 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling
Oct 26, 2023
While conditional diffusion models are known to have good coverage of the data distribution, they still face limitations in output diversity, particularly when sampled with a high classifier-free guidance scale for optimal image quality or when trained on small datasets. We attribute this problem to the role of the conditioning signal in inference and offer an improved sampling strategy for diffusion models that can increase generation diversity, especially at high guidance scales, with minimal loss of sample quality. Our sampling strategy anneals the conditioning signal by adding scheduled, monotonically decreasing Gaussian noise to the conditioning vector during inference to balance diversity and condition alignment. Our Condition-Annealed Diffusion Sampler (CADS) can be used with any pretrained model and sampling algorithm, and we show that it boosts the diversity of diffusion models in various conditional generation tasks. Further, using an existing pretrained diffusion model, CADS achieves a new state-of-the-art FID of 1.70 and 2.31 for class-conditional ImageNet generation at 256$\times$256 and 512$\times$512 respectively.
OTMatch: Improving Semi-Supervised Learning with Optimal Transport
Oct 26, 2023Semi-supervised learning has made remarkable strides by effectively utilizing a limited amount of labeled data while capitalizing on the abundant information present in unlabeled data. However, current algorithms often prioritize aligning image predictions with specific classes generated through self-training techniques, thereby neglecting the inherent relationships that exist within these classes. In this paper, we present a new approach called OTMatch, which leverages semantic relationships among classes by employing an optimal transport loss function. By utilizing optimal transport, our proposed method consistently outperforms established state-of-the-art methods. Notably, we observed a substantial improvement of a certain percentage in accuracy compared to the current state-of-the-art method, FreeMatch. OTMatch achieves 3.18%, 3.46%, and 1.28% error rate reduction over FreeMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100 labels per class, respectively. This demonstrates the effectiveness and superiority of our approach in harnessing semantic relationships to enhance learning performance in a semi-supervised setting.
IDENAS: Internal Dependency Exploration for Neural Architecture Search
Oct 26, 2023Machine learning is a powerful tool for extracting valuable information and making various predictions from diverse datasets. Traditional algorithms rely on well-defined input and output variables however, there are scenarios where the distinction between the input and output variables and the underlying, associated (input and output) layers of the model, are unknown. Neural Architecture Search (NAS) and Feature Selection have emerged as promising solutions in such scenarios. This research proposes IDENAS, an Internal Dependency-based Exploration for Neural Architecture Search, integrating NAS with feature selection. The methodology explores internal dependencies in the complete parameter space for classification involving 1D sensor and 2D image data as well. IDENAS employs a modified encoder-decoder model and the Sequential Forward Search (SFS) algorithm, combining input-output configuration search with embedded feature selection. Experimental results demonstrate IDENASs superior performance in comparison to other algorithms, showcasing its effectiveness in model development pipelines and automated machine learning. On average, IDENAS achieved significant modelling improvements, underscoring its significant contribution to advancing the state-of-the-art in neural architecture search and feature selection integration.
LP-OVOD: Open-Vocabulary Object Detection by Linear Probing
Oct 26, 2023This paper addresses the challenging problem of open-vocabulary object detection (OVOD) where an object detector must identify both seen and unseen classes in test images without labeled examples of the unseen classes in training. A typical approach for OVOD is to use joint text-image embeddings of CLIP to assign box proposals to their closest text label. However, this method has a critical issue: many low-quality boxes, such as over- and under-covered-object boxes, have the same similarity score as high-quality boxes since CLIP is not trained on exact object location information. To address this issue, we propose a novel method, LP-OVOD, that discards low-quality boxes by training a sigmoid linear classifier on pseudo labels retrieved from the top relevant region proposals to the novel text. Experimental results on COCO affirm the superior performance of our approach over the state of the art, achieving $\textbf{40.5}$ in $\text{AP}_{novel}$ using ResNet50 as the backbone and without external datasets or knowing novel classes during training. Our code will be available at https://github.com/VinAIResearch/LP-OVOD.
Black-box Targeted Adversarial Attack on Segment Anything (SAM)
Oct 16, 2023Deep recognition models are widely vulnerable to adversarial examples, which change the model output by adding quasi-imperceptible perturbation to the image input. Recently, Segment Anything Model (SAM) has emerged to become a popular foundation model in computer vision due to its impressive generalization to unseen data and tasks. Realizing flexible attacks on SAM is beneficial for understanding the robustness of SAM in the adversarial context. To this end, this work aims to achieve a targeted adversarial attack (TAA) on SAM. Specifically, under a certain prompt, the goal is to make the predicted mask of an adversarial example resemble that of a given target image. The task of TAA on SAM has been realized in a recent arXiv work in the white-box setup by assuming access to prompt and model, which is thus less practical. To address the issue of prompt dependence, we propose a simple yet effective approach by only attacking the image encoder. Moreover, we propose a novel regularization loss to enhance the cross-model transferability by increasing the feature dominance of adversarial images over random natural images. Extensive experiments verify the effectiveness of our proposed simple techniques to conduct a successful black-box TAA on SAM.
CrossEAI: Using Explainable AI to generate better bounding boxes for Chest X-ray images
Oct 29, 2023Explainability is critical for deep learning applications in healthcare which are mandated to provide interpretations to both patients and doctors according to legal regulations and responsibilities. Explainable AI methods, such as feature importance using integrated gradients, model approximation using LIME, or neuron activation and layer conductance to provide interpretations for certain health risk predictions. In medical imaging diagnosis, disease classification usually achieves high accuracy, but generated bounding boxes have much lower Intersection over Union (IoU). Different methods with self-supervised or semi-supervised learning strategies have been proposed, but few improvements have been identified for bounding box generation. Previous work shows that bounding boxes generated by these methods are usually larger than ground truth and contain major non-disease area. This paper utilizes the advantages of post-hoc AI explainable methods to generate bounding boxes for chest x-ray image diagnosis. In this work, we propose CrossEAI which combines heatmap and gradient map to generate more targeted bounding boxes. By using weighted average of Guided Backpropagation and Grad-CAM++, we are able to generate bounding boxes which are closer to the ground truth. We evaluate our model on a chest x-ray dataset. The performance has significant improvement over the state of the art model with the same setting, with $9\%$ improvement in average of all diseases over all IoU. Moreover, as a model that does not use any ground truth bounding box information for training, we achieve same performance in general as the model that uses $80\%$ of the ground truth bounding box information for training
JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues
Oct 20, 2023The rising importance of 3D representation learning, pivotal in computer vision, autonomous driving, and robotics, is evident. However, a prevailing trend, which straightforwardly resorted to transferring 2D alignment strategies to the 3D domain, encounters three distinct challenges: (1) Information Degradation: This arises from the alignment of 3D data with mere single-view 2D images and generic texts, neglecting the need for multi-view images and detailed subcategory texts. (2) Insufficient Synergy: These strategies align 3D representations to image and text features individually, hampering the overall optimization for 3D models. (3) Underutilization: The fine-grained information inherent in the learned representations is often not fully exploited, indicating a potential loss in detail. To address these issues, we introduce JM3D, a comprehensive approach integrating point cloud, text, and image. Key contributions include the Structured Multimodal Organizer (SMO), enriching vision-language representation with multiple views and hierarchical text, and the Joint Multi-modal Alignment (JMA), combining language understanding with visual representation. Our advanced model, JM3D-LLM, marries 3D representation with large language models via efficient fine-tuning. Evaluations on ModelNet40 and ScanObjectNN establish JM3D's superiority. The superior performance of JM3D-LLM further underscores the effectiveness of our representation transfer approach. Our code and models are available at https://github.com/Mr-Neko/JM3D.
Sparse Multi-Object Render-and-Compare
Oct 17, 2023Reconstructing 3D shape and pose of static objects from a single image is an essential task for various industries, including robotics, augmented reality, and digital content creation. This can be done by directly predicting 3D shape in various representations or by retrieving CAD models from a database and predicting their alignments. Directly predicting 3D shapes often produces unrealistic, overly smoothed or tessellated shapes. Retrieving CAD models ensures realistic shapes but requires robust and accurate alignment. Learning to directly predict CAD model poses from image features is challenging and inaccurate. Works, such as ROCA, compute poses from predicted normalised object coordinates which can be more accurate but are susceptible to systematic failure. SPARC demonstrates that following a ''render-and-compare'' approach where a network iteratively improves upon its own predictions achieves accurate alignments. Nevertheless, it performs individual CAD alignment for every object detected in an image. This approach is slow when applied to many objects as the time complexity increases linearly with the number of objects and can not learn inter-object relations. Introducing a new network architecture Multi-SPARC we learn to perform CAD model alignments for multiple detected objects jointly. Compared to other single-view methods we achieve state-of-the-art performance on the challenging real-world dataset ScanNet. By improving the instance alignment accuracy from 31.8% to 40.3% we perform similar to state-of-the-art multi-view methods.
Learning to Explain: A Model-Agnostic Framework for Explaining Black Box Models
Oct 25, 2023We present Learning to Explain (LTX), a model-agnostic framework designed for providing post-hoc explanations for vision models. The LTX framework introduces an "explainer" model that generates explanation maps, highlighting the crucial regions that justify the predictions made by the model being explained. To train the explainer, we employ a two-stage process consisting of initial pretraining followed by per-instance finetuning. During both stages of training, we utilize a unique configuration where we compare the explained model's prediction for a masked input with its original prediction for the unmasked input. This approach enables the use of a novel counterfactual objective, which aims to anticipate the model's output using masked versions of the input image. Importantly, the LTX framework is not restricted to a specific model architecture and can provide explanations for both Transformer-based and convolutional models. Through our evaluations, we demonstrate that LTX significantly outperforms the current state-of-the-art in explainability across various metrics.
Graph-based multimodal multi-lesion DLBCL treatment response prediction from PET images
Oct 25, 2023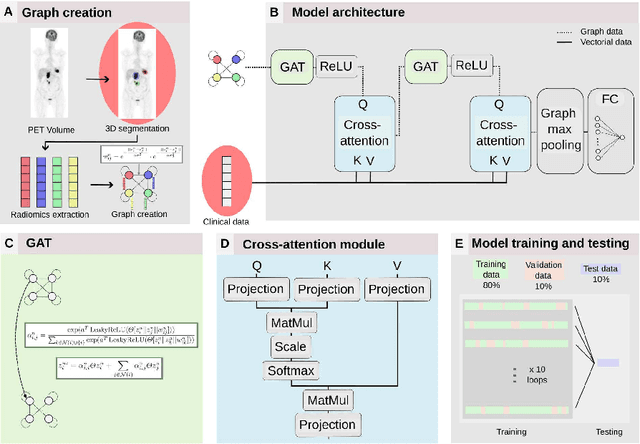
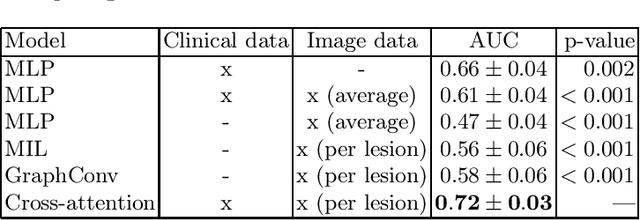
Diffuse Large B-cell Lymphoma (DLBCL) is a lymphatic cancer involving one or more lymph nodes and extranodal sites. Its diagnostic and follow-up rely on Positron Emission Tomography (PET) and Computed Tomography (CT). After diagnosis, the number of nonresponding patients to standard front-line therapy remains significant (30-40%). This work aims to develop a computer-aided approach to identify high-risk patients requiring adapted treatment by efficiently exploiting all the information available for each patient, including both clinical and image data. We propose a method based on recent graph neural networks that combine imaging information from multiple lesions, and a cross-attention module to integrate different data modalities efficiently. The model is trained and evaluated on a private prospective multicentric dataset of 583 patients. Experimental results show that our proposed method outperforms classical supervised methods based on either clinical, imaging or both clinical and imaging data for the 2-year progression-free survival (PFS) classification accuracy.