 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 20, 2024

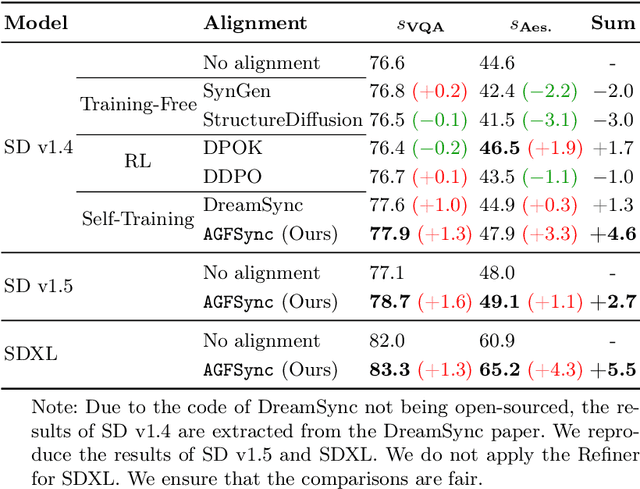
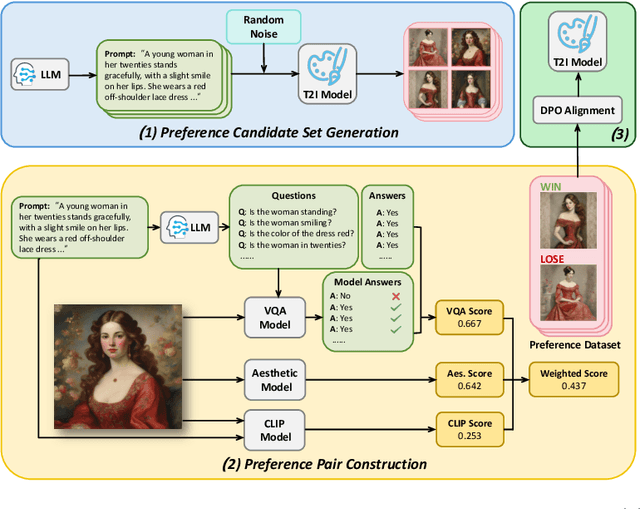
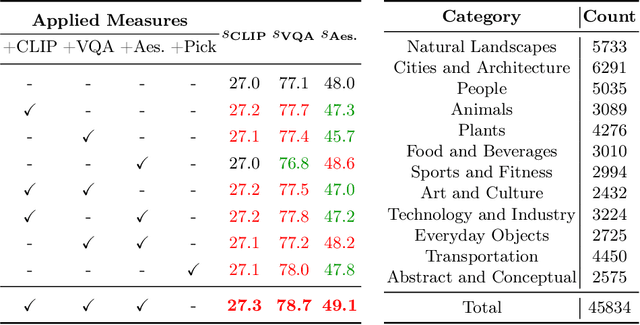
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
Dependability Evaluation of Stable Diffusion with Soft Errors on the Model Parameters
Mar 30, 2024Stable Diffusion is a popular Transformer-based model for image generation from text; it applies an image information creator to the input text and the visual knowledge is added in a step-by-step fashion to create an image that corresponds to the input text. However, this diffusion process can be corrupted by errors from the underlying hardware, which are especially relevant for implementations at the nanoscales. In this paper, the dependability of Stable Diffusion is studied focusing on soft errors in the memory that stores the model parameters; specifically, errors are injected into some critical layers of the Transformer in different blocks of the image information creator, to evaluate their impact on model performance. The simulations results reveal several conclusions: 1) errors on the down blocks of the creator have a larger impact on the quality of the generated images than those on the up blocks, while the errors on middle block have negligible effect; 2) errors on the self-attention (SA) layers have larger impact on the results than those on the cross-attention (CA) layers; 3) for CA layers, errors on deeper levels result in a larger impact; 4) errors on blocks at the first levels tend to introduce noise in the image, and those on deep layers tend to introduce large colored blocks. These results provide an initial understanding of the impact of errors on Stable Diffusion.
DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
Mar 30, 2024We present DiffHuman, a probabilistic method for photorealistic 3D human reconstruction from a single RGB image. Despite the ill-posed nature of this problem, most methods are deterministic and output a single solution, often resulting in a lack of geometric detail and blurriness in unseen or uncertain regions. In contrast, DiffHuman predicts a probability distribution over 3D reconstructions conditioned on an input 2D image, which allows us to sample multiple detailed 3D avatars that are consistent with the image. DiffHuman is implemented as a conditional diffusion model that denoises pixel-aligned 2D observations of an underlying 3D shape representation. During inference, we may sample 3D avatars by iteratively denoising 2D renders of the predicted 3D representation. Furthermore, we introduce a generator neural network that approximates rendering with considerably reduced runtime (55x speed up), resulting in a novel dual-branch diffusion framework. Our experiments show that DiffHuman can produce diverse and detailed reconstructions for the parts of the person that are unseen or uncertain in the input image, while remaining competitive with the state-of-the-art when reconstructing visible surfaces.
Efficient scene text image super-resolution with semantic guidance
Mar 20, 2024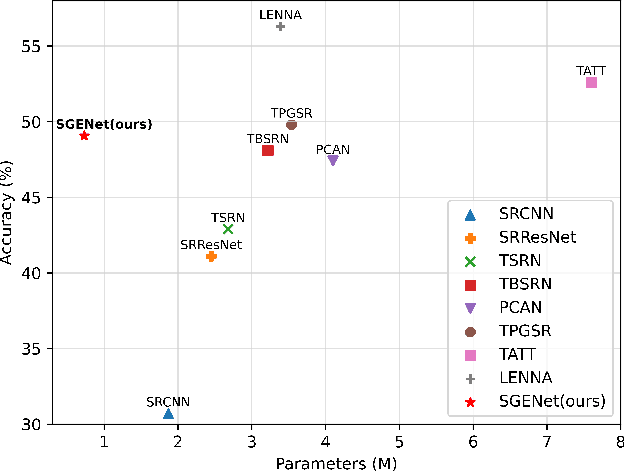
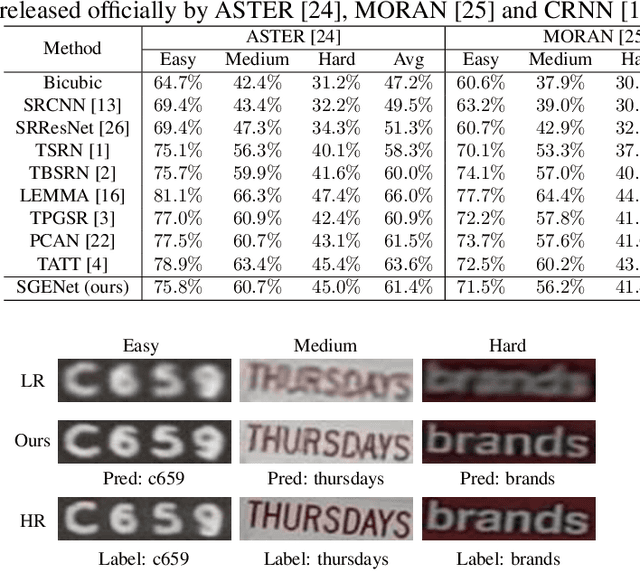
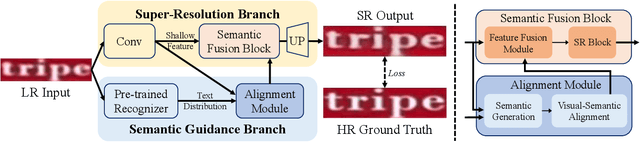
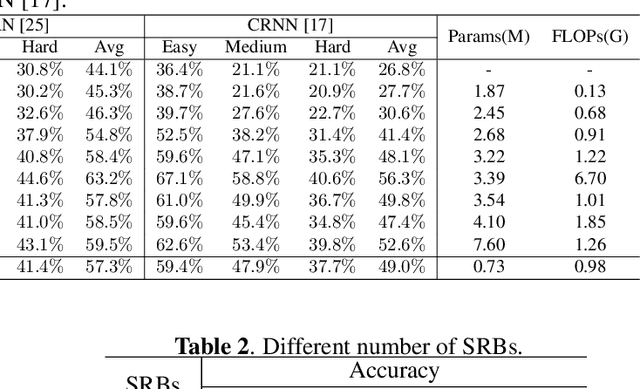
Scene text image super-resolution has significantly improved the accuracy of scene text recognition. However, many existing methods emphasize performance over efficiency and ignore the practical need for lightweight solutions in deployment scenarios. Faced with the issues, our work proposes an efficient framework called SGENet to facilitate deployment on resource-limited platforms. SGENet contains two branches: super-resolution branch and semantic guidance branch. We apply a lightweight pre-trained recognizer as a semantic extractor to enhance the understanding of text information. Meanwhile, we design the visual-semantic alignment module to achieve bidirectional alignment between image features and semantics, resulting in the generation of highquality prior guidance. We conduct extensive experiments on benchmark dataset, and the proposed SGENet achieves excellent performance with fewer computational costs. Code is available at https://github.com/SijieLiu518/SGENet
Flexible Variable-Rate Image Feature Compression for Edge-Cloud Systems
Mar 30, 2024Feature compression is a promising direction for coding for machines. Existing methods have made substantial progress, but they require designing and training separate neural network models to meet different specifications of compression rate, performance accuracy and computational complexity. In this paper, a flexible variable-rate feature compression method is presented that can operate on a range of rates by introducing a rate control parameter as an input to the neural network model. By compressing different intermediate features of a pre-trained vision task model, the proposed method can scale the encoding complexity without changing the overall size of the model. The proposed method is more flexible than existing baselines, at the same time outperforming them in terms of the three-way trade-off between feature compression rate, vision task accuracy, and encoding complexity. We have made the source code available at https://github.com/adnan-hossain/var_feat_comp.git.
ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Mar 20, 2024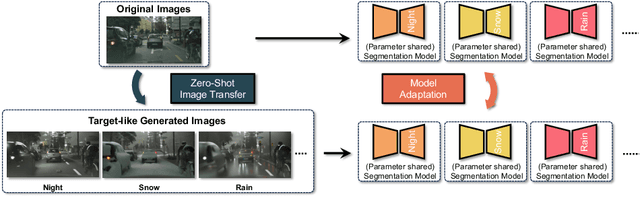
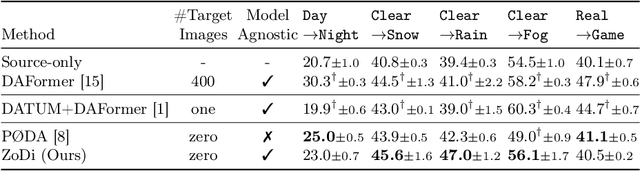
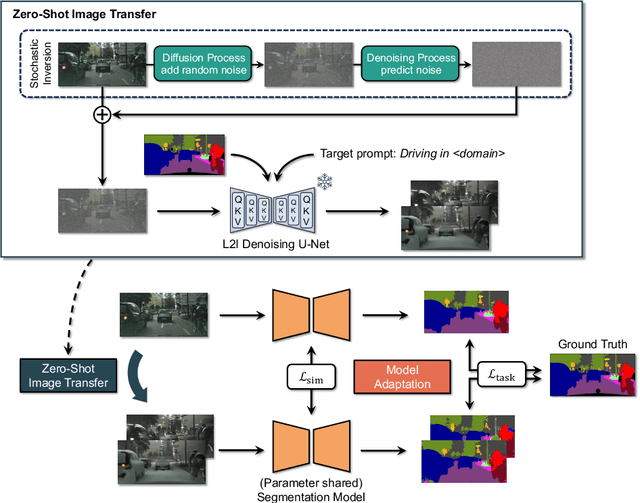
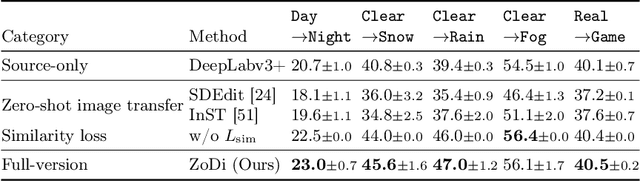
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models' performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model's performance without target images by inspecting generated images. Our implementation will be publicly available.
Image Classification with Rotation-Invariant Variational Quantum Circuits
Mar 22, 2024Variational quantum algorithms are gaining attention as an early application of Noisy Intermediate-Scale Quantum (NISQ) devices. One of the main problems of variational methods lies in the phenomenon of Barren Plateaus, present in the optimization of variational parameters. Adding geometric inductive bias to the quantum models has been proposed as a potential solution to mitigate this problem, leading to a new field called Geometric Quantum Machine Learning. In this work, an equivariant architecture for variational quantum classifiers is introduced to create a label-invariant model for image classification with $C_4$ rotational label symmetry. The equivariant circuit is benchmarked against two different architectures, and it is experimentally observed that the geometric approach boosts the model's performance. Finally, a classical equivariant convolution operation is proposed to extend the quantum model for the processing of larger images, employing the resources available in NISQ devices.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 13, 2024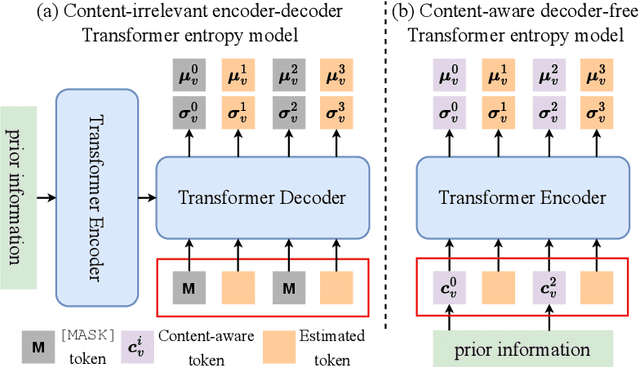
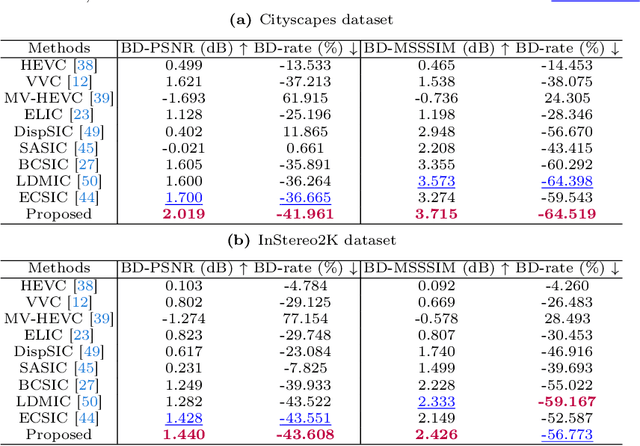
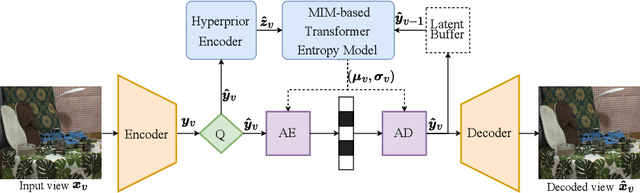
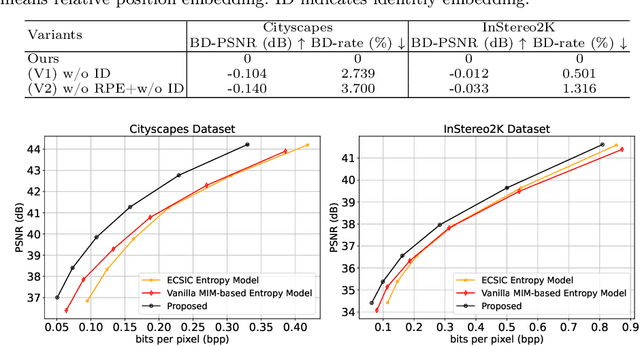
Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
Prompt Learning for Oriented Power Transmission Tower Detection in High-Resolution SAR Images
Apr 01, 2024Detecting transmission towers from synthetic aperture radar (SAR) images remains a challenging task due to the comparatively small size and side-looking geometry, with background clutter interference frequently hindering tower identification. A large number of interfering signals superimposes the return signal from the tower. We found that localizing or prompting positions of power transmission towers is beneficial to address this obstacle. Based on this revelation, this paper introduces prompt learning into the oriented object detector (P2Det) for multimodal information learning. P2Det contains the sparse prompt coding and cross-attention between the multimodal data. Specifically, the sparse prompt encoder (SPE) is proposed to represent point locations, converting prompts into sparse embeddings. The image embeddings are generated through the Transformer layers. Then a two-way fusion module (TWFM) is proposed to calculate the cross-attention of the two different embeddings. The interaction of image-level and prompt-level features is utilized to address the clutter interference. A shape-adaptive refinement module (SARM) is proposed to reduce the effect of aspect ratio. Extensive experiments demonstrated the effectiveness of the proposed model on high-resolution SAR images. P2Det provides a novel insight for multimodal object detection due to its competitive performance.
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Anthropic Prior Knowledge
Apr 01, 2024Teeth localization, segmentation, and labeling in 2D images have great potential in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, general instance segmentation frameworks are incompetent due to 1) the subtle differences between some teeth' shapes (e.g., maxillary first premolar and second premolar), 2) the teeth's position and shape variation across subjects, and 3) the presence of abnormalities in the dentition (e.g., caries and edentulism). To address these problems, we propose a ViT-based framework named TeethSEG, which consists of stacked Multi-Scale Aggregation (MSA) blocks and an Anthropic Prior Knowledge (APK) layer. Specifically, to compose the two modules, we design 1) a unique permutation-based upscaler to ensure high efficiency while establishing clear segmentation boundaries with 2) multi-head self/cross-gating layers to emphasize particular semantics meanwhile maintaining the divergence between token embeddings. Besides, we collect 3) the first open-sourced intraoral image dataset IO150K, which comprises over 150k intraoral photos, and all photos are annotated by orthodontists using a human-machine hybrid algorithm. Experiments on IO150K demonstrate that our TeethSEG outperforms the state-of-the-art segmentation models on dental image segmentation.