is more parameter-efficient, exhibits faster convergence, and demonstrates increased noise robustness. Experimenting with denoising probabilistic diffusion models, our framework operates with approximately a quarter of the parameters and 30% of the Floating Point Operations (FLOPs) compared to standard U-Nets in Denoising Diffusion Probabilistic Models (DDPMs). Furthermore, our model is up to 70% faster in inference than the baseline models when measured in equal conditions while converging to better quality solutions.
Soil Image Segmentation Based on Mask R-CNN
Sep 02, 2023
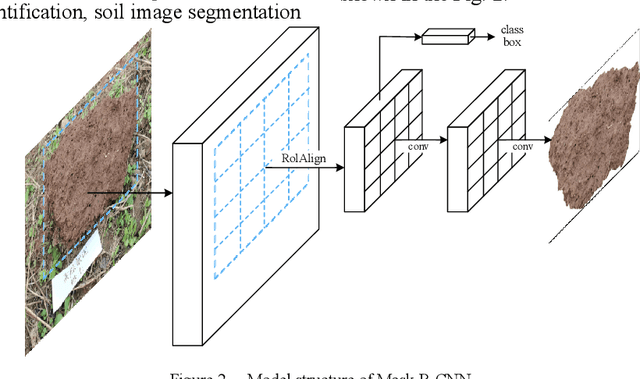
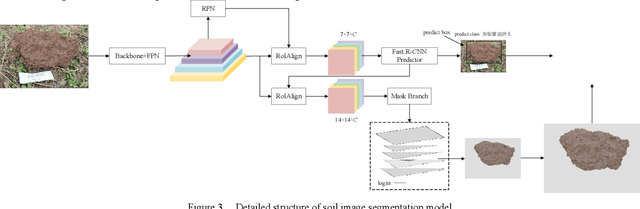
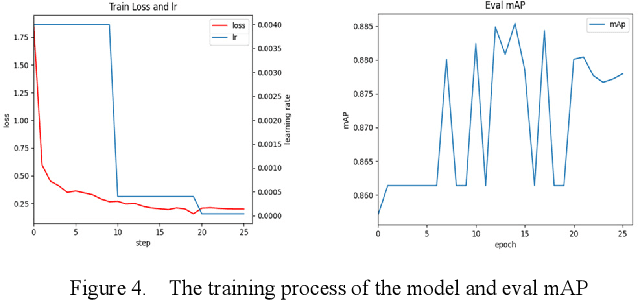
The complex background in the soil image collected in the field natural environment will affect the subsequent soil image recognition based on machine vision. Segmenting the soil center area from the soil image can eliminate the influence of the complex background, which is an important preprocessing work for subsequent soil image recognition. For the first time, the deep learning method was applied to soil image segmentation, and the Mask R-CNN model was selected to complete the positioning and segmentation of soil images. Construct a soil image dataset based on the collected soil images, use the EISeg annotation tool to mark the soil area as soil, and save the annotation information; train the Mask R-CNN soil image instance segmentation model. The trained model can obtain accurate segmentation results for soil images, and can show good performance on soil images collected in different environments; the trained instance segmentation model has a loss value of 0.1999 in the training set, and the mAP of the validation set segmentation (IoU=0.5) is 0.8804, and it takes only 0.06s to complete image segmentation based on GPU acceleration, which can meet the real-time segmentation and detection of soil images in the field under natural conditions. You can get our code in the Conclusions. The homepage is https://github.com/YidaMyth.
* 4 pages, 5 figures, Published in 2023 3rd International Conference on Consumer Electronics and Computer Engineering
MEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences
Sep 25, 2023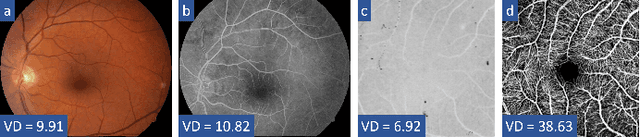
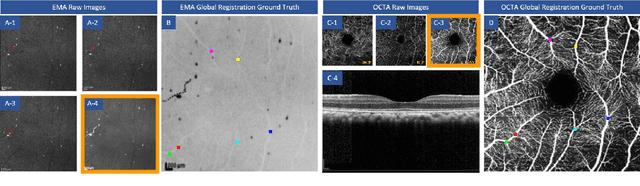
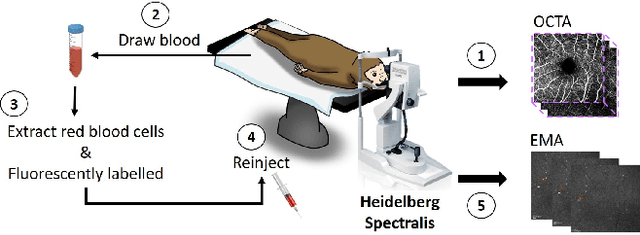
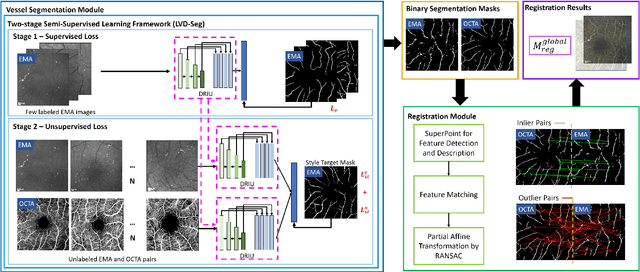
The measurement of retinal blood flow (RBF) in capillaries can provide a powerful biomarker for the early diagnosis and treatment of ocular diseases. However, no single modality can determine capillary flowrates with high precision. Combining erythrocyte-mediated angiography (EMA) with optical coherence tomography angiography (OCTA) has the potential to achieve this goal, as EMA can measure the absolute 2D RBF of retinal microvasculature and OCTA can provide the 3D structural images of capillaries. However, multimodal retinal image registration between these two modalities remains largely unexplored. To fill this gap, we establish MEMO, the first public multimodal EMA and OCTA retinal image dataset. A unique challenge in multimodal retinal image registration between these modalities is the relatively large difference in vessel density (VD). To address this challenge, we propose a segmentation-based deep-learning framework (VDD-Reg) and a new evaluation metric (MSD), which provide robust results despite differences in vessel density. VDD-Reg consists of a vessel segmentation module and a registration module. To train the vessel segmentation module, we further designed a two-stage semi-supervised learning framework (LVD-Seg) combining supervised and unsupervised losses. We demonstrate that VDD-Reg outperforms baseline methods quantitatively and qualitatively for cases of both small VD differences (using the CF-FA dataset) and large VD differences (using our MEMO dataset). Moreover, VDD-Reg requires as few as three annotated vessel segmentation masks to maintain its accuracy, demonstrating its feasibility.
Leveraging Language Models to Detect Greenwashing
Oct 30, 2023In recent years, climate change repercussions have increasingly captured public interest. Consequently, corporations are emphasizing their environmental efforts in sustainability reports to bolster their public image. Yet, the absence of stringent regulations in review of such reports allows potential greenwashing. In this study, we introduce a novel methodology to train a language model on generated labels for greenwashing risk. Our primary contributions encompass: developing a mathematical formulation to quantify greenwashing risk, a fine-tuned ClimateBERT model for this problem, and a comparative analysis of results. On a test set comprising of sustainability reports, our best model achieved an average accuracy score of 86.34% and F1 score of 0.67, demonstrating that our methods show a promising direction of exploration for this task.
MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion
Sep 21, 2023In this paper, we introduce a new approach for high-quality multi-exposure image fusion (MEF). We show that the fusion weights of an exposure can be encoded into a 1D lookup table (LUT), which takes pixel intensity value as input and produces fusion weight as output. We learn one 1D LUT for each exposure, then all the pixels from different exposures can query 1D LUT of that exposure independently for high-quality and efficient fusion. Specifically, to learn these 1D LUTs, we involve attention mechanism in various dimensions including frame, channel and spatial ones into the MEF task so as to bring us significant quality improvement over the state-of-the-art (SOTA). In addition, we collect a new MEF dataset consisting of 960 samples, 155 of which are manually tuned by professionals as ground-truth for evaluation. Our network is trained by this dataset in an unsupervised manner. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show that our approach outperforms the SOTA in our and another representative dataset SICE, both qualitatively and quantitatively. Moreover, our 1D LUT approach takes less than 4ms to run a 4K image on a PC GPU. Given its high quality, efficiency and robustness, our method has been shipped into millions of Android mobiles across multiple brands world-wide. Code is available at: https://github.com/Hedlen/MEFLUT.
DEsignBench: Exploring and Benchmarking DALL-E 3 for Imagining Visual Design
Oct 23, 2023We introduce DEsignBench, a text-to-image (T2I) generation benchmark tailored for visual design scenarios. Recent T2I models like DALL-E 3 and others, have demonstrated remarkable capabilities in generating photorealistic images that align closely with textual inputs. While the allure of creating visually captivating images is undeniable, our emphasis extends beyond mere aesthetic pleasure. We aim to investigate the potential of using these powerful models in authentic design contexts. In pursuit of this goal, we develop DEsignBench, which incorporates test samples designed to assess T2I models on both "design technical capability" and "design application scenario." Each of these two dimensions is supported by a diverse set of specific design categories. We explore DALL-E 3 together with other leading T2I models on DEsignBench, resulting in a comprehensive visual gallery for side-by-side comparisons. For DEsignBench benchmarking, we perform human evaluations on generated images in DEsignBench gallery, against the criteria of image-text alignment, visual aesthetic, and design creativity. Our evaluation also considers other specialized design capabilities, including text rendering, layout composition, color harmony, 3D design, and medium style. In addition to human evaluations, we introduce the first automatic image generation evaluator powered by GPT-4V. This evaluator provides ratings that align well with human judgments, while being easily replicable and cost-efficient. A high-resolution version is available at https://github.com/design-bench/design-bench.github.io/raw/main/designbench.pdf?download=
ESVAE: An Efficient Spiking Variational Autoencoder with Reparameterizable Poisson Spiking Sampling
Oct 23, 2023In recent years, studies on image generation models of spiking neural networks (SNNs) have gained the attention of many researchers. Variational autoencoders (VAEs), as one of the most popular image generation models, have attracted a lot of work exploring their SNN implementation. Due to the constrained binary representation in SNNs, existing SNN VAE methods implicitly construct the latent space by an elaborated autoregressive network and use the network outputs as the sampling variables. However, this unspecified implicit representation of the latent space will increase the difficulty of generating high-quality images and introduces additional network parameters. In this paper, we propose an efficient spiking variational autoencoder (ESVAE) that constructs an interpretable latent space distribution and design a reparameterizable spiking sampling method. Specifically, we construct the prior and posterior of the latent space as a Poisson distribution using the firing rate of the spiking neurons. Subsequently, we propose a reparameterizable Poisson spiking sampling method, which is free from the additional network. Comprehensive experiments have been conducted, and the experimental results show that the proposed ESVAE outperforms previous SNN VAE methods in reconstructed & generated images quality. In addition, experiments demonstrate that ESVAE's encoder is able to retain the original image information more efficiently, and the decoder is more robust. The source code is available at https://github.com/QgZhan/ESVAE.
BAAF: A Benchmark Attention Adaptive Framework for Medical Ultrasound Image Segmentation Tasks
Oct 02, 2023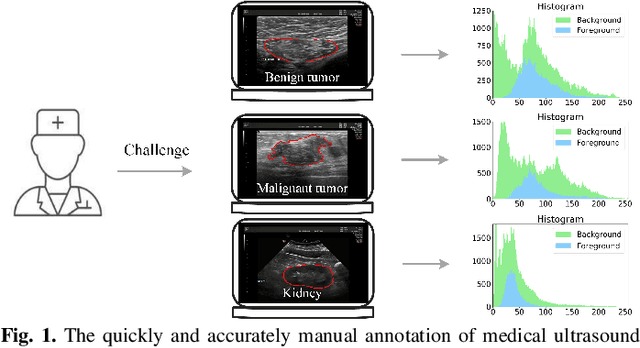
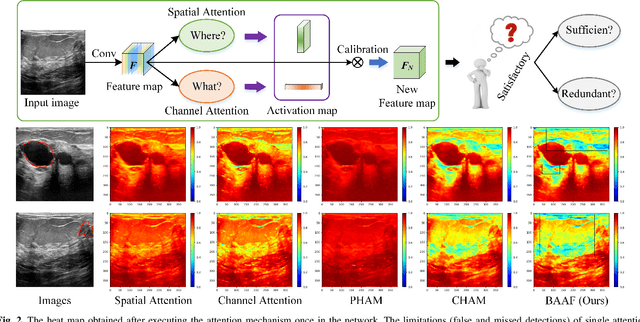
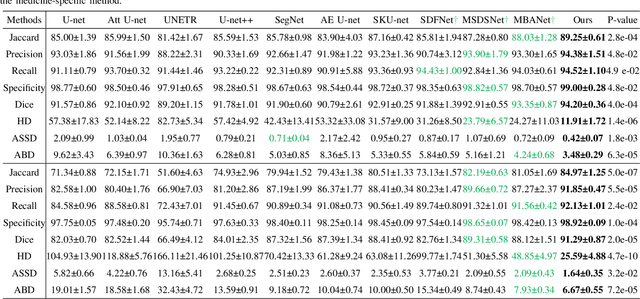
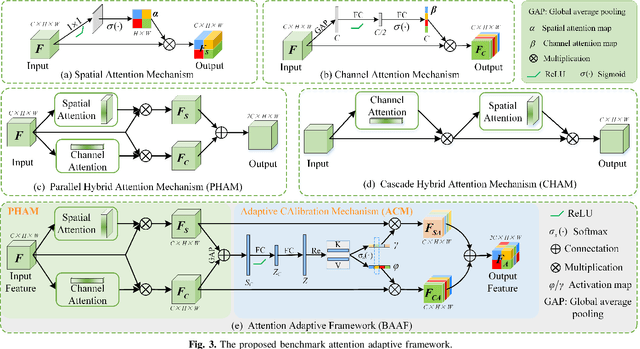
The AI-based assisted diagnosis programs have been widely investigated on medical ultrasound images. Complex scenario of ultrasound image, in which the coupled interference of internal and external factors is severe, brings a unique challenge for localize the object region automatically and precisely in ultrasound images. In this study, we seek to propose a more general and robust Benchmark Attention Adaptive Framework (BAAF) to assist doctors segment or diagnose lesions and tissues in ultrasound images more quickly and accurately. Different from existing attention schemes, the BAAF consists of a parallel hybrid attention module (PHAM) and an adaptive calibration mechanism (ACM). Specifically, BAAF first coarsely calibrates the input features from the channel and spatial dimensions, and then adaptively selects more robust lesion or tissue characterizations from the coarse-calibrated feature maps. The design of BAAF further optimizes the "what" and "where" focus and selection problems in CNNs and seeks to improve the segmentation accuracy of lesions or tissues in medical ultrasound images. The method is evaluated on four medical ultrasound segmentation tasks, and the adequate experimental results demonstrate the remarkable performance improvement over existing state-of-the-art methods. In addition, the comparison with existing attention mechanisms also demonstrates the superiority of BAAF. This work provides the possibility for automated medical ultrasound assisted diagnosis and reduces reliance on human accuracy and precision.
Brain decoding: toward real-time reconstruction of visual perception
Oct 18, 2023In the past five years, the use of generative and foundational AI systems has greatly improved the decoding of brain activity. Visual perception, in particular, can now be decoded from functional Magnetic Resonance Imaging (fMRI) with remarkable fidelity. This neuroimaging technique, however, suffers from a limited temporal resolution ($\approx$0.5 Hz) and thus fundamentally constrains its real-time usage. Here, we propose an alternative approach based on magnetoencephalography (MEG), a neuroimaging device capable of measuring brain activity with high temporal resolution ($\approx$5,000 Hz). For this, we develop an MEG decoding model trained with both contrastive and regression objectives and consisting of three modules: i) pretrained embeddings obtained from the image, ii) an MEG module trained end-to-end and iii) a pretrained image generator. Our results are threefold: Firstly, our MEG decoder shows a 7X improvement of image-retrieval over classic linear decoders. Second, late brain responses to images are best decoded with DINOv2, a recent foundational image model. Third, image retrievals and generations both suggest that MEG signals primarily contain high-level visual features, whereas the same approach applied to 7T fMRI also recovers low-level features. Overall, these results provide an important step towards the decoding - in real time - of the visual processes continuously unfolding within the human brain.